温馨提示:以下所有文字都是本人自己的理解,有什么问题可以在下面的评论进行留言,一起探讨 谢谢支持!!!
概念
MySQL 属于关系型数据库管理系统(RDBMS),在关系型数据库中有一些专业的术语:
- 数据库 :关联表的一种集合
- 数据表:一张数据库中的电子表格
- 列:是一种数据元素,包含了相同的信息
- 行:行等于元组,存放一些相关的信息
- 主键:主键是唯一的, 你可以使用主键查询数据
- 外键:关联多个表
- 复合键:将多个列作为一个索引键,一般用于复合查询
- 索引:对数据表中的一列或者多列进行排序的一种数据结构
- 冗余:将数据存为两份,减少了性能,但是提高的安全性
- 参照完整性:不允许表中引用不存在的实体。保证数据的一致性
MySQL数据库就是把数据存放在不同的表中,而不是存在一个大仓库中,这样就提高了速度和灵活性
MySQL 也有一些自己的优点,如下:
- MySQL是不需要花钱的,开源的(但是现在的MySQL好像也是不开源了)
- MySQL对多种语言的支持很好(PHP,java,python等)
- MySQL是可定制的,也就是你可以对MySQL进行二次开发,像是阿里自己开发AliSQL
- MySQL允许运行在多个系统上
- MySQL支持大型数据库,可以处理千万级的数据记录,支持5000万条记录的数据仓库,32位系统表文件最大可支持4GB,64位系统支持最大的表文件为8TB。
MySQL的缺点,如下:
- 不支持热备份
- 对原生JSON支持的缺乏
- 不支持自定义数据类型
- 安全系统,主要是复杂而非标准,另外只有到调用mysqladmin来重读用户权限时才发生改变;
安装
想要快捷的安装MySQL 请点击这里:MySQL yum安装
数据库操作
连接MySQL
安装完成后,我们需要连接到数据库进行操作:
连接本地MySQL:
# 语法: mysql -u 用户名 -p密码 # 实例 mysql -uroot -p
连接其他主机MySQL,前提是保证网络和端口之间可通
# 语法 mysql -h MySQL主机IP -P MySQL端口 -u 用户名 -p 密码 #实例 mysql -h 192.168.1.11 -P3306 -u root -p
截图:
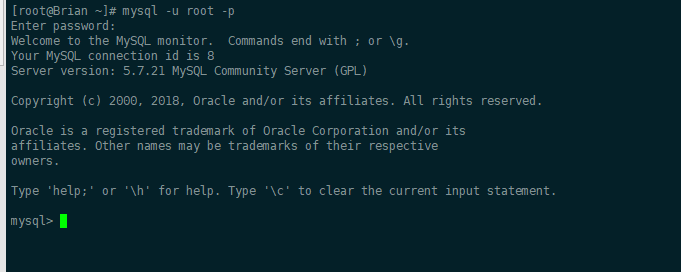
看到这个输出就说明了登录成功,用户只要有权限就可以在这里执行任何的SQL语句了,当然这显然是不安全的。
创建数据库
在MySQL中创建数据库,有两种方式,也是我知道的两种方式:
第一种就是使用mysqladmin 来创建:
[root@Brian ~]# mysqladmin -uroot -p create Brian Enter password: # 输入密码回车,密码正确数据库创建成功
我们也可以不登录到终端查看已有的数据库
[root@Brian ~]# mysql -u root -p -e "show databases" Enter password: +--------------------+ | Database | +--------------------+ | information_schema | | Brian | # 我们使用mysqladmin新建的数据库 | mysql | | performance_schema | | sys | +--------------------+
第二种就是使用sql语句来创建:
[root@Brian ~]# mysql -uroot -p # 登录数据库 Enter password: Welcome to the MySQL monitor. Commands end with ; or g. Your MySQL connection id is 18 Server version: 5.7.21 MySQL Community Server (GPL) Copyright (c) 2000, 2018, Oracle and/or its affiliates. All rights reserved. Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners. Type 'help;' or 'h' for help. Type 'c' to clear the current input statement. mysql> create database if not exists Brianzhu default charset utf8 collate utf8_general_ci; # 新建数据库 Query OK, 1 row affected (0.00 sec) mysql> show databases; # 查看数据库 +--------------------+ | Database | +--------------------+ | information_schema | | Brian | | Brianzhu | # 这个就是我们新建的库 | mysql | | performance_schema | | sys | +--------------------+ 6 rows in set (0.00 sec) mysql>
这条新建数据库的命令:(create database if not exists Brianzhu default charset utf8 collate utf8_general_ci; )意思就是:
- 如果数据库存在不创建,不存在则创建。
- 创建名为BrianZhu的数据库 ,设置字符编码为utf8
选择数据库
在连接到数据库后,肯定会有很多的库,我们不能同时的去操作所有的库,只能选择一个库来进行操作:
[root@Brian ~]# mysql -uroot -p # 登录数据库 Enter password: Welcome to the MySQL monitor. Commands end with ; or g. Your MySQL connection id is 22 Server version: 5.7.21 MySQL Community Server (GPL) Copyright (c) 2000, 2018, Oracle and/or its affiliates. All rights reserved. Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners. Type 'help;' or 'h' for help. Type 'c' to clear the current input statement. mysql> use Brianzhu; # 选择数据库 Database changed mysql>
执行完成上面的的sql语句 我们就成功的切换到了选择的数据库,前提是数据库存在,不存在报错,在执行sql就是在我们选择的库中执行了
我们可以用sql的status命令来查看一些信息,也包括我们现在所在的库名
mysql> status; # 执行 -------------- mysql Ver 14.14 Distrib 5.7.21, for Linux (x86_64) using EditLine wrapper Connection id: 22 Current database: Brianzhu # 这个就是我们现在所在库的名称 Current user: root@localhost SSL: Not in use Current pager: stdout Using outfile: '' Using delimiter: ; Server version: 5.7.21 MySQL Community Server (GPL) Protocol version: 10 Connection: Localhost via UNIX socket Server characterset: latin1 Db characterset: utf8 Client characterset: utf8 Conn. characterset: utf8 UNIX socket: /var/lib/mysql/mysql.sock Uptime: 1 hour 47 min 58 sec Threads: 4 Questions: 44 Slow queries: 0 Opens: 109 Flush tables: 1 Open tables: 102 Queries per second avg: 0.006 -------------- mysql>
