转载请注明出处:Java集合中List,Set以及Map等集合体系详解(史上最全)
概述:
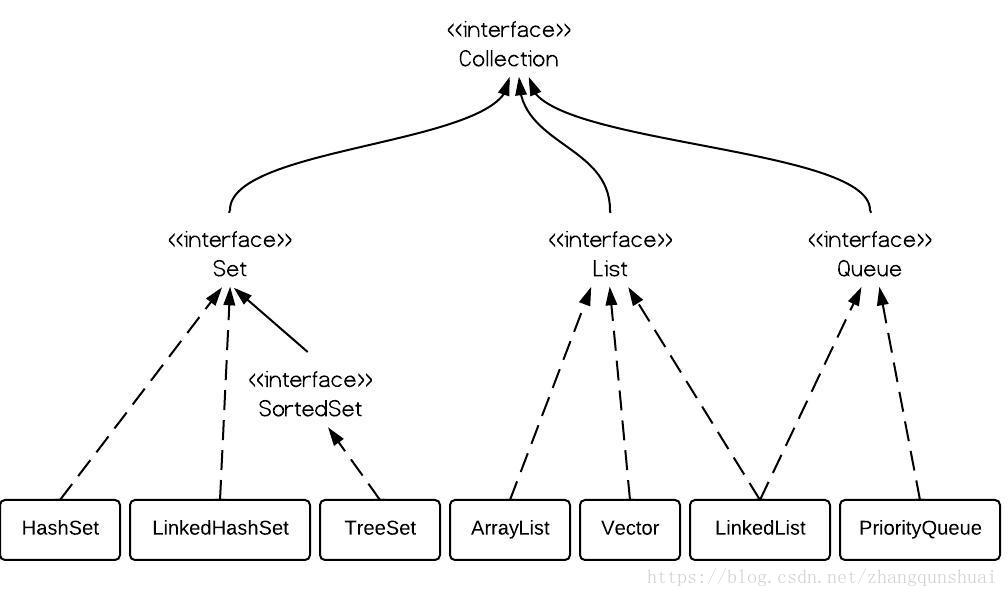
- List , Set, Map都是接口,前两个继承至Collection接口,Map为独立接口
- Set下有HashSet,LinkedHashSet,TreeSet
- List下有ArrayList,Vector,LinkedList
- Map下有Hashtable,LinkedHashMap,HashMap,TreeMap
- Collection接口下还有个Queue接口,有PriorityQueue类
注意:
-
Queue接口与List、Set同一级别,都是继承了Collection接口。
看图你会发现,LinkedList既可以实现Queue接口,也可以实现List接口.只不过呢, LinkedList实现了Queue接口。Queue接口窄化了对LinkedList的方法的访问权限(即在方法中的参数类型如果是Queue时,就完全只能访问Queue接口所定义的方法 了,而不能直接访问 LinkedList的非Queue的方法),以使得只有恰当的方法才可以使用。 -
SortedSet是个接口,它里面的(只有TreeSet这一个实现可用)中的元素一定是有序的。
总结:
Connection接口:
— List 有序,可重复
- ArrayList
优点: 底层数据结构是数组,查询快,增删慢。
缺点: 线程不安全,效率高 - Vector
优点: 底层数据结构是数组,查询快,增删慢。
缺点: 线程安全,效率低 - LinkedList
优点: 底层数据结构是链表,查询慢,增删快。
缺点: 线程不安全,效率高
—Set 无序,唯一
-
HashSet
底层数据结构是哈希表。(无序,唯一)
如何来保证元素唯一性?
1.依赖两个方法:hashCode()和equals() -
LinkedHashSet
底层数据结构是链表和哈希表。(FIFO插入有序,唯一)
1.由链表保证元素有序
2.由哈希表保证元素唯一 -
TreeSet
底层数据结构是红黑树。(唯一,有序)
1. 如何保证元素排序的呢?
自然排序
比较器排序
2.如何保证元素唯一性的呢?
根据比较的返回值是否是0来决定
针对Collection集合我们到底使用谁呢?(掌握)
唯一吗?
是:Set
排序吗?
