第一部分 Hadoop 2.2 下载
Hadoop我们从Apache官方网站直接下载最新版本Hadoop2.2。官方目前是提供了linux32位系统可执行文件,所以如果需要在64位系统上部署则需要单独下载src 源码自行编译(10楼评论中提供了一个解决方法链接)。
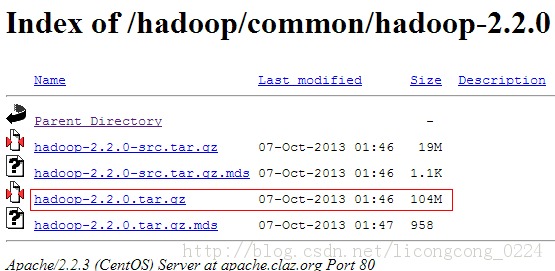
下载地址:http://apache.claz.org/hadoop/common/hadoop-2.2.0/
如下图所示,下载红色标记部分即可。如果要自行编译则下载src.tar.gz.
第二部分 集群环境搭建
1、这里我们搭建一个由三台机器组成的集群:
192.168.0.1 hduser/passwd cloud001 nn/snn/rm CentOS6 64bit
192.168.0.2 hduser/passwd cloud002 dn/nm Ubuntu13.04 32bit
192.168.0.3 hduser/passwd cloud003 dn/nm Ubuntu13.0432bit
1.1 上面各列分别为IP、user/passwd、hostname、在cluster中充当的角色(namenode, secondary namenode, datanode , resourcemanager, nodemanager)
vi /etc/hosts
编辑/etc/sysconfig/network文件,更改hostname:
[root@server1 ~]# vi /etc/sysconfig/network
[root@server1 ~]# hostname server2
1.2 Hostname可以在/etc/hostname中修改(ubuntu是在这个路径下,redhat稍有不同)
1.3 这里我们为每台机器新建了一个账户hduser.这里需要给每个账户分配sudo的权限。(切换到root账户,修改/etc/sudoers文件,增加:hduser ALL=(ALL) ALL )
2、修改/etc/hosts 文件,增加三台机器的ip和hostname的映射关系
192.168.0.1 cloud001
192.168.0.2 cloud002
192.168.0.3 cloud003
3、打通cloud001到cloud002、cloud003的SSH无密码登陆
3.1 安装ssh
一般系统是默认安装了ssh命令的。如果没有,或者版本比较老,则可以重新安装:
sodu apt-get install ssh
3.2设置local无密码登陆
安装完成后会在~目录(当前用户主目录,即这里的/home/hduser)下产生一个隐藏文件夹.ssh(ls -a 可以查看隐藏文件)。如果没有这个文件,自己新建即可(mkdir .ssh)。
具体步骤如下:
1、 进入.ssh文件夹
2、 ssh-keygen -t rsa 之后一路回 车(产生秘钥)
3、 把id_rsa.pub 追加到授权的 key 里面去(cat id_rsa.pub >> authorized_keys)
4、 重启 SSH 服 务命令使其生效 :service sshd restart(这里RedHat下为sshdUbuntu下为ssh)
此时已经可以进行ssh localhost的无密码登陆
【注意】:以上操作在每台机器上面都要进行。
3.3设置远程无密码登陆
这里只有cloud001是master,如果有多个namenode,或者rm的话则需要打通所有master都其他剩余节点的免密码登陆。(将001的authorized_keys追加到002和003的authorized_keys)
进入001的.ssh目录
scp authorized_keys hduser@cloud002:~/.ssh/ authorized_keys_from_cloud001
进入002的.ssh目录
cat authorized_keys_from_cloud001>> authorized_keys
至此,可以在001上面sshhduser@cloud002进行无密码登陆了。003的操作相同。
4、安装jdk(建议每台机器的JAVA_HOME路径信息相同)
注意:这里选择下载jdk并自行安装,而不是通过源直接安装(apt-get install)
4.1、下载jkd( http://www.oracle.com/technetwork/java/javase/downloads/index.html)
4.1.1 对于32位的系统可以下载以下两个Linux x86版本(uname -a 查看系统版本)
4.1.2 64位系统下载Linux x64版本(即x64.rpm和x64.tar.gz)

4.2、安装jdk(这里以.tar.gz版本,32位系统为例)
安装方法参考http://docs.oracle.com/javase/7/docs/webnotes/install/linux/linux-jdk.html
4.2.1 选择要安装java的位置,如/usr/目录下,新建文件夹java(mkdirjava)
4.2.2 将文件jdk-7u40-linux-i586.tar.gz移动到/usr/java
4.2.3 解压:tar -zxvf jdk-7u40-linux-i586.tar.gz
4.2.4 删除jdk-7u40-linux-i586.tar.gz(为了节省空间)
至此,jkd安装完毕,下面配置环境变量
4.3、打开/etc/profile(vim /etc/profile)
在最后面添加如下内容:
JAVA_HOME=/usr/java/jdk1.7.0_40(这里的版本号1.7.40要根据具体下载情况修改)
CLASSPATH=.:$JAVA_HOME/lib.tools.jar
PATH=$JAVA_HOME/bin:$PATH
export JAVA_HOMECLASSPATH PATH
4.4、source /etc/profile
4.5、验证是否安装成功:java–version
【注意】每台机器执行相同操作,最后将java安装在相同路径下(不是必须的,但这样会使后面的配置方便很多)
5、关闭每台机器的防火墙
RedHat:
/etc/init.d/iptables stop 关闭防火墙。
chkconfig iptables off 关闭开机启动。
Ubuntu:
ufw disable (重启生效)
第三部分 Hadoop 2.2安装过程
由于hadoop集群中每个机器上面的配置基本相同,所以我们先在namenode上面进行配置部署,然后再复制到其他节点。所以这里的安装过程相当于在每台机器上面都要执行。但需要注意的是集群中64位系统和32位系统的问题。
1、 解压文件
tar zxvf hadoop-2.2.tar.gz
将第一部分中下载的hadoop-2.2.tar.gz解压到/home/hduser路径下(或者将在64位机器上编译的结果存放在此路径下)。然后为了节省空间,可删除此压缩文件,或将其存放于其他地方进行备份。
注意:每台机器的安装路径要相同!!
