系统最近对基础模块增加了一些新的功能,顺便就对老版本的实现做了一些重构。基本上相当于重写了,主要是第一版是在需求断断续续的变化,也就在最初的版本上修修补补,直到这次实在不想继续这么修补下去,就来了一次大翻新。在翻新的过程中,也不断地尝试了一些小技巧将逻辑理顺,代码的复用性提高,这里希望能够将一些体会和经验趁热打铁记录下来。
首先简单描述一下基础模块的信息。如图,几个基础的机构分别是代理商个人,代理商公司,物业个人,物业公司,物业其它组织几个实体,它们是整个系统最核心的机构,所有的业务都是可以溯源到这几个类型机构上的;代理商集合和物业集合是为了方便查询列表和各自的基本信息合成的信息表;金融相关的业务需要用到第三方机构的账户,比如一些商户信息,所以银行账户也是夹杂在其中。
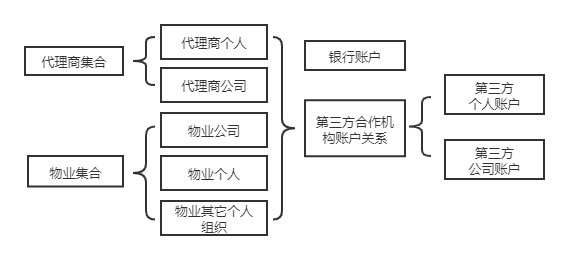
不同类型的机构实体在进行数据存储和更新时,都有特定的规则;而第三方相关的账户进行注册或者绑卡之后,主体的很多字段也是不允许再进行修改的;另外,在研发和交付的过程中,一些规则和功能又可能会发生变化。所以,在这种情况下,我们需要尽量地将代码设计地灵活一些,否则一旦发生变动,对于开发维护甚至测试都是很困难的。以下内容会结合场景来总结一些重构过程中的编码变化。
1.尝试采用基类处理公共字段和逻辑。
可以从上图中看到,五个核心的主体,既可以按照公司、个人的分类进行区分,也可以按照代理商、物业的分类进行区分。而在实际字段设置时,也确实有很多重叠的部分。这种分类的区分,在进行持久化实体字段设计时,可以通过提取公共字段的办法组装基类。如果业务逻辑的变化是发生在基类字段上的,那么不同的主体类处理这个逻辑时,可以通过向上转型,从而达到调用相同方法处理这一段逻辑。
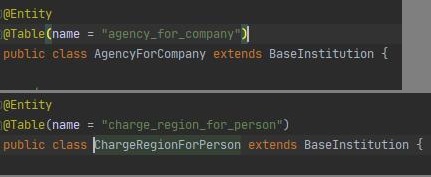
