1、安装Elasticsearch
cd ~/app; curl -L -O https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.4.0-linux-x86_64.tar.gz; tar -xzvf elasticsearch-7.4.0-linux-x86_64.tar.gz; ln -s elasticsearch-7.4.0 elasticsearch;
sudo vim /etc/profile
末尾新增:
#elasticsearch export ES_HOME=/home/hadoop/app/elasticsearch export PATH=${ES_HOME}/bin:$PATH
使环境变量生效:
source /etc/profile
基础配置
调大最大虚拟内存
sudo vim /etc/sysctl.conf
新增如下配置:
vm.max_map_count=262144
保存退出再执行如下命令:
sudo sysctl -p
配置ES
vim $ES_HOME/config/elasticsearch.yml
修改的配置如下:
network.host: 0.0.0.0
discovery.seed_hosts: ["canal01"]
启停ES
$ES_HOME/bin/elasticsearch -d

可以看到启动的时候报错了
max file descriptors [4096] for elasticsearch process is too low, increase to at least [65536]
每个进程最大同时打开文件数太小
修改/etc/security/limits.conf文件,增加配置,用户退出后重新登录生效,我这里退出hadoop用户,再重新进入hadoop用户
* soft nofile 65536 * hard nofile 65536
再次启动ES:

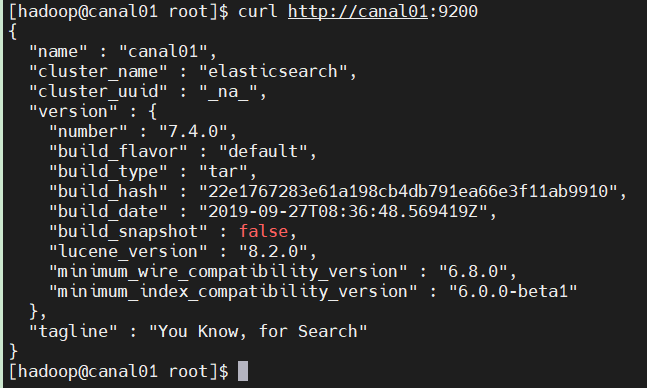
确认ES是否启动:
curl http://canal01:9200
2、安装Kibana
下载安装包并解压
cd ~/app; curl -L -O https://artifacts.elastic.co/downloads/kibana/kibana-7.4.0-linux-x86_64.tar.gz; tar -xzvf kibana-7.4.0-linux-x86_64.tar.gz; ln -s kibana-7.4.0-linux-x86_64 kibana;
sudo vim /etc/profile
末尾新增:
#kibana export KIBANA_HOME=/home/hadoop/app/kibana export PATH=${KIBANA_HOME}/bin:$PATH