是:TreeSet或LinkedHashSet
否:HashSet
如果你知道是Set,但是不知道是哪个Set,就用HashSet。
否:List
要安全吗?
是:Vector
否:ArrayList或者LinkedList查询多:ArrayList
增删多:LinkedList
如果你知道是List,但是不知道是哪个List,就用ArrayList。
如果你知道是Collection集合,但是不知道使用谁,就用ArrayList。
如果你知道用集合,就用ArrayList。
说完了Collection,来简单说一下Map.
Map接口:
上图:
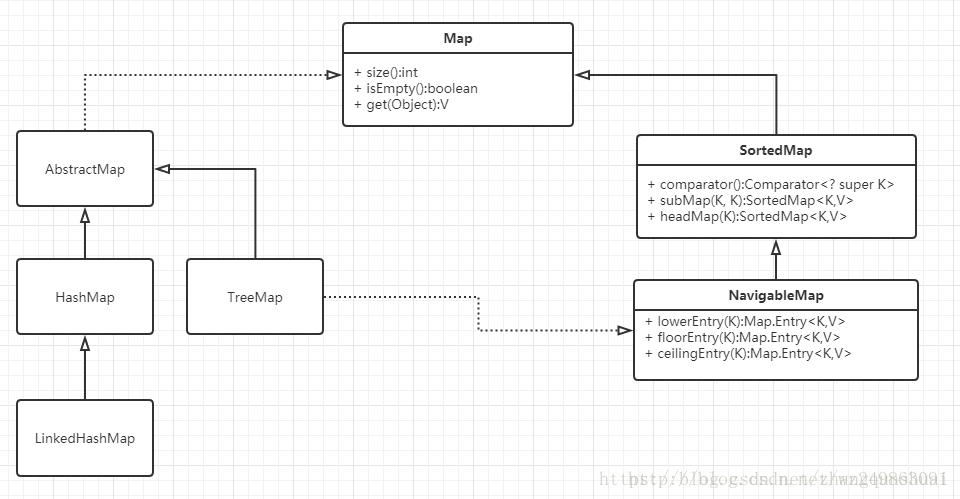
Map接口有三个比较重要的实现类,分别是HashMap、TreeMap和HashTable。
- TreeMap是有序的,HashMap和HashTable是无序的。
- Hashtable的方法是同步的,HashMap的方法不是同步的。这是两者最主要的区别。
这就意味着:
- Hashtable是线程安全的,HashMap不是线程安全的。
- HashMap效率较高,Hashtable效率较低。
如果对同步性或与遗留代码的兼容性没有任何要求,建议使用HashMap。 查看Hashtable的源代码就可以发现,除构造函数外,Hashtable的所有 public 方法声明中都有 synchronized关键字,而HashMap的源码中则没有。 - Hashtable不允许null值,HashMap允许null值(key和value都允许)
- 父类不同:Hashtable的父类是Dictionary,HashMap的父类是AbstractMap
重点问题重点分析:
(一).TreeSet, LinkedHashSet and HashSet 的区别
1. 介绍
- TreeSet, LinkedHashSet and HashSet 在java中都是实现Set的数据结构
- TreeSet的主要功能用于排序
- LinkedHashSet的主要功能用于保证FIFO即有序的集合(先进先出)
- HashSet只是通用的存储数据的集合
2. 相同点
- Duplicates elements: 因为三者都实现Set interface,所以三者都不包含duplicate elements
- Thread safety: 三者都不是线程安全的,如果要使用线程安全可以Collections.synchronizedSet()
3. 不同点
- Performance and Speed: HashSet插入数据最快,其次LinkHashSet,最慢的是TreeSet因为内部实现排序
- Ordering: HashSet不保证有序,LinkHashSet保证FIFO即按插入顺序排序,TreeSet安装内部实现排序,也可以自定义排序规则
- null:HashSet和LinkHashSet允许存在null数据,但是TreeSet中插入null数据时会报NullPointerException
4. 代码比较
public static void main(String args[]) {
HashSet<String> hashSet = new HashSet<>();
LinkedHashSet<String> linkedHashSet = new LinkedHashSet<>();
TreeSet<String> treeSet = new TreeSet<>();
for (String data : Arrays.asList("B", "E", "D", "C", "A")) {
hashSet.add(data);
linkedHashSet.add(data);
treeSet.add(data);
}
//不保证有序
System.out.println("Ordering in HashSet :" + hashSet);
//FIFO保证安装插入顺序排序
System.out.println("Order of element in LinkedHashSet :" + linkedHashSet);
//内部实现排序
System.out.println("Order of objects in TreeSet :" + treeSet);
}
运行结果:
Ordering in HashSet :[A, B, C, D, E] (无顺序)
Order of element in LinkedHashSet :[B, E, D, C, A] (FIFO插入有序)
Order of objects in TreeSet :[A, B, C, D, E] (排序)
(二).TreeSet的两种排序方式比较
1.排序的引入(以基本数据类型的排序为例)
由于TreeSet可以实现对元素按照某种规则进行排序,例如下面的例子
public class MyClass {
public static void main(String[] args) {
// 创建集合对象
// 自然顺序进行排序
TreeSet<Integer> ts = new TreeSet<Integer>();
// 创建元素并添加
// 20,18,23,22,17,24,19,18,24
ts.add(20);
ts.add(18);
ts.add(23);
ts.add(22);
ts.add(17);
ts.add(24);
ts.add(19);
ts.add(18);
ts.add(24);
// 遍历
for (Integer i : ts) {
System.out.println(i);
}
}
}
运行结果:
17
18
19
20
22
23
24
2.如果是引用数据类型呢,比如自定义对象,又该如何排序呢?
测试类:
public class MyClass {
public static void main(String[] args) {