如图所示,如果业务逻辑是承载在BaseInstitution中的字段上时,可以将AgencyCompany和ChargeRegionPerson转型为BaseInstitution,在逻辑代码中使用BaseInstitutionService.doSomething(BaseInstitution baseInstitution)来进行处理。
当然,这种处理方式也是需要非常肯定这个公共基类中的内容基本不会发生变化,一旦有变动,涉及变更的类和方法将会很多,所以这里也需要根据实际场景进行取舍。
2.不要写重复代码。
重复代码带来的危害主要是,当一处发现了问题,你必须找到所有相同逻辑的地方进行修改,如果发生了遗漏,这个过程就会反反复复。一开始的提取方法,也确实是需要花费一些精力和时间的,但这对于后期来说易于维护,是ROI极高的一件事情。
我们时常说,面向对象的代码要设计成易于维护,可扩展性强的代码结构。但如果这种单纯的重复代码都不愿意进行抽取的话,那就是懒惰,这是在设计经验不足时唯一能够做到,也是能够做好的一件事情。经验不够不足以采用合适的设计模式来完成这些逻辑的时候,起码要做到的就是不写重复代码。处理相同的逻辑时,要想办法将它们合并到一处。
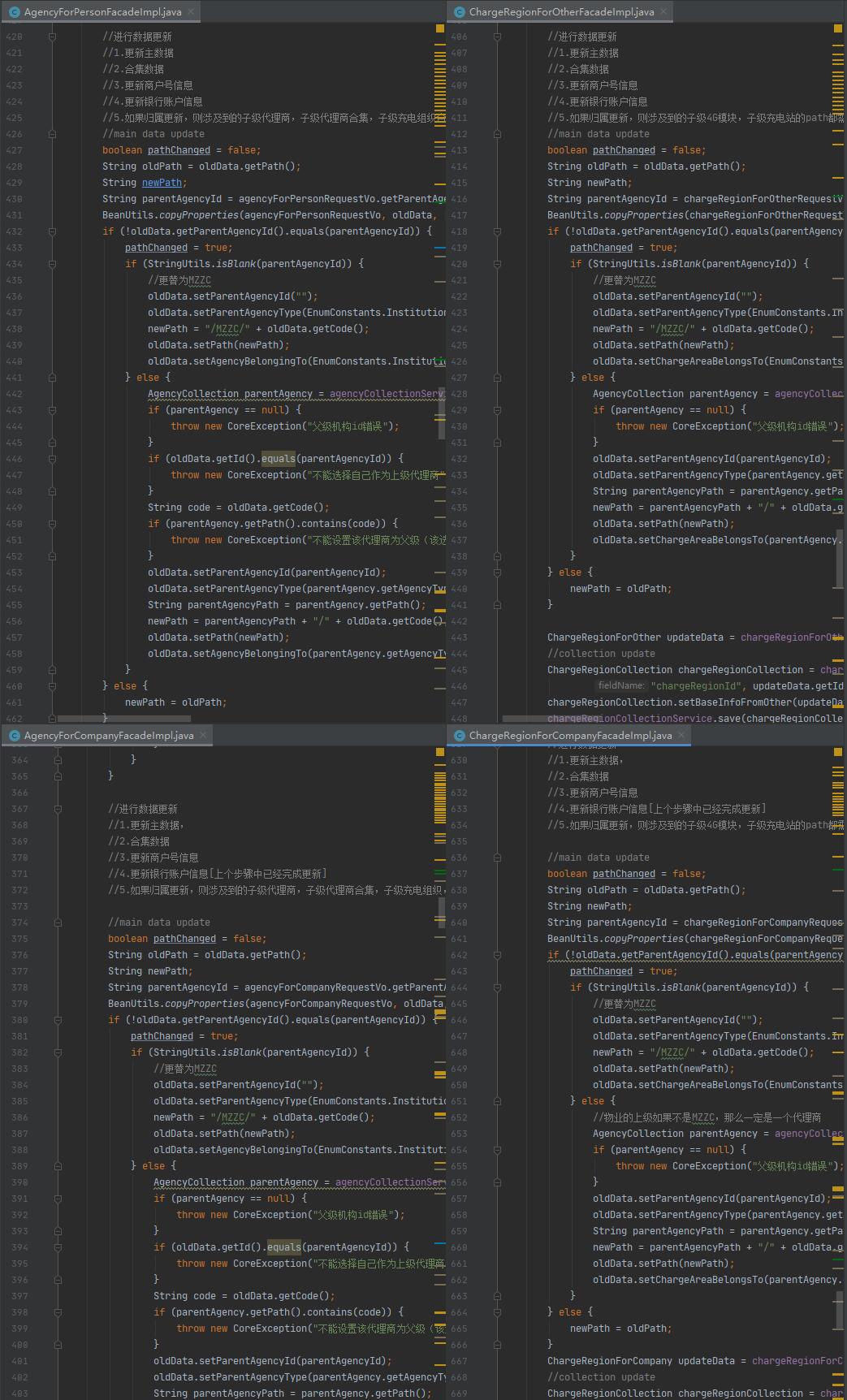
如图中代码,其实各个主体要做的事情一模一样,但是这里完全是照抄之前的代码进行处理。这种偷懒无论从开发进度、还是维护进度的ROI都是极低的,贪一时之方便,陷万难之纠缠。所以一旦察觉到有类似的代码块,就要想办法进行公共方法的提取。实际上,现在的IDE越来越智能,只要一个快捷键,我们就能够很方便地将一段逻辑处理抽取成为单独的方法。熟练掌握也能够大大提升生产力。

3.不要在公共方法中传输多个参数。
在平常的开发中,如果经常抽取代码,为了图省事,我们可能会使用多个参数来达到目的。就如上图中,我们用自动抽取的办法获得了一个4个参数的方法。虽然这达到了抽取方法以减少重复代码的目标,但是如果参数多了,也是会增加我们编码和后期维护的难度。