注:下面的在数据库中的一些sql语句的执行,我就不粘贴登录到的代码了 ,这样会显的清晰一些,只要是执行sql就要登录到MySQL终端中。
查看数据库
查看MySQL中的所有的数据库:
mysql> show databases; +--------------------+ | Database | +--------------------+ | information_schema | | Brian | | Brianzhu | | mysql | | performance_schema | | sys | +--------------------+ 6 rows in set (0.00 sec) mysql>
删除数据库
删除数据库和创建数据库一样也是有两种方式:
第一种是使用mysqladmin操作:
[root@Brian ~]# mysqladmin -uroot -p drop Brian # 执行 Enter password: Dropping the database is potentially a very bad thing to do. Any data stored in the database will be destroyed. Do you really want to drop the 'Brian' database [y/N] y # 这里提示是否删除 Database "Brian" dropped
删除后我们执行下面命令查看:
[root@Brian ~]# mysql -u root -p -e "show databases" Enter password: +--------------------+ | Database | +--------------------+ | information_schema | | Brianzhu | | mysql | | performance_schema | | sys | +--------------------+
可以看到Brian库已经删除
第二种是登录MySQL终端操作:
mysql> drop database if exists Brianzhu; Query OK, 0 rows affected (0.01 sec)
上面sql的意思是 先判断库是否存在在执行删除
查看结果:
mysql> show databases; +--------------------+ | Database | +--------------------+ | information_schema | | mysql | | performance_schema | | sys | +--------------------+ 4 rows in set (0.00 sec)
已经被删除
数据表操作
支持的数据类型
MySQL中对数据类型的支持,其实就有三种
- 数值
- 字符串
- 时间
数值
数值类型包括:
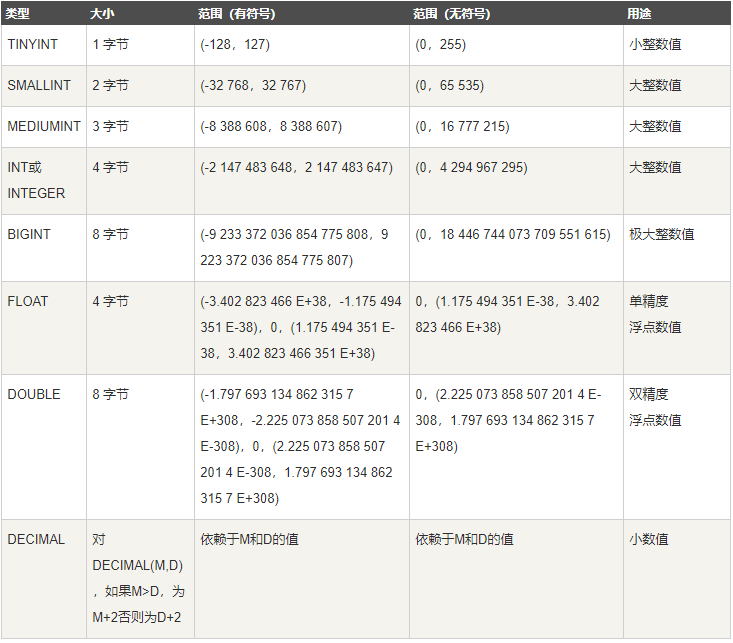
表示字符串的值为:char、varchar、binary、varbinary、blob、text、enum、set
字符串类型包括:
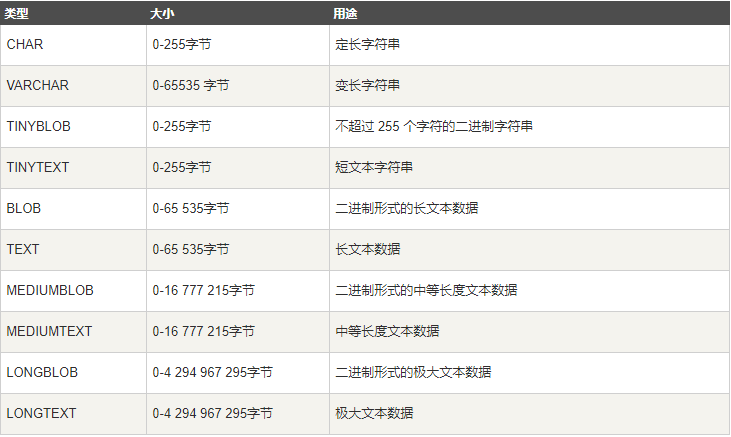
char和varchar类型类似,但是他们的保存和检索的方式不同,在存储和检索的过程中不进行大小写的转换
表示时间值的日期与时间类型为:datetime、date、timestamp、time、year
每个时间类型都有一个有效的取值范围和一个零值,在指定不合法的MySQL不能表示的值的时候用零表示
时间类型包括:
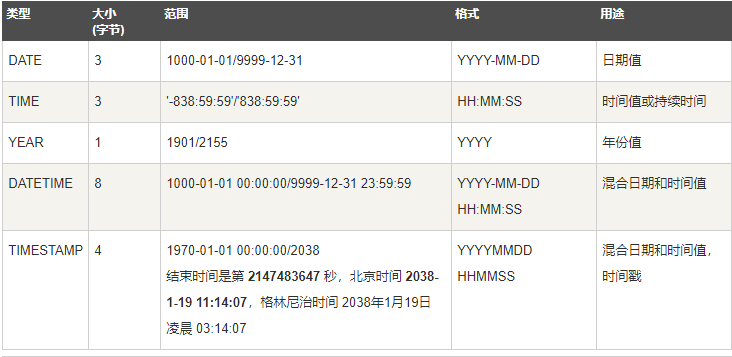
创建数据表
每个表都要有的三个必要的信息:
- 表名
- 字段名
- 定义字段
语法
create table 表名 (字段名,字段类型)
在Brian库中创建个brian的表:
mysql> use Brian
Database changed
mysql> create table if not exists `brian`(
-> `id` int unsigned auto_increment,
-> `title` varchar(100) not null,
-> `name` varchar(50) not null,
-> `submission_data` date,
-> primary key (`id`)
-> )engine=innodb default charset=utf8;
Query OK, 0 rows affected (0.13 sec)
SQL解析:
- unsigned属性就是将数字类型无符号化,INT的类型范围是-2 147 483 648 ~ 2 147 483 647, INT UNSIGNED的范围类型就是0 ~ 4 294 967 295。
- auto_increment:定义列为自增的属性,一般为主键,数值加1
- not null:字段不能为空,为空则报错
- primary key:设置主键,可以为多个主键,用逗号隔开
- engine:存储引擎
- charset:设置字符编码
附赠一些编程语言创建数据表实例:
Python:
Java:
PHP:
GO:
删除数据表
注:删除是个非常危险的操作,一定谨慎,但是删除很简单
语法
drop table 表名;
删除刚刚新建的brian表:
mysql> drop table brian; Query OK, 0 rows affected (0.07 sec) mysql>
附赠一些编程语言删除数据表实例:
Python:
Java:
PHP:
GO:
查询表结构
语法:
show columns from 表名;
查询 customers 表结构;
mysql> show columns from customers; +---------+----------+------+-----+-----------+----------------+ | Field | Type | Null | Key | Default | Extra | +---------+----------+------+-----+-----------+----------------+ | id | int(11) | NO | PRI | NULL | auto_increment | | name | char(20) | NO | | NULL | | | address | char(50) | YES | | NULL | | | city | char(50) | YES | | NULL | | | age | int(11) | NO | | NULL | | | love | char(50) | NO | | No habbit | | +---------+----------+------+-----+-----------+----------------+ 6 rows in set (0.00 sec)
修改数据表
首先在Brian库中创建一个表,对新创建的表进行操作:
create table customers(
id int not null auto_increment,
name char(20) not null,
address char(50) null,
city char(50) null,
age int not null,
love char(50) not null default 'No habbit',
primary key(id)
)engine=InnoDB;
先查看上面我们新建表的表结构:
mysql> show columns from customers; +---------+----------+------+-----+-----------+----------------+ | Field | Type | Null | Key | Default | Extra | +---------+----------+------+-----+-----------+----------------+ | id | int(11) | NO | PRI | NULL | auto_increment | | name | char(20) | NO | | NULL | | | address | char(50) | YES | | NULL | | | city | char(50) | YES | | NULL | | | age | int(11) | NO | | NULL | | | love | char(50) | NO | | No habbit | | +---------+----------+------+-----+-----------+----------------+ 6 rows in set (0.00 sec)
