设计模式之美 已经将设计模式讲的很详细了,不过其代码稍显枯燥——本篇提供了更多生动的示例,以及个人对相关模式的思考。
参考:
- 《大话设计模式》
- 《设计模式之禅》
1. 创建型
1.1. 工厂模式
Factory Method,别名:Virtual Constructor(虚拟构造器)

工厂模式,就是把对象的创建封装在一个工厂类中实现。相比于直接使用 new Object(),封装可以添加对象创建的逻辑控制,并且隐藏细节。具体而言,其适用于以下情形:
- 需要动态创建实例对象时:
- 当一个类不知道它所必须创建的对象的类的时候。
- 当一个类希望由它的子类来指定它所创建的对象的时候。
- 系统需要对客户端隐藏创建实例的细节过程(实现封装)时。
1.1.1. 从简单工厂说起
首先定义了 AbstractProduct 和 ConcreteProduct:
interface ICar{
void run();
}
class BenzCar: ICar{
public void run(){ Log.print("奔驰"); }
}
class HummerCar: ICar{
public void run(){ Log.print("悍马"); }
}
接下来是创建简单工厂:
class CarSimpleFactory{
public ICar build_car(string type){
if(type == "Benz"){
return new BenzCar();
}else if(type == "Hummer"){
return new HummerCar();
}else throw new Exception();
}
}
于是乎,客户端是简化的:
var simple_factory = new CarSimpleFactory();
var car = simple_factory.build_car("Hummer");
car.run();
实际上,SimpleFactory::build_car() 方法封装了两组过程:
-
封装了对象的创建过程
ps: 这个步骤在示例中被简化了,实际上的 new 操作可能很复杂,例如享元模式里增加 HashTable 来检测是否实例化一个新的对象
-
产生哪个对象的逻辑判断,也就是 if...else...
因此,工厂模式才有理由对简单工厂“解耦”:分离这两组过程!
1.1.2. 工厂模式
简单工厂通过 SimpleFactory 实现了对象创建过程的封装,但问题来了:当 ConcreteProduct 需要扩展的时候,简单工厂不符合开闭原则——你需要修改对象创建的逻辑代码(也就是那一组 if...else... 判断逻辑)。于是乎通过 “工厂模式” 实现解耦——将那一组 if...else... 判断逻辑拎出来,在客户端实现,而 ConcreteFactory 的工作仅仅是封装对象创建的过程:
interface IFactory{
ICar build_car();
}
class BenzFactory: IFactory{
// ConcreteProduct 的工作单一化:封装对象的创建流程
public ICar build_car(){
return new BenzCar();
}
}
class HummerFactory: IFactory{
public ICar build_car(){
return new HummerCar();
}
}
而将判断逻辑交给客户端实现(于是乎,在客户端里可以继续拓展 ConcreteProduct):
class Demo{
/*-----------------------------------------------------------------*
工厂类拓展
*-----------------------------------------------------------------*/
class FutureCar: ICar{
public void run(){
Log.print("未来汽车:你想象不到的样子");
}
}
class FutureFactory: IFactory{
public ICar build_car(){
return new FutureCar();
}
}
// Client
static void Main(){
var simple_factory = new CarSimpleFactory();
var car = simple_factory.build_car("Hummer");
car.run();
// 创建哪个对象的逻辑判断,解耦到了客户端实现,因而可以不断的拓展 else if 语句
var type_runtime = "21-century";
if (type_runtime == "21-century"){ // 当你拓展ICar子类时,你不需要改写原有代码的逻辑(而简单工厂则不然)
var factory = new FutureFactory();
var car2 = factory.build_car();
car2.run();
}
// else if(type_runtime == "Benz"){ } ...
}
}
我一直觉得工厂模式的解耦方式是丑陋的——当你需要增加一个产品实现,你必须新创建两个类:ConcreteNewProduct 和 ConcreteNewFacotry。
1.1.3. 再思考
简单工厂真的无法应对拓展了吗?个人觉得答案未必:
class Demo{
/*-----------------------------------------------------------------*
工厂类拓展
*-----------------------------------------------------------------*/
class FutureCar: ICar{
public void run(){
Log.print("未来汽车:你想象不到的样子");
}
}
/*-----------------------------------------------------------------*
简单工厂的优化
*-----------------------------------------------------------------*/
class NewSimpleFactory{
private CarSimpleFactory old_factory = new CarSimpleFactory();
public ICar build_car(string type){ // no need to override
if(type == "21-century"){
return new FutureCar();
}else{
return old_factory.build_car(type);
}
}
}
static void Main(){
var type_runtime = "21-century";
// Here, we try to update the SimpleFactory
var simple_factory2 = new NewSimpleFactory();
var car3 = simple_factory2.build_car(type_runtime);
car3.run();
}
}
的确,简单工厂的类库仅实现了自身对现有 ConcreteProduct 库的判断封装,但个人认为,这也比没有封装要好。而没有理由说,客户端拓展了产品类库,却不去拓展 Facoty 的判断条件。可以认为,这种对 SimpleFactory 的拓展是对 Factory Method 思路的一种延续—— NewSimpleFactory 仅仅实现了对 “条件判断” 的二次封装(这也算是对 SimpleFacotry 两个组合功能的解耦吧),重要的是,它重用了简单工厂对原类库的产品对象创建过程的封装,同时也没有引入 Factory Method 不断创建新工厂的臃肿。
1.1.4. 继续思考
如上所述,我们统一的对 SimpleFactory 的问题作以修复:
- 将产品的创建流程封装成独立方法(且统一为相同一个接口);
- 封装了创建已知产品的判断逻辑;
- 新产品的逻辑判断的拓展接口,以钩子方法的形式提供;
- 如果你愿意,你甚至可以结合装饰模式,将 AdvancedSimpleFactory 作为一个装饰类,动态地给 DecoupleFactory 拓展功能。
/*-----------------------------------------------------------------*
解耦的简单工厂
*-----------------------------------------------------------------*/
class DecoupleFactory{
// 对单个产品创建流程的封装
public virtual BenzCar build_benz(){
return new BenzCar();
}
public virtual HummerCar build_hummer(){
return new HummerCar();
}
public ICar build_car(string type){ // 封装了创建已知产品的判断逻辑
if(type == "Benz")
return this.build_benz();
else if(type == "Hummer")
return this.build_hummer();
else
return this.build_car_extend(type); // 提供拓展产品的逻辑判断接口
}
public virtual ICar build_car_extend(string type){ // 空实现/默认实现
throw new Exception($"未知的car类型:{type}");
}
}
class Demo{
/*-----------------------------------------------------------------*
产品线拓展
*-----------------------------------------------------------------*/
class FutureCar: ICar{
public void run(){
Log.print("未来汽车:你想象不到的样子");
}
}
/*-----------------------------------------------------------------*
简单工厂的再优化:拓展工厂内部判断逻辑
*-----------------------------------------------------------------*/
class AdvancedSimpleFactory: DecoupleFactory{
// 封装新产品的创建流程
public FutureCar build_future_car(){
return new FutureCar();
}
// 重写钩子方法
public override ICar build_car_extend(string type){
if(type == "21-century")
return this.build_future_car();
else
return base.build_car_extend(type);
}
}
// Client
static void Main(){
var type_runtime = "21-century";
// 对 AdvancedSimpleFactory 的应用
var decouple_factory = new AdvancedSimpleFactory();
var car4 = decouple_factory.build_car(type_runtime);
car4.run();
}
}
1.1.5. 新的思考
随着语言表达力的进一步提升,简单工厂实现了升级,我们来看下 Python 实现简单工厂的方式:
class SimpleFactory:
""" 通过eval(),将strType构造为一个对象 """
def build_car(self, car_type):
""" 当然,这里只适用于简单的对象创建 """
return eval(car_type)()
class DictFactory:
""" 通过回调,动态加载构造函数 """
def __init__(self):
self.map_type = {
"Hummer": self.build_hummer,
"Benz": self.build_benz,
}
def build_hummer(self):pass
def build_benz(self):pass
def build_car(self, type: str):
return self.map_type[type]()
if __name__ == "__main__":
class FutureCar:
def run(self):
print("未来汽车:你想象不到的样子")
factory = SimpleFactory()
car = factory.build_car("FutureCar")
car.run()
以上其实本质上还是工厂方法模式,只是利用回调的方式,让工厂模式的if...else...更加灵活。
同样,Java 也提供了相似的模式:
class SimpleFactory{
public <T extends Car> T build_car(Class<T> car){
return (T)Class.forName(car.getName()).newInstance();
}
}
1.1.6. 总结
工厂模式的核心有两点:
- 使用 build_instance() 来封装一个class实例化的过程。
- 使用 factory_create() 来封装对多种产品的选择流程,这个过程可以写死(简单工厂),也可以保留到客户端进行(工厂方法),或者通过回调方式(参数或字典)动态传入构造方法。
1.1.7. 相关模式
由于工厂模式可以实现对象创建过程的控制,于是 “享元”(池技术)模式、“单例” 模式都可以套用工厂模式实现。
1.2. 建造者模式
Builder

在以下情况下可以使用 Builder 模式:
- 当创建复杂对象的算法应该独立于该对象的组成部分以及它们的装配方式时。
- 当构造过程必须允许被构造的对象有不同的表示时。
从本质上说,创建型模式都是对 new 操作的封装——但封装就会产生耦合。相比于工厂模式解耦了 “多种对象 选择性实例化的判断条件”——将逻辑过程独立于 Product / Factory 之外,只是实现了对象创建过程的封装;而建造者,解决的就是对象创建流程的耦合——当然是部分的解耦,封装还是要有的(毕竟处理的是复杂对象,否则直接操作对象就结了)。