首先,参数越多,就越需要我们花费精力去读懂它。试想一下,如果一个方法有十几个参数,你会不会头大?我们的目标就是当知道这个方法是做什么的时候,使用这个方法的时候越容易、甚至越无感才是最好的。其次,过多的参数往往意味着组成这个方法的来源的要素是比较多的,如果这其中还有什么特殊的规则和业务逻辑,那么我们每次在调用这个方法的时候都必须要考虑这些规则和逻辑,一旦出了问题,也是需要对每个调用的地点进行修改的。
为了解决这些问题,我们可能就需要将这一批参数转换为一个DTO,进行数据转换之后再进行传输。在这个DTO种我们可以统一将上述的规则和逻辑进行集中处理。
这里其实是一个比较重要的原则,就是对于相同的持久层数据实体,要归聚到这一个DTO类中进行处理。这样做的好处是,一旦跟这个数据实体相关的规则发生变化或者扩展,那么我们只需要在这个DTO类中就能完成改动,而不是在散落于整个系统中的代码块或者方法中修改。而这些DTO承载了这些规则和逻辑之后,外部的调用也是很轻松的,基本上我们可以在调用时不用考虑这些规则,直接调用API即可,做到调用容易、无感,出现了规则相关的bug,只需在DTO中处理就好。以上只是说逻辑和规则简单时直接放在DTO中承载,如果比较复杂我们可以专门设计一个Service或者Manager来处理这个规则。
这里举个例子说明。外部的数据由于界面上的一些限制,所以传入的VO类中,数据是不完整的。而传入数据库实体的过程中,各个机构的数据来源会因为机构的类型不同而采用不同的规则,比如对于公司类机构,公户银行卡账户名称需要填入合同主体名称,而私户账户名称需要填入法人姓名;对于个人类机构,只有私户,但是代理商和物业个人的私户银行卡名称需要填入合同主体姓名,而其他机构的物业的私户银行卡名称需要填入联系人姓名。所以我们需要一个类专门处理这个补充内容的字段:
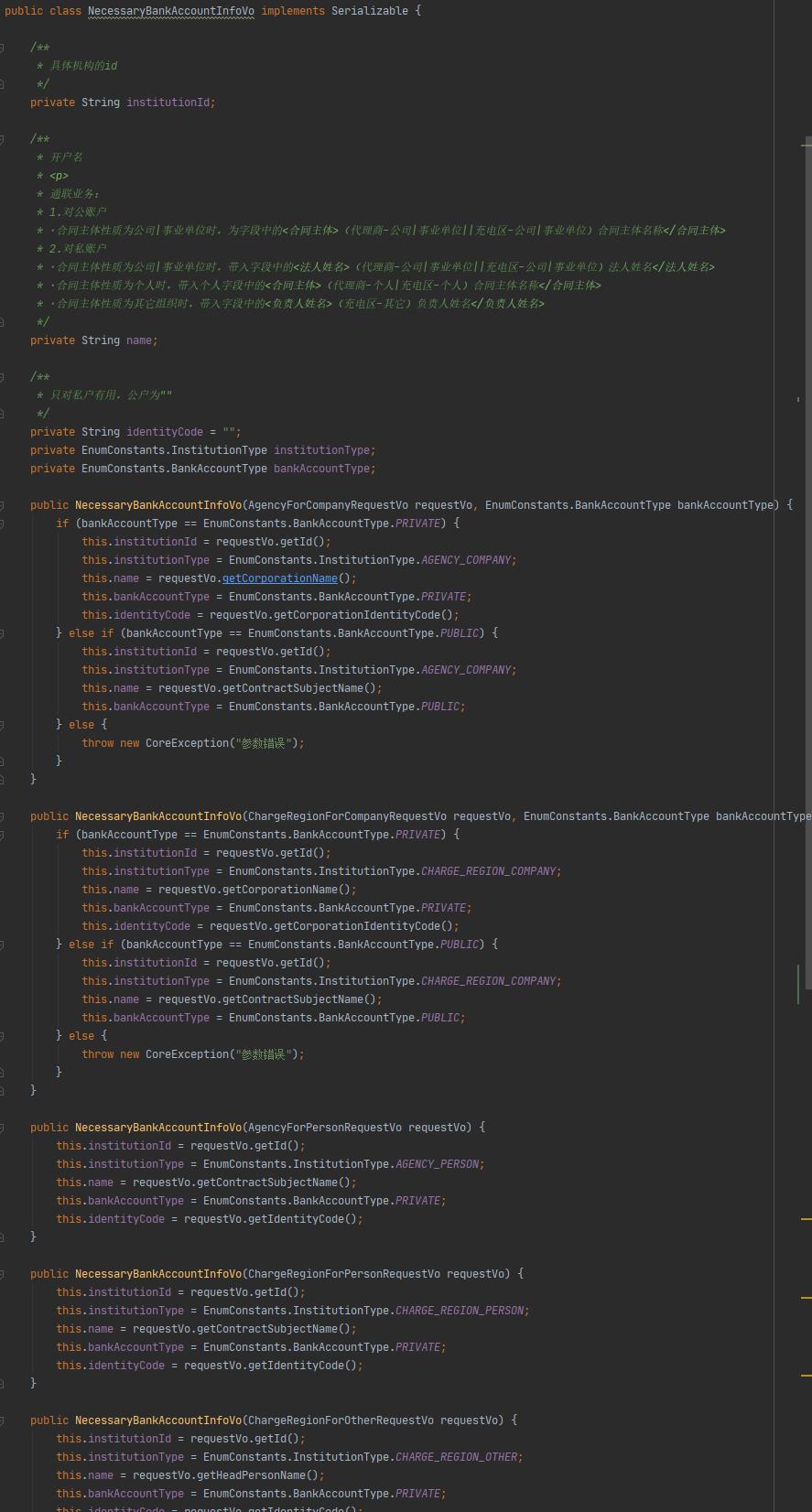
在编写过程中,第一个版本是直接在大方法中实现的,似乎因为规则的不同和类别的差异存在,无法将其抽象为一个具体的方法来处理。但是后期的维护一旦有相关的变化出现,就需要到所有的机构类中找到代码块修改,维护困难,容易产生bug。