TreeSet<Student> ts=new TreeSet<Student>();
//创建元素对象
Student s1=new Student("zhangsan",20);
Student s2=new Student("lis",22);
Student s3=new Student("wangwu",24);
Student s4=new Student("chenliu",26);
Student s5=new Student("zhangsan",22);
Student s6=new Student("qianqi",24);
//将元素对象添加到集合对象中
ts.add(s1);
ts.add(s2);
ts.add(s3);
ts.add(s4);
ts.add(s5);
ts.add(s6);
//遍历
for(Student s:ts){
System.out.println(s.getName()+"-----------"+s.getAge());
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
Student.java:
public class Student {
private String name;
private int age;
public Student() {
super();
// TODO Auto-generated constructor stub
}
public Student(String name, int age) {
super();
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}
结果报错:
原因分析:
由于不知道该安照那一中排序方式排序,所以会报错。
解决方法:
1.自然排序
2.比较器排序

(1).自然排序
自然排序要进行一下操作:
1.Student类中实现 Comparable接口
2.重写Comparable接口中的Compareto方法
compareTo(T o) 比较此对象与指定对象的顺序。
- 1
public class Student implements Comparable<Student>{
private String name;
private int age;
public Student() {
super();
// TODO Auto-generated constructor stub
}
public Student(String name, int age) {
super();
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public int compareTo(Student s) {
//return -1; //-1表示放在红黑树的左边,即逆序输出
//return 1; //1表示放在红黑树的右边,即顺序输出
//return o; //表示元素相同,仅存放第一个元素
//主要条件 姓名的长度,如果姓名长度小的就放在左子树,否则放在右子树
int num=this.name.length()-s.name.length();
//姓名的长度相同,不代表内容相同,如果按字典顺序此 String 对象位于参数字符串之前,则比较结果为一个负整数。
//如果按字典顺序此 String 对象位于参数字符串之后,则比较结果为一个正整数。
//如果这两个字符串相等,则结果为 0
int num1=num==0?this.name.compareTo(s.name):num;
//姓名的长度和内容相同,不代表年龄相同,所以还要判断年龄
int num2=num1==0?this.age-s.age:num1;
return num2;
}
}运行结果:
lis-----------22
qianqi-----------24
wangwu-----------24
chenliu-----------26
zhangsan-----------20
zhangsan-----------22
(2).比较器排序
比较器排序步骤:
1.单独创建一个比较类,这里以MyComparator为例,并且要让其继承Comparator接口
2.重写Comparator接口中的Compare方法
compare(T o1,T o2) 比较用来排序的两个参数。
- 1
3.在主类中使用下面的 构造方法
TreeSet(Comparator<? superE> comparator)
构造一个新的空 TreeSet,它根据指定比较器进行排序。
- 1
- 2
测试类:
public class MyClass {
public static void main(String[] args) {
//创建集合对象
//TreeSet(Comparator<? super E> comparator) 构造一个新的空 TreeSet,它根据指定比较器进行排序。
TreeSet<Student> ts=new TreeSet<Student>(new MyComparator());
//创建元素对象
Student s1=new Student("zhangsan",20);
Student s2=new Student("lis",22);
Student s3=new Student("wangwu",24);
Student s4=new Student("chenliu",26);
Student s5=new Student("zhangsan",22);
Student s6=new Student("qianqi",24);
//将元素对象添加到集合对象中
ts.add(s1);
ts.add(s2);
ts.add(s3);
ts.add(s4);
ts.add(s5);
ts.add(s6);
//遍历
for(Student s:ts){