使环境变量生效:
source /etc/profile
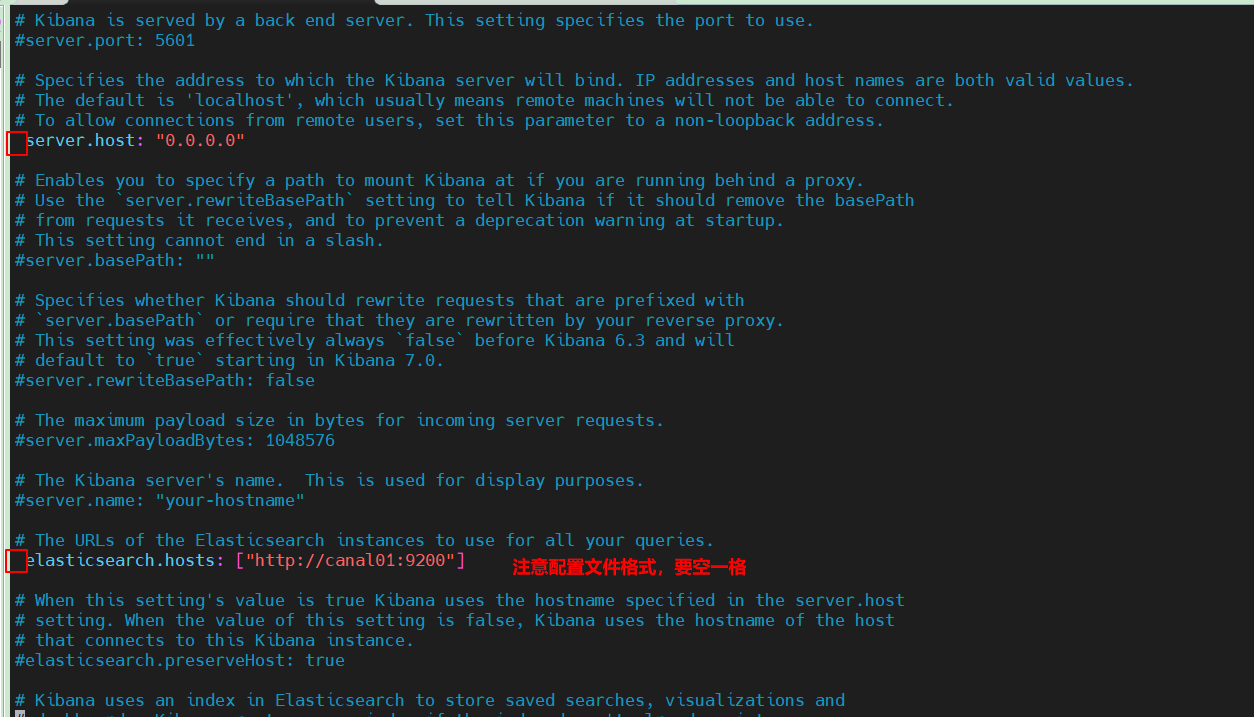
vim $KIBANA_HOME/config/kibana.yml
修改配置如下:
server.host: "0.0.0.0" elasticsearch.hosts: ["http://canal01:9200"]
其余配置项暂时保持不变。
启动Kibana
nohup $KIBANA_HOME/bin/kibana > $KIBANA_HOME/kibana.out 2>&1 &
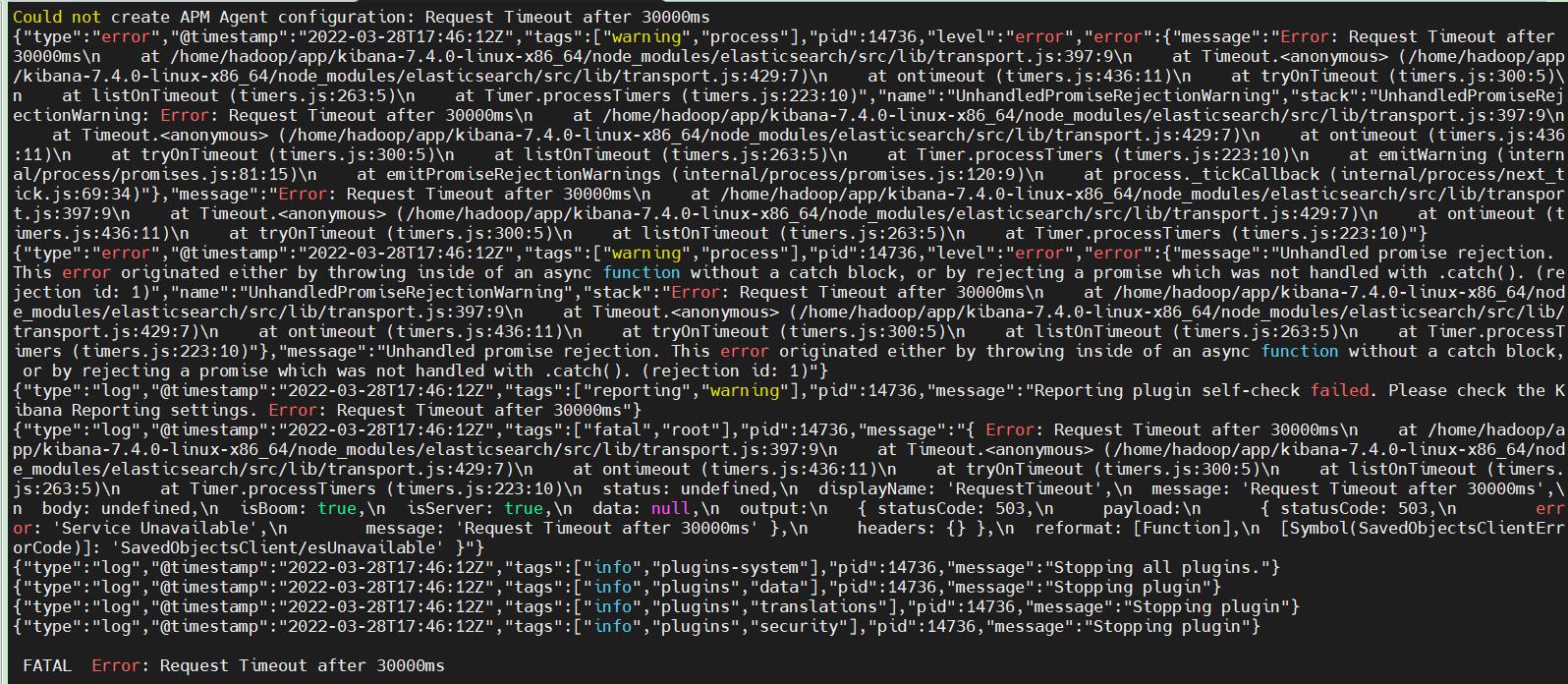
显示超时,我们把kibana的等待时间调更长一些
修改配置文件
vim $KIBANA_HOME/config/kibana.yml
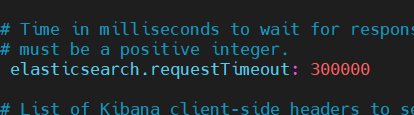
重新运行kibana,还是报错
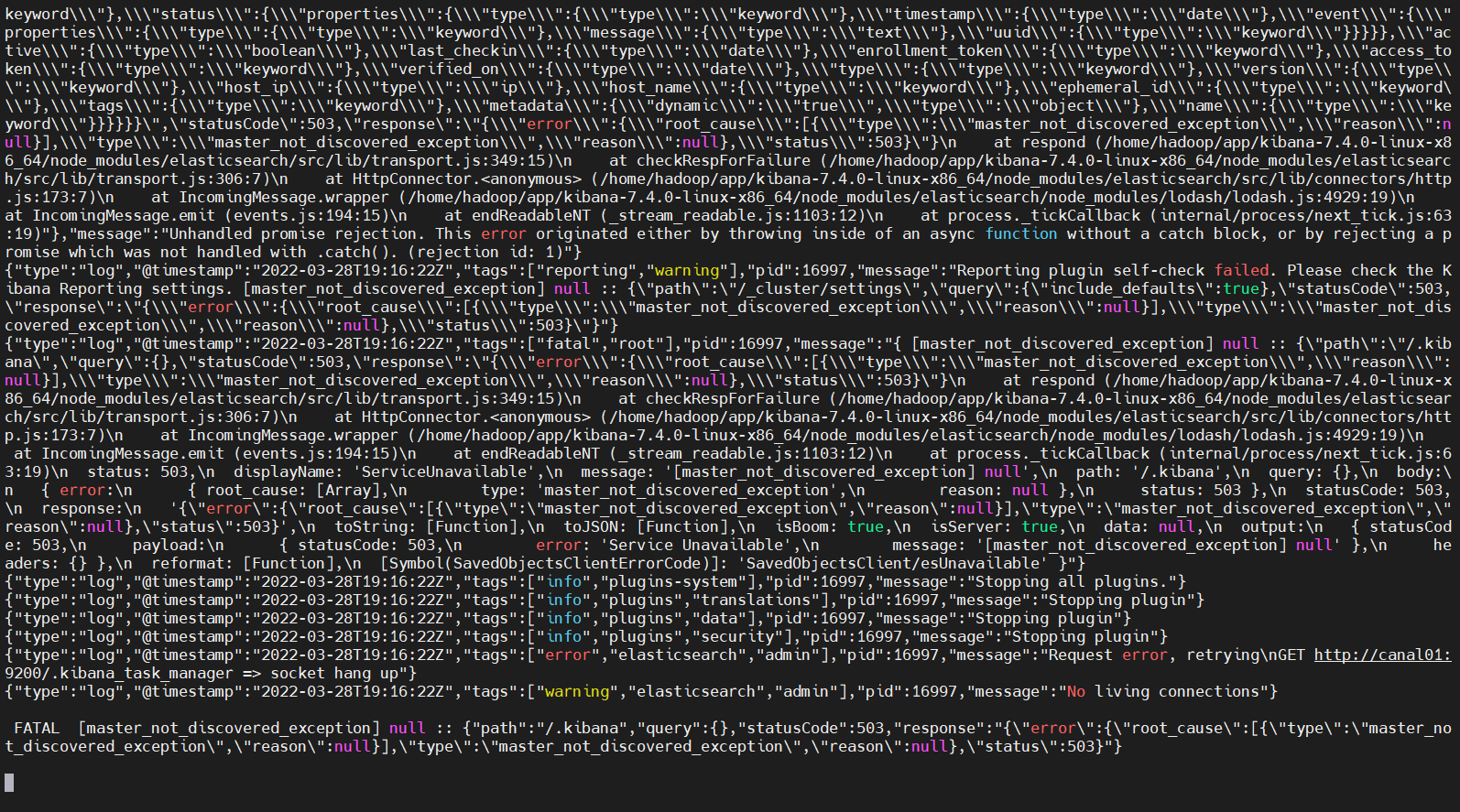
我们修改elasticsearch.yml配置文件:
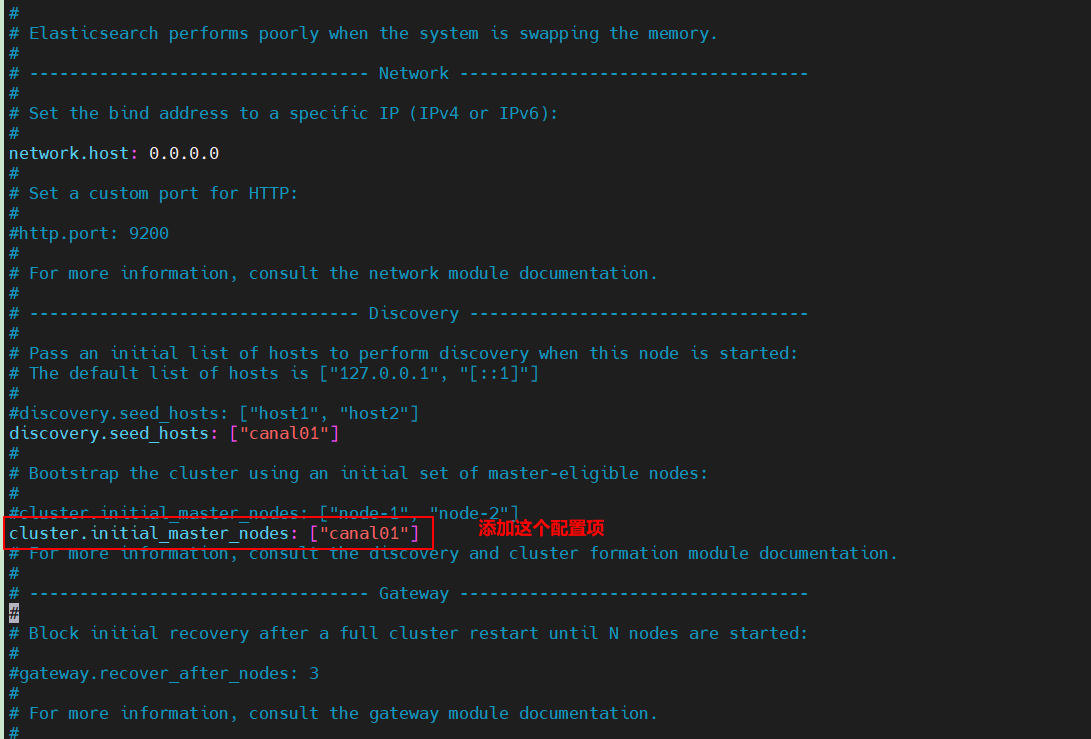
再重启ES,启动kibana.
查看kibana的后台日志
都是正常的日志打印,没有报错。
浏览器访问http://canal01:5601/
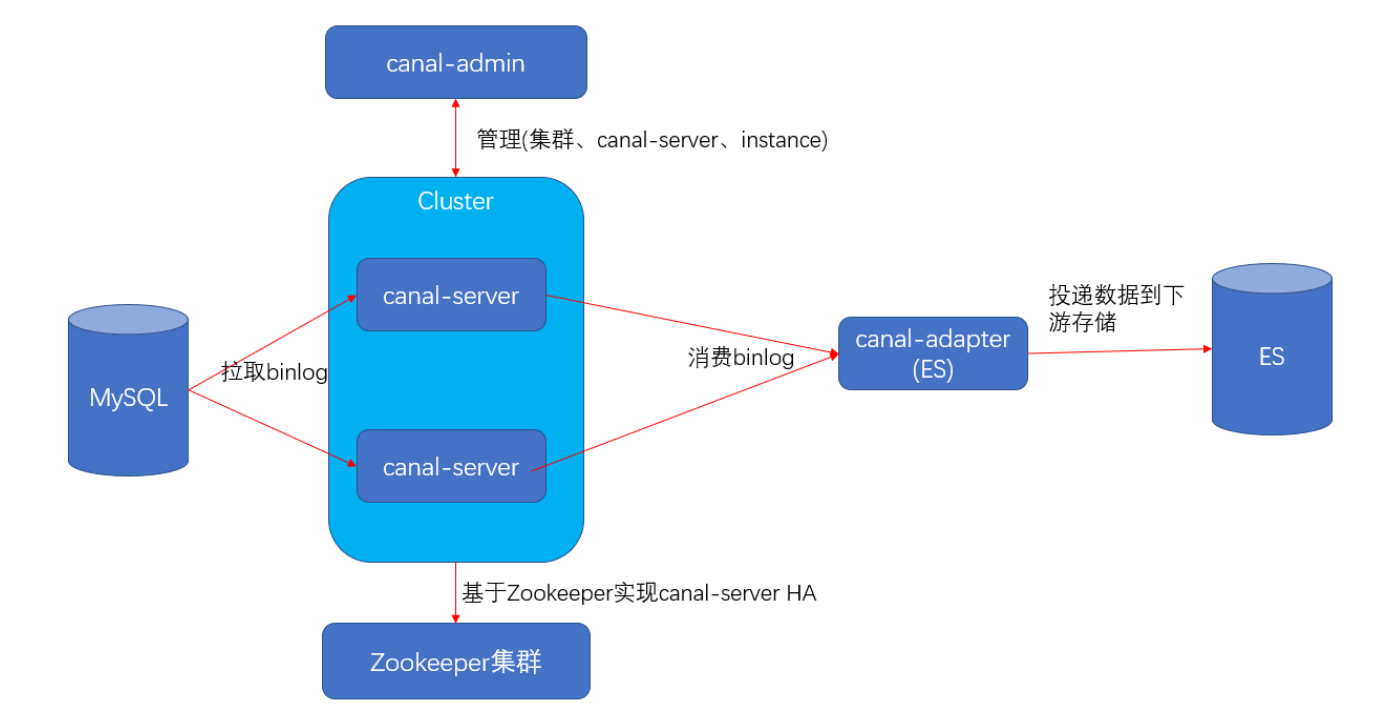
3、配置同步流
登录mysql执行以下命令
CREATE DATABASE IF NOT EXISTS test DEFAULT CHARSET utf8 COLLATE utf8_general_ci; use test; DROP TABLE IF EXISTS `test`; CREATE TABLE `test` ( `uid` INT UNSIGNED AUTO_INCREMENT,
`name` VARCHAR(100) NOT NULL,
`age` int(3) DEFAULT NULL,
`modified_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`uid`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
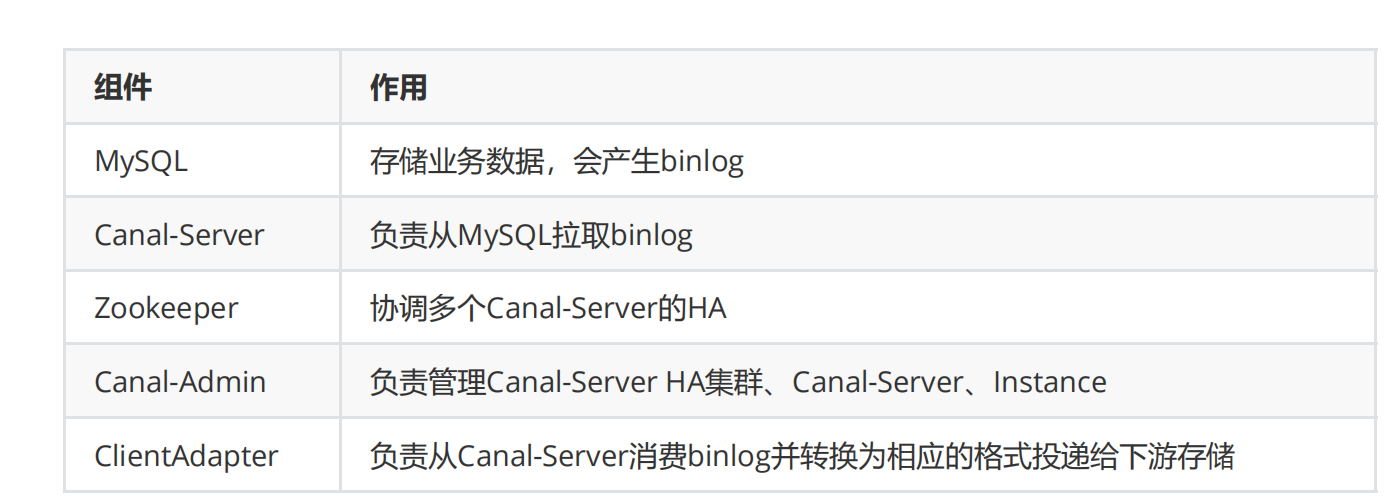
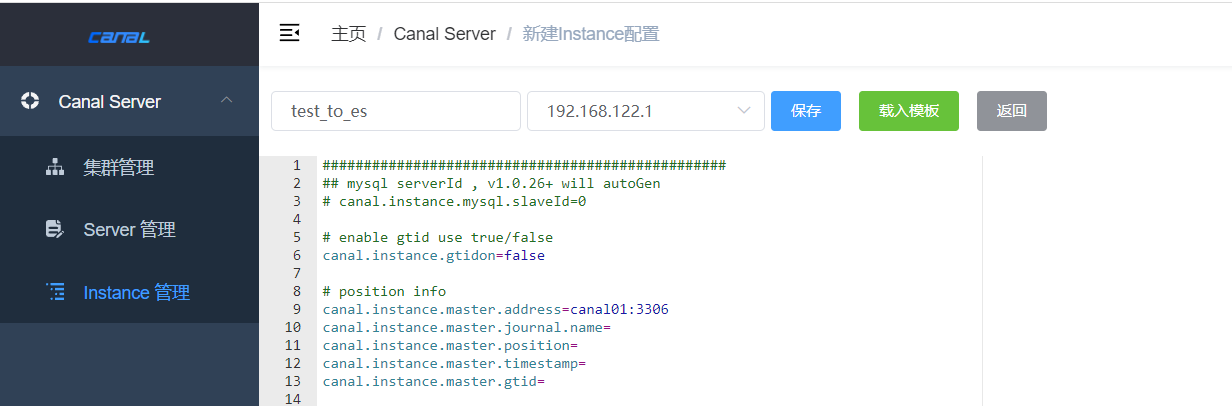
新建instance