更改表结构(删除、添加表字段):
# 添加字段 mysql> alter table customers add des int first; Query OK, 0 rows affected (0.12 sec) Records: 0 Duplicates: 0 Warnings: 0 mysql> alter table customers add des_one int after love; Query OK, 0 rows affected (0.13 sec) Records: 0 Duplicates: 0 Warnings: 0 # 删除字段 mysql> alter table customers drop age; Query OK, 0 rows affected (0.16 sec) Records: 0 Duplicates: 0 Warnings: 0
如果你需要指定新增字段的位置,可以使用MySQL提供的关键字 FIRST (设定位第一列), AFTER 字段名(设定位于某个字段之后)。
FIRST 和 AFTER 关键字只占用于 ADD 子句,所以如果你想重置数据表字段的位置就需要先使用 DROP 删除字段然后使用 ADD 来添加字段并设置位置。
在次查看表结构:
mysql> show columns from customers; +---------+----------+------+-----+-----------+----------------+ | Field | Type | Null | Key | Default | Extra | +---------+----------+------+-----+-----------+----------------+ | des | int(11) | YES | | NULL | | | id | int(11) | NO | PRI | NULL | auto_increment | | name | char(20) | NO | | NULL | | | address | char(50) | YES | | NULL | | | city | char(50) | YES | | NULL | | | love | char(50) | NO | | No habbit | | | des_one | int(11) | YES | | NULL | | +---------+----------+------+-----+-----------+----------------+ 7 rows in set (0.00 sec)
和原始的表结构进行对比,就会发现很多不同的地方了吧
修改字段类型及名称:
如果需要修改字段类型及名称, 你可以在ALTER命令中使用 MODIFY 或 CHANGE 子句 。
MODIFY 参数示例
# 把字段name的类型char(20)改为char(50) mysql> alter table customers modify name char(50); Query OK, 0 rows affected (0.21 sec) Records: 0 Duplicates: 0 Warnings: 0
使用 CHANGE 子句, 语法有很大的不同。 在 CHANGE 关键字之后,紧跟着的是你要修改的字段名,然后指定新字段名及类型
# 修改des字段的名字和类型 mysql> alter table customers change des dess bigint; Query OK, 0 rows affected (0.21 sec) Records: 0 Duplicates: 0 Warnings: 0 mysql> alter table customers change dess dess int; Query OK, 0 rows affected (0.20 sec) Records: 0 Duplicates: 0 Warnings: 0
修改字段默认值:
# 修改love字段的默认值 mysql> alter table customers alter love set default 1000; Query OK, 0 rows affected (0.04 sec) Records: 0 Duplicates: 0 Warnings: 0 # 查看是否修改 mysql> show columns from customers; +---------+----------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +---------+----------+------+-----+---------+----------------+ | dess | int(11) | YES | | NULL | | | id | int(11) | NO | PRI | NULL | auto_increment | | name | char(50) | YES | | NULL | | | address | char(50) | YES | | NULL | | | city | char(50) | YES | | NULL | | | love | char(50) | NO | | 1000 | | | des_one | int(11) | YES | | NULL | | +---------+----------+------+-----+---------+----------------+ 7 rows in set (0.01 sec)
你也可以使用 ALTER 命令及 DROP子句来删除字段的默认值:
# 删除love字段的默认值 mysql> alter table customers alter love drop default; Query OK, 0 rows affected (0.01 sec) Records: 0 Duplicates: 0 Warnings: 0 # 查看是否修改 mysql> show columns from customers; +---------+----------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +---------+----------+------+-----+---------+----------------+ | dess | int(11) | YES | | NULL | | | id | int(11) | NO | PRI | NULL | auto_increment | | name | char(50) | YES | | NULL | | | address | char(50) | YES | | NULL | | | city | char(50) | YES | | NULL | | | love | char(50) | NO | | NULL | | | des_one | int(11) | YES | | NULL | | +---------+----------+------+-----+---------+----------------+ 7 rows in set (0.00 sec)
注意:查看数据表类型可以使用 SHOW TABLE STATUS 语句
mysql> show table status like 'customers'G
*************************** 1. row ***************************
Name: customers
Engine: InnoDB
Version: 10
Row_format: Dynamic
Rows: 0
Avg_row_length: 0
Data_length: 16384
Max_data_length: 0
Index_length: 0
Data_free: 0
Auto_increment: 1