后来提取出了一个方法,但是这个方法的参数是比较多的,那么在调用时我们可能就要牢记各个机构类别的差异,在填入参数时,需要根据类别输入不同的字段内容。即便在后来,将输入参数抽取为一个类时,也没有根本改观规则变化多处更改的尴尬局面。
直到现阶段的如图版本,不再在各个机构类中处理这些逻辑,通过接受不同类的输入VO,到DTO类的内部直接处理。此时,我们看到所有规则相关的逻辑就承载到了DTO内部,这就方便我们几种处理了。可以想象,后期的维护难度会降低很多。
4.比较setXXXInfo和构造方法
在处理DTO内部接收参数的过程中,其实还是有些小技巧。如一开始为了区分DTO输入参数的来源,会刻意地将方法名称设置为:
...
setBaseInfoFromAgencyCompany(AgencyForCompanyRequestVo requestVo);
setBaseInfoFromChargeRegionPerson(ChargeRegionForCompanyRequestVo requestVo);
...
而后在各自的机构类中调用各自的方法。但是这在调用过程中也是会带来不便的,比如这里有五个机构种类,那么我们调用时要仔细分辨我们的调用是否是对应到了各自机构上,没有做到调用过程中的易用性。
所以此时,我们可以使用统一的方法名称,但是参数类别上做出区别。通过这种重载,极大地方便使用者进行调用。

此时,外部的调用应该是以下模式:
... NecessaryBankAccountInfoVo vo = new NecessaryBankAccountInfoVo(); vo.setBaseInfo(requestVo); //通过vo中的字段数据对bankAccountEntity进行补充 institutionManager.doSomething(bankAccountEntity, vo); ...