建造者的核心操作,是将对象的创建流程分解为多个步骤,并提供控制接口,使外部可以实现对创建步骤的自由组合,乃至重写 build 方法。
举个例子,要组装一台电脑,它的组装过程基本是不变的,都可以由主板、CPU、内存等按照某个稳定方式组合而成。然而主板、CPU、内存等零件本身都是可能多变的。将内存等这种易变的零件与电脑的其他部件分离,实现解耦合,则可以轻松实现电脑不断升级。
装CPU、装内存条、装主板...这就是IBuilder提供的接口,而不同品牌的内存条,就是产品。由于产品不同,一台组装机(ConcreteBuilder)的各个接口实现也就不尽相同。至于Director,似乎无关紧要了,就当做是client即可。
1.2.1. 总结
建造者的核心,就是把一个整体的构造过程(construct函数),分解成多个步骤(method),目的在于,子类根据自身产品的变化,重写其中的一部分(step)。一般的,我们在设计之初都是一个函数写到底(出于封装的要求,也没毛病),但后面考虑到子类的衍生,需要拆分函数,使代码片段支持重写,同时保留整体流程。那么自热而然,你就用上了建造者模式。
可以说,建造者模式有点事后诸葛的味道,在设计之初,没有太多的参考意义。
1.3. 抽象工厂
Abstract Factory,别名:Kit
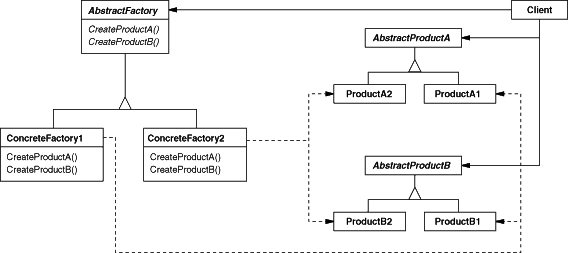
1.3.1. 问题导入
引自《大话设计模式》
这是一个现实的故事,我们正在管理一个 “MySQL” 数据库。数据库对象有很多,包括数据库文件、数据库表、视图以及每个数据项。他们都包括以下几个行为:创建、初始化、备份、删除等等。于是我们通过一个工厂模式,实现了不同的数据库对象的管理:
interface DatabaseObject{
void initialize();
void delete();
void backup();
void update();
}
class DatabaseFile: DatabaseObject{
public void initialize(){ }
public void delete(){ }
public void backup(){ }
public void update(){ }
}
class DatabaseTable: DatabaseObject{
public void initialize(){ Log.print("创建表"); }
public void delete(){ Log.print("删除表"); }
public void backup(){ }
public void update(){ }
}
class DatabaseView: DatabaseObject{
public void initialize(){ }
public void delete(){ }
public void backup(){ }
public void update(){ }
}
// 工厂方法,整合多个产品
class DatabaseObjectFactory{
public DatabaseObject create_object(string type){
if(type == "file")
return new DatabaseFile();
else if(type == "table")
return new DatabaseTable();
else if(type == "view")
return new DatabaseView();
else throw new Exception();
}
}
class Demo{
static void Main(){
var type_runtime = "table";
var factory = new DatabaseObjectFactory();
var product = factory.create_object(type_runtime);
product.initialize();
product.delete();
}
}
程序运行了几年之后,客户升级系统,其数据库软件从 MySQL 改为了 MariaDB。由于不同数据库的操作接口不同,这带来了巨大的麻烦……
1.3.2. 分析
实际上,我们的数据库管理程序(而不是 MySQL 这类数据库软件)包含两方面的职能:
- 客户端的逻辑,包含了客户端代码,以及现有的类结构(对象与对象之间的框架关系);
- 对 MySQL 数据库接口的封装,如 void DatabaseTable::delete(){ Log.print("删除表"); } 的代码——这部分与 MySQL 强耦合!
于是,更换数据库的关键调整就是解耦——解除 SQL 接口的强耦合,而尽可能保留原程序的框架。我们对简单工厂提炼一个抽象类,而 MySQL 的简单工厂是这个抽象的一种实现,同时我们为新的需求提供另外一种实现——这将产生两套并行的产品线(或者称为“产品族”)。
class DatabaseTable: DatabaseObject{
public virtual void initialize(){ Log.print("创建表"); }
public virtual void delete(){ Log.print("删除表"); }
public virtual void backup(){ }
public virtual void update(){ }
}
/*-----------------------------------------------------------------*
按产品族,派生不同的产品项
*-----------------------------------------------------------------*/
class MySQLTable: DatabaseTable{
public override void initialize(){ Log.print("MySQL 创建表"); }
public override void delete(){ Log.print("MySQL 删除表"); }
public override void backup(){ }
public override void update(){ }
}
class MariaDBTable: DatabaseTable{
public override void initialize(){ Log.print("MariaDB 创建表"); }
public override void delete(){ Log.print("MariaDB 删除表"); }
public override void backup(){ }
public override void update(){ }
}
/*-----------------------------------------------------------------*
按产品族,派生不同的产品线工厂
*-----------------------------------------------------------------*/
abstract class DatabaseObjectFactory{
public virtual DatabaseObject create_object(string type){
if(type == "file")
return this.create_dbfile();
else if(type == "table")
return this.create_table();
else if(type == "view")
return this.create_view();
else throw new Exception();
}
public abstract DatabaseObject create_dbfile();
public abstract DatabaseObject create_table();
public abstract DatabaseObject create_view();
}
class MySQLFactory: DatabaseObjectFactory{
public override DatabaseObject create_dbfile(){
return new MySQLTable();
}
public override DatabaseObject create_table(){
return new MySQLTable();
}
public override DatabaseObject create_view(){
return new MySQLTable();
}
}
class MariaDBFactory: DatabaseObjectFactory{
public override DatabaseObject create_dbfile(){
return new MariaDBTable();
}
public override DatabaseObject create_table(){
return new MariaDBTable();
}
public override DatabaseObject create_view(){
return new MariaDBTable();
}
}
class Demo{
static void Main(){
var type_runtime = "table";
var factory = new MariaDBFactory(); // 客户端根据需要,new一个特定的产品线工厂
var product = factory.create_object(type_runtime);
product.initialize();
product.delete();
}
}
这个过程很简单,就是在工厂模式的基础上,对各项产品和整个工厂,分别进行派生(各自派生出 MySQL 和 MariaDB 两套子类)。而客户端则根据需要,要么 new MySQLFactory(),要么 new MariaDBFactory() 。这个具体工厂的创建是手动进行的(当然也可以再封装一层,动态创建工厂——比如,根据现有数据库文件类型,传入 type_runtime 的参数)。
1.3.3. 总结
抽象工厂的目标,是提供与现有产品族并行的另一套产品线。一般的,单一的产品族是通过工厂模式创建的,而对单一产品线进行抽象,使多套具体的产品线针对同一个抽象类进行不同的实现(继承关系),就是抽象工厂提供的技巧。
同样的,对于多个Backend的算法框架,同样可以采用抽象工厂的设计模式:
- Keras.Backend 支持Tensorflow和Theano作为后端
- 个人的图形图像算法框架: MVLib.Backend 支持OpenCV、Pillow、Skimage作为后端
题外话,对于数据库的例子,在设计之初,当然没有必要同时开发MySQL与MarialDB两套或更多的数据库形式(用不到又何必白白的浪费精力去做代码实现),但框架设计还是很有必要的:至少有这样一个目标,就会以多后端的形式开发接口。这样即便后期添加MarialDB(再优秀的框架,也一定是会有冲突的,接口调整少不了),修改接口的时候也不会是天翻地覆!
1.4. 单例模式
Singleton
单例模式实际上是一组模式的合集,通过这些技巧都可以实现单例的效果(当然,这些方式里有些太普通,实在称不上是 “模式”~)。实际上,你甚至可以完全不用任何的模式或技巧,完全通过不同的状态变量(常见的是 bool,或者 int 类型),根据不同状态变量的组合方式,控制流程的精确运行。而单例,是最大程度上让你简化了控制的复杂度。
1.4.1. 饿汉式单例
class EagerSingleton_Static_Field{
private static EagerSingleton_Static_Field _instance = new EagerSingleton_Static_Field();
// the constructor should be protected or private
private EagerSingleton_Static_Field(){ }
public static EagerSingleton_Static_Field get_instance(){ return _instance; }
}
饿汉式单例的问题在于:静态成员变量是在程序运行之初就被系统创建的。如果对象的创建开销过大,但对象实际又一直未被使用时,静态对象的创建就没有意义。
1.4.2. 懒汉式单例
class LazySingleton_Static_Field{
private static LazySingleton_Static_Field _instance;
private LazySingleton_Static_Field(){ }
public static LazySingleton_Static_Field get_instance(){
if(_instance == null){
_instance = new LazySingleton_Static_Field(); // 动态创建对象
}
return _instance;
}
}
懒汉式单例的问题在于线程不安全:对于高并发环境时,初始化时已经有多个线程同时执行 get_instance(),由于判断条件为 _instance 对象的存在性,而创建对象是需要时间的。在这个时间差里,可能 if 被执行了多次。
解决方法很多:
-
最简单的,增加一个
bool量用于判断当前对象是否被创建,当然这个方式只是降低了风险(毕竟bool的赋值要比对象创建过程快很多)。 -
更标准的方式,比如创建同步锁,限制多进程对同一变量的访问。但这样的解决方案同样不够完美——它影响了并发的执行效率(当然对象创建也就是那么一刹那,也无可厚非)。所以这个方法不被推荐。
-
结合以上两种方式——双重同步锁。
public static Singleton Instance(){ // double-check locking if (_instance == null){ lock (_syncRoot){ if (_instance == null){ // 双重检查 // use lazy initialization _instance = new Singleton(); } } } return _instance; }很多人会认为这种办法是最佳的解决办法了,其实不是,这也是线程不安全的(由于JVM和CPU的优化中可能会执行指令重排,详见 知乎:用单例模式来讲讲线程安全)。
但反过来,如果真的那么在乎效率,就直接采用饿汉式模式吧——方案是需要取舍的!