System.out.println(s.getName()+"-----------"+s.getAge());
}
}
}Student.java:
public class Student {
private String name;
private int age;
public Student() {
super();
// TODO Auto-generated constructor stub
}
public Student(String name, int age) {
super();
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}
MyComparator类:
public class MyComparator implements Comparator<Student> {
@Override
public int compare(Student s1,Student s2) {
// 姓名长度
int num = s1.getName().length() - s2.getName().length();
// 姓名内容
int num2 = num == 0 ? s1.getName().compareTo(s2.getName()) : num;
// 年龄
int num3 = num2 == 0 ? s1.getAge() - s2.getAge() : num2;
return num3;
}
}
运行结果:
lis-----------22
qianqi-----------24
wangwu-----------24
chenliu-----------26
zhangsan-----------20
zhangsan-----------22
(三). 性能测试
对象类:
class Dog implements Comparable<Dog> {
int size;
public Dog(int s) {
size = s;
}
public String toString() {
return size + "";
}
@Override
public int compareTo(Dog o) {
//数值大小比较
return size - o.size;
}
}主类:
public class MyClass {
public static void main(String[] args) {
Random r = new Random();
HashSet<Dog> hashSet = new HashSet<Dog>();
TreeSet<Dog> treeSet = new TreeSet<Dog>();
LinkedHashSet<Dog> linkedSet = new LinkedHashSet<Dog>();
// start time
long startTime = System.nanoTime();
for (int i = 0; i < 1000; i++) {
int x = r.nextInt(1000 - 10) + 10;
hashSet.add(new Dog(x));
}
// end time
long endTime = System.nanoTime();
long duration = endTime - startTime;
System.out.println("HashSet: " + duration);
// start time
startTime = System.nanoTime();
for (int i = 0; i < 1000; i++) {
int x = r.nextInt(1000 - 10) + 10;
treeSet.add(new Dog(x));
}
// end time
endTime = System.nanoTime();
duration = endTime - startTime;
System.out.println("TreeSet: " + duration);
// start time
startTime = System.nanoTime();
for (int i = 0; i < 1000; i++) {
int x = r.nextInt(1000 - 10) + 10;
linkedSet.add(new Dog(x));
}
// end time
endTime = System.nanoTime();
duration = endTime - startTime;
System.out.println("LinkedHashSet: " + duration);
}
}
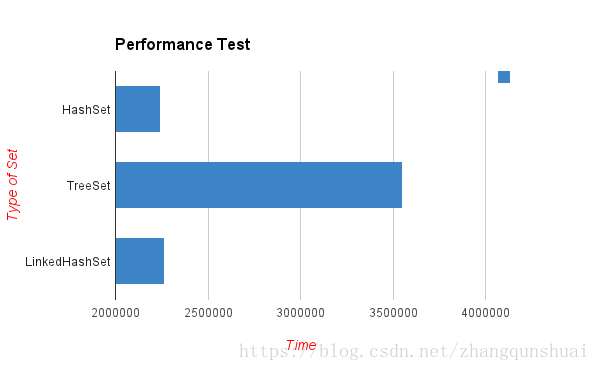
运行结果:
HashSet: 1544313
TreeSet: 2066049
LinkedHashSet: 629826
虽然测试不够准确,但能反映得出,TreeSet要慢得多,因为它是有序的。
数据结构解析-HashTable
概要
HashTable也是散列表的一种实现,我们在上一篇解析了HashMap,在这里我们与HashMap做个对比,让你能清晰的了解两者的区别:
| 散列表 | 实现方式 | 数据安全 | 数据安全实现方式 | keyvalue是否可为Null |
|---|---|---|---|---|
| HashMap | 数组+单向链表+红黑树 | 不安全 | 无 | 可为Null |
| HashTable | 数组+单向链表 | 安全 | Synchronized | 不可为 Null |
HashTable
1.继承关系
public class Hashtable<K,V>
extends Dictionary<K,V>
implements Map<K,V>, Cloneable, java.io.Serializable
2.常量&构造方法

/**
* The hash table data.