如果是使用了构造函数完成这一过程,那么代码编写会更加方便,先看看构造函数处理的过程:
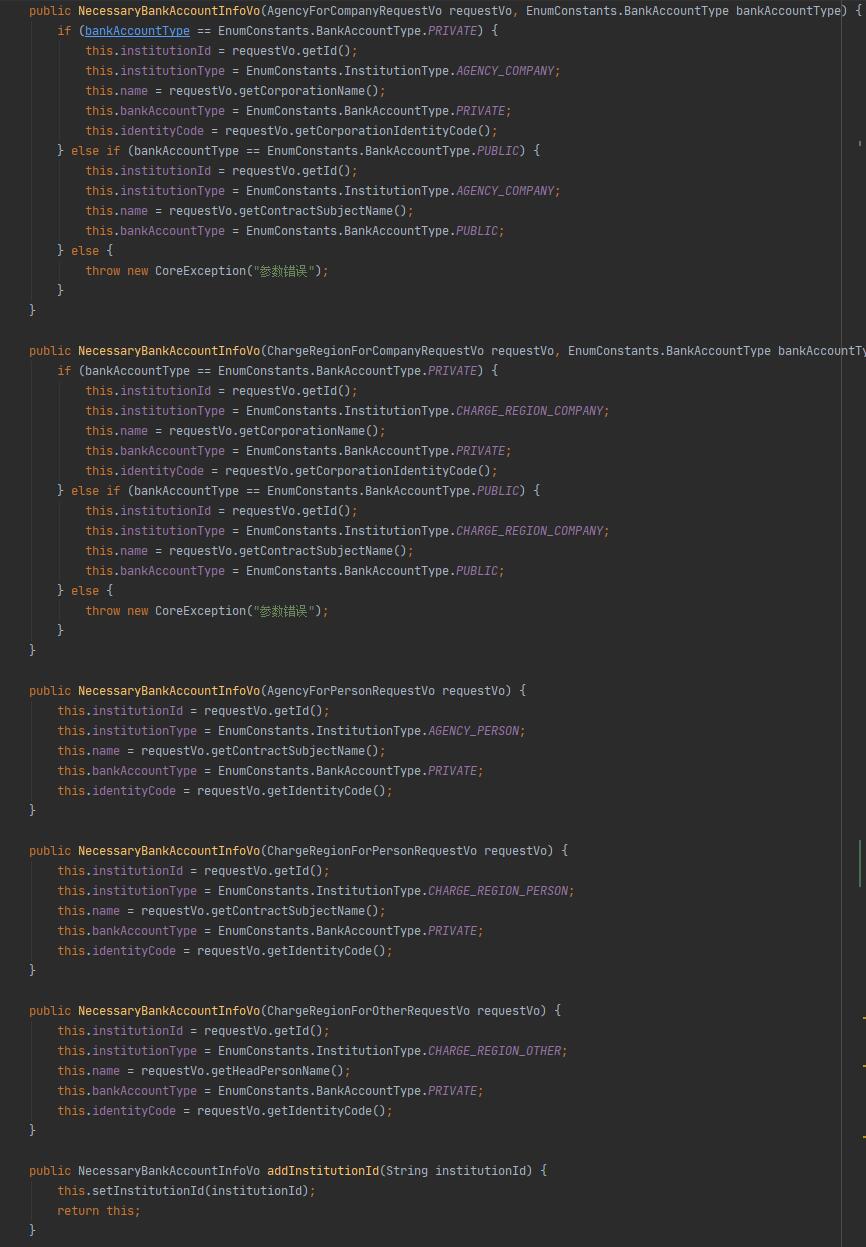
此时的调用代码变成了:
institutionManager.doSomething(bankAccountEntity, new NecessaryBankAccountInfoVo(requestVo));
5.builder模式
考虑一个场景,DTO中数据的来源requestVo少了个别字段的来源,或者说这些字段是可选的,可填可不填,那么builder就是一个比较好的模式。
比如在上述代码中,如果在使用requestVo中的字段初始化了NecessaryBankAccountInfoVo之后我们需要对其中个别字段进行更改,如果是额外增加方法来做这个事情,或者使用setter来处理,那么代码会变成这样:
... NecessaryBankAccountInfoVo vo = new NecessaryBankAccountInfoVo(requestVo); vo.setInstitutionId(savedInstitution.getId()); institutionManager.doSomething(bankAccountEntity, vo); ...