Create_time: 2018-04-11 15:48:03
Update_time: NULL
Check_time: NULL
Collation: utf8_general_ci
Checksum: NULL
Create_options:
Comment:
1 row in set (0.00 sec)
修改表名:
# 修改customers 表名为customers_test mysql> alter table customers rename to customers_test; Query OK, 0 rows affected (0.02 sec) # 查看是否修改 mysql> show tables; +-----------------+ | Tables_in_Brian | +-----------------+ | brian | | customers_test | | runoob_tbl | +-----------------+ 3 rows in set (0.00 sec)
alter其他用途:
# 修改存储引擎:修改为myisam alter table tableName engine=myisam; # 删除外键约束:keyName是外键别名 alter table tableName drop foreign key keyName; # 修改字段的相对位置:这里name1为想要修改的字段,type1为该字段原来类型,first和after二选一,这应该显而易见,first放在第一位,after放在name2字段后面 alter table tableName modify name1 type1 first|after name2;
数据表数据操作
插入数据
MySQL 表中使用insert into 来完成表中插入数据的实现
语法:
insert into table_name ( field1, field2,...fieldN )
VALUES
( value1, value2,...valueN );
注:如果数据是字符型,必须使用单引号或者双引号,如:"value"。
我们往下面的brian表中插入数据:
表结构:
mysql> show columns from brian; +-----------------+------------------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +-----------------+------------------+------+-----+---------+----------------+ | id | int(10) unsigned | NO | PRI | NULL | auto_increment | | title | varchar(100) | NO | | NULL | | | name | varchar(50) | NO | | NULL | | | submission_data | date | YES | | NULL | | +-----------------+------------------+------+-----+---------+----------------+ 4 rows in set (0.00 sec)
开始插入数据:
mysql> use Brian; # 选择数据库
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
mysql> insert into brian(title,name,submission_data) value ("唐人街探案","唐人","2016-01-10");
Query OK, 1 row affected (0.01 sec)
mysql> insert into brian(title,name,submission_data) value ("哈哈哈","哈",NOW());
Query OK, 1 row affected, 1 warning (0.01 sec)
mysql> insert into brian(title,name,submission_data) value ("大鱼海棠","大鱼",NOW());
Query OK, 1 row affected (0.01 sec)
我们并没有提供 id 的数据,因为该字段我们在创建表的时候已经设置它为 AUTO_INCREMENT(自动增加) 属性。 所以,该字段会自动递增而不需要我们去设置。实例中 NOW() 是一个 MySQL 函数,该函数返回日期和时间。
附赠一些编程语言插入数据实例:
Python:
Java:
PHP:
GO:
读取数据
语法:
select column_name,column_name from table_name [where clause] [limit n][offset m]
-
查询语句中你可以使用一个或者多个表,表之间使用逗号(,)分割,并使用WHERE语句来设定查询条件。
-
select 命令可以读取一条或者多条记录。
-
你可以使用星号(*)来代替其他字段,SELECT语句会返回表的所有字段数据。
-
你可以使用 WHERE 语句来包含任何条件。
-
你可以使用 LIMIT 属性来设定返回的记录数。
-
你可以通过OFFSET指定SELECT语句开始查询的数据偏移量。默认情况下偏移量为0。
我们读取刚刚插入的全部数据:
mysql> select * from brian; +----+-----------------+--------+-----------------+ | id | title | name | submission_data | +----+-----------------+--------+-----------------+ | 1 | 大鱼海棠 | 大鱼 | 2018-04-11 | | 2 | 唐人街探案 | 唐人 | 2016-01-10 | | 3 | 哈哈哈 | 哈 | 2018-04-11 | +----+-----------------+--------+-----------------+ 3 rows in set (0.00 sec)
使用where读取name等于哈的数据:
mysql> select * from brian where name="哈"; +----+-----------+------+-----------------+ | id | title | name | submission_data | +----+-----------+------+-----------------+ | 3 | 哈哈哈 | 哈 | 2018-04-11 | +----+-----------+------+-----------------+ 1 row in set (0.00 sec)
修改数据
语法:
语法:update 表名 set 字段=新值,… where 条件
-
UPDATE语法可以用新值更新原有表行中的各列。
-
SET子句指示要修改哪些列和要给予哪些值。
-
WHERE子句指定应更新哪些行。如果没有WHERE子句,则更新所有的行。
-
如果指定了ORDER BY子句,则按照被指定的顺序对行进行更新。
-
LIMIT子句用于给定一个限值,限制可以被更新的行的数目。
我们把name=哈 改成name=嘿嘿:
mysql> update brian set name="嘿嘿" where id=3; Query OK, 1 row affected (0.02 sec) Rows matched: 1 Changed: 1 Warnings: 0 mysql> select * from brian where id=3; +----+-----------+--------+-----------------+ | id | title | name | submission_data | +----+-----------+--------+-----------------+ | 3 | 哈哈哈 | 嘿嘿 | 2018-04-11 | +----+-----------+--------+-----------------+ 1 row in set (0.00 sec)
删除数据
MySQL删除表中的数据有两种方式:
delete from 表名; truncate table 表名; # 这个两种方式的区别: 不带where参数的delete语句可以删除mysql表中所有内容,使用truncate table也可以清空mysql表中所有内容。 效率上truncate比delete快,但truncate删除后不记录mysql日志,不可以恢复数据。 delete的效果有点像将mysql表中所有记录一条一条删除到删完, 而truncate相当于保留mysql表的结构,重新创建了这个表,所有的状态都相当于新表。
我们删除name=嘿嘿的这条数据:
mysql> delete from brian where name="嘿嘿"; Query OK, 1 row affected (0.01 sec) mysql> select * from brian where id=3; Empty set (0.00 sec) mysql> select * from brian; +----+-----------------+--------+-----------------+ | id | title | name | submission_data | +----+-----------------+--------+-----------------+ | 1 | 大鱼海棠 | 大鱼 | 2018-04-11 | | 2 | 唐人街探案 | 唐人 | 2016-01-10 | +----+-----------------+--------+-----------------+ 2 rows in set (0.00 sec)
数据进行排序
如果我们需要对读取的数据进行排序,我们就可以使用 MySQL 的 ORDER BY 子句来设定你想按哪个字段哪种方式来进行排序,再返回搜索结果。
语法:
SELECT field1, field2,...fieldN table_name1, table_name2... ORDER BY field1, [field2...] [ASC [DESC]]
-
你可以使用任何字段来作为排序的条件,从而返回排序后的查询结果
-
你可以设定多个字段来排序。
-
你可以使用 ASC 或 DESC 关键字来设置查询结果是按升序或降序排列。 默认情况下,它是按升序排列。
-
你可以添加 WHERE...LIKE 子句来设置条件。
下面示例对分别对升序和降序示例:
mysql> select * from brian order by submission_data asc; +----+-----------------+--------+-----------------+ | id | title | name | submission_data | +----+-----------------+--------+-----------------+ | 5 | 哈哈哈 | 哈s | 2011-02-21 | | 2 | 唐人街探案 | 唐人 | 2016-01-10 | | 1 | 大鱼海棠 | 大鱼 | 2018-04-11 | | 4 | 哈哈哈 | 哈 | 2018-04-11 | +----+-----------------+--------+-----------------+ 4 rows in set (0.00 sec) mysql> select * from brian order by submission_data desc; +----+-----------------+--------+-----------------+ | id | title | name | submission_data | +----+-----------------+--------+-----------------+ | 1 | 大鱼海棠 | 大鱼 | 2018-04-11 | | 4 | 哈哈哈 | 哈 | 2018-04-11 | | 2 | 唐人街探案 | 唐人 | 2016-01-10 | | 5 | 哈哈哈 | 哈s | 2011-02-21 | +----+-----------------+--------+-----------------+ 4 rows in set (0.00 sec)
数据分组
GROUP BY 语句根据一个或多个列对结果集进行分组。
在分组的列上我们可以使用 COUNT, SUM, AVG,等函数。
语法:
SELECT column_name, function(column_name) FROM table_name WHERE column_name operator value GROUP BY column_name;
实例演示:
新建表:
CREATE TABLE `employee_tbl` ( `id` INT ( 11 ) NOT NULL, `name` CHAR ( 10 ) NOT NULL DEFAULT '', `date` datetime NOT NULL, `singin` TINYINT ( 4 ) NOT NULL DEFAULT '0' COMMENT '登录次数', PRIMARY KEY ( `id` ) ) ENGINE = INNODB DEFAULT CHARSET = utf8;
插入数据:
INSERT INTO `employee_tbl` VALUES ('1', '小明', '2016-04-22 15:25:33', '1'), ('2', '小王', '2016-04-20 15:25:47', '3'), ('3', '小丽', '2016-04-19 15:26:02', '2'), ('4', '小王', '2016-04-07 15:26:14', '4'), ('5', '小明', '2016-04-11 15:26:40', '4'), ('6', '小明', '2016-04-04 15:26:54', '2');
查看数据:
mysql> select * from employee_tbl; +----+--------+---------------------+--------+ | id | name | date | singin | +----+--------+---------------------+--------+ | 1 | 小明 | 2016-04-22 15:25:33 | 1 | | 2 | 小王 | 2016-04-20 15:25:47 | 3 | | 3 | 小丽 | 2016-04-19 15:26:02 | 2 | | 4 | 小王 | 2016-04-07 15:26:14 | 4 | | 5 | 小明 | 2016-04-11 15:26:40 | 4 | | 6 | 小明 | 2016-04-04 15:26:54 | 2 | +----+--------+---------------------+--------+ 6 rows in set (0.00 sec)
接下来我们使用 GROUP BY 语句 将数据表按名字进行分组,并统计每个人有多少条记录:
mysql> select name, count(*) from employee_tbl group by name; +--------+----------+ | name | count(*) | +--------+----------+ | 小丽 | 1 | | 小明 | 3 | | 小王 | 2 | +--------+----------+ 3 rows in set (0.00 sec)
WITH ROLLUP 可以实现在分组统计数据基础上再进行相同的统计(SUM,AVG,COUNT…)。
例如我们将以上的数据表按名字进行分组,再统计每个人登录的次数:
mysql> select name, sum(singin) as singin_connt from employee_tbl group by name with rollup; +--------+--------------+ | name | singin_connt | +--------+--------------+ | 小丽 | 2 | | 小明 | 7 | | 小王 | 7 | | NULL | 16 | +--------+--------------+ 4 rows in set (0.00 sec)
其中记录 NULL 表示所有人的登录次数。
我们可以使用 coalesce 来设置一个可以取代 NUll 的名称,coalesce 语法:
select coalesce(a,b,c);