*/
private transient HashtableEntry<?,?>[] table;
//HashTable条目数总量
private transient int count;
//下次扩容量
private int threshold;
//负载因子
private float loadFactor;
//修改次数
private transient int modCount = 0;
//默认的构造函数
public Hashtable() {
this(11, 0.75f);
}
//指定容量大小
public Hashtable(int initialCapacity) {
this(initialCapacity, 0.75f);
}
//指定容量大小和负载因子大小
public Hashtable(int initialCapacity, float loadFactor) {
//指定的容量大小不可以小于0,否则将抛出IllegalArgumentException异常
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
////指定的负载因子不可以小于0或为Null,若判定成立则抛出IllegalArgumentException异常
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal Load: "+loadFactor);
//若指定的容量大小为0,则赋为1 即容量初始大小最小为 1
if (initialCapacity==0)
initialCapacity = 1;
this.loadFactor = loadFactor;
//声明table实例
table = new HashtableEntry<?,?>[initialCapacity];
//下次扩容量长度
threshold = (int)Math.min(initialCapacity, MAX_ARRAY_SIZE + 1);
}
//传入一个Map集合,将Map集合中元素Map.Entry全部添加进HashTable实例中
public Hashtable(Map<? extends K, ? extends V> t) {
this(Math.max(2*t.size(), 11), 0.75f);
putAll(t);
}
3.HashtableEntry单向链表的实现
private static class HashtableEntry<K,V> implements Map.Entry<K,V> {
// END Android-changed: Renamed Entry -> HashtableEntry.
final int hash;
final K key;
V value;
HashtableEntry<K,V> next;
//构造函数
protected HashtableEntry(int hash, K key, V value, HashtableEntry<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
@SuppressWarnings("unchecked")
protected Object clone() {
return new HashtableEntry<>(hash, key, value,
(next==null ? null : (HashtableEntry<K,V>) next.clone()));
}
// Map.Entry Ops
//获取key
public K getKey() {
return key;
}
//获取value
public V getValue() {
return value;
}
//设置value
public V setValue(V value) {
if (value == null)
throw new NullPointerException();
V oldValue = this.value;
this.value = value;
return oldValue;
}
//equals对比
public boolean equals(Object o) {
if (!(o instanceof Map.Entry))
return false;
Map.Entry<?,?> e = (Map.Entry<?,?>)o;
return (key==null ? e.getKey()==null : key.equals(e.getKey())) &&
(value==null ? e.getValue()==null : value.equals(e.getValue()));
}
//获取hash值
public int hashCode() {
return hash ^ Objects.hashCode(value);
}
public String toString() {
return key.toString()+"="+value.toString();
}
}
4.Hashtable put函数源码实现
//这里使用Synchronized锁方法的方式来保证put方法的在多线程下的数据安全
public synchronized V put(K key, V value) {
// 确定value值不可为null
if (value == null) {
throw new NullPointerException();
}
// 确定key已经在table中存在
HashtableEntry<?,?> tab[] = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
@SuppressWarnings("unchecked")
HashtableEntry<K,V> entry = (HashtableEntry<K,V>)tab[index];
//通过for循环,查找符合条件的key,赋予新的Value
for(; entry != null ; entry = entry.next) {
if ((entry.hash == hash) && entry.key.equals(key)) {
V old = entry.value;
entry.value = value;
return old;
}
}
//添加新的Entry
addEntry(hash, key, value, index);
return null;
}
private void addEntry(int hash, K key, V value, int index) {
//修改次数+1
modCount++;
HashtableEntry<?,?> tab[] = table;
//如果HashTable的子条目大小 大于 下次扩容大小
if (count >= threshold) {
// 如果超过阈值,则重新组织HashTable 即对HashTable进行扩容
rehash();
tab = table;
hash = key.hashCode();
index = (hash & 0x7FFFFFFF) % tab.length;
}
// Creates the new entry.