是不是很眼熟,跟最开始处理过程一样了,构造器的设置失去了我们简化代码的功能。此时如果我们采用builder模式,还是可以用一句搞定:
先在DTO中定义:
public NecessaryBankAccountInfoVo addInstitutionId(String institutionId) { this.setInstitutionId(institutionId); return this; }
调用处变成了:
institutionManager.doSomething(bankAccountEntity, new NecessaryBankAccountInfoVo(requestVo).addInstitutionId(savedInstitution.getId()));
6.在编写代码时,一处代码专心做一件事,不要既做A,又贪图方便完成B。一旦发现,要想想这里有没有办法只做一件事。
其实一次只做一件事这个概念我相信很多人都知道,但是实际编码中能有体会就是另外的事情了。这是一个意识问题。当出现了以下的情况,可能就需要考虑我们是不是在一个代码块中做了太多事情,导致代码的复杂度增加,后期维护难度变大了。
看以下代码:
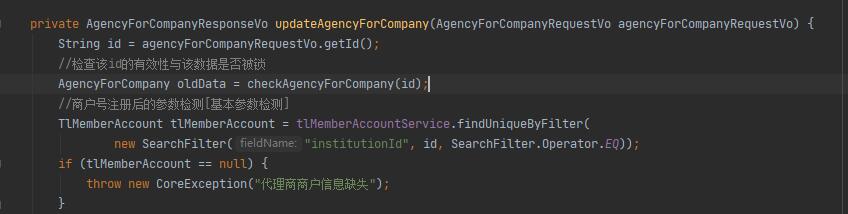
这里原本的意图是需要检查参数,但是这个过程中发生了一次查询,如果将这个查询结果封闭在了方法中,待后续进行处理时可能又要进行一次查询,增加了系统的开销。为了后续减少查询,这里在检查过程中就将检查结果返回。