参数说明:如果a==null,则选择b;如果b==null,则选择c;如果a!=null,则选择a;如果a b c 都为null ,则返回为null(没意义)。
以下实例中如果名字为空我们使用总数代替:
mysql> select coalesce(name,'总数'),sum(singin) as singin_connt from employee_tbl group by name with rollup; +-------------------------+--------------+ | coalesce(name,'总数') | singin_connt | +-------------------------+--------------+ | 小丽 | 2 | | 小明 | 7 | | 小王 | 7 | | 总数 | 16 | +-------------------------+--------------+ 4 rows in set (0.00 sec)
内外连接
一张表的操作很简单,但是在真实的生产环境中 ,怎么可能会是一张表呢 所有这里我们就开始使用多张表进行操作了
MySQL 的 JOIN 在两个或多个表中查询数据。
你可以在 SELECT, UPDATE 和 DELETE 语句中使用 Mysql 的 JOIN 来联合多表查询。
JOIN 按照功能大致分为如下三类:
-
INNER JOIN(内连接,或等值连接):获取两个表中字段匹配关系的记录。
-
LEFT JOIN(左连接):获取左表所有记录,即使右表没有对应匹配的记录。
-
RIGHT JOIN(右连接): 与 LEFT JOIN 相反,用于获取右表所有记录,即使左表没有对应匹配的记录。
union sql语句连接查询
MySQL UNION 操作符用于连接两个以上的 SELECT 语句的结果组合到一个结果集合中。多个 SELECT 语句会删除重复的数据。
语法:
SELECT expression1, expression2, ... expression_n FROM tables [WHERE conditions] UNION [ALL | DISTINCT] SELECT expression1, expression2, ... expression_n FROM tables [WHERE conditions];
参数:
-
expression1, expression2, ... expression_n: 要检索的列
-
tables: 要检索的数据表。
-
WHERE conditions: 可选, 检索条件
-
DISTINCT: 可选,删除结果集中重复的数据。默认情况下 UNION 操作符已经删除了重复数据,所以 DISTINCT 修饰符对结果没啥影响
-
ALL: 可选,返回所有结果集,包含重复数据
实例:
mysql> select name from brian
-> union
-> select name from employee_tbl
-> order by name;
+--------+
| name |
+--------+
| 哈 |
| 哈s |
| 唐人 |
| 大鱼 |
| 小丽 |
| 小明 |
| 小王 |
+--------+
7 rows in set (0.00 sec)
mysql> select name from brian union all select name from employee_tbl order by name; +--------+ | name | +--------+ | 哈 | | 哈s | | 唐人 | | 大鱼 | | 小丽 | | 小明 | | 小明 | | 小明 | | 小王 | | 小王 | +--------+ 10 rows in set (0.00 sec)
like 模糊匹配
SQL LIKE 子句中使用百分号 %字符来表示任意字符,类似于UNIX或正则表达式中的星号 *。
如果没有使用百分号 %, LIKE 子句与等号 = 的效果是一样的。
语法:
SELECT field1, field2,...fieldN FROM table_name WHERE field1 LIKE condition1 [AND [OR]] filed2 = 'somevalue'
-
你可以在 WHERE 子句中指定任何条件。
-
你可以在 WHERE 子句中使用LIKE子句。
-
你可以使用LIKE子句代替等号 =。
-
LIKE 通常与 % 一同使用,类似于一个元字符的搜索
-
你可以使用 AND 或者 OR 指定一个或多个条件
-
你可以在 DELETE 或 UPDATE 命令中使用 WHERE...LIKE 子句来指定条件
具体实例:
正则表达式
MySQL 同样也支持其他正则表达式的匹配, MySQL中使用 REGEXP 操作符来进行正则表达式匹配
下表中的正则模式可应用于 REGEXP 操作符中。
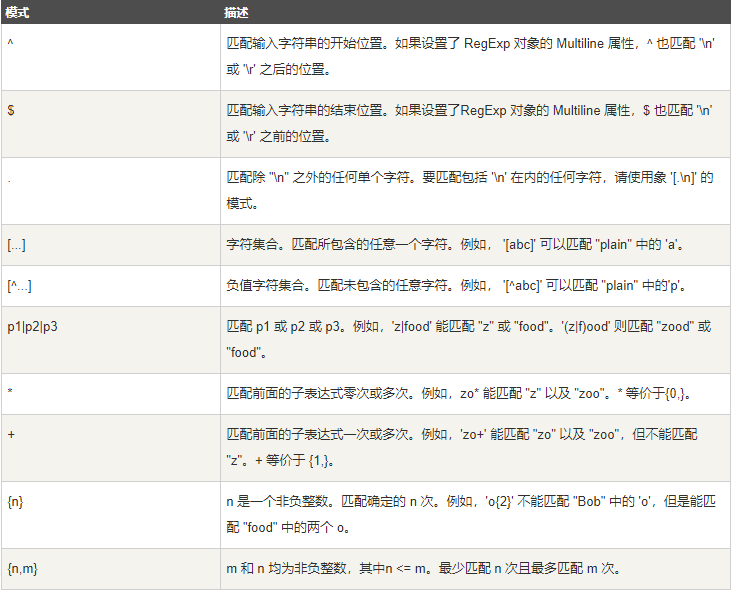
实例:
# 查找name字段中以'st'为开头的所有数据 mysql> SELECT name FROM person_tbl WHERE name REGEXP '^st'; # 查找name字段中以'ok'为结尾的所有数据 mysql> SELECT name FROM person_tbl WHERE name REGEXP 'ok$'; # 查找name字段中包含'mar'字符串的所有数据 mysql> SELECT name FROM person_tbl WHERE name REGEXP 'mar'; # 查找name字段中以元音字符开头或以'ok'字符串结尾的所有数据 mysql> SELECT name FROM person_tbl WHERE name REGEXP '^[aeiou]|ok$';
Null 值处理
MySQL 使用 SQL SELECT 命令及 WHERE 子句来读取数据表中的数据,但是当提供的查询条件字段为 NULL 时,该命令可能就无法正常工作
为了处理这种情况,MySQL提供了三大运算符:
- IS NULL: 当列的值是 NULL,此运算符返回 true
- IS NOT NULL: 当列的值不为 NULL, 运算符返回 true
- <=>: 比较操作符(不同于=运算符),当比较的的两个值为 NULL 时返回 true
关于 NULL 的条件比较运算是比较特殊的。你不能使用 = NULL 或 != NULL 在列中查找 NULL 值 。
在 MySQL 中,NULL 值与任何其它值的比较(即使是 NULL)永远返回 false,即 NULL = NULL 返回false 。
MySQL 中处理 NULL 使用 IS NULL 和 IS NOT NULL 运算符。
实例:
创建表:
mysql> create table test_db(
-> test1 varchar(40) NOT NULL,
-> test2 int
-> ;
Query OK, 0 rows affected (0.16 sec)
插入数据:
mysql> insert into test_db (test1, test2) values ('qq', 20);
Query OK, 1 row affected (0.01 sec)
mysql> insert into test_db (test1, test2) values ('aa', NULL);
Query OK, 1 row affected (0.04 sec)
mysql> insert into test_db (test1, test2) values ('cc', NULL);
Query OK, 1 row affected (0.01 sec)
mysql> insert into test_db (test1, test2) values ('pp', NULL);
Query OK, 1 row affected (0.04 sec)
mysql> insert into test_db (test1, test2) values ('pp', 20);
Query OK, 1 row affected (0.01 sec)
查看数据:
mysql> select * from test_db; +-------+-------+ | test1 | test2 | +-------+-------+ | qq | 20 | | aa | NULL | | cc | NULL | | pp | NULL | | pp | 20 | +-------+-------+ 5 rows in set (0.00 sec)