################################################# ## mysql serverId , v1.0.26+ will autoGen # canal.instance.mysql.slaveId=0 # enable gtid use true/false canal.instance.gtidon=false # position info canal.instance.master.address=canal01:3306 canal.instance.master.journal.name= canal.instance.master.position= canal.instance.master.timestamp= canal.instance.master.gtid= # rds oss binlog canal.instance.rds.accesskey= canal.instance.rds.secretkey= canal.instance.rds.instanceId= # table meta tsdb info canal.instance.tsdb.enable=true #canal.instance.tsdb.url=jdbc:mysql://127.0.0.1:3306/canal_tsdb #canal.instance.tsdb.dbUsername=canal #canal.instance.tsdb.dbPassword=canal #canal.instance.standby.address = #canal.instance.standby.journal.name = #canal.instance.standby.position = #canal.instance.standby.timestamp = #canal.instance.standby.gtid= # username/password canal.instance.dbUsername=canal canal.instance.dbPassword=canal canal.instance.connectionCharset = UTF-8 # enable druid Decrypt database password canal.instance.enableDruid=false #canal.instance.pwdPublicKey=MFwwDQYJKoZIhvcNAQEBBQADSwAwSAJBALK4BUxdDltRRE5/zXpVEVPUgunvscYFtEip3pmLlhrWpacX7y7GCMo2/JM6LeHmiiNdH1FWgGCpUfircSwlWKUCAwEAAQ== # table regex canal.instance.filter.regex=.*\\..