如果整个方法的逻辑比较简单,这么处理也没有问题,但是这里后续涉及到多个实体类的数据更新,这样做就将查询和获取结果与后续的处理逻辑绑定在了一起。此时,我们使用第7点进行处理。
7.使用容器解耦对象的获取和针对对象的逻辑处理
Java提供了Collection体系,包含很多易用的容器。在我们处理对象时,这里根据场景提供一种思路,以在尽量少地去查询对象同时,也让整个代码的逻辑更为清晰(解耦了自然就清晰了)。每一块的代码与其它的内容完全解耦。
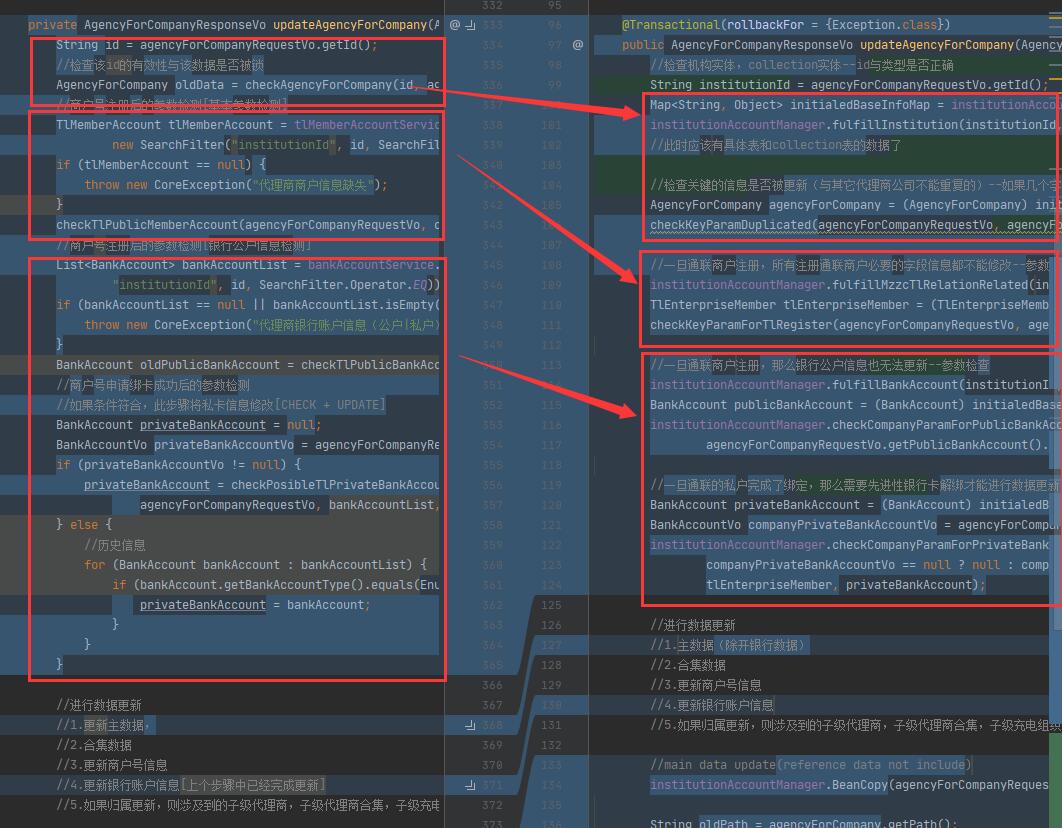
在新版本的代码中,我们在统一的InstitutionManager中处理相关对象的获取,存放在容器中,需要检查或者后续使用时直接从容器中获取。这里展示一部分获取时的代码:

其中根据机构分类分别做了处理,在外部各自类中调用时代码是基本一致的,如果后期机构的种类越来越多时,我们甚至可以在此基础上对整个update逻辑做一个接口,在接口中整体调用这个处理流程来进一步降低代码的重复度,提升维护便利性。
8.部分逻辑可以下放到db中完成。
在参数检查过程中,所有机构的合同主体名称和联系电话是不能与其它机构重复的。比较一下开始版本和现在版本处理这个问题的编码:
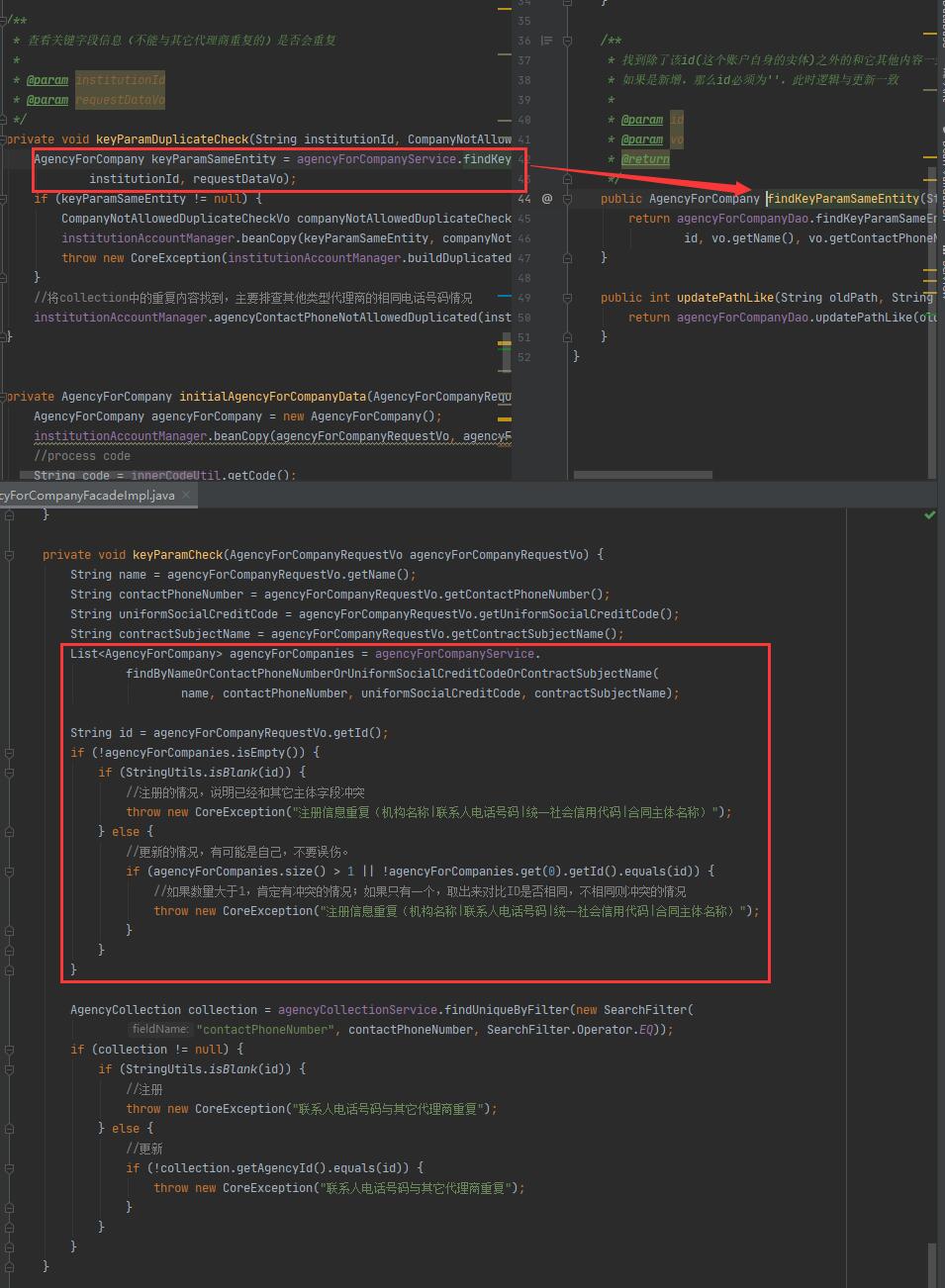
这里新版本的代码是将这个排除自身update重复了关键字段的逻辑放到了数据库查询语句中完成的:
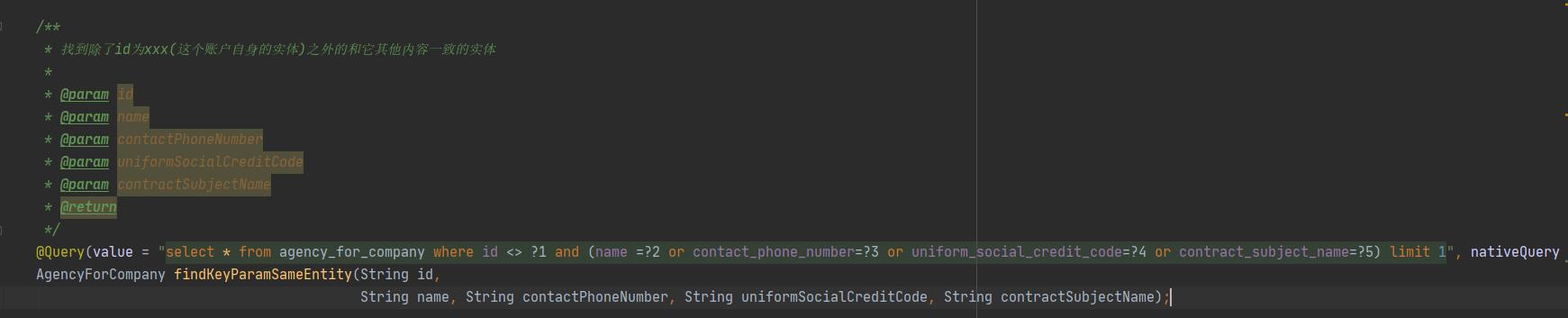