查找数据表中 列是否为 NULL,必须使用 IS NULL 和 IS NOT NULL,如下实例:
mysql> SELECT * FROM test_db WHERE test2 IS NULL; +-------+-------+ | test1 | test2 | +-------+-------+ | aa | NULL | | cc | NULL | | pp | NULL | +-------+-------+ 3 rows in set (0.00 sec) mysql> SELECT * from test_db WHERE test2 IS NOT NULL; +-------+-------+ | test1 | test2 | +-------+-------+ | qq | 20 | | pp | 20 | +-------+-------+ 2 rows in set (0.00 sec)
高级功能
事务
MySQL 主要用于处理操作量大,复杂度高的数据,比如:删除一个人要删除这个人的所有信息,这些sql就成了一个数据库的事物
- 在MySQL中只有innodb引擎的库或者表才支持事务。
- 事务可以用来维护数据库的完整性,保证批量的sql要么全部执行,要么全部不执行。
- 事务用来管理insert、update、delete语句。
一般来说,事务是必须满足4个条件:
- 原子性:一个事务(transaction)中的所有操作,要么全部完成,要么全部不完成,不会结束在中间某个环节。事务在执行过程中发生错误,会被回滚(Rollback)到事务开始前的状态,就像这个事务从来没有执行过一样。
- 一致性:在事务开始之前和事务结束以后,数据库的完整性没有被破坏。这表示写入的资料必须完全符合所有的预设规则,这包含资料的精确度、串联性以及后续数据库可以自发性地完成预定的工作。
- 隔离性:数据库允许多个并发事务同时对其数据进行读写和修改的能力,隔离性可以防止多个事务并发执行时由于交叉执行而导致数据的不一致。事务隔离分为不同级别,包括读未提交(Read uncommitted)、读提交(read committed)、可重复读(repeatable read)和串行化(Serializable)。
- 持久性:事务处理结束后,对数据的修改就是永久的,即便系统故障也不会丢失。
事务控制语句:
- BEGIN或START TRANSACTION;显式地开启一个事务
- COMMIT;也可以使用COMMIT WORK,不过二者是等价的。COMMIT会提交事务,并使已对数据库进行的所有修改称为永久性的
- ROLLBACK;有可以使用ROLLBACK WORK,不过二者是等价的。回滚会结束用户的事务,并撤销正在进行的所有未提交的修改
- SAVEPOINT identifier;SAVEPOINT允许在事务中创建一个保存点,一个事务中可以有多个SAVEPOINT
- RELEASE SAVEPOINT identifier;删除一个事务的保存点,当没有指定的保存点时,执行该语句会抛出一个异常
- ROLLBACK TO identifier;把事务回滚到标记点
- SET TRANSACTION;用来设置事务的隔离级别。InnoDB存储引擎提供事务的隔离级别有READ UNCOMMITTED、READ COMMITTED、REPEATABLE READ和SERIALIZABLE
MySQL事务处理主要的两种方法:
1、用 BEGIN, ROLLBACK, COMMIT来实现
- BEGIN 开始一个事务
- ROLLBACK 事务回滚
- COMMIT 事务确认
2、直接用 set 来改变MySQL的自动提交模式
- set autocommit = 0 禁止自动提交
- set autocommit = 1 开启自动提交
事务示例:
mysql> create table one_test (id int(5)) engine=innodb; # 创建数据库 Query OK, 0 rows affected (0.08 sec) mysql> select * from one_test; Empty set (0.00 sec) mysql> begin; # 开始事务 Query OK, 0 rows affected (0.00 sec) mysql> insert into one_test value(5); # 插入数据 Query OK, 1 row affected (0.00 sec) mysql> insert into one_test value(6); # 插入数据 Query OK, 1 row affected (0.00 sec) mysql> commit; # 提交事务 Query OK, 0 rows affected (0.01 sec) mysql> select * from one_test; # 查看数据 +------+ | id | +------+ | 5 | | 6 | +------+ 2 rows in set (0.00 sec)
回滚机制:
mysql> begin; # 开始一个新事务 Query OK, 0 rows affected (0.00 sec) mysql> insert into one_test value(7); # 插入数据 Query OK, 1 row affected (0.00 sec) mysql> insert into one_test value(8); # 插入数据 Query OK, 1 row affected (0.00 sec) mysql> rollback; # 回滚机制启动 Query OK, 0 rows affected (0.01 sec) mysql> select * from one_test; # 因为启动了回滚 所有数据没有插入 +------+ | id | +------+ | 5 | | 6 | +------+ 2 rows in set (0.00 sec)
索引
MySQL索引的建立对于MySQL的高效运行是很重要的,索引可以大大提高MySQL的检索速度
索引分单列索引和组合索引。单列索引,即一个索引只包含单个列,一个表可以有多个单列索引,但这不是组合索引。组合索引,即一个索引包含多个列。
创建索引时,你需要确保该索引是应用在 SQL 查询语句的条件(一般作为 WHERE 子句的条件)。
实际上,索引也是一张表,该表保存了主键与索引字段,并指向实体表的记录。
上面都在说使用索引的好处,但过多的使用索引将会造成滥用。因此索引也会有它的缺点:虽然索引大大提高了查询速度,同时却会降低更新表的速度,如对表进行INSERT、UPDATE和DELETE。因为更新表时,MySQL不仅要保存数据,还要保存一下索引文件。
建立索引会占用磁盘空间的索引文件。
普通索引----创建索引:
# 第一种方式,使用create create index indexname on table(username(length)); # 第二种方式:修改表结构 alter table tablename add index indexname(columnname) # 第三种方式 创建表的时候直接指定 create table mytable( ID INT NOT NULL, username VARCHAR(16) NOT NULL, INDEX [indexName] (username(length)) );
删除索引:
drop index indexname on table;
注:如果是CHAR,VARCHAR类型,length可以小于字段实际长度;如果是BLOB和TEXT类型,必须指定 length。
唯一索引----它与前面的普通索引类似,不同的就是:索引列的值必须唯一,但允许有空值。如果是组合索引,则列值的组合必须唯一。它有以下几种创建方式:
# 第一种方式,使用create create unique indexname on table(username(length)); # 第二种方式:修改表结构 alter table tablename add unique indexname(columnname) # 第三种方式 创建表的时候直接指定 create table mytable( ID INT NOT NULL, username VARCHAR(16) NOT NULL, unique [indexName] (username(length)) );
临时表和复制表
