不知道大家又没有遇到这样的问题,某些业务系统有导出数据功能,导出的数据都是存放在excel表格里面,需要批量转csv,
但是这样的文件不是标准的excel文档,本质是html文档
比如说,系统导出的文档是这样的
从这里我们可以看出来,感觉就是一个普通的excel文档,通过office也能正常打开,但是你通过编写代码批量转csv的时候,就出问题
我也是在无意中发现这不是标准的excle文档,我们通过文档编辑器打开试试
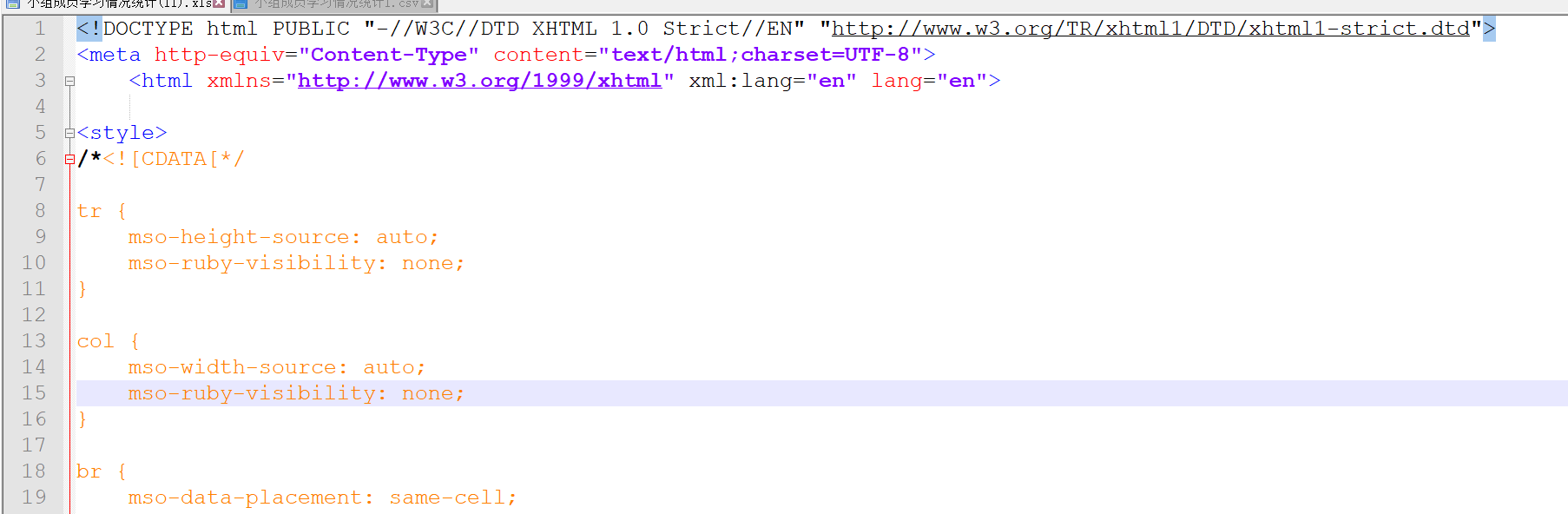
这明显就是html文件,只能怪这个业务系统的开发人员不够严谨了,现在需要我们来解决这样的问题
我们先在idea里面创建一个maven项目
package com.gong; import java.io.*; import java.util.ArrayList; import java.util.LinkedList; import java.util.List; import java.util.Scanner; import org.apache.commons.lang.StringUtils; import org.jsoup.Jsoup; import org.jsoup.nodes.Document; import org.jsoup.nodes.Element; import org.jsoup.select.Elements; /** * Jsoup解析html标签时类似于JQuery的一些符号 * * @author chixh * */ public class HtmlParser { protected List<List<String>> data = new LinkedList<List<String>>(); /** * 获取value值 * * @param e * @return */ public static String getValue(Element e) { return e.attr("value"); } /** * 获取 * <tr> * 和 * </tr> * 之间的文本 * * @param e * @return */ public static String getText(Element e) { return e.text(); } /** * 识别属性id的标签,一般一个html页面id唯一 * * @param body * @param id * @return */ public static Element getID(String body, String id) { Document doc = Jsoup.parse(body); // 所有#id的标签 Elements elements = doc.select("#" + id); // 返回第一个 return elements.first(); } /** * 识别属性class的标签 * * @param body * @param class * @return */ public static Elements getClassTag(String body, String classTag) { Document doc = Jsoup.parse(body); // 所有#id的标签 return doc.select("." + classTag); } /** * 获取tr标签元素组 * * @param e * @return */ public static Elements getTR(Element e) { return e.getElementsByTag("tr"); } /** * 获取td标签元素组 * * @param e * @return */ public static Elements getTD(Element e) { return e.getElementsByTag("td"); } /** * 获取表元组 * @param table * @return */ public static List<List<String>> getTables(Element table){ List<List<String>> data = new ArrayList<>(); for (Element etr : table.select("tr")) { List<String> listh=new ArrayList<>(); //获取表头 for(Element eth : etr.select("th")){ String th=eth.text(); listh.add(th); } if(!listh.isEmpty()) { data.add(listh); } List<String> list = new ArrayList<>(); for (Element etd : etr.select("td")) { String temp = etd.text(); //增加一行中的一列 list.add(temp); } //增加一行 if(!list.isEmpty()) { data.add(list); } } return data; } /** * 读html文件 * @param fileName * @return */ public static String readHtml(String fileName){ FileInputStream fis = null; StringBuffer sb = new StringBuffer(); try { fis = new FileInputStream(fileName); byte[] bytes = new byte[1024]; while (-1 != fis.read(bytes)) { sb.append(new String(bytes)); } } catch (FileNotFoundException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } finally { try { fis.close(); } catch (IOException e1) { e1.printStackTrace(); } } return sb.toString(); } public static void getFileName(String inputexecl,String outputcsv){ // Document doc2 = Jsoup.parse(readHtml("E:\datas\小组成员学习情况统计(11).xls")); String path = inputexecl; File f = new File(path); if (!f.exists()) { System.out.println(path + " not exists"); return; } File fa[] = f.listFiles();//获取该目录下所有文件和目录的绝对路径 for (int i = 0; i < fa.length; i++) { File fs = fa[i]; if (fs.isDirectory()) { System.out.println(fs.getName() + " [目录]"); } else{ String filepath= String.valueOf(fs); Document doc2 = Jsoup.parse(readHtml(filepath)); Element table = doc2.select("table").first(); //获取table表的内容,存放到List集合里面 List<List<String>> list = getTables(table); for (List<String> list2 : list) { for (String string : list2) { System.out.print(string+","); } System.out.println(); } String name= StringUtils.substringBeforeLast(fs.getName(),".");//获取文件名字部分 //String newFilePath="E:\datas\csv\小组成员学习.csv"; String newFilePath=outputcsv+name+".csv"; String savePath = newFilePath; File saveCSV = new File(savePath); String buffer=""; try { if(!saveCSV.exists()) saveCSV.createNewFile(); OutputStreamWriter write = new OutputStreamWriter(new