新建包

package com.it19gong.clickproject; import java.io.IOException; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; public class AccessLogPreProcessMapper extends Mapper<LongWritable, Text, Text, NullWritable> { Text text = new Text(); @Override protected void map(LongWritable key, Text value,Context context) throws IOException, InterruptedException { String itr[] = value.toString().split(" "); if (itr.length < 11) { return; } String ip = itr[0]; String date = AnalysisNginxTool.nginxDateStmpToDate(itr[3]); String url = itr[6]; String upFlow = itr[9]; text.set(ip+","+date+","+url+","+upFlow); context.write(text, NullWritable.get()); } }
package com.it19gong.clickproject; import java.text.ParseException; import java.text.SimpleDateFormat; import java.util.Date; import org.slf4j.Logger; import org.slf4j.LoggerFactory; public class AnalysisNginxTool { private static Logger logger = LoggerFactory.getLogger(AnalysisNginxTool.class); public static String nginxDateStmpToDate(String date) { String res = ""; try { SimpleDateFormat df = new SimpleDateFormat("[dd/MM/yyyy:HH:mm:ss"); String datetmp = date.split(" ")[0].toUpperCase(); String mtmp = datetmp.split("/")[1]; DateToNUM.initMap(); datetmp = datetmp.replaceAll(mtmp, (String) DateToNUM.map.get(mtmp)); System.out.println(datetmp); Date d = df.parse(datetmp); SimpleDateFormat sdf = new SimpleDateFormat("yyyy/MM/dd"); res = sdf.format(d); } catch (ParseException e) { logger.error("error:" + date, e); } return res; } public static long nginxDateStmpToDateTime(String date) { long l = 0; try { SimpleDateFormat df = new SimpleDateFormat("[dd/MM/yyyy:HH:mm:ss"); String datetmp = date.split(" ")[0].toUpperCase(); String mtmp = datetmp.split("/")[1]; datetmp = datetmp.replaceAll(mtmp, (String) DateToNUM.map.get(mtmp)); Date d = df.parse(datetmp); l = d.getTime(); } catch (ParseException e) { logger.error("error:" + date, e); } return l; } }
package com.it19gong.clickproject; import junit.framework.Test; import junit.framework.TestCase; import junit.framework.TestSuite; /** * Unit test for simple App. */ public class AppTest extends TestCase { /** * Create the test case * * @param testName name of the test case */ public AppTest( String testName ) { super( testName ); } /** * @return the suite of tests being tested */ public static Test suite() { return new TestSuite( AppTest.class ); } /** * Rigourous Test :-) */ public void testApp() { assertTrue( true ); } }
package com.it19gong.clickproject; import java.util.HashMap; public class DateToNUM { public static HashMap map = new HashMap(); public static void initMap() { map.put("JAN", "01"); map.put("FEB", "02"); map.put("MAR", "03"); map.put("APR", "04"); map.put("MAY", "05"); map.put("JUN", "06"); map.put("JUL", "07"); map.put("AUG", "08"); map.put("SEPT", "09"); map.put("OCT", "10"); map.put("NOV", "11"); map.put("DEC", "12"); } }
新建AccessLogDriver类
package com.it19gong.clickproject; import java.io.IOException; import java.util.ArrayList; import java.util.List; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.spark.SparkConf; import org.apache.spark.api.java.JavaRDD; import org.apache.spark.api.java.JavaSparkContext; import org.apache.spark.api.java.function.Function; import org.apache.spark.sql.DataFrame; import org.apache.spark.sql.Row; import org.apache.spark.sql.RowFactory; import org.apache.spark.sql.SQLContext; import org.apache.spark.sql.types.DataTypes; import org.apache.spark.sql.types.StructField; import org.apache.spark.sql.types.StructType; public class AccessLogDriver { public static void main(String[] args) throws Exception { // 创建SparkConf、JavaSparkContext、SQLContext SparkConf conf = new SparkConf() .setMaster("local") .setAppName("RDD2DataFrameProgrammatically"); JavaSparkContext sc = new JavaSparkContext(conf); SQLContext sqlContext = new SQLContext(sc); // 第一步,创建一个普通的RDD,但是,必须将其转换为RDD<Row>的这种格式 JavaRDD<String> lines = sc.textFile("E:\Mycode\dianshixiangmu\sparkproject\data\access.log"); // 分析一下 // 它报了一个,不能直接从String转换为Integer的一个类型转换的错误 // 就说明什么,说明有个数据,给定义成了String类型,结果使用的时候,要用Integer类型来使用 // 而且,错误报在sql相关的代码中 // 所以,基本可以断定,就是说,在sql中,用到age<=18的语法,所以就强行就将age转换为Integer来使用 // 但是,肯定是之前有些步骤,将age定义为了String // 所以就往前找,就找到了这里 // 往Row中塞数据的时候,要注意,什么格式的数据,就用什么格式转换一下,再塞进去 JavaRDD<Row> clickRDD = lines.map(new Function<String, Row>() { private static final long serialVersionUID = 1L; @Override public