1.4.3. 枚举模式
最推荐的是使用枚举类实现单例模式,这是线程安全的。JVM会保证枚举类中的构造方法只调用一次,因此使用枚举会保证只实例化一次。
public class SingletonExample6 {
// 私有构造函数
private SingletonExample6() { }
public static SingletonExample6 getInstance() {
return Singleton.INSTANCE.getInstance();
}
private enum Singleton {
INSTANCE;
private SingletonExample6 singleton;
// JVM保证这个方法绝对只调用一次
Singleton() {
singleton = new SingletonExample6();
}
public SingletonExample6 getInstance() {
return singleton;
}
}
}
1.4.4. 思考
关于单例的继承性
我常常想,能否定义一个单例的基类——如果构造函数和静态成员对象的可访问性均为 protected,是没理由不能继承的:
class Singleton_Base{
protected static Singleton_Base _instance = new Singleton_Base();
protected Singleton_Base(){ }
public static Singleton_Base get_instance(){ return _instance; }
}
class Singleton_Derived: Singleton_Base{
private bool flag = false;
protected Singleton_Derived(): base(){ }
protected static Singleton_Derived _instance2 = new Singleton_Derived();
public static Singleton_Derived get_instance2(){ return _instance2; }
}
class demo{
static void Main(){
var x = Singleton_Base.get_instance();
var y = Singleton_Derived.get_instance();
var z = Singleton_Derived.get_instance2();
if(x == y) Log.print("They are the same."); // same
if(x == z) Log.print("They are the same."); // different
}
}
事实也正是如此,get_instance() 方法会被继承,并依然是返回基类的单例对象。如果想返回自身的对象,需要重新定义一个访问函数——原静态访问函数是不能允许 override 重写的。
但尽管如此,这样继承的实际意义呢?与你创建一个新的类型,并组合原 Singleton 对象,几乎没有什么不同。所以应该避免这种费力不讨好的设计形式。
1.4.5. Singleton for Python3
Python 由于没有访问权限限制,你无法阻止一个对象的 init 方法不被调用。但这也不是坏事儿,毕竟 init() 直接做了本该 get_instance() 方法做的事情:
class Singleton:
def __new__(cls, *args):
# usually, this static method return super().__new__(cls); but here:
if not hasattr(cls, "instance"):
cls.instance = super().__new__(cls)
cls.instance_override = False # here, you should choose to use this or MagicMethod
if cls.instance_override == False:
cls.instance.initialize_singleton(*args)
return cls.instance
def __init__(self, attrib: str, num: int):
# 没办法屏蔽该方法的运行
# 且每次new操作,该方法都会被调用
# 使用不当将造成单例属性的改写
if self.instance_override == True:
print("self.__init__() is called : attrib[{}], num[{}]".format(attrib, num))
self.attrib = attrib
self.number = num # 新建属性
elif True: # or just ignore this renew-operation, BY comment this two lines.
raise Exception("The Singleton-Class should not override the self.__init__()")
def initialize_singleton(self, attrib: str, num: int):
# 换用自定义方法,则仅在对象第一次创建时执行初始化
print("self.initialize() is called : attrib[{}], num[{}]".format(attrib, num))
self.attrib = attrib
如上示例,通过魔术方法 new() 控制对象的创建,而 init 则可以根据需要来实现:默认的,对于单例对象,你应该只创建一次,但如果你选择了第二次创建并传入了不同的初始化参数,你需要指定算法——这样的事情是否允许发生,又该如何处理。
对于 self.instance_override 变量符,你可以通过其他方式自动的实现,比如说根据是否实现了 initialize_singleton( ) 方法等等。当然,所有的前提都是一个协议:约定俗成的一种共同认知——就好像魔术方法的使用。
或者,更加标准的方式应该是,对于 new 操作,传入恰当的参数并且只创建一次,并在 init() 中报出异常;同时,实现 get_instance() 用于返回单例对象——一般的,该方法显式的提醒你,获得的是一个单例对象,所以这里没必要也不应该有任何参数:
class Program_Singleton2:
def __new__(cls, *args):
# usually, this static method return super().__new__(cls); but here:
if not hasattr(cls, "__hasinstance__"):
cls.instance = super().__new__(cls)
cls.__hasinstance__ = False
return cls.instance
def __init__(self, attrib: str, num: int):
if self.__hasinstance__ == False:
self.__hasinstance__ = True
# the singleton initialize
print("singleton initialize : attrib[{}], num[{}]".format(attrib, num))
self.attrib = attrib
self.number = num # 新建属性
else:
raise Exception("The Singleton-Class should not override the self.__init__()")
# or pass directly. so u can get instance by: new Program_Singleton2()
@classmethod
def get_instance(cls):
return cls.instance # or self, it's the same
def TEST_FOR_SINGLETON2():
p0 = Program_Singleton2("abc", 123) # or : p0=Program_Singleton2("abc", 123).get_instance()
p1 = Program_Singleton2.get_instance() # 显示区分单例对象的创建与获取
更新【2019-05-22】
其实没必要 get_instance() 了,且使用boolean来应对“懒汉”的多线程……其实Python的线程不用担心这么多。
class GlobalObjectManager:
singleton_step = [False, False] # 分别代表:是否执行了new(), 是否执行了init()
def __new__(cls, *args, **kargs):
if not cls.singleton_step[0]:
cls.singleton_instance = super().__new__(cls)
cls.singleton_step[0] = True
return cls.singleton_instance
def __init__(self):
if self.singleton_step[1]: return
else:
self.singleton_step[1] = True
self.dict_variable = {} # variable_name: variable
self.dict_callable = {} # call_name: callable_func
更新【2019-09-14】
用一种更加简单的写法(装饰器),定义SingletonClass。
_instance = {}
def singleton(cls):
# 对于单例类,无法通过继承的方式节省代码
def inner():
if cls not in _instance:
_instance[cls] = cls()
return _instance[cls]
return inner
不过用到了全局变量,略显丑陋,且进程不安全(Python多进程不共享全局变量)。
Monostate
该模式利用了 dict() 对象的引用属性。对于每个对象,都存在一个 self.dict 属性,用于存储该对象的所有属性。那么如果两个对象的 dict 是相同的,则可以认为两个对象相同(至少二者的内存空间是相互引用,虽然二者的 id 并不相同)。在类中创建类属性,并使每个对象的 dict 引用于该类属性。由于类属性在内存中被所有对象共享,于是每个对象的 dict 也绑定在一起了。在外观上,每个对象是一样的。
class Program_Singleton3:
singleton_attribute = {}
def __init__(self, attrib: str):
self.__dict__ = self.singleton_attribute # 利用类变量__dict__
if not self.singleton_attribute: # 若属性为空,则当前尚未实例化Singleton对象
# initialize here
print("self.__init__() is called : attrib[{}]".format(attrib))
self.attrib = attrib
if __name__ == "__main__":
p0 = Program_Singleton3("abcd")
print("p0.attrib -> %s" % p0.attrib)
p1 = Program_Singleton3("efg") # 实际上无法修改类成员attrib的值
print("p1.attrib -> %s" % p1.attrib)
p0.attrib = "hijk" # 修改了p0的属性
print("修改了p0的属性后,p1.attrib -> %s" % p0.attrib) # p1属性也被修改了,所以实际上p0与p1所操作的对象是同一个
1.4.6. 进程单例模式
以上所有讨论都限定在单进程多线程的机制里。
单实例和全局变量是针对一个进程内的多线程或者多模块而言的,是不能跨越进程的。进程的内存空间是相互独立的。所以如果需要进程间共享变量或者通信,需要用进程间的通信机制。
Python multiprocess.Manager()
1.5. 原型模式
Prototype,别名:Clone
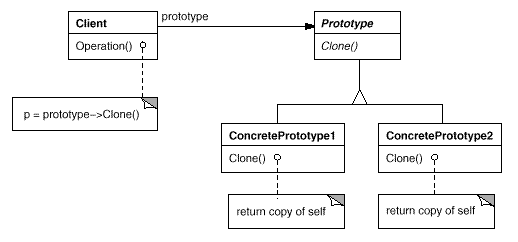
所有的创建型模式都是为了获得一个新的对象,而获取对象的方式不一定是创建,也可以是拷贝一个现有的对象并适当改造。原型的核心就是复制并使用一个现成的对象。
这里引用一下 GOF 中对原型模式适用性的描述:
当一个系统应该独立于它的产品创建、构成和表示时,要使用 Prototype 模式;以及
- 当要实例化的类是在运行时刻指定时,例如,通过动态装载;或者
- 为了避免创建一个与产品类层次平行的工厂类层次时;或者
- 当一个类的实例只能有几个不同状态组合中的一种时。建立相应数目的原型并克隆它们可能比每次用合适的状态手工实例化该类更方便一些。
具体的解析引述《原型模式,不只是 clone 那么简单》:
- 对于第一条,我们做如下的解释:动态环境下,无法得知当前对象的类型,于是乎采取了一个讨巧的方式:“我要创建一个跟它类型一样的对象”,而不是 if...elif...else... 的复杂判断。
- 第二条暂不理解 -> 借用网友的论述:这个就是用原型模式替代抽象工厂,实际上,原型模式就是把对象本身当作了工厂。
- 第三条,借用例子说明:比如斯诺克用台球虽然有不同颜色,但红黄绿棕蓝粉和黑以及白几种颜色,你绝不可能创建一个紫球。这个时候,可以用原型模式来创建对象,我们首先手动实例化 8 种颜色的球各一个,之后的创建就全都用复制的方式来进行。
从其他地方摘抄了一些更多的适用场景:
- 当一个系统应该独立于它的产品创建、构成和表示时;
- 用类动态配置应用:一些运行时刻环境允许你动态将类装载到应用中。在像 C++ 这样的语言中,Prototype 模式是利用这种功能的关键。
很多软件提供的复制 (Ctrl + C) 和粘贴 (Ctrl + V) 操作就是原型模式的应用,复制得到的对象与原型对象是两个类型相同但内存地址不同的对象,通过原型模式可以大大提高对象的创建效率。
1.5.1. 问题导入
引自 GOF 设计模式
看看 Gof 提供的例子,那个经典的图形编辑器(其标准案例解释:参考这里):
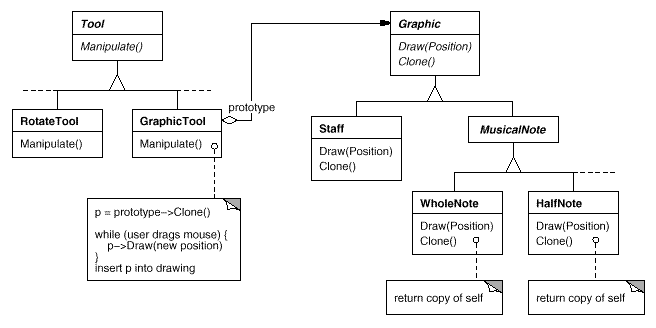
作以解释:TOOL 是我们的图形框架,而 Graphic 可以理解为我们用工具打开的一份图形文件。我们的工具栏上(Tool 层)包括了旋转按钮(RotateTool)、GraphicTool(绘图按钮)。
由于 Graphic 是一个外部文件,图形编辑器工具并不知道它到底包含了哪些图元对象,甚至还包括自定义对象、或者是既有对象的组合(并保存为图形库)。在 GraphicTool 实现一个绘图功能时,我们可以先在预定义图形库中选择一个图元(包括图形库中增加的自定义图元),或者是通过鼠标选择了一个已有的图形,实现 Ctrl+V 复制(创建)功能:
class GrphicTool{
public void create_graphic(AbstractGraphic select_graphic){
#if TRY_CREATE
var graphic = new AbstractGraphic(); // 那么显示什么呢? 额...