* # table black regex canal.instance.filter.black.regex= # table field filter(format: schema1.tableName1:field1/field2,schema2.tableName2:field1/field2) #canal.instance.filter.field=test1.t_product:id/subject/keywords,test2.t_company:id/name/contact/ch # table field black filter(format: schema1.tableName1:field1/field2,schema2.tableName2:field1/field2) #canal.instance.filter.black.field=test1.t_product:subject/product_image,test2.t_company:id/name/contact/ch # mq config canal.mq.topic=example # dynamic topic route by schema or table regex #canal.mq.dynamicTopic=mytest1.user,mytest2\\..*,.*\\..* canal.mq.partition=0 # hash partition config #canal.mq.partitionsNum=3 #canal.mq.partitionHash=test.table:id^name,.*\\..* #################################################

Instance命名
查看运行日志
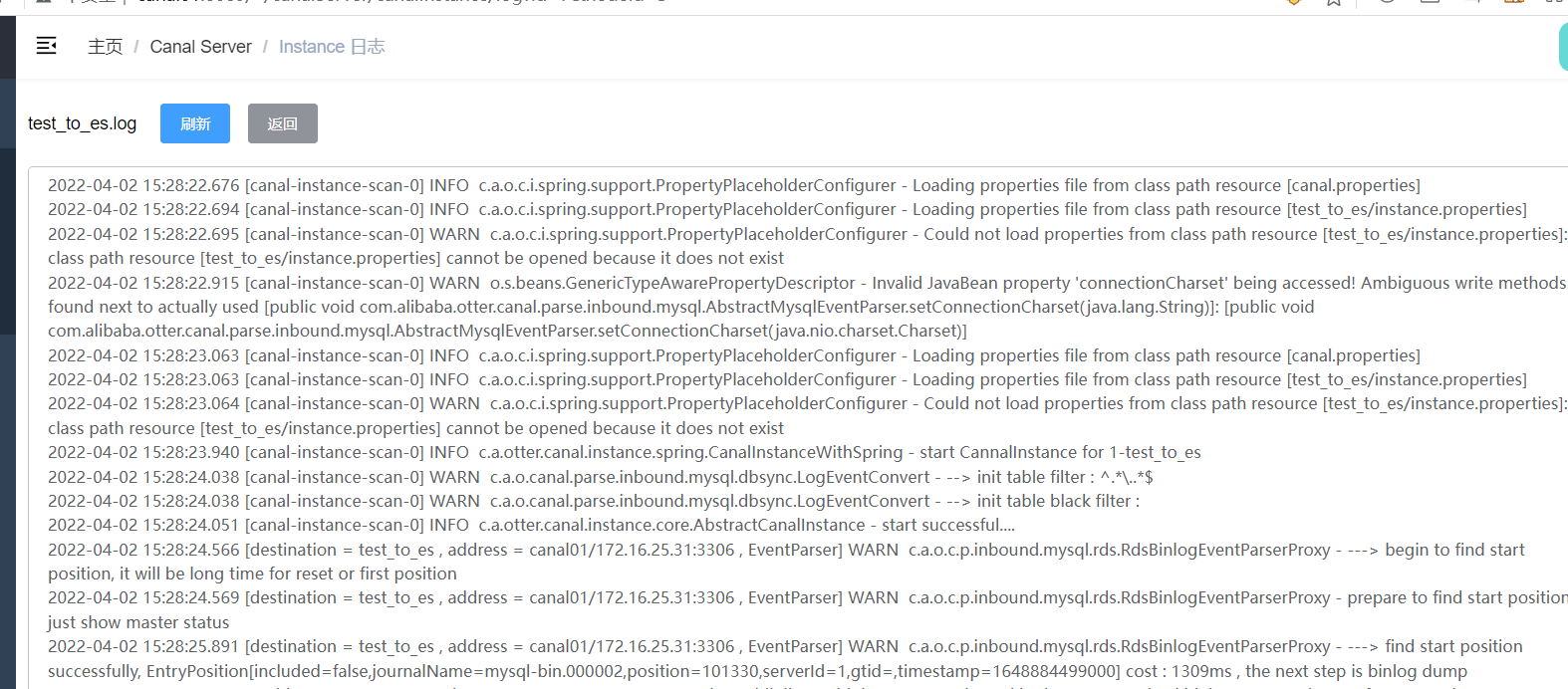
git clone https://github.com/alibaba/canal.git cd canal git checkout canal-1.1.5-alpha-1 mvn clean package -DskipTests -Denv=release
但是直接下载的话,1.1.5版本的源码还是有问题的,直接使用会报这个错误
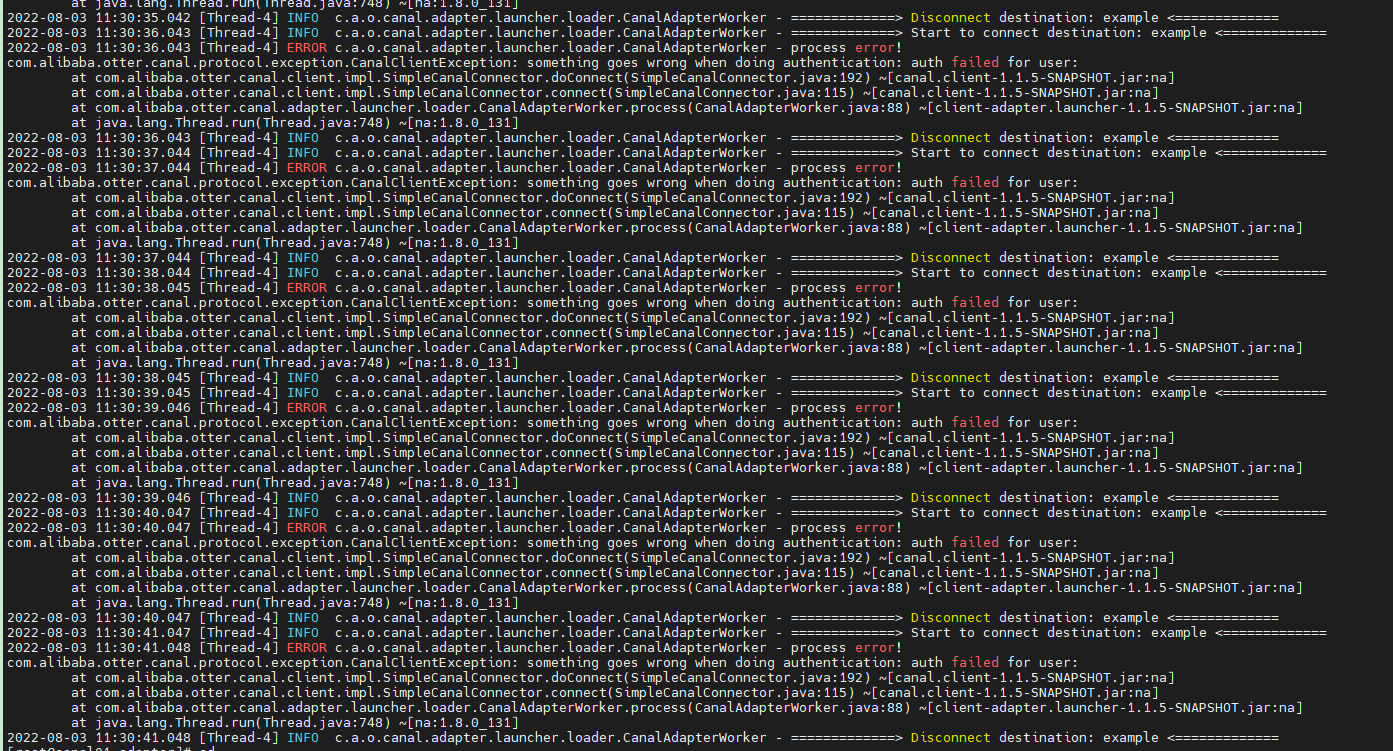
因此我们把源码下载下来,然后修改源码,再编译
1.1.5版本的源码地址:https://github.com/alibaba/canal/tree/canal-1.1.5-alpha-1
下面进行源码修改:
第一处要修改的,41行代码
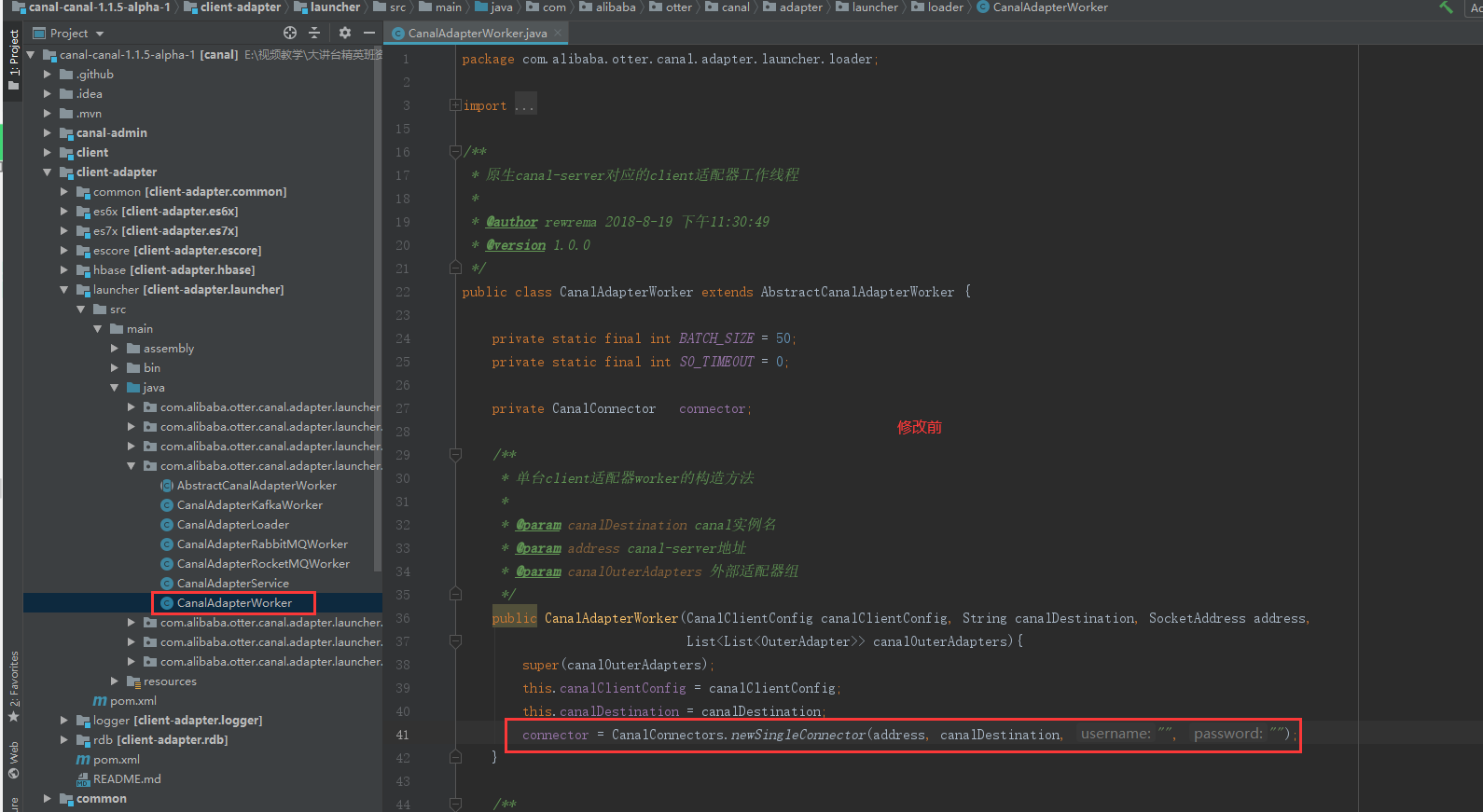
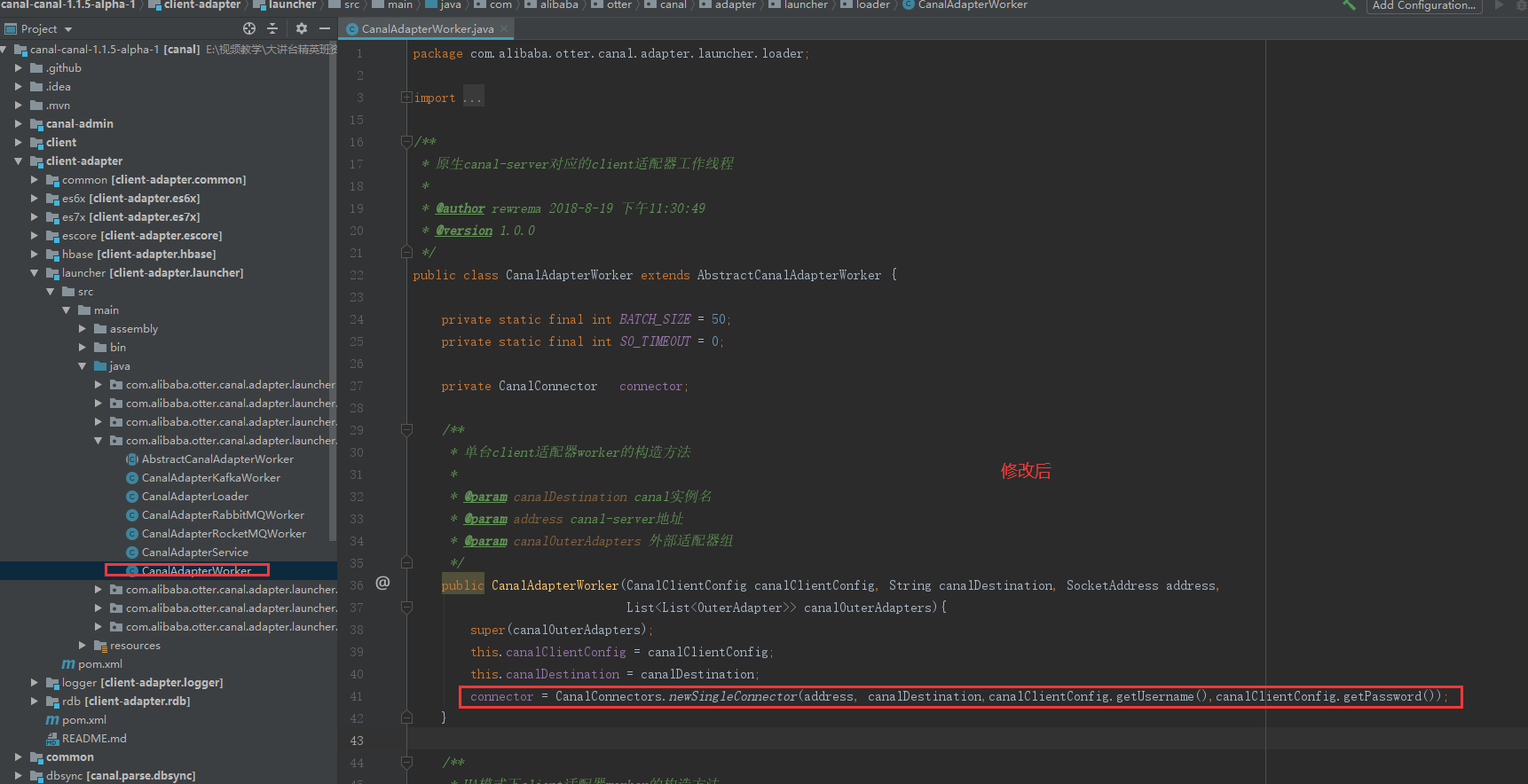
第二处要修改的,56行代码

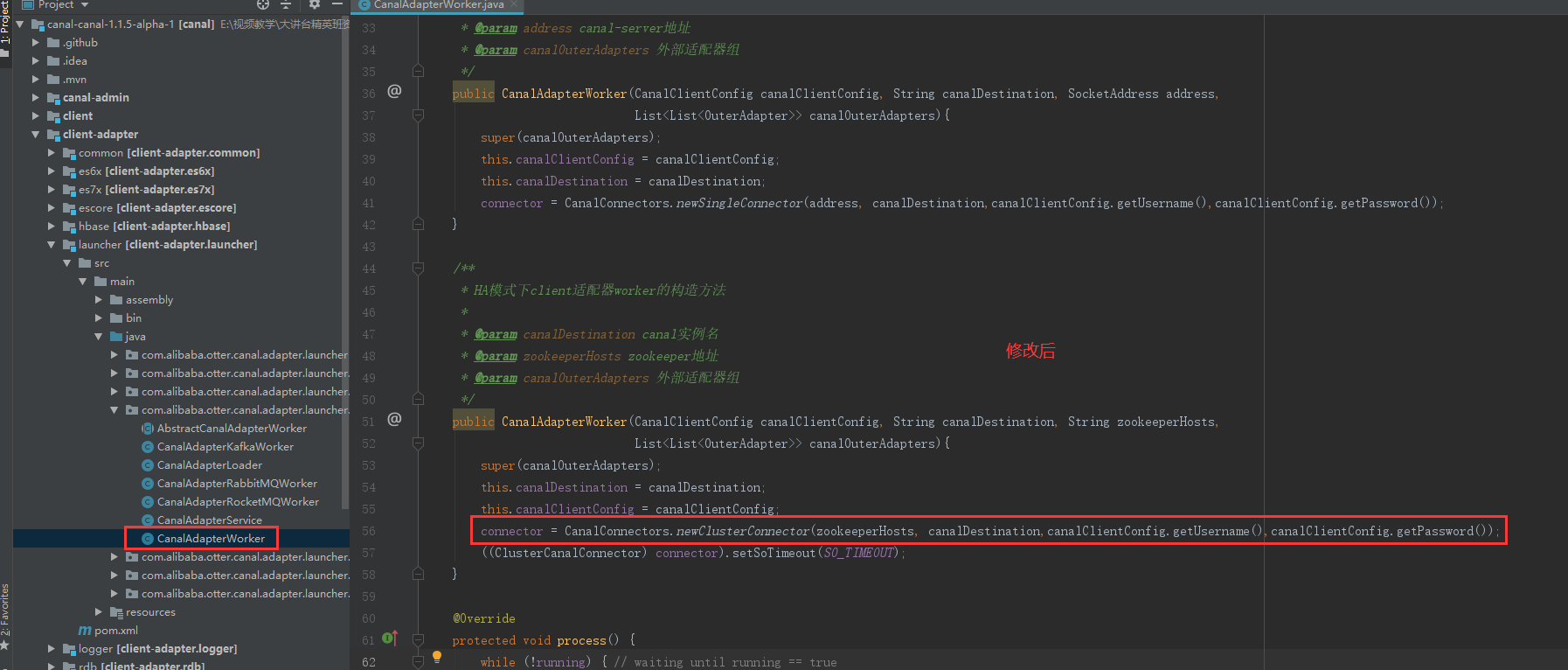
编译打包:
mvn clean package -DskipTests -Denv=release