临时表:MySQL 临时表在我们需要保存一些临时数据时是非常有用的。临时表只在当前连接可见,当关闭连接时,Mysql会自动删除表并释放所有空间
示例:
# 创建临时表
mysql> CREATE TEMPORARY TABLE SalesSummary (
-> product_name VARCHAR(50) NOT NULL
-> , total_sales DECIMAL(12,2) NOT NULL DEFAULT 0.00
-> , avg_unit_price DECIMAL(7,2) NOT NULL DEFAULT 0.00
-> , total_units_sold INT UNSIGNED NOT NULL DEFAULT 0
);
Query OK, 0 rows affected (0.00 sec)
mysql> INSERT INTO SalesSummary
-> (product_name, total_sales, avg_unit_price, total_units_sold)
-> VALUES
-> ('cucumber', 100.25, 90, 2);
mysql> SELECT * FROM SalesSummary;
+--------------+-------------+----------------+------------------+
| product_name | total_sales | avg_unit_price | total_units_sold |
+--------------+-------------+----------------+------------------+
| cucumber | 100.25 | 90.00 | 2 |
+--------------+-------------+----------------+------------------+
1 row in set (0.00 sec)
# 删除临时表
mysql> CREATE TEMPORARY TABLE SalesSummary (
-> product_name VARCHAR(50) NOT NULL
-> , total_sales DECIMAL(12,2) NOT NULL DEFAULT 0.00
-> , avg_unit_price DECIMAL(7,2) NOT NULL DEFAULT 0.00
-> , total_units_sold INT UNSIGNED NOT NULL DEFAULT 0
);
Query OK, 0 rows affected (0.00 sec)
mysql> INSERT INTO SalesSummary
-> (product_name, total_sales, avg_unit_price, total_units_sold)
-> VALUES
-> ('cucumber', 100.25, 90, 2);
mysql> SELECT * FROM SalesSummary;
+--------------+-------------+----------------+------------------+
| product_name | total_sales | avg_unit_price | total_units_sold |
+--------------+-------------+----------------+------------------+
| cucumber | 100.25 | 90.00 | 2 |
+--------------+-------------+----------------+------------------+
1 row in set (0.00 sec)
mysql> DROP TABLE SalesSummary;
mysql> SELECT * FROM SalesSummary;
ERROR 1146: Table 'RUNOOB.SalesSummary' doesn't exist
注:
当你使用 SHOW TABLES命令显示数据表列表时,你将无法看到 SalesSummary表。
如果你退出当前MySQL会话,再使用 SELECT命令来读取原先创建的临时表数据,那你会发现数据库中没有该表的存在,因为在你退出时该临时表已经被销毁了。
默认情况下,当你断开与数据库的连接后,临时表就会自动被销毁。当然你也可以在当前MySQL会话使用 DROP TABLE 命令来手动删除临时表。
复制表: 分三步:挺傻瓜式的:
- 查看表结构
- 修改表名和字段名,然后创建表
- 插入数据
SHOW CREATE TABLE tablenameG; CREATE TABLE `new_table`; insert into new_table;
序列
MySQL序列是一组整数:1, 2, 3, ...,由于一张数据表只能有一个字段自增主键, 如果你想实现其他字段也实现自动增加,就可以使用MySQL序列来实现。
使用AUTO_INCREMENT:
# 创建了数据表insect, insect中id无需指定值可实现自动增长
mysql> CREATE TABLE insect
-> (
-> id INT UNSIGNED NOT NULL AUTO_INCREMENT,
-> PRIMARY KEY (id),
-> name VARCHAR(30) NOT NULL, # type of insect
-> date DATE NOT NULL, # date collected
-> origin VARCHAR(30) NOT NULL # where collected
);
Query OK, 0 rows affected (0.02 sec)
mysql> INSERT INTO insect (id,name,date,origin) VALUES
-> (NULL,'housefly','2001-09-10','kitchen'),
-> (NULL,'millipede','2001-09-10','driveway'),
-> (NULL,'grasshopper','2001-09-10','front yard');
Query OK, 3 rows affected (0.02 sec)
Records: 3 Duplicates: 0 Warnings: 0
mysql> SELECT * FROM insect ORDER BY id;
+----+-------------+------------+------------+
| id | name | date | origin |
+----+-------------+------------+------------+
| 1 | housefly | 2001-09-10 | kitchen |
| 2 | millipede | 2001-09-10 | driveway |
| 3 | grasshopper | 2001-09-10 | front yard |
+----+-------------+------------+------------+
3 rows in set (0.00 sec)
重置序列:
如果你删除了数据表中的多条记录,并希望对剩下数据的AUTO_INCREMENT列进行重新排列,那么你可以通过删除自增的列,然后重新添加来实现。 不过该操作要非常小心,如果在删除的同时又有新记录添加,有可能会出现数据混乱。操作如下所示:
mysql> ALTER TABLE insect DROP id;
mysql> ALTER TABLE insect
-> ADD id INT UNSIGNED NOT NULL AUTO_INCREMENT FIRST,
-> ADD PRIMARY KEY (id);
设置序列的开始值:
mysql> CREATE TABLE insect
-> (
-> id INT UNSIGNED NOT NULL AUTO_INCREMENT,
-> PRIMARY KEY (id),
-> name VARCHAR(30) NOT NULL,
-> date DATE NOT NULL,
-> origin VARCHAR(30) NOT NULL
)engine=innodb auto_increment=100 charset=utf8;