#elif TRY_CREATE_2
if(select_graphic is Staff){
var graphic = new Staff(); // 传入参数,或针对staff对象执行若干初始化操作
// ...
}else if(select_graphic is WholeNote){
var graphic = new WholeNote("abc");
}else if(select_graphic is HalfNote){
var graphic = new HalfNote(23, 56);
}else{
// Here, you can't new an object of FutureExpandingClass
var graphic = new AnyCombination(); // 额,不支持拓展...
}
// ...
#endif
}
}
对于 TRY_CREATE_2 的方式,有点像简单工厂了——而很显然,如果使用原型模式,这个过程将会容易很多,当然,新的问题是,你需要给所有的已知图元提供 Clone() 方法。或许可以把二者结合起来:
class GrphicTool{
public void create_graphic(AbstractGraphic select_graphic){
// 首先我们利用简单工厂,按已有的套路创建工厂——这个过程可能都不需要重写,
// 在其他功能模块里可能已经实现...
// so, the class, for example Staff, no need the Clone() method
if(select_graphic is Staff){
var graphic = new Staff(); // 传入参数,或针对staff对象执行若干初始化操作
// ...
}else if(select_graphic is WholeNote){
var graphic = new WholeNote("abc");
}else if(select_graphic is HalfNote){
var graphic = new HalfNote(23, 56);
}
// 接下来,实现自定义图元或组合图元的创建,这里用到了原型模式
else{
// Here, you can't new an object of FutureExpandingClass
var graphic = select_graphic.Clone(); // 实现自定义图元的Clone接口即可
}
}
}
为了省略给已知类型实现复杂的 Clone(),我们针对已知图元类,通过简单工厂的模式实现功能,而自定义图元则实现 Clone()。至于组合图元呢,拆开了来个递归吧。。。
1.5.2. 总结
原型模式非常的灵活,因为它提供了创建对象的两大方法的一个分支,却只有一种已知模式,那么这个模式的技巧性一定很强…… 再结合各种其他的创建型设计模式,留给我们的发挥空间应该是非常大的。
2. 结构型
2.1. 代理模式
Proxy,别名:Surrogate

情景:游戏代练
using System;
using logging;
interface IGamePlayer{
void playing();
void upgrade();
}
class GamePlayer: IGamePlayer{ // 实际玩家
protected string _name;
public GamePlayer(string name){
this._name = name;
}
public virtual void playing(){
Log.print(_name + "执行任务");
}
public virtual void upgrade(){
Log.print(_name + "升级啦!");
}
}
class GamePlayerProxy: IGamePlayer{ // 代练
private GamePlayer _real;
public GamePlayerProxy(GamePlayer real_player){
if(real_player == null) throw new Exception("No real player found.");
_real = real_player;
}
public void playing(){
_real.playing();
}
public void upgrade(){
_real.upgrade();
}
}
2.1.1. 强制代理
class ForcedGamePlayer: GamePlayer{
public ForcedGamePlayer(string name): base(name){ }
private GamePlayerProxy _proxy;
public GamePlayerProxy proxy{
get{
this._proxy = new GamePlayerProxy(this);
return this._proxy;
}
}
private bool isMyProxy(){ // proxy check
if(this._proxy == null){
Log.print("请使用指定的代理访问");
return false;
}else
return true;
}
public override void playing(){
if(isMyProxy()) // 强制代理
base.playing();
}
public override void upgrade(){
if(isMyProxy()) // 强制代理
base.upgrade();
}
}
class Demo{
public static void Main(string[] args){
#if FORCED
var player = new ForcedGamePlayer("Flora");
GamePlayerProxy proxy = player.proxy;
proxy.playing();
proxy.upgrade();
#else
IGamePlayer player = new GamePlayer("Bob");
// these two method will return directly.
player.playing();
player.upgrade();
#endif
}
}
2.1.2. 相关模式
- 远程代理(Remote Proxy)为一个对象在不同的地址空间提供局部代表。
- 虚拟代理(Virtual Proxy)根据需要创建开销很大的对象。
- 保护代理(Protection Proxy)控制对原始对象的访问。
- 智能代理(Smart Proxy)在访问对象时执行一些附件操作。
2.2. 适配器模式
Adapter,别名:Wrapper
对象适配器依赖于对象组合:

类适配器使用多重继承对一个接口与另一个接口进行匹配:
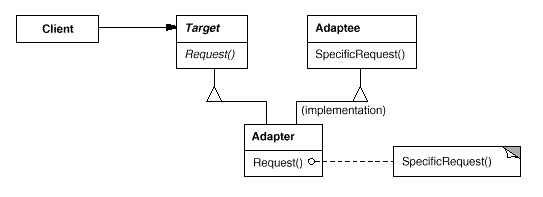
示例:标准电源插头包括了三脚插头、两脚插头、棒状插头等等,有时恰恰电器的插头与插座不匹配,怎么办?这个时候就用到了 “插头转换器”。
首先,定义各种插座和电灯:
class SocketWith3pin{
// if this function is not virtual, Adapter would be aborted.
public virtual void power_supply_for_3pin(){
Log.print("powered by 3 pin.");
}
}
class SocketWith2pin{ // it's different to the 3 pin.
public virtual void power_supply_for_2pin(){
Log.print("powered by 2 pin.");
}
}
class LampWith2pin{
protected SocketWith2pin _socket;
public void connect_to_power(SocketWith2pin socket){
this._socket = socket;
Log.print("Well done, connect the power socket.");
}
public void light(){
_socket.power_supply_for_2pin();
Log.print("We light the lamp!");
}
}
然后,适配器和客户端:
// Adapter to change the 3pin to 2pin.
class Adapter: SocketWith2pin{ // must inherit from the SocketWith2pin, so it can be use as a Socket.
private SocketWith3pin _socket;
public Adapter(SocketWith3pin socket){
_socket = socket;
}
public override void power_supply_for_2pin(){ // it has a function of SocketWith2pin class
_socket.power_supply_for_3pin(); // and it calls function of SocketWith3pin class
}
}
class Demo{
static void Main(){
var lamp = new LampWith2pin();
var socket = new SocketWith3pin(); // socket is object of SocketWith3pin
#if NO_Adapter
lamp.connect_to_power(socket); // Fail to compile...
#else
var socket2 = new Adapter(socket); // here, socket is object of SocketWith2pin
lamp.connect_to_power(socket2);
#endif
lamp.light();
}
}
跟装饰模式太像了,有没有!
其实不然,装饰模式的操作方式是:导入原 Target 对象,并输出增加了新功能(可能是属性更新,也可能是增加了新的方法)的 Target 对象,看起来就是:对象更新了。然而对于适配器的设计意图,我们导入对象 Class-B,并获得 Adapter(继承于 Class-A)对象,而 Adapter 对象是作为 Class-A 使用的。通过适配器,我们改变了输入与输出对象的类型!
2.2.1. 思考
为什么不设计成这样呢:
interface PowerSocket{
void power_supply();
}
class SocketWith3pin: PowerSocket{ }
class SocketWith2pin: PowerSocket{ }
class Lamp{
protected PowerSocket _socket;
public void connect_to_power(PowerSocket socket){
this._socket = socket;
Log.print("Well done, connect the power socket.");
}
public void light(){
_socket.power_supply();
Log.print("We light the lamp!");
}
}
这个思路没错——所有的灯都应该使用 PowerSocket 接口,而不是与 ConcreteContext 耦合在一起。但是如果项目已经庞大到难以重构,或者你根本没有权限修改接口时——适配器是一种退而求其次的无奈之举。
另外,适配器还存在一处限制:如果 SocketWith3pin::power_supply_for_3pin() 方法没有定义为 virtual 类型,则 Adapter 无法重写该方法。
2.2.2. 总结
适配器的核心,在于继承自 功能类 A(所以能作为 class A 使用),并重写了其接口 method x,但改写其功能为(调用或重新实现) class B::method_y( ),效果等同于 class B 。
2.2.3. 相关模式
Bridge 模式的结构与对象 Adapter 模式类似,但是 Bridge 模式的出发点不同:Bridge 目的是将接口部分和实现部分分离,从而对它们可以较为容易也相对独立的加以改变。而 Adapter 则意味着改变一个已有对象的接口。
Decorator 模式增强了其他对象的功能而同时又不改变它的接口。因此 Decorator 对应用程序的透明性比 Adapter 要好。结果是 Decorator 支持递归组合,而 Adapter 无法实现这一点。
Proxy 模式与其代理对象的接口一致(基于同一 interface 的两个派生类)。而适配器貌似也在 “提供”(也可以称为 “代理”)真实对象(Adaptee)的功能,却是在为 Adaptee 提供新的接口;适配器与其适配对象 Target 保持相同的接口。
Facade 模式同样是在整合旧的接口,为客户端做适配。区别在于,Facade 中客户端还未开始,接口可以任意定义;而适配器中客户端已经定型,并且调用了执行器方法——只是执行器没有正常运行。为了匹配客户端的调用,适配器需要成为 Target 派生类(且接口需要与 Target 完全一致,当然这个要求已经通过继承自动实现了)。
2.3. 装饰模式
Decorator,别名:Wrapper(包装器)
2.3.1. 问题导入
引自《Head First Design Patterns》
咖啡店:定义 “咖啡” 基类,根据咖啡的品类、工艺,又细分为焦炒咖啡(DarkRoast)、蒸馏咖啡(Espresso)、脱因咖啡(Decaf)、白咖啡等。根据定性的区别,我们可以从基类中派生出若干子类。
但这没有结束——我们知道还有 “拿铁”、“卡布奇诺”、“玛奇朵”、“摩卡” 等,他们是根据加入的配料而衍生出的品种,现在这个可不再是定性的问题了,而是根据成分含量不同而产生了不同的类型。更为复杂的是,由于自由度很大,品类还在不断的增加中,甚至于你可以选择自由组合,定制属于自己的咖啡类型——比如 “两份” 糖,外加柠檬且不要牛奶……
2.3.2. 分析
对于拓展,我们最自然的方式就 “继承”。例如咖啡基类(Coffe),派生出子类:DarkRost, Espresso, Decaf... 等——继承很适合定性的区分类型。但如果类型的区别是定量的,如 Latte 与 Cappuccino 都含有 Decorator 属性——milk & sugar,而根据若干配料而组合出的品类是无限制的(糖多一点,再多一点...),因而导致子类无限拓展,继承关系会导致“类爆炸” 的发生!