2、 hadoop配置过程
配置之前,需要在cloud001本地文件系统创建以下文件夹:
~/dfs/name
~/dfs/data
~/temp
这里要涉及到的配置文件有7个:
~/hadoop-2.2.0/etc/hadoop/hadoop-env.sh
~/hadoop-2.2.0/etc/hadoop/yarn-env.sh
~/hadoop-2.2.0/etc/hadoop/slaves
~/hadoop-2.2.0/etc/hadoop/core-site.xml
~/hadoop-2.2.0/etc/hadoop/hdfs-site.xml
~/hadoop-2.2.0/etc/hadoop/mapred-site.xml
~/hadoop-2.2.0/etc/hadoop/yarn-site.xml
以上个别文件默认不存在的,可以复制相应的template文件获得。
配置文件1:hadoop-env.sh
修改JAVA_HOME值(export JAVA_HOME=/usr/java/jdk1.7.0_40)
配置文件2:yarn-env.sh
修改JAVA_HOME值(exportJAVA_HOME=/usr/java/jdk1.7.0_40)
配置文件3:slaves (这个文件里面保存所有slave节点)
写入以下内容:
cloud002
cloud003
配置文件4:core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://cloud001:9000</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/home/hduser/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>hadoop.proxyuser.hduser.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hduser.groups</name>
<value>*</value>
</property>
</configuration>
配置文件5:hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>cloud001:9001</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/hduser/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/hduser/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>
配置文件6:mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>cloud001:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>cloud001:19888</value>
</property>
</configuration>
配置文件7:yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>cloud001:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value> cloud001:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value> cloud001:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value> cloud001:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value> cloud001:8088</value>
</property>
</configuration>
3、复制到其他节点
这里可以写一个shell脚本进行操作(有大量节点时比较方便)
cp2slave.sh
#!/bin/bash
scp–r /home/hduser/hadoop-2.2.0 hduser@cloud002:~/
scp–r /home/hduser/hadoop-2.2.0 hduser@cloud003:~/
注意:由于我们集群里面001是64bit 而002和003是32bit的,所以不能直接复制,而采用单独安装hadoop,复制替换相关配置文件:
Cp2slave2.sh
#!/bin/bash
scp /home/hduser/hadoop-2.2.0/etc/hadoop/slaveshduser@cloud002:~/hadoop-2.2.0/etc/hadoop/slaves
scp /home/hduser/hadoop-2.2.0/etc/hadoop/slaveshduser@cloud003:~/hadoop-2.2.0/etc/hadoop/slaves
scp /home/hduser/hadoop-2.2.0/etc/hadoop/core-site.xmlhduser@cloud002:~/hadoop-2.2.0/etc/hadoop/core-site.xml
scp /home/hduser/hadoop-2.2.0/etc/hadoop/core-site.xml hduser@cloud003:~/hadoop-2.2.0/etc/hadoop/core-site.xml
scp /home/hduser/hadoop-2.2.0/etc/hadoop/hdfs-site.xmlhduser@cloud002:~/hadoop-2.2.0/etc/hadoop/hdfs-site.xml
scp /home/hduser/hadoop-2.2.0/etc/hadoop/hdfs-site.xmlhduser@cloud003:~/hadoop-2.2.0/etc/hadoop/hdfs-site.xml
scp /home/hduser/hadoop-2.2.0/etc/hadoop/mapred-site.xmlhduser@cloud002:~/hadoop-2.2.0/etc/hadoop/mapred-site.xml
scp /home/hduser/hadoop-2.2.0/etc/hadoop/mapred-site.xmlhduser@cloud003:~/hadoop-2.2.0/etc/hadoop/mapred-site.xml
scp /home/hduser/hadoop-2.2.0/etc/hadoop/yarn-site.xmlhduser@cloud002:~/hadoop-2.2.0/etc/hadoop/yarn-site.xml
scp /home/hduser/hadoop-2.2.0/etc/hadoop/yarn-site.xmlhduser@cloud003:~/hadoop-2.2.0/etc/hadoop/yarn-site.xml
4、启动验证
4.1 启动hadoop
进入安装目录: cd ~/hadoop-2.2.0/
格式化namenode:./bin/hdfs namenode –format
启动hdfs: ./sbin/start-dfs.sh
此时在001上面运行的进程有:namenode secondarynamenode
002和003上面运行的进程有:datanode
启动yarn: ./sbin/start-yarn.sh
此时在001上面运行的进程有:namenode secondarynamenoderesourcemanager
002和003上面运行的进程有:datanode nodemanaget
查看集群状态:./bin/hdfs dfsadmin –report
查看文件块组成: ./bin/hdfsfsck / -files -blocks
查看HDFS: http://16.187.94.161:50070
查看RM: http:// 16.187.94.161:8088
4.2 运行示例程序:
先在hdfs上创建一个文件夹
./bin/hdfs dfs –mkdir /input
./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-2.2.0.jarrandomwriter input
PS:dataNode 无法启动是配置过程中最常见的问题,主要原因是多次format namenode 造成namenode 和datanode的clusterID不一致。建议查看datanode上面的log信息。解决办法:修改每一个datanode上面的CID(位于dfs/data/current/VERSION文件夹中)使两者一致。