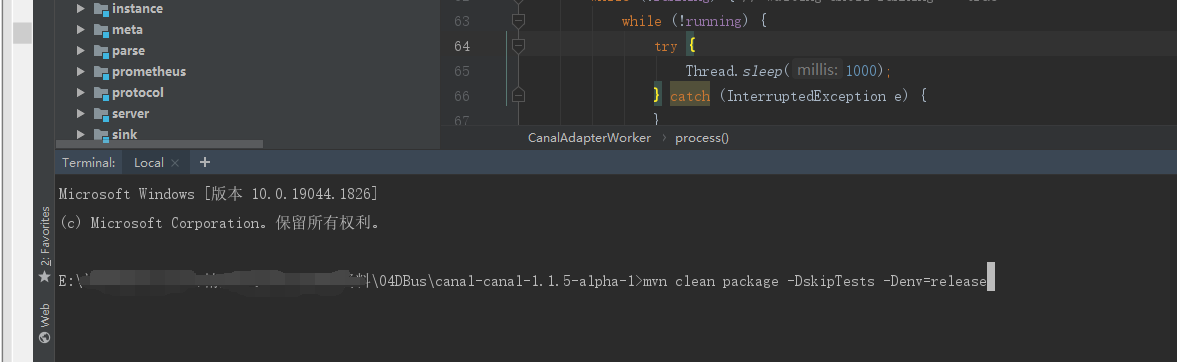
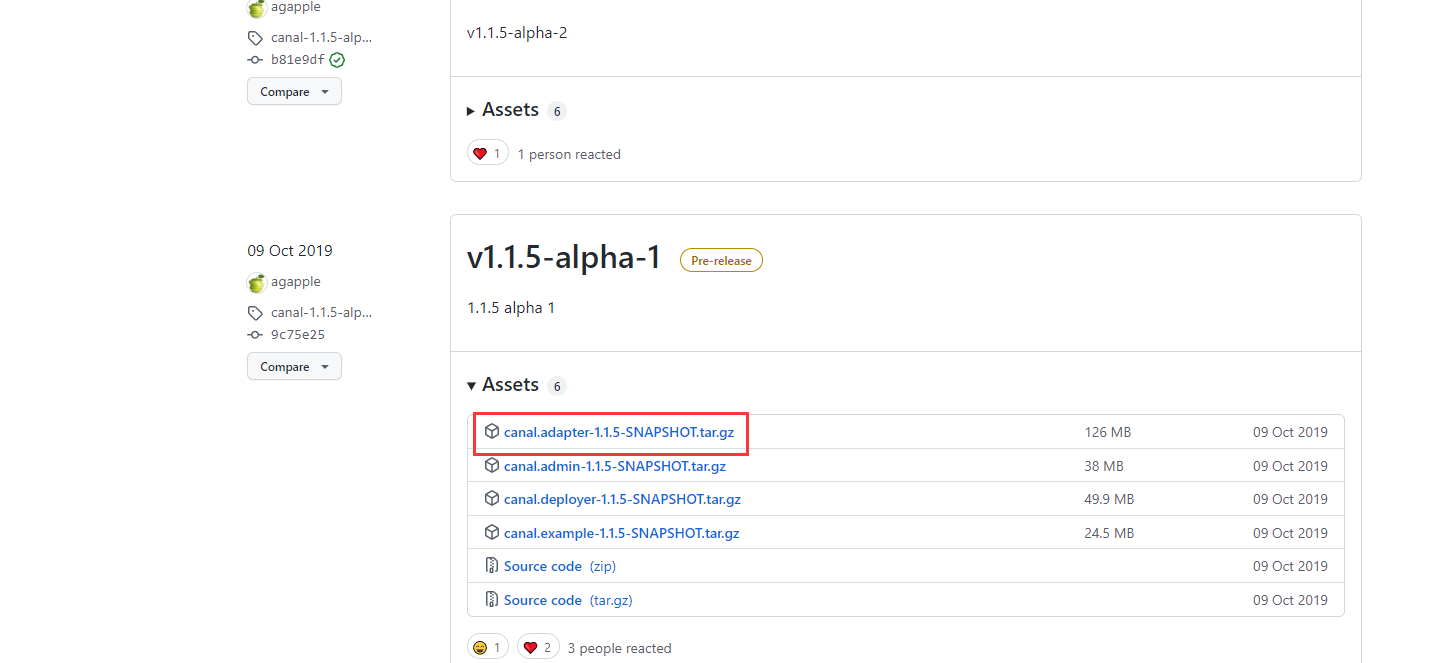
这个就是我们需要的包
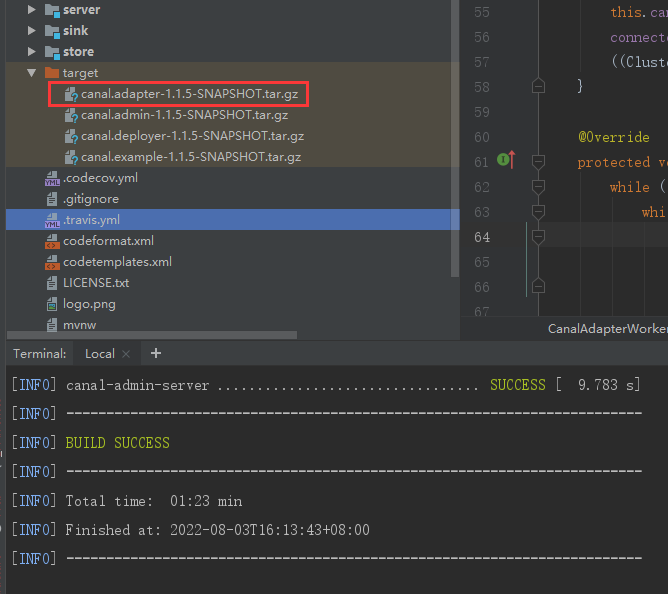
解压缩安装包
cd ~; mkdir -p app/canal-adapter; tar -zxvf canal.adapter-1.1.5-SNAPSHOT.tar.gz -C app/canal-adapter; cd app/canal-adapter;
配置环境变量
#canal-adapter export CANAL_ADAPTER_HOME=/home/hadoop/app/canal-adapter export PATH=${CANAL_ADAPTER_HOME}/bin:$PATH
修改启动器配置
vim $CANAL_ADAPTER_HOME/conf/application.yml
server: port: 8081 spring: jackson: date-format: yyyy-MM-dd HH:mm:ss time-zone: GMT+8 default-property-inclusion: non_null canal.conf: mode: tcp # kafka rocketMQ canalServerHost: canal01:11111 # zookeeperHosts: slave1:2181 # mqServers: 127.0.0.1:9092 #or rocketmq # flatMessage: true batchSize: 500 syncBatchSize: 1000 retries: 0 timeout: accessKey: secretKey: username: canal password: canal vhost: srcDataSources: defaultDS: url: jdbc:mysql://canal01:3306/test?useUnicode=true username: root password: root%123 canalAdapters: - instance: test_to_es # canal instance Name or mq topic name groups: - groupId: g1 outerAdapters: - name: logger # - name: rdb # key: mysql1 # properties: # jdbc.driverClassName: com.mysql.jdbc.Driver # jdbc.url: jdbc:mysql://127.0.0.1:3306/mytest2?useUnicode=true # jdbc.username: root # jdbc.password: 121212 # - name: rdb # key: oracle1 # properties: # jdbc.driverClassName: oracle.jdbc.OracleDriver # jdbc.url: jdbc:oracle:thin:@localhost:49161:XE # jdbc.username: mytest # jdbc.password: m121212 # - name: rdb # key: postgres1 # properties: # jdbc.driverClassName: org.postgresql.Driver # jdbc.url: jdbc:postgresql://localhost:5432/postgres # jdbc.username: postgres # jdbc.password: 121212 # threads: 1 # commitSize: 3000 # - name: hbase # properties: # hbase.zookeeper.quorum: 127.0.0.1 # hbase.zookeeper.property.clientPort: 2181 # zookeeper.znode.parent: /hbase - name: es7 hosts: canal01:9300 # 127.0.0.1:9200 for rest mode properties: mode: transport # or rest # security.auth: test:123456 # only used for rest mode cluster.name: elasticsearch
修改适配器表映射文件
adapter将会自动加载 conf/es7 下的所有.yml结尾的表映射文件。
rm $CANAL_ADAPTER_HOME/conf/es7/* vim $CANAL_ADAPTER_HOME/conf/es7/test_test.yml
dataSourceKey: defaultDS # 源数据源的key, 对应上面配置的srcDataSources中的值 destination: test_to_es # cannal的instance或者MQ的topic groupId: g1 # 对应MQ模式下的groupId, 只会同步对应groupId的数据 esMapping: _index: test_test # es 的索引名称 _id: _id # es 的_id, 如果不配置该项必须配置下面的pk项_id则会由es自动分配 # pk: uid # 如果不需要_id, 则需要指定一个属性为主键属性 upsert: true # sql映射 sql: "select a.uid as _id, a.name, a.age, a.modified_time