
在pom.xml文件添加以下依赖
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-scala_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
批处理案例
创建一个scala类


创建一个scala对象
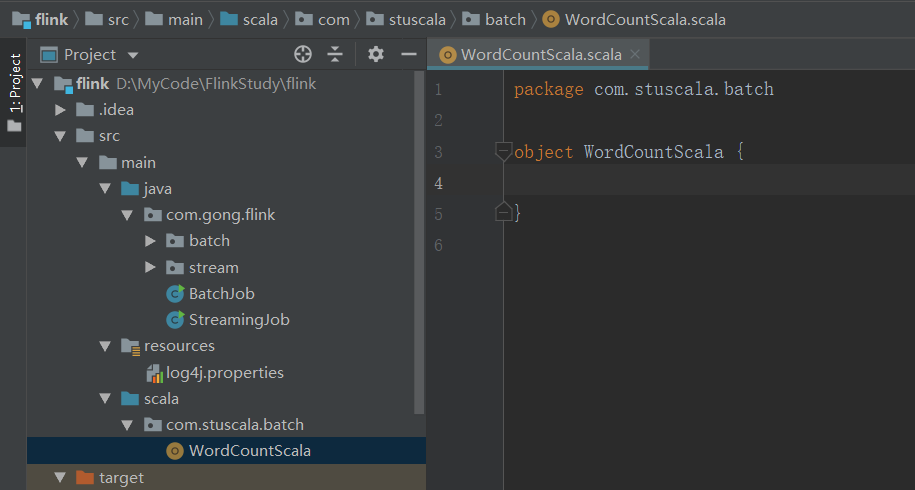
package com.stuscala.batch
import org.apache.flink.api.scala.ExecutionEnvironment
import org.apache.flink.api.scala._
object WordCount {
def main(args: Array[String]) {
//批处理程序,需要创建ExecutionEnvironment
val env = ExecutionEnvironment.getExecutionEnvironment
//fromElements(elements:_*) --- 从一个给定的对象序列中创建一个数据流,所有的对象必须是相同类型的。
val text = env.fromElements(
"Who's there?",
"I think I hear them. Stand, ho! Who's there?","hah")
val counts = text.flatMap { _.toLowerCase.split("\W+") filter { _.nonEmpty } }
.map { (_, 1) }
.groupBy(0)//根据第一个元素分组
.sum(1)
//打印
counts.print()
}
}