另外,继承需要静态定义子类,而装饰模式下可以动态的自由拼接 —— Attach additional responsibilities to an object dynamically.
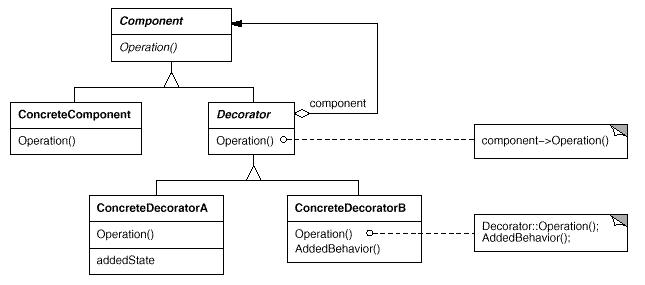
2.3.3. 思考
首先我们得定义咖啡和配料,按照面向对象的思想,每一个品类最好独立封装成 class:
// Here is the coffee.
abstract class CoffeeBase{
protected string _name;
public string name => _name;
public int cost{get;set;}
}
class DarkRoast: CoffeeBase{
public DarkRoast(){ _name = "DarkRoast"; cost = 5; }
}
class Espresso: CoffeeBase{
public Espresso(){ _name = "Espresso"; cost = 6; }
}
class Decaf: CoffeeBase{
public Decaf(){ _name = "Decaf"; cost = 7; }
}
// Here is the decorator.
abstract class Decorator{ // it's the same as CoffeeBase, but there is no relationship.
protected string _name;
public string name => _name;
public int cost{get;set;}
}
class Sugar: Decorator{
public Sugar(){ _name = "sugar"; cost = 1; }
}
class Milk: Decorator{
public Milk(){ _name = "milk"; cost = 2; }
}
class Mocha: Decorator{
public Mocha(){ _name = "mocha"; cost = 3; }
}
接下来,我们介绍 “装饰模式” 的使用——

装饰模式并没有使用配料类,而是重新定义了 Decorator 。
新定义的 Decorator 类很有趣,它叫做装饰类,但它的对象是 CoffeeBase 类型;实际上,Decorator2 更像是 CoffeeBase 的补丁。所以,对于新的 Decorator,已然替换了概念——它不再是一个装饰对象,而是一个转换器。只不过,它将装饰与转换的功能耦合在了一起,有点似是而非。
// if there is only one additional function for CoffeeBase, u don't need the abstract Decorator class.
abstract class CoffeeDecorator: CoffeeBase{ // Decorator class must inherit CoffeeBase.
protected string name_decorator;
protected int cost_decorator;
public CoffeeDecorator(CoffeeBase semi_coffee){
this.init_decorator();
_name = semi_coffee.name + " with " + name_decorator;
cost = semi_coffee.cost + cost_decorator;
}
protected abstract void init_decorator();
}
class SugarCoffee: CoffeeDecorator{ // u can inherit the CoffeeBase directly.
public SugarCoffee(CoffeeBase semi_coffee): base(semi_coffee){ }
protected override void init_decorator(){
name_decorator = "sugar";
cost_decorator = 1;
}
}
class MilkCoffee: CoffeeDecorator{
public MilkCoffee(CoffeeBase semi_coffee): base(semi_coffee){ }
protected override void init_decorator(){
name_decorator = "milk";
cost_decorator = 2;
}
}
class MochaCoffee: CoffeeDecorator{
public MochaCoffee(CoffeeBase semi_coffee): base(semi_coffee){ }
protected override void init_decorator(){
name_decorator = "mocha";
cost_decorator = 3;
}
}
class Demo{
public static void Main(){
CoffeeBase coffee = new DarkRoast();
coffee = new SugarCoffee(coffee);
coffee = new MilkCoffee(coffee);
coffee = new MochaCoffee(coffee);
coffee = new SugarCoffee(coffee);
Log.print("I got a cup of coffee: " + coffee.name);
Log.print("Cost of the coffee: " + coffee.cost); // should be 12
}
}
尽管装饰器尝试给 CoffeeBase 的对象增加一个新的功能,原来的 CoffeeBase 对象还是更新成了诸如 SugarCoffee 等子类型。
我们希望:
- 能够保留
DarkRoast的类型; new的方式并不符合逻辑,应该是对DarkRoast对象调用add_decorator()方法。
2.3.4. 再思考
相比而言,接下来提供一种优化方式——创建一个新的子类,融合了 CoffeeBase 与 CoffeeDecorator 的对象,生成新的类型 UdfCoffe——但它如刚才的 “装饰模式” 里的 SugarCoffee 一样,继承自 CoffeeBase。
这个方式将 Decorator 解耦,而你得到的也仅仅是一个 CoffeeWithDecorator 对象,它依旧属于 CoffeeBase 类型。
你还可以用 ArrayList 存储层发生在该对象上的装饰过程。
class UdfCoffe: CoffeeBase{ // inherit or not, is import to think! it will be discussed later.
/* if you like, you could store the process.
protected CoffeeBase _coffee;
protected ArrayList al_decorator = new ArrayList(); */
public UdfCoffe(CoffeeBase coffee){
// _coffee = coffee;
_name = coffee.name;
cost = coffee.cost;
}
public void add_decorator(Decorator decorator){
// al_decorator.Add(decorator);
_name += " with " + decorator.name;
cost += decorator.cost;
}
}
class Demo{
public static void Main(){
var coffee = new UdfCoffe(new DarkRoast());
coffee.add_decorator(new Sugar());
coffee.add_decorator(new Milk());
coffee.add_decorator(new Mocha());
coffee.add_decorator(new Milk());
Log.print("I got a cup of coffee: " + coffee.name);
Log.print("Cost of the coffee: " + coffee.cost); // should be 13
}
}
这里有一个重要的话题:UdfCoffee 是否要继承 CoffeeBase?
从功能角度讲,你完全可以将 UdfCoffee 作为一个全新的类型使用,并定义其自身的接口,而不一定是 name or cost。
但如果,你继承了 CoffeeBase ,这才能被称之为装饰模式!
因为,如此而来,UdfCoffee 能够作为 CoffeeBase 对象使用。这正是装饰模式的设计意图:动态的为 CoffeeBase 增加功能 / 职责(Attach additional responsibilities to an object dynamically)。
2.3.5. 继续思考
如果你更喜欢装饰模式 object = new class(object) 的形式...
class CoffeeWithDecorator: CoffeeBase{ // u don't need to inherit. read the discuss above.