from test a" # objFields: # _labels: array:; # 数组或者对象属性, array:; 代表以;字段里面是以;分隔的 # _obj: object # json对象 # etlCondition: "where a.c_time>='{0}'" # etl 的条件参数 commitBatch: 2 # 提交批大小(生产上要大一些,这里设置为2)
sql支持多表关联自由组合, 但是有一定的限制:
1. 主表不能为子查询语句
2. 只能使用left outer join即最左表一定要是主表
3. 关联从表如果是子查询不能有多张表
4. 主sql中不能有where查询条件(从表子查询中可以有where条件但是不推荐, 可能会造成数据同步的
不一致, 比如修改了where条件中的字段内容)
5. 关联条件只允许主外键的'='操作不能出现其他常量判断比如: on a.role_id=b.id and b.statues=1
6. 关联条件必须要有一个字段出现在主查询语句中比如: on a.role_id=b.id 其中的 a.role_id 或者 b.id
必须出现在主select语句中
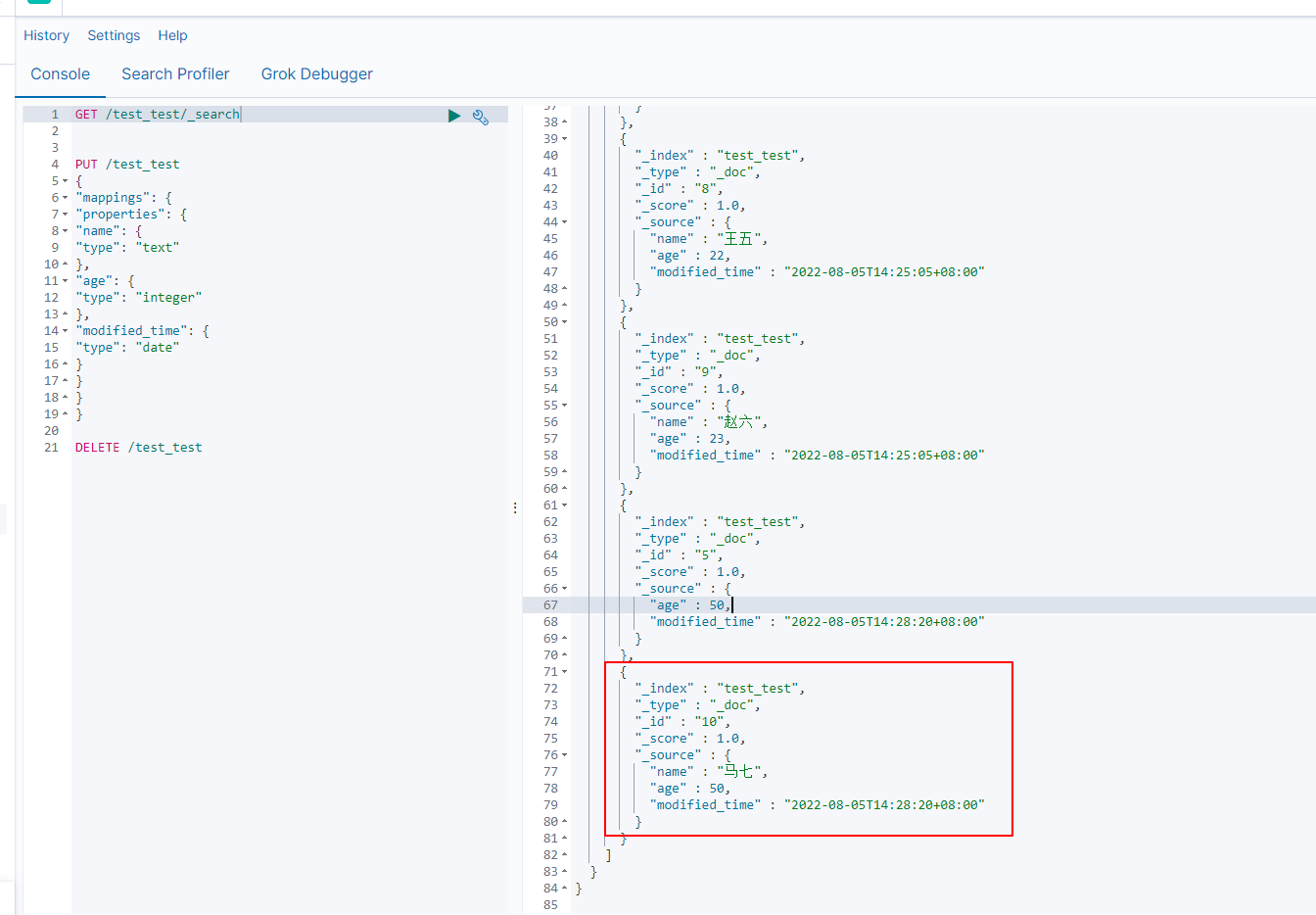
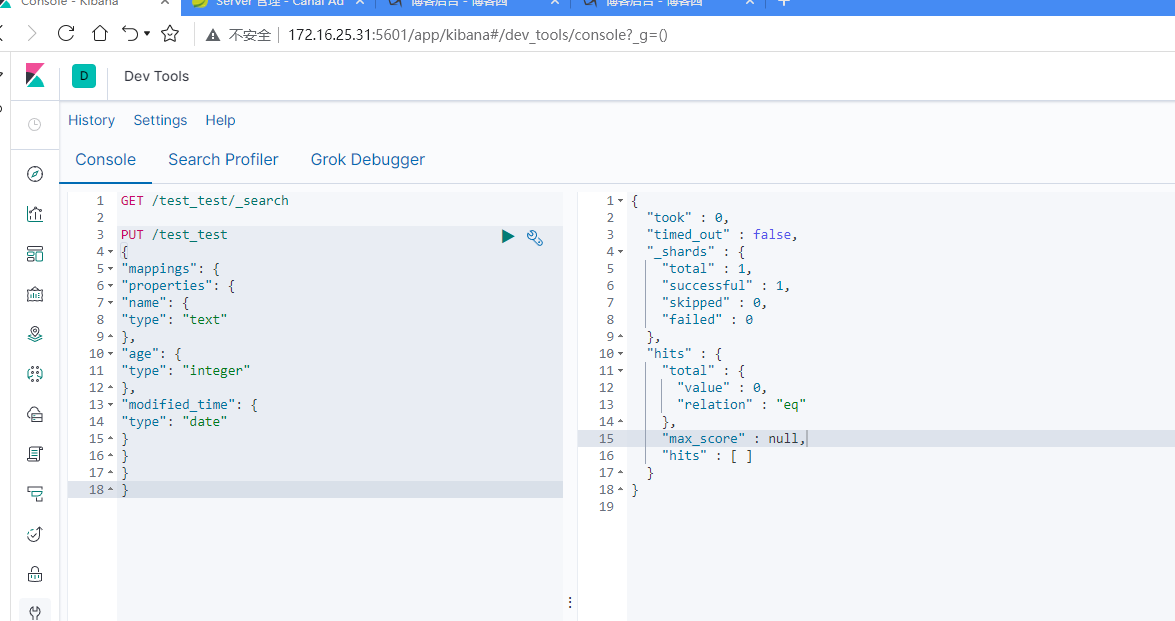
创建ES索引
PUT /test_test { "mappings": { "properties": { "name": { "type": "text" }, "age": { "type": "integer" }, "modified_time": { "type": "date" } } } }
替换MySQL驱动包
我们安装的MySQL8,但是Canal-apapter默认的MySQL驱动不支持MySQL8,因此需要替换驱动包
[root@canal01 lib]# rm mysql-connector-java-5.1.48.jar rm: remove regular file ‘mysql-connector-java-5.1.48.jar’? y [root@canal01 lib]# pwd /home/hadoop/app/canal-adapter/lib [root@canal01 lib]# ln -s /usr/share/java/mysql-connector-java-8.0.18.jar /home/hadoop/app/canal-adapter/lib/mysql-connector-java-8.0.18.jar
启动适配器
$CANAL_ADAPTER_HOME/bin/startup.sh $CANAL_ADAPTER_HOME/bin/stop.sh $CANAL_ADAPTER_HOME/bin/restart.sh