FileOutputStream(saveCSV ),"UTF-8"); BufferedWriter writer = new BufferedWriter(write); for(int j=0;j<list.size();j++){ List<String> list1=new ArrayList<String>(); buffer=list.get(j).toString(); System.out.println(buffer); buffer = buffer.substring(1, buffer.lastIndexOf("]")).toString(); list1.add(buffer); writer.write(buffer); writer.newLine(); } writer.close(); } catch (IOException e) { e.printStackTrace(); } } } } public static void main(String[] args) { System.out.println("请输入Execl数据所在路径"); Scanner execl=new Scanner(System.in); String input=execl.nextLine(); //获取execl输入路径 System.out.println("请输入csv文件数据的输出路径"); Scanner csv=new Scanner(System.in); String output = csv.nextLine(); getFileName(input,output); } }
pom.xml
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.gong</groupId> <artifactId>csv</artifactId> <version>1.0-SNAPSHOT</version> <name>csv</name> <!-- FIXME change it to the project's website --> <url>http://www.example.com</url> <properties> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> <maven.compiler.source>1.7</maven.compiler.source> <maven.compiler.target>1.7</maven.compiler.target> </properties> <dependencies> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>4.11</version> <scope>test</scope> </dependency> <dependency> <groupId>net.sf.opencsv</groupId> <artifactId>opencsv</artifactId> <version>2.1</version> </dependency> <dependency> <groupId>org.apache.poi</groupId> <artifactId>ooxml-schemas</artifactId> <version>1.1</version> <type>pom</type> </dependency> <dependency> <groupId>org.apache.poi</groupId> <artifactId>poi</artifactId> <version>3.7</version> </dependency> <dependency> <groupId>org.apache.poi</groupId> <artifactId>ooxml-schemas</artifactId> <version>1.1</version> </dependency> <dependency> <groupId>org.apache.poi</groupId> <artifactId>poi-ooxml</artifactId> <version>3.7</version> </dependency> <dependency> <groupId>dom4j</groupId> <artifactId>dom4j</artifactId> <version>1.6.1</version> </dependency> <!-- https://mvnrepository.com/artifact/net.sourceforge.jexcelapi/jxl --> <dependency> <groupId>net.sourceforge.jexcelapi</groupId> <artifactId>jxl</artifactId> <version>2.6.12</version> </dependency> <dependency> <groupId>commons-lang</groupId> <artifactId>commons-lang</artifactId> <version>2.6</version> </dependency> <dependency> <groupId>org.jsoup</groupId> <artifactId>jsoup</artifactId> <version>1.11.3</version> </dependency> </dependencies> <build> <pluginManagement><!-- lock down plugins versions to avoid using Maven defaults (may be moved to parent pom) --> <plugins> <!-- clean lifecycle, see https://maven.apache.org/ref/current/maven-core/lifecycles.html#clean_Lifecycle --> <plugin> <artifactId>maven-clean-plugin</artifactId> <version>3.1.0</version> </plugin> <!-- default lifecycle, jar packaging: see https://maven.apache.org/ref/current/maven-core/default-bindings.html#Plugin_bindings_for_jar_packaging --> <plugin> <artifactId>maven-resources-plugin</artifactId> <version>3.0.2</version> </plugin> <plugin> <artifactId>maven-compiler-plugin</artifactId> <version>3.8.0</version> </plugin> <plugin> <artifactId>maven-surefire-plugin</artifactId> <version>2.22.1</version> </plugin> <plugin> <artifactId>maven-jar-plugin</artifactId> <version>3.0.2</version> </plugin> <plugin> <artifactId>maven-install-plugin</artifactId> <version>2.5.2</version> </plugin> <plugin> <artifactId>maven-deploy-plugin</artifactId> <version>2.8.2</version> </plugin> <!-- site lifecycle, see https://maven.apache.org/ref/current/maven-core/lifecycles.html#site_Lifecycle --> <plugin> <artifactId>maven-site-plugin</artifactId> <version>3.7.1</version> </plugin> <plugin> <artifactId>maven-project-info-reports-plugin</artifactId> <version>3.0.0</version> </plugin> </plugins> </pluginManagement> </build> </project>
运行分别输入excel文档的目录和csv的输出目录就可以了,在这里提醒一下大家,如果使用我这段代码的话,excel文档的数据文件不能带有其他类型的文件。