public CoffeeWithDecorator(CoffeeBase semi_coffee, Decorator decorator){
_name = semi_coffee.name + " with " + decorator.name;
cost = semi_coffee.cost + decorator.cost;
}
}
class Demo{
public static void Main(){
CoffeeBase coffee = new DarkRoast();
coffee = new CoffeeWithDecorator(coffee, new Sugar());
coffee = new CoffeeWithDecorator(coffee, new Milk());
coffee = new CoffeeWithDecorator(coffee, new Mocha());
coffee = new CoffeeWithDecorator(coffee, new Mocha());
Log.print("I got a cup of coffee: " + coffee.name);
Log.print("Cost of the coffee: " + coffee.cost); // should be 14
}
}
这个方式实际上还是 UdfCoffe 的模式,只不过构造时完成 CoffeeBase 与 Decorator 的融合。而在客户端,看上去与原生的 “装饰模式” 更相似了。
2.3.6. 重新思考【2020-02-23】
再重申一下我们的目标:
- 能够保留
DarkRoast的类型; new的方式并不符合逻辑,应该是对DarkRoast对象调用add_decorator()方法。
另外,考虑新定义的产品需要批量复制。对于前面的方式,仅仅是一次性的,无法批量生产"100杯含两勺糖4滴奶的摩卡"(当然,这不是装饰模式的目标——装饰器就是为了避免类爆炸)。
解决方案:使用原型模式。或者直接利用python的 deepcopy() 复制一个对象。
class Decorator:
""" 无需继承任何class """
def __init__(self, name, cost):
self.name = name
self.cost = cost
def add_decorator(base: Coffee, decorator: Decorator):
new_obj = copy.deepcopy(base)
new_obj.name += "with " + decorator.name
new_obj.cost += decorator.cost
return new_obj
if __name__ == "__main__":
base = DarkRoast()
# new_type()
x_ = add_decorator(base, Sugar())
x_ = add_decorator(x_, Milk())
x_ = add_decorator(x_, Mocha())
x_ = add_decorator(x_, Mocha())
new_type = x_
def create_new_type():
return copy.deepcopy(new_type)
for idx in range(100):
coffee = create_new_type()
print(f">> 第{idx}杯咖啡的价格:{coffee.cost}")
2.3.7. 总结
前面针对 Decorator 的实现,实现了几种优化。选择 CoffeeDecorator(SugarCoffee...) 还是 Decorator+CoffeeWithDecorator,是另一个模式的问题——CoffeeWithDecorator 不过是一层封装罢了。
装饰模式的核心,在于 SugarCoffee, or CoffeeWithDecorator,它继承于 Component,那么对于使用 Component 的客户端来说,Decorator 是透明的(客户端依然在使用 Component 的接口)。
而 Component 的创建过程(可以封装成建造者),可以在客户端不知道 Decorator 的情况下,增加 Component 的功能或职责。这就是所谓的 “递归组合”。
2.3.8. 相关模式
Decorator 模式与 Adapter 模式实现方式很类似,只是应用层面不同。从客户端看二者的区别:Adapter 的意图在于客户端以同样的方式操作 Target 和 Adapter 对象(调用的 interface 是一样的);它导入现有 Lib 库对象,而导出 Target 接口对象;而装饰则导入 Target 对象并输出新的 Target 对象,新对象增加了新的功能,这个新功能可能是改变了原对象的属性,也可能是增加了接口,客户端也可以调用 Decorator 对象的新方法。
可以将 Decorator 视为一个退化的、仅有一个组件的 Composite。然而,Decorator 仅给对象添加额外的职责,它的目的不在于对象聚集。
用一个 Decorator 可以改变对象的外表,而 Strategy 模式使得你可以改变对象的内核。这是改变对象的两种途径。
当 Component 类原本就很庞大时,使用 Decorator 模式的代价太高,Strategy 模式相对更好一些。
Proxy 的实现与 Decorator 很相似,但目的不同。 Decorator 为对象添加功能,Proxy 则控制对对象的访问。一般的,Proxy 并不会在 Subject 接口的基础上添加新的接口(仅仅是代理,一般无需创新),而 Decorator 则一定需要增加一些新的接口或功能,才能实现 “递归组合” 的目标。
2.4. 组合模式
Composite
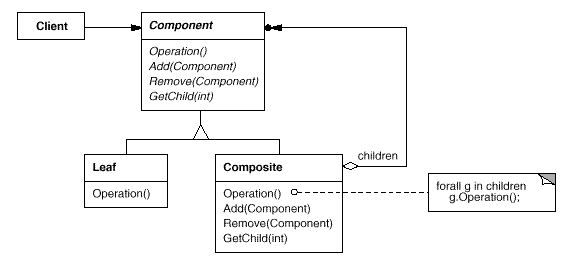
组合模式的设计意图包含了两个方向:
- 将对象组合成树形结构以表示 “部分 - 整体” 的层次结构(Compose objects into tree structures to represent part-whole hierarchies)。
- Composite 使得用户对于单个对象和组合对象的使用具有一致性(Composite lets clients treat individual objects and compositions of objects uniformly)。
示例:组织构架图
using logging;
using System.Collections;
interface Component{
void info();
}
class Person: Component{
public string name{get;set;}
public string title{get;set;}
public Person(string name){ this.name = name; title = "小兵"; }
public virtual void info(){
Log.print(title + ": " + name);
}
}
class Manager: Person{
public ArrayList _group = new ArrayList();
public Manager(Person man, string title): base(man.name){
this.title = title;
}
public void add_manager(Manager manager){
_group.Add(manager);
}
public void add_person(Person man){
_group.Add(man);
}
public override void info(){ // 重写:递归查询
base.info();
foreach(Person item in _group){
// if(item.GetType() == typeof(Manager)) // u don't need to judge the type
item.info();
}
}
}
class Demo{
static void Main(){
var chairman = new Manager(new Person("Hello"), "董事长"); // the top.
var Tesla = new Manager(new Person("Tesla"), "美国分公司经理");
var WangPeng = new Manager(new Person("WangPeng"), "中国分公司经理");
chairman.add_manager(Tesla);
chairman.add_manager(WangPeng);
chairman.add_person(new Person("最美小蜜"));
var aa = new Manager(new Person("aa.zhao"), "财务部经理"); Tesla.add_manager(aa);
var bb = new Manager(new Person("bb.qian"), "人事部经理"); Tesla.add_manager(bb);
var cc = new Manager(new Person("cc.sun"), "技术部经理"); Tesla.add_manager(cc);
var dd = new Person("孤单的小蜜"); Tesla.add_person(dd);
var ee = new Person("ee"); cc.add_person(ee);
var ff = new Person("ff"); cc.add_person(ff);
var gg = new Person("gg"); cc.add_person(gg);
var mm = new Person("打不死的小蜜"); cc.add_person(mm);
chairman.info();
mm.info(); // 无论是谁,我们的接口相同
}
}
组合模式的核心,就是递归,将所有事物分为两类—— 叶子节点 或 分支节点;组合模式达到的效果,就是叶子节点与分支节点的操作完全一致,是以客户端调用对象时无需区分节点当前的身份或状态。
叶子节点可以组合成分支节点,而分支节点可以无限递归组合。于是乎构建复杂的结构变得简单和重复;
同时,对于叶子节点,同样会实现 Add / Remove 等 Composite 类才有的接口(空实现)。于是乎客户端可以一致地使用组合结构和单独对象(结构和对象对客户端是统一的,客户端不需要判断当前对象状态),这个方法称为 “透明模式”。与之相对的,是 “安全模式”,Component 接口层不去声明 Add / Remove 方法,叶子也就不用空实现了,当然由于不够透明,所以客户端需要进行类型判断,执行不同的 action,带来了不便。
2.4.1. 总结
一般情况下,我们用 ArrayList 存储一个列表。注意, ArrayList 是一维的,意味着所有的数据项都是平级关系。如果需求调整,你需要增加“子菜单”,例如在 ArrayList 中,逐层嵌套另一个 ArrayList ,此时你需要考虑“递归”。一旦涉及递归访问,你应该想到 “组合模式”,也就是无差别的对待 Group 和 One-Item ——组合模式可以帮助你减小模型解析的复杂度。
2.4.2. 相关模式
Command 模式描述了如何用一个 MacroCommand Composite 类组成一些 Command 对象,并对它们进行排序。
通常 “部件 - 父部件” 连接用于 Responsibility of Chain 模式。
Decorator 模式经常与 Composite 模式一起使用。它们通常有一个公共的父类。
Flyweight 让你共享组件,但不再能引用它们的父部件。
Iterator 可以用来遍历 Composite。
Visitor 将本来应该分布在 Composite 和 Leaf 类中的操作和行为局部化。
2.5. 门面模式
Facade,别名:外观模式

门面模式说白了,就是封装——将一个子系统中错乱的功能封装成若干简单接口,作为统一的入口点,提供给外界使用。
例如,邮局寄信的过程,包括了——写信、填表单、粘贴邮票、封装盖章、投递等若干步骤。这些步骤顺序还不能颠倒、任何一个步骤运行失败需要回退整个过程(错误处理)…… 这个过程与 “高内聚” 的要求相差甚远,更不用说迪米特法则、接口隔离和类的单一职责了。
于是我们增加了一个 PostOffice 类,并利用接口 send_letter( ) 封装了以上操作步骤和异常处理机制。OK,这就是门面模式。
如此一来,当邮局要再增加诸如 “安全检查”、按重收费等功能时,只需要在 send_letter() 中调整响应的代码就够了,对客户端完全透明。
2.5.1. 相关模式
一个系统中通常仅需要一个 Facade 对象,因此可以用 Singleton 模式定义 Facade。
2.5.2. 一个子系统可以有多个门面
门面过于庞大时,可以将一个门面拆分为多个。如何拆分呢?按照功能拆分是一个非常好的原则,比如一个数据库操作的门面可以拆分为查询门面、删除门面、更新门面等。
注意:门面不参与子系统内的业务逻辑
先看一个错误的示例程序:
public class Facade {
//被委托的对象
private ClassA a = new ClassA();
private ClassB b = new ClassB();
private ClassC c = new ClassC();
//提供给外部访问的方法
public void methodC(){ // 不规范操作:封装了业务操作
this.a.doSomethingA();
this.c.doSomethingC();
}
}
为什么错误呢?
门面对象只是提供一个访问子系统的一个路径而已,它不应该也不能参与具体的业务逻辑,否则就会产生一个倒依赖的问题:子系统必须依赖门面才能被访问,这是设计上一个严重错误,不仅违反了单一职责原则,同时也破坏了系统的封装性。
上述代码的调整如下:
public class Context {
//委托处理
private ClassA a = new ClassA();
private ClassC c = new ClassC();
//复杂的计算
public void complexMethod(){
this.a.doSomethingA();
this.c.doSomethingC();
}
}
public class Facade {
//被委托的对象
private ClassA a = new ClassA();
private ClassB b = new ClassB();
private Context context = new Context();
//提供给外部访问的方法
public void methodA(){
this.a.doSomethingA();
}
public void methodB(){
this.b.doSomethingB();
}
public void methodC(){
this.context.complexMethod();
}
}
2.6. 桥接模式
Bridge,别名:Handle, or Body
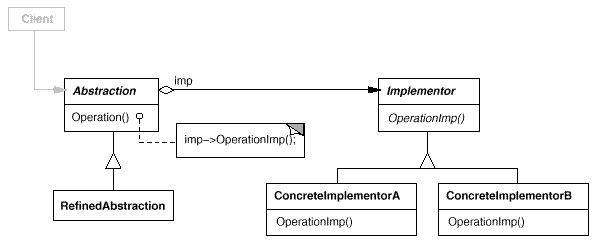
2.6.1. 问题导入
引自《大话设计模式》
我门小时候经常玩游戏机,那时候有一款很火的游戏《拳皇》。后来出了 Windows 的复刻版,又痴迷了很久;突然想,能否把这款经典游戏复刻到安装系统呢?
KOF 是一款软件,但它受硬件和操作系统的限制(强耦合)。最直接的,我们这样设计类图:
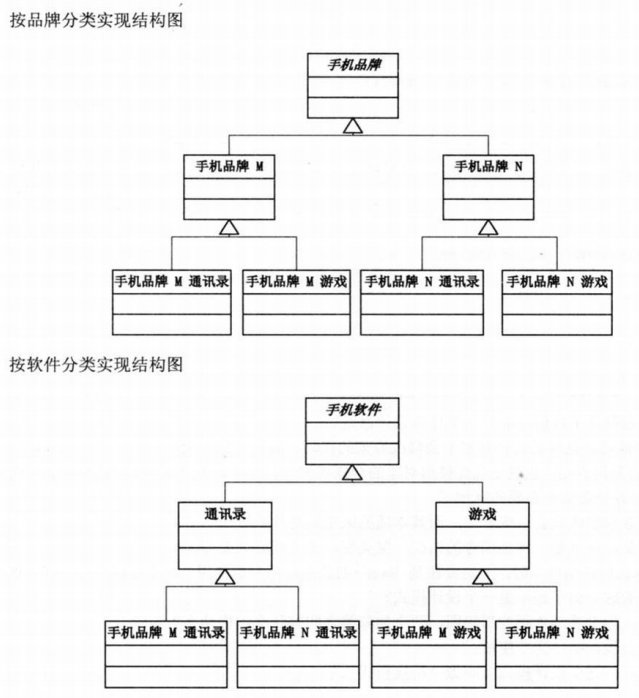
这个设计的弊端非常明显——当我们提供了一个新的平台,我们需要把全部现有的软件重新在该平台下实现一遍;再或者,当我们提供了一款新的软件,我们需要在所有平台下重写一遍该软件的实现?