@SuppressWarnings("unchecked")
//将tab中索引位置下的Entry赋予 e
HashtableEntry<K,V> e = (HashtableEntry<K,V>) tab[index];
//创建新的HashtableEntry赋予tab中索引位置
tab[index] = new HashtableEntry<>(hash, key, value, e);
//table的条目树+1
count++;
}
梳理以下HashTable.put函数的执行过程
- 1.确定value值不可为null
- 2.若key已经在table中存在,通过for循环,查找符合条件的key,赋予新的Value 返回 旧值
- 3.若不存在则进行新增操作;
- 3.1 修改次数+1,判断HashTable是否需要扩容
- 3.2 获取tab索引下的Entry 赋给 e
- 3.3 创建一个HashTableEntry赋给tab指定索引位置
- 3.4 tab的条目数 +1
5.Hashtable get函数源码实现
//这里使用Synchronized 锁方法的方式来保证get函数在多线程下的数据安全
public synchronized V get(Object key) {
HashtableEntry<?,?> tab[] = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
//通过for循环来查找如何条件的value
for (HashtableEntry<?,?> e = tab[index] ; e != null ; e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
return (V)e.value;
}
}
return null;
}
6.Hashtable rehash函数源码实现
protected void rehash() {
int oldCapacity = table.length;
HashtableEntry<?,?>[] oldMap = table;
// 旧表长度 二进制左移1位+1 当作新表的长度
int newCapacity = (oldCapacity << 1) + 1;
if (newCapacity - MAX_ARRAY_SIZE > 0) {
if (oldCapacity == MAX_ARRAY_SIZE)
// Keep running with MAX_ARRAY_SIZE buckets
return;
newCapacity = MAX_ARRAY_SIZE;
}
HashtableEntry<?,?>[] newMap = new HashtableEntry<?,?>[newCapacity];
//修改次数+1
modCount++;
//记录下次扩容量
threshold = (int)Math.min(newCapacity * loadFactor, MAX_ARRAY_SIZE + 1);
//将新表赋予当前操作表
table = newMap;
//通过for循环将旧表数据赋予新表中
for (int i = oldCapacity ; i-- > 0 ;) {
//通过for循环遍历老表索引下的节点数据,赋予新表中
for (HashtableEntry<K,V> old = (HashtableEntry<K,V>)oldMap[i] ; old != null ; ) {
HashtableEntry<K,V> e = old;
//将老表的下一个节点重新赋给old
old = old.next;
int index = (e.hash & 0x7FFFFFFF) % newCapacity;
e.next = (HashtableEntry<K,V>)newMap[index];
//赋予新表的指定索引位置
newMap[index] = e;
}
}
}
结束分析
- 通过上面的分析我们可以清楚地知道,HashTable的put函数和get函数在多线程下可以保证数据安全,实现方式都是使用Synchronized 同步锁 锁方法的方式实现的,而相对于HashMap是没有采取任何方式保证数据安全,所以HashMap在多线程下无法保证数据安全.
- 也同样由于HashTable采用Synchronized同步锁 锁方法方式 锁住了整个table保证数据安全,在多线程竞争激烈的情况下效率非常低;因为线程访问同步时,其他线程访问HashTable的同步方法时可能会进入阻塞或轮询状态.
好了,至此完结.小伙伴有问题的话,请留言