limit 1这种做法比之前查找所有的entity是更加推荐的,可以看到这里sql语句中已经将自身id的排除,所以只要找到不为null的结果,那么这个结果一定是其它机构的重复数据,代码的处理逻辑就会简单一些。准确把握当前的逻辑需要完成的任务,部分查询可以完成的逻辑任务交给db.query完成,下放多少逻辑,是否方便后续的维护,这些也是需要根据实际场景来进行协调。
9.对于一些小的细节好好把握。
细节把握好了很多时候会给我们信心和动力去做进一步的优化提升。如果对这些细节把握不到位,那么潜意识里可能就没有足够的信心和动力来做这件事情,就会低级低效的保守做法破坏了代码的性能或者是可维护性。
一旦遇到这样的场景,感觉可以做一些性能和可维护性的提升,但对于想实施的做法没有足够把握的时候,要告诉自己,了解这个细节的机会和场景来了。如果当时没空,那么把心里的疑惑记录下来,然后空闲时做实验、找资料进行研究。研究透彻以后这些便不再是障碍,相信我,如果当前不做这些事情,以后肯定还会再次面对这些问题的,久而久之就会麻木,放任自流了;另外在心态上,要敢于犯错,犯错才能对发生的问题印象深刻,解决之后所得来的印象比看资料看书来得更加深刻。遇到没把握的处理方式时,我倾向于先上了再说,如果是影响整个项目的重大处理方式,可以考虑一下如果这个路走不下去,有没有简单的有把握的办法能处理好。如果有,那么大胆用更优雅更好的但也许不那么有把握的办法,好好研究,做好测试,花一些时间犯一些错误,才能够让自己对技术细节的把握更进一步。