还有,我们在Android系统下,install(app) 函数只能调用具体类(app=AndroidChrome)。这不符合开闭原则、面向接口编程……
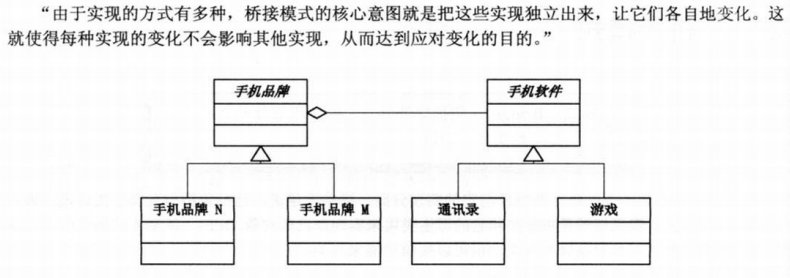
我们首先定义了软件与硬件的接口类:
public interface IHardWare{
void drive();
void software_install(ISoftWare software);
void software_execute();
}
public abstract class SoftWare{
public IHardWare env{get;set;}
protected abstract void function(); // 软件功能代码(我们假设功能代码与环境无关,也就是Java跨平台特性)
public void run(){ // run() 就是一个 Template Method.
this.env.drive(); // 软件运行需要载入系统运行时
this.function();
}
}
接着我们修改了硬件的接口(改成了抽象类,并提供了模板方法和一些接口的实现),然后很容易的构建了若干软硬件的实例:
public abstract class HardWare: IHardWare{
protected SoftWare _software{get;set;}
public abstract void drive();
public void software_install(SoftWare software){
this._software = software;
this._software.env = this; // 点睛之笔,相互引用
}
public void software_execute(){
this.software.run();
}
}
class Windows7: HardWare{
public override void drive(){
Log.print("This is a computer, with Windows7 environment.");
}
}
class Android: HardWare{
public override void drive(){
Log.print("This is a cellphone, with Android-8.0 environment.");
}
}
class KOFGame: SoftWare{
protected override void function(){
Log.print("King of Fighters: A PLAYSTATION game.");
}
}
最后,我们在客户端里模拟一个操作系统,并为其安装、运行软件。我们还可以很轻易的拓展软硬件,让客户端足够灵活:
class Demo{
// 时代在进步,我们有了新的系统
class FutureOS:HardWare{
public override void drive(){
Log.print("A future Operating System, for hardware you never known.");
}
}
// 以及新的软件
class Chrome: SoftWare{
protected override void function(){
Log.print("Chrome: A browser written by google.");
}
}
static void Main(){
var os = new Windows7();
os.software_install(new KOFGame());
os.software_execute();
os.software_install(new Chrome()); // 安装新软件
os.software_execute();
var os2 = new FutureOS();
os2.software_install(new KOFGame()); // 新系统中复刻经典
os2.software_execute();
}
}
2.6.2. 总结
桥接模式的核心是解耦——尽可能避免使用继承,而是通过组合实现不直接相关的对象之间的联系。同时,它也避免了类爆炸,你可以用更少的类,组合成同样丰富的世界。
2.7. 享元模式
FlyWeight
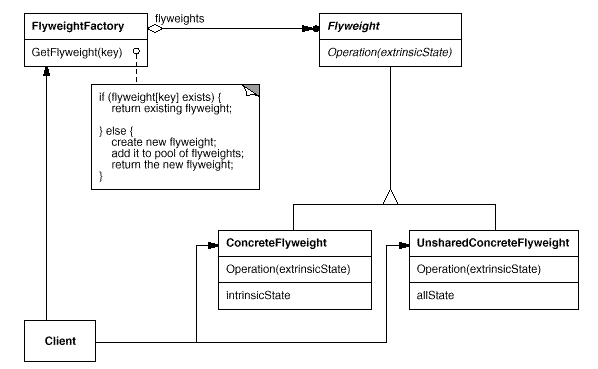
2.7.1. 问题导入
引自《大话设计模式》
如果你要创建一个网站,需要租用虚拟空间、编写服务器代码、网站上线、装饰页面(前端)等几个步骤。当你完成了一个(比方说)博客网站的建设,你对整个流程已经轻车熟路了,那么此时如果有人请你再创建一个新的个人博客呢?很多内容你是可以复用的(比如代码、服务器部署,尤其是虚拟空间是可以共享的,节省成本嘛~),而不需要你重新再实现一遍。
假设,针对开销最大的虚拟空间,对于相同类型的网站(可以是博客,还可以是论坛、视频网站、交友网站...)可以共用同一个服务器,只是需要调整 UI——你该怎么解耦?
public class Website{
protected string _type;
public Website(string type){
this._type = type;
alloc_vpc(); // 开销巨大
}
protected void alloc_vpc(){ // VPC: VirtualPrivateServer
Log.print($"【{_type}类】网站: 租用新的虚拟主机空间, 花销¥3000");
}
// 不同的Website,也有着不同的表现层
public void decorate_space(int money_for_ui){
Log.print("美化页面,调整布局,整合UI");
}
}
我们设计了一个网站类,由于构造函数包含了对虚拟空间的租用,导致对象的创建是个开销巨大的事情。故而我们应该尽可能减少该对象的创建。怎么办?
class WebSiteFactory{ // 通过工厂类,实现对“共享内存”的复用
private Hashtable flyweights = new Hashtable();
public Website build_website(string key){
if(!flyweights.ContainsKey(key)){
flyweights.Add(key, new Website(key)); // 通过hash等方式,减少大对象的创建
}
return (Website)flyweights[key];
}
}
引入工厂!把 new Website() 的工作交给 Factory 去实现(工厂就是封装了一层函数,在每次 new 操作之前作以检测,如果同类型的对象已存在,则直接返回,而不是创建新对象)。
但这也只是实现了 “内部状态” 的复用,每个对象都不同的部分呢——比如说,UI?我们将这部分功能从 Website 中解耦,重新设计 Website 类:
// 享元模式最核心的意图:减少巨大开销对象的创建
public class Website{
protected string _type;
public Website(string type){
this._type = type;
alloc_vpc(); // 开销巨大
}
protected void alloc_vpc(){ // VPC: VirtualPrivateServer
Log.print($"【{_type}类】网站: 租用新的虚拟主机空间, 花销¥300");
}
// 不同的Website,也有着不同的表现层(类似QQ空间)
public void decorate_space(IUser user, int money_for_ui){
user.reset_web_ui(money_for_ui); // 实际上,享元对象将外部状态分离为user对象,由user对象处理变化部分。
// 由于user对象的创建开销很小,故而减少了整体项目的开销。
}
}
public interface IUser{ // 针对接口编程
void reset_web_ui(int money);
}
public class User: IUser{
public string user{get;}
public User(string user){ this.user = user; }
public void reset_web_ui(int money){
Log.print($"{user}: 配置个人网站-私人空间,花销¥{money}");
}
}
这里我们增加了 IUser 接口,由 User 对象存储原本 Website 的可变部分(例如网站的所有人、前端开发的方式和花销)。decorate_space() 接口对于 Website 是固定的,不同的是传入的参数——从而实现 “外部状态” 与 “内部状态” 的分离。而从设计意图上,我们只想独立开销巨大的 Website 对象的创建,而对于开销很小且各不相同的 User ,我们并不关心它的数量。
于是,我们可以在客户端中,随意的创建各种享元对象和 User 对象,但实际上,真正 new 出的 “庞大” 对象没有几个,这些大对象保留了项目的不变部分。而 User 小对象的创建开销是可以忽略的,而他们实现了项目的变化部分。
class Demo{
static void Main(){
var factory = new WebSiteFactory();
var wang = new User("隔壁老王");
var blog_website = factory.build_website("博客");
blog_website.decorate_space(new User("Myself"), 10);
var blog_2 = factory.build_website("博客");
blog_2.decorate_space(wang, 50);
var forum = factory.build_website("论坛");
forum.decorate_space(new User("天涯"), 99);
var movie = factory.build_website("视频");
movie.decorate_space(wang, 20);
var movie_2 = factory.build_website("视频");
movie_2.decorate_space(new User("NoName"), 10);
}
}
2.7.2. 总结
享元模式是一个简单的解耦合方法,它的核心是分离对象的可变部分和不可变部分。享元模式也是 “池技术” 的重要实现方式,无论你是参数池、对象池、线程池,既然对象数量庞大,我们为了优化存储空间和开销,就有必要解耦对象的可变与不可变,让共性的东西单独保留。这就是所谓“支持大量细粒度的对象”。
2.7.3. 相关模式
Flyweight 模式通常和 Composite 模式结合起来,用共享叶节点的又向无环图实现一个逻辑上的层次结构。
通常,最好用 Flyweight 实现 State 和 Strategy 对象。
3. 行为型
3.1. 策略模式
Strategy,别名:Policy

这个模式没什么好说的——如果你有多种算法,或者算法可能会优化,升级为多种算法,那么策略模式可以让算法独立于客户端的变换。
例如,我们买了辆车,并保留其更换发动机的改装能力——接下来,我们可以很容易的变换引擎,享受不同的驾驶体验(实际上很多车型都集成了 “山地”、“高速”、“越野” 等多种行驶模式)。
using logging;
interface Engine{
void run();
}
class BenzEngine: Engine{
public void run(){
Log.print("奔驰:舒适而稳定");
}
}
class BWM_Engine: Engine{
public void run(){
Log.print("宝马:完美的操控体验");
}
}
class HummerEngine: Engine{
public void run(){
Log.print("悍马:超强的越野性能");
}
}
class Car{
private Engine _engine;
public Car(Engine engine){
this.conditioning(engine);
}
public void conditioning(Engine engine){ // 调校发动机
this._engine = engine;
this._engine.run(); // 试试车呗
}
}
class TuningHouse{
static void Main(){
#if FACTORY
var car_benz = new Car(new BenzEngine());
var car_BWM = new Car(new BWM_Engine());
#else // conditioning
var car = new Car(new BenzEngine());
car.conditioning(new BWM_Engine());
car.conditioning(new HummerEngine());
#endif
}
}
3.2. 迭代器模式
Iterator
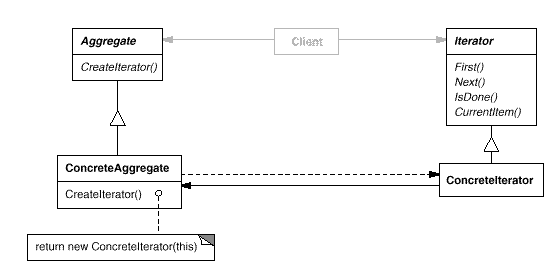
迭代器的设计是为容器服务的——容器只需要考虑存储数据、增减元素,遍历元素的工作则交由迭代器完成。如此可以达到该模式的设计意图:不需暴露集合的内部结构,又能让外部透明地访问集合内部的数据。
那么,直观的想,迭代器结构不应该很简单吗:
写一个 interface Iterator,并为其提供几个方法,如 getFirst(), getNext(), hasNext() 等;然后定义一个容器并实现 Iterator 接口。客户端编程时,对于容器的遍历,直接调用 getNext() 即可:
interface Iterator{
bool next(out object item);
}
class MyCollection: Iterator{
private object[] data = {123, 3.1415926, "中华民族"};
private int iter_index = 0;
public bool next(out object item){ // 集成了 hasNext() 方法
if(iter_index < data.Length){ // here use a length of data.