如果遇到这个问题:
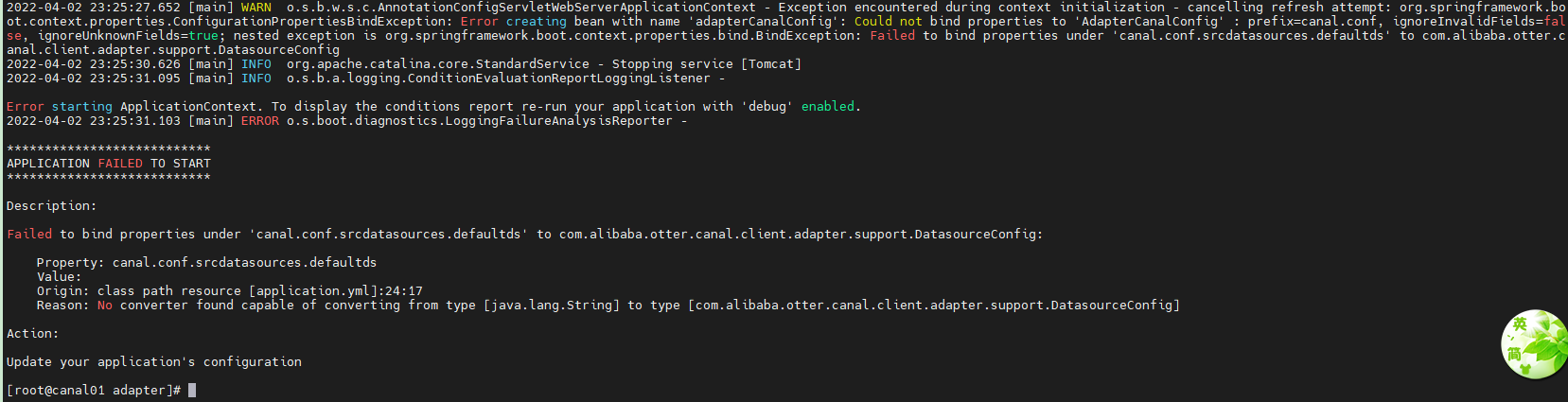
canal_manage库有脏数据导致,可以通过重新导入这个库尝试解决。
新增mysql数据
INSERT INTO test.test (name, age) VALUES ("张三",20); INSERT INTO test.test (name, age) VALUES ("李四",21); INSERT INTO test.test (name, age) VALUES ("王五",22); INSERT INTO test.test (name, age) VALUES ("赵六",23); INSERT INTO test.test (name, age) VALUES ("马七",24);
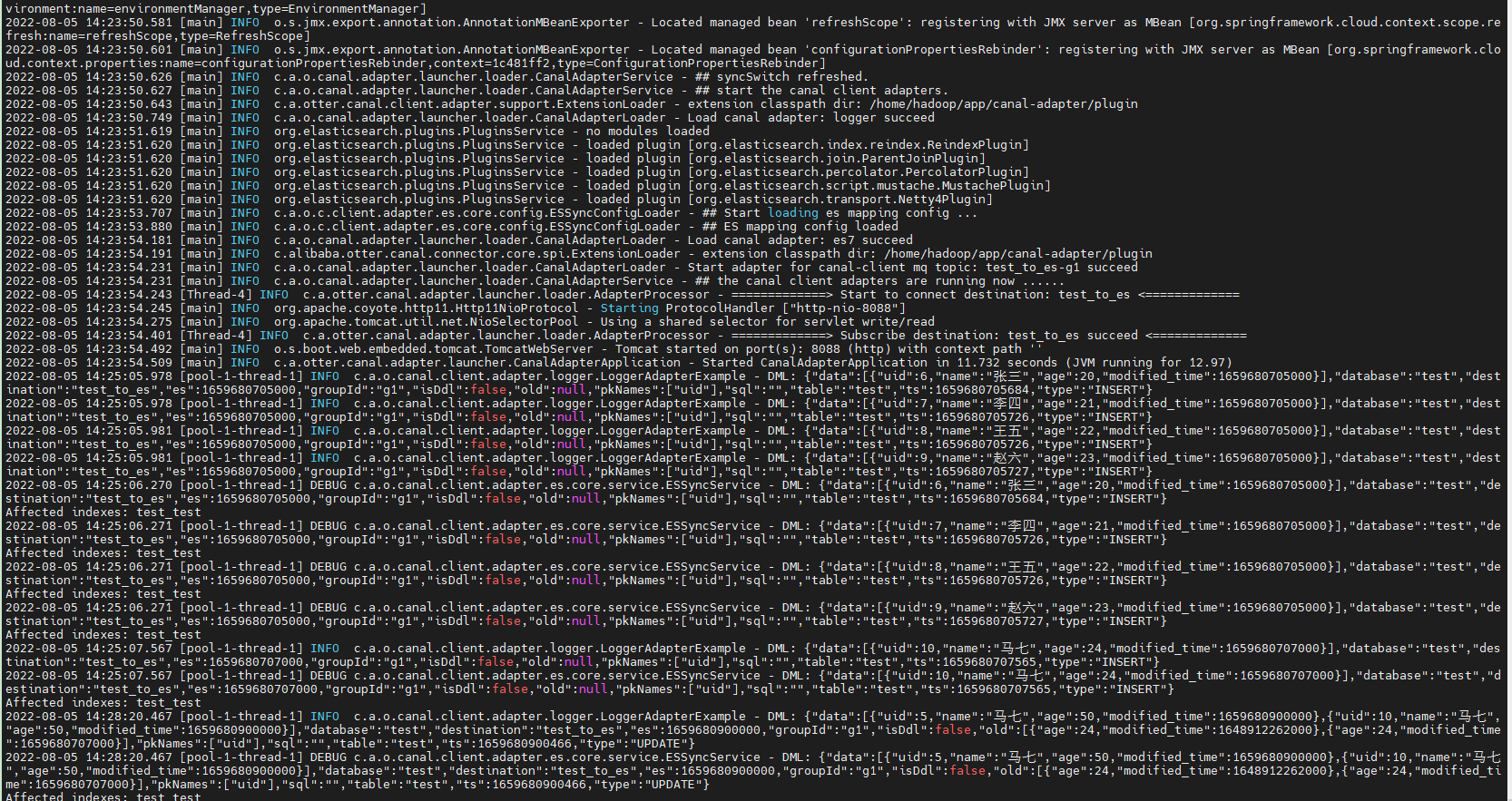
查看ClientAdapter的执行日志
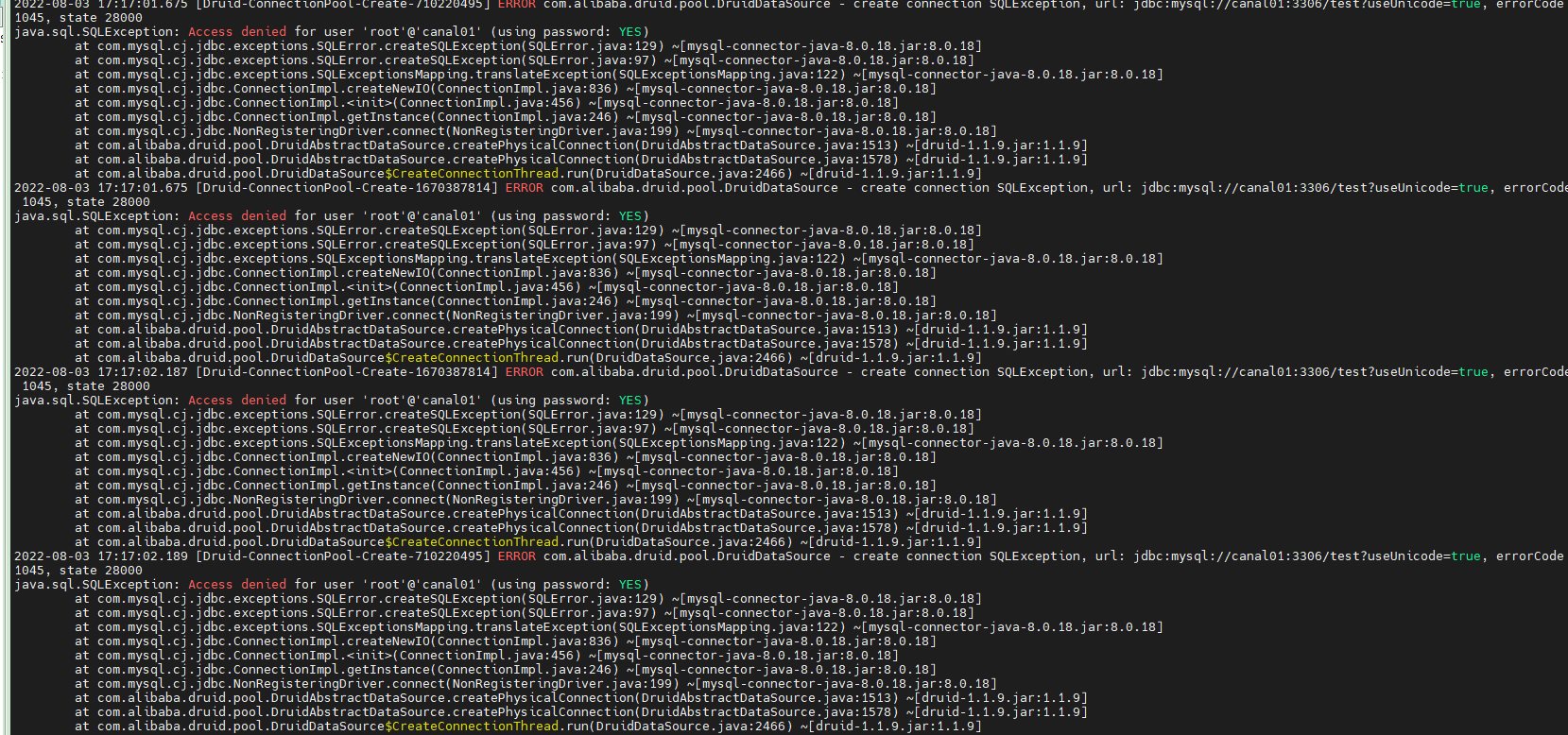
是mysql的问题,这样看应该是mysql的root用户的权限不够
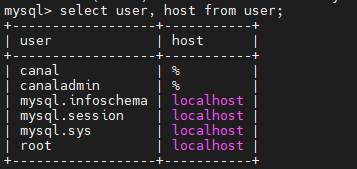
给root用户开放访问权限:
update user set host='%' where user='root'; grant all privileges on *.* to 'root'@'%' with grant option; //这句执行两次 flush privileges;
重启ClientAdapter
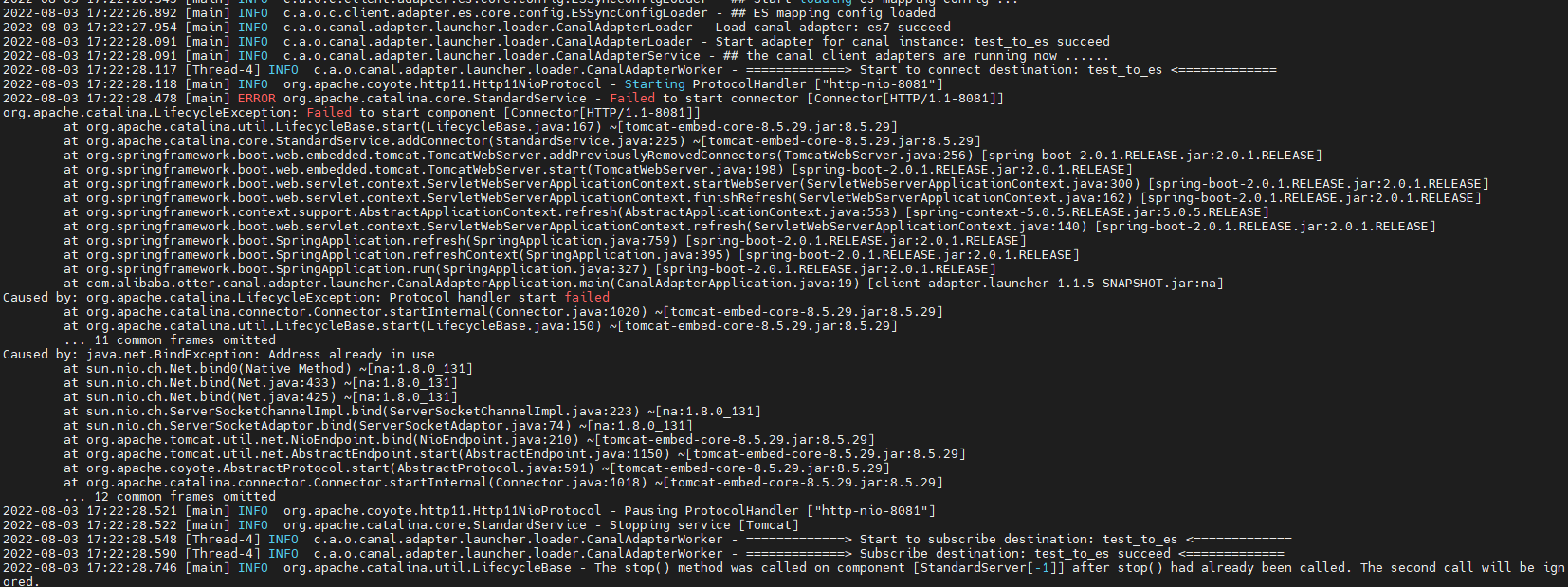
端口被占用,我换成8088端口
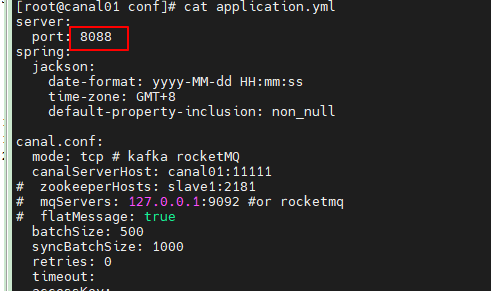
实践证明,虽然有的教程里面是成功了,至少我这次实践是没有效果,即使通过修改源码的方式,结果还是报这个错误:
当你在一个方向上面一直专研发现还是错误的时候,可以考虑换个方向了,这次我选择下载这个
配置跟前面的一样,这里我不作赘述了,这个不用下载源码编译,直接解压,修改配置文件,启动clientadapter,
这个时候有一点要注意了,因为cancal是检测的是增量数据的,如果原来在mysql对应的表已经导入数据了,直接查看es的索引看不到数据,
就一直觉得自己哪里配置有问题,一直在检测,但是到处看日志也没有发现什么。所以我们这个时候需要到mysql表里面再一次添加数据,
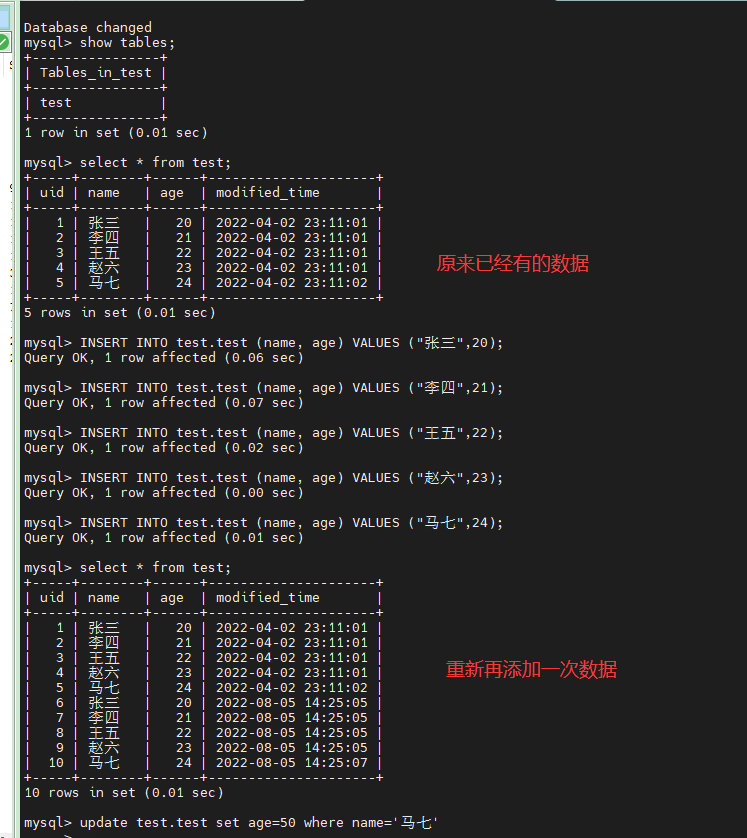
我们再通过kibana查看es索引,增量数据同步过来了
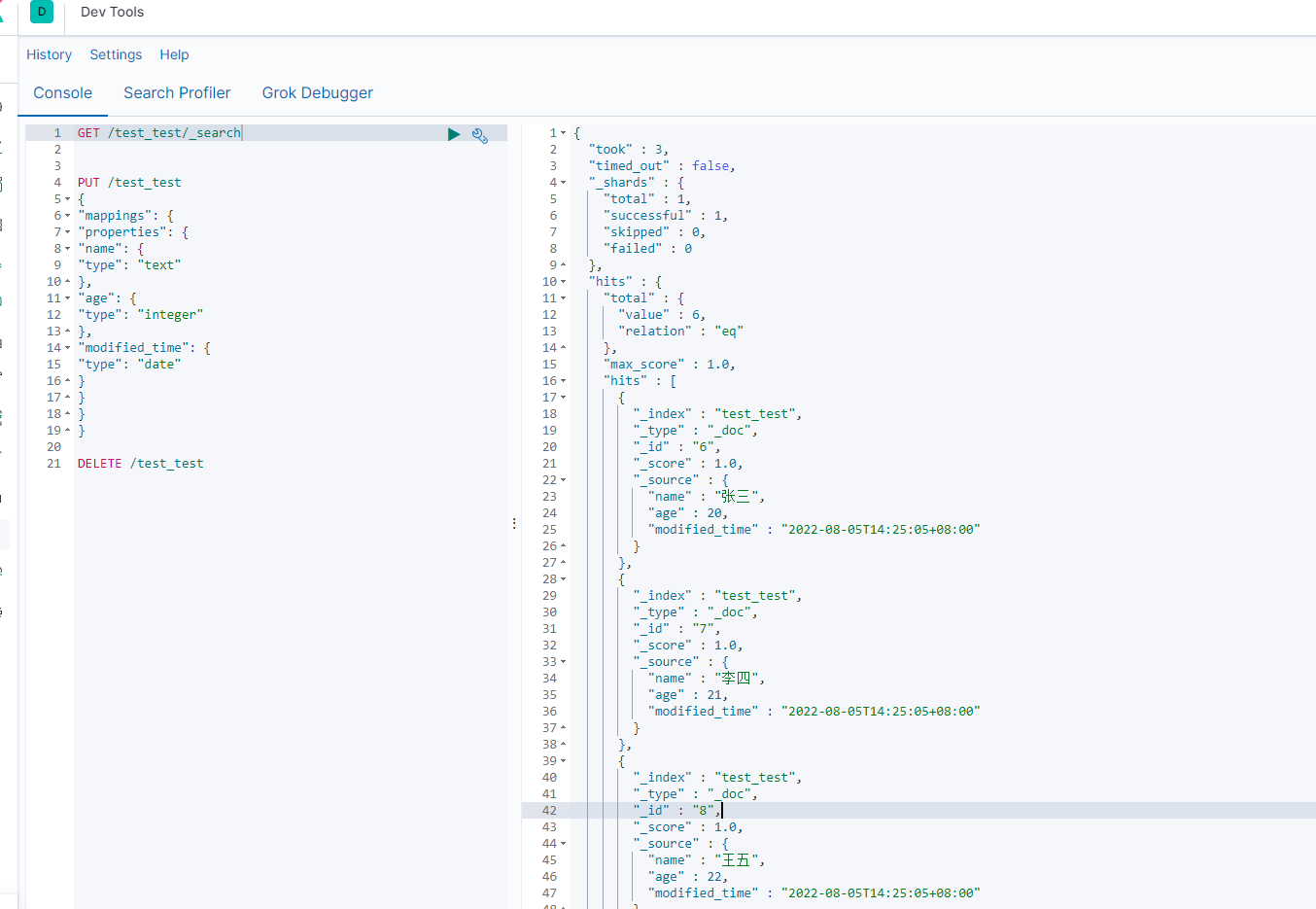
update test.test set age=50 where name='马七' ;