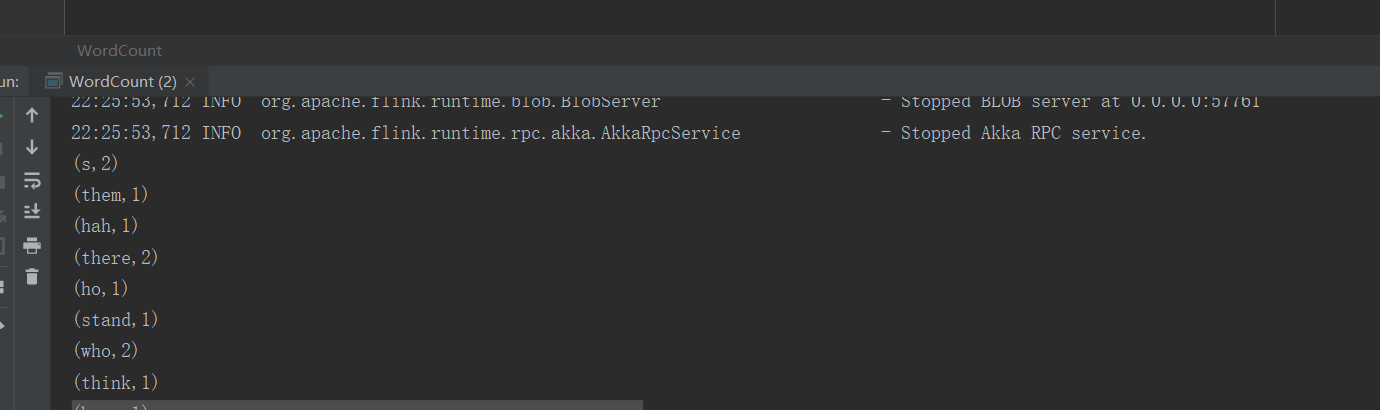
流处理案例
1、安装netcat工具,工具下载地址
https://eternallybored.org/misc/netcat/
2、解压安装包
3、将nc.exe 复制到C:WindowsSystem32的文件夹下
4、打开cmd。输入nc 命令OK~
新建一个scala类
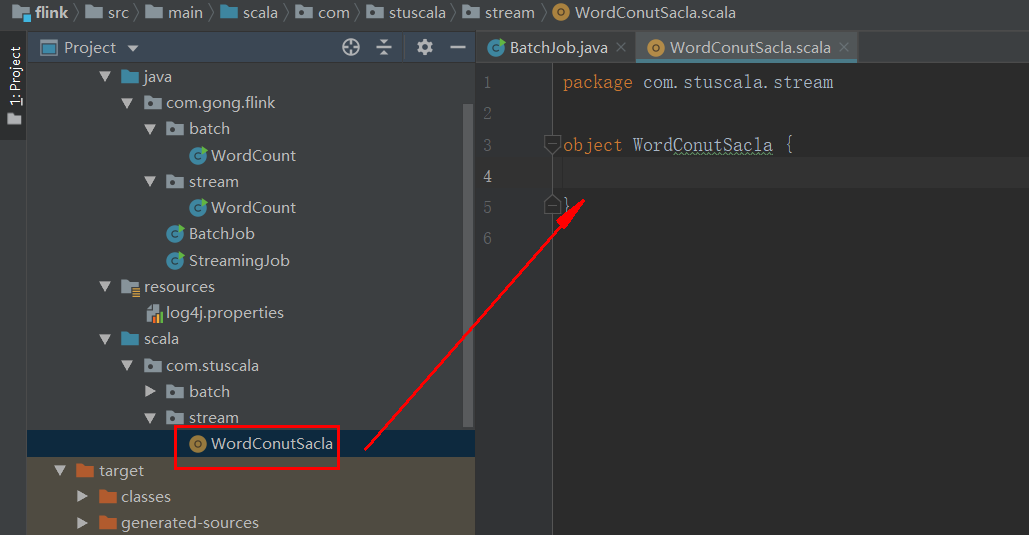
package com.stuscala.stream import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment import org.apache.flink.streaming.api.windowing.time.Time import org.apache.flink.streaming.api.scala._ object WordConutSacla { def main(args: Array[String]) { /* 在Flink程序中首先需要创建一个StreamExecutionEnvironment (如果你在编写的是批处理程序,需要创建ExecutionEnvironment),它被用来设置运行参数。 当从外部系统读取数据的时候,它也被用来创建源(sources)。 */ val env = StreamExecutionEnvironment.getExecutionEnvironment val text = env.socketTextStream("localhost", 9999) val counts = text.flatMap { _.toLowerCase.split("\W+") filter { _.nonEmpty } }//nonEmpty非空的 .map { (_, 1) } .keyBy(0)//通过Tuple的第一个元素进行分组 .timeWindow(Time.seconds(5))//Windows 根据某些特性将每个key的数据进行分组 (例如:在5秒内到达的数据). .sum(1) //将结果流在终端输出 counts.print //开始执行计算 env.execute("Window Stream WordCount") } }
打开cmd终端
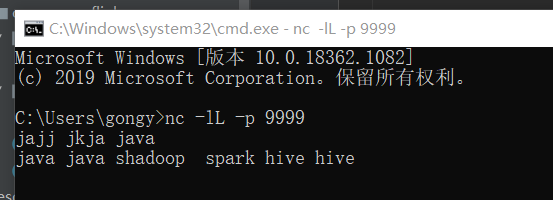
输入命令:nc -lL -p 9999 回车等待启动程序
这个时候先运行idea里面的程序
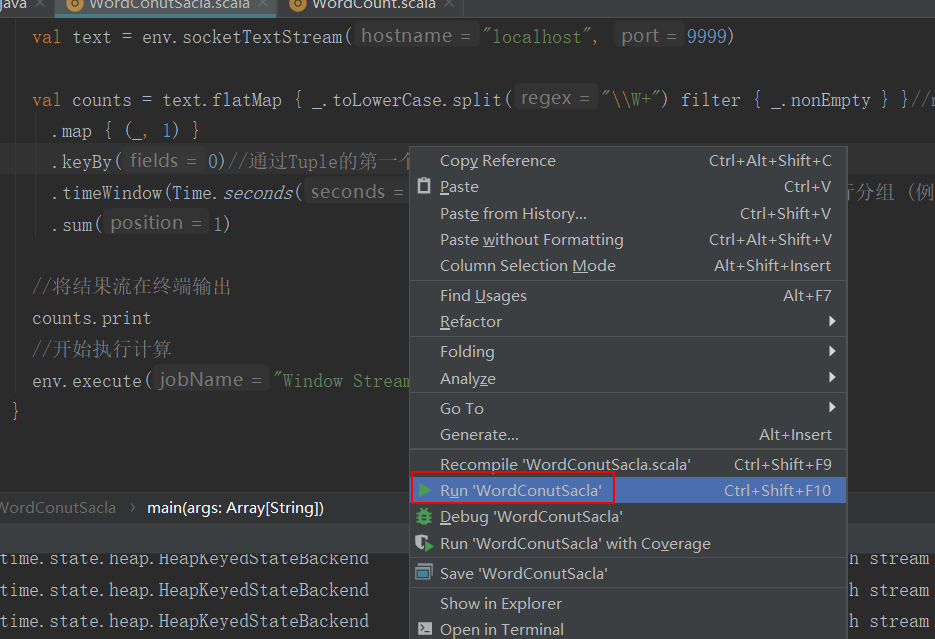

在终端输入一些单词
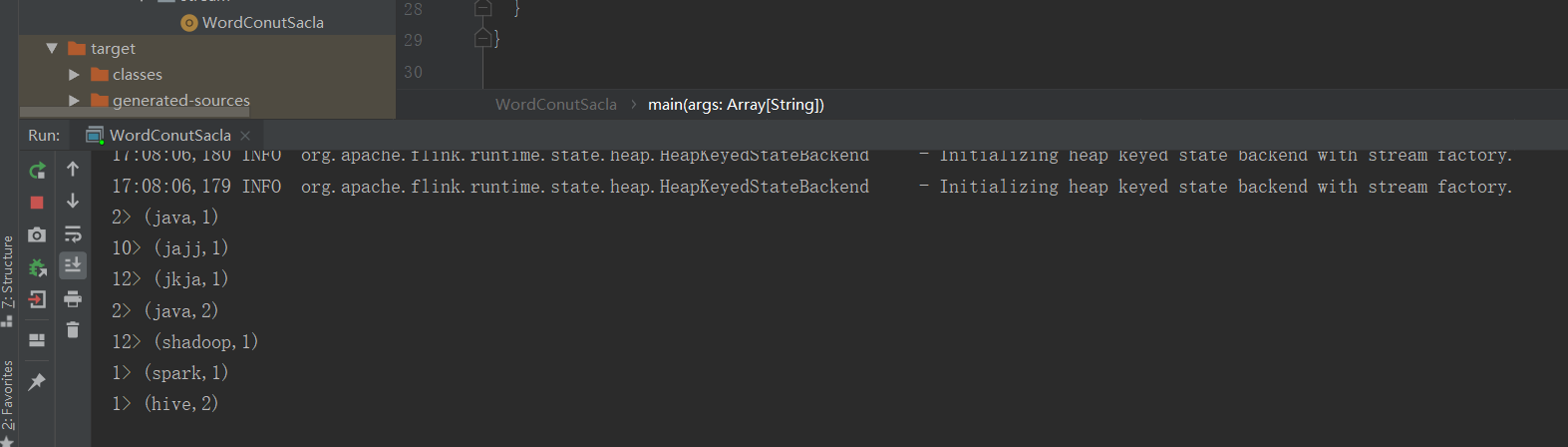
可以在idea里面看到统计的结果
关闭cmd窗口后,idea的程序会自动退出

如果需要对scala代码一起打包,就需要在pom.xml文件里面添加以下依赖了,否则打包的时候只打包java相关的
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.2</version>
<configuration>
<recompileMode>incremental</recompileMode>
</configuration>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
本文参考链接:https://blog.csdn.net/qichangjian/article/details/89152409