item = data[iter_index];
iter_index += 1;
return true;
}else{
iter_index = 0;
item = null;
return false;
}
}
}
class Demo{
static void Main(){
var list = new MyCollection();
for(object item; list.next(out item);){ // like this: foreach(var item in list)
Log.print($"Here is the item: {item}");
}
}
}
3.2.1. 思考
前面的这个实现,存在一些冗余,比如说:当我需要创建一个新的集合 MyCollection2,我需要重新实现一遍 next() 方法,而函数体结构基本相似——这说明,Iterator 接口可以独立为类,然后被多个容器复用:
class GeneralIterator: Iterator{
private ICollection _data;
public GeneralIterator(ICollection data){
this._data = data;
}
private int iter_index = 0;
public bool next(out object item){
if(iter_index < _data.size()){ // here use a length of data.
item = _data.item(iter_index); // here use a data value.
iter_index += 1;
return true;
}else{
iter_index = 0;
item = null;
return false;
}
}
}
注意原来的 next() 实现里,有两处与 ConcreteCollection 存在耦合——分别用到了数据长度和数据项。如果解耦,就需要将 Collection 抽象为接口,GeneralIterator 就可以面向接口编程了:
interface ICollection{
int size();
object item(int index);
Iterator iterator();
}
再看我们的自定义容器和客户端:
class MyCollection: ICollection{
private object[] _data = {123, 3.1415926, "中华民族"};
public object[] data => _data;
public int size(){ return _data.Length; }
public object item(int index){ return _data[index]; }
public Iterator iterator(){
return new GeneralIterator(this);
}
}
class Demo{
static void Main(){
var list = new MyCollection();
var iter = list.iterator();
for(object item; iter.next(out item);){ // like this: foreach(var item in list)
Log.print($"Here is the item: {item}");
}
}
}
3.2.2. 再思考
看看我们的 MyCollection 类就会发现,iterator() 其实是固定不变的——那么将这部分代码整合到 interface ICollection 中,就演变成了:
abstract class AbstractCollection{
public abstract int size();
public abstract object item(int index);
public Iterator iterator(){
return new GeneralIterator(this);
}
}
此时,如果创建一个新的容器,我们只需要继承 AbstractCollection 并重写 size() 和 item() 方法,即可默认实现迭代器。
class MyCollection2: AbstractCollection{
private object[] _data = {123, 3.1415926, "中华民族"};
public override int size(){ return _data.Length; }
public override object item(int index){ return _data[index]; }
}
现代化的编程语言,基本都实现了语言级别的容器和迭代器,例如: java.util.Iterable 和 C#::IEnumerator,所以迭代器模式更多的是学习和使用,而非再造轮子啦。
3.2.3. 继续思考:解析 foreach
C# 语言的 foreach 语句隐藏了枚举数的复杂性。因此,建议使用 foreach,而不是直接操作枚举数。其做的事情大概是这样:
IEnumerator<string> e = a.GetEnumerator();
while (e.MoveNext() ){
Log.print($"{e.Current}");
}
关于枚举数,用到了以下两个接口:
- IEnumerator,这是所有非泛型枚举器的基接口;
- IEnumerable,这是可枚举的所有非泛型集合的基接口。
具体的使用示例,请移步官网。
另外,博客《设计模式之美》中提供了多个示例,看上去很牛逼,给出链接。
3.2.4. 总结
我们再回到迭代器的设计初衷——提供一种方法顺序访问一个聚合对象中各个元素,而又不需暴露该对象的内部表示。
如果我们的对象不是容器,实际上就是提供一个访问接口: public Data get_data() ,这就根本不需要什么设计模式了。但容器类存在特殊性,它需要分几次返回若干个数据(每次一个),所以我们提炼了一个专门的对象来完成这件事—— iterator 。而 iterator 又需要 “通用化”、“标准化”,实现与具体的容器类解耦,就引发了上述的长篇过程。
3.3. 模板模式
Template Method
定义了一套算法的骨架(若干步骤),而将其中的一些步骤延迟到子类中实现。
Template Method 可调用下列类型的操作:
- 某操作,需要延迟到客户端才能实现
- Factory Method 方法
- 抽象操作(Primitive Operation):抽象类或接口中定义的方法
- 钩子操作(Hook Operation)(may be overridden),通常提供默认实现。
Template Method 需要指明哪些是 Hook Operation,哪些是 Primitive Operation。例如使用命名约定等方式指明。
3.3.1. 所谓钩子
抽象类提供实现(可能是空实现),子类进行选择性重写的方法。
3.4. 状态模式
State
3.4.1. 问题导入
引自《设计模式之禅》
平时乘坐的电梯(直梯),我们可以很容易的实现它的运动:open_door, close_door, move, stop。但问题来了:我们怎样保证,在执行了 move 方法后,电梯限制我们继续执行 open_door 或 close_door 以及重复执行 move 方法,而只允许我们做 stop 操作呢?控制逻辑如下:

3.4.2. 分析
直接的方式,就是增加 4 个成员变量,分别表示 4 个动作的执行状态,然后在每个动作方法的函数末尾,加上状态控制逻辑,并在下一次调用动作方法前检测状态变量。
但这个复杂但直接的思路,在需求进一步扩展时崩溃了:如果电梯可以停电(可能是为了维护),有要引入 “通电” 和“断电”两个成员变量?然后继续增加判断逻辑,并与之前的运行状态变量进行组合判断?
电梯有没有发生过只运行未停止的过程呢?比如说,从 10 楼直接坠下——电梯故障!
如果业务需要,增加 “电梯维修” 时在 stop 状态不允许开门的规则,又该怎么实现?
故而不断的通过成员变量控制,并不是问题的解决方式——这也不符合 “单一职责原则”:业务上一个小改动,会导致电梯类整体的修改,这种设计在项目开发上是有很大风险的。
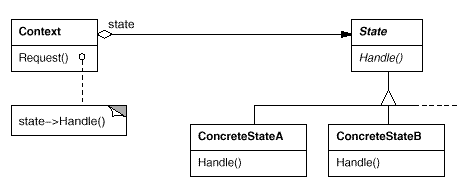
状态量也可以作为对象,而且也有着它的行为——控制状态:
interface ILiftStatus{
bool check_open_door();
bool check_close_door();
bool check_move();
bool check_stop();
}
class OpenningStatus: ILiftStatus{
public bool check_open_door(){ Console.WriteLine("不能执行open_door"); return false; }
public bool check_close_door(){ return true; }
public bool check_move(){ Console.WriteLine("不能执行move"); return false; }
public bool check_stop(){ Console.WriteLine("不能执行stop"); return false; }
}
// 同理定义出其他的各种状态类
class ClosingStatus: ILiftStatus{ }
class MovingStatus: ILiftStatus{ }
class StopingStatus: ILiftStatus{ }
当然你也可以将 ILiftStatus 改为 class 并将方法改为钩子(提供一个 return true 的默认行为)。
class Lift{
private ILiftStatus curr_status; // 一个 ConcreteState 的实例
private OpenningStatus open_status = new OpenningStatus();
...
public Lift(ILiftStatus initial_status=null){ ... } // 这都不是重点
public void open_door(){
if(curr_status.check_open_door()){ // 状态监测
Console.WriteLine("开门");
this.curr_status = this.open_status; // 状态更新
}
}
// 同理,提供其他动作的实现
...
}
3.4.3. Python 模式
# 每个状态记录着 Allow 选项
OpenningStatus = ["close"]
ClosingStatus = ["open", "move", "stop"]
MovingStatus = ["stop"]
StoppingStatus = ["open", "move"]
class Lift:
def __init__(self):
self._currStatus = StoppingStatus
def open_door(self):
if "open" in self._currStatus:
print("开门")
self._currStatus = OpenningStatus
else: print("无法执行操作")
def close_door(self):
...
对 Python 来说,由于语言级 in 的支持,一切就是这么简单(什么是语言级?比方说 C# 中 foreach 对迭代器的支持)
3.4.4. 总结
在以下情况下可以使用 State 模式:
- 一个对象的行为取决于它的状态,并且它必须在运行时根据状态改变它的行为。
- 一个操作中含有庞大的多分支的条件语句,且这些分支依赖于该对象的状态。
状态模式将状态从对象中解耦,对象(Context)需要维护一个 ConcreteState 子类的实例,这个实例定义当前状态。IState 接口定义了一组接口,代表某个特定状态的行为;每一个 ConcreteState 子类都将实现一个与 Context 的状态相关的行为。