Row call(String line) throws Exception { String itr[] = line.split(" "); String ip = itr[0]; String date = AnalysisNginxTool.nginxDateStmpToDate(itr[3]); String url = itr[6]; String upFlow = itr[9]; return RowFactory.create( ip, date, url, Integer.valueOf(upFlow) ); } }); // 第二步,动态构造元数据 // 比如说,id、name等,field的名称和类型,可能都是在程序运行过程中,动态从mysql db里 // 或者是配置文件中,加载出来的,是不固定的 // 所以特别适合用这种编程的方式,来构造元数据 List<StructField> structFields = new ArrayList<StructField>(); structFields.add(DataTypes.createStructField("ip", DataTypes.StringType, true)); structFields.add(DataTypes.createStructField("date", DataTypes.StringType, true)); structFields.add(DataTypes.createStructField("url", DataTypes.StringType, true)); structFields.add(DataTypes.createStructField("upflow", DataTypes.IntegerType, true)); StructType structType = DataTypes.createStructType(structFields); // 第三步,使用动态构造的元数据,将RDD转换为DataFrame DataFrame studentDF = sqlContext.createDataFrame(clickRDD, structType); // 后面,就可以使用DataFrame了 studentDF.registerTempTable("log"); DataFrame sumFlowDF = sqlContext.sql("select ip,sum(upflow) as sum from log group by ip order by sum desc"); List<Row> rows = sumFlowDF.javaRDD().collect(); for(Row row : rows) { System.out.println(row); } } }
运行程序
新建DBHelper类
package com.it19gong.clickproject; import java.sql.Connection; import java.sql.DriverManager; import java.sql.SQLException; public class DBHelper { public static final String url ="jdbc:mysql://192.168.86.131:3306/userdb"; public static final String name="com.mysql.jdbc.Driver"; public static final String user="sqoop"; public static final String password="sqoop"; //获取数据库连接 public Connection conn=null; public DBHelper(){ try { Class.forName(name); conn = DriverManager.getConnection(url, user, password); } catch (Exception e) { // TODO: handle exception e.printStackTrace(); } } public void close(){ try { this.conn.close(); } catch (SQLException e) { // TODO: handle exception e.printStackTrace(); } } }
修改AccessLogDriver类
package com.it19gong.clickproject; import java.sql.PreparedStatement; import java.util.ArrayList; import java.util.List; import org.apache.spark.SparkConf; import org.apache.spark.api.java.JavaRDD; import org.apache.spark.api.java.JavaSparkContext; import org.apache.spark.api.java.function.Function; import org.apache.spark.api.java.function.VoidFunction; import org.apache.spark.sql.DataFrame; import org.apache.spark.sql.Row; import org.apache.spark.sql.RowFactory; import org.apache.spark.sql.SQLContext; import org.apache.spark.sql.types.DataTypes; import org.apache.spark.sql.types.StructField; import org.apache.spark.sql.types.StructType; public class AccessLogDriver { static DBHelper db1=null; public static void main(String[] args) throws Exception { // 创建SparkConf、JavaSparkContext、SQLContext SparkConf conf = new SparkConf() .setMaster("local") .setAppName("RDD2DataFrameProgrammatically"); JavaSparkContext sc = new JavaSparkContext(conf); SQLContext sqlContext = new SQLContext(sc); // 第一步,创建一个普通的RDD,但是,必须将其转换为RDD<Row>的这种格式 JavaRDD<String> lines = sc.textFile("E:\Mycode\dianshixiangmu\sparkproject\data\access.log"); // 分析一下 // 它报了一个,不能直接从String转换为Integer的一个类型转换的错误 // 就说明什么,说明有个数据,给定义成了String类型,结果使用的时候,要用Integer类型来使用 // 而且,错误报在sql相关的代码中 // 所以,基本可以断定,就是说,在sql中,用到age<=18的语法,所以就强行就将age转换为Integer来使用 // 但是,肯定是之前有些步骤,将age定义为了String // 所以就往前找,就找到了这里 // 往Row中塞数据的时候,要注意,什么格式的数据,就用什么格式转换一下,再塞进去 JavaRDD<Row> clickRDD = lines.map(new Function<String, Row>() { private static final long serialVersionUID = 1L; @Override public Row call(String line) throws Exception { String itr[] = line.split(" "); String ip = itr[0]; String date = AnalysisNginxTool.nginxDateStmpToDate(itr[3]); String url = itr[6]; String upFlow = itr[9]; return RowFactory.create( ip, date, url, Integer.valueOf(upFlow) ); } }); // 第二步,动态构造元数据 // 比如说,id、name等,field的名称和类型,可能都是在程序运行过程中,动态从mysql db里 // 或者是配置文件中,加载出来的,是不固定的 // 所以特别适合用这种编程的方式,来构造元数据 List<StructField> structFields = new ArrayList<StructField>(); structFields.add(DataTypes.createStructField("ip", DataTypes.StringType, true)); structFields.add(DataTypes.createStructField("date", DataTypes.StringType, true)); structFields.add(DataTypes.createStructField("url", DataTypes.StringType, true)); structFields.add(DataTypes.createStructField("upflow", DataTypes.IntegerType, true)); StructType structType = DataTypes.createStructType(structFields); // 第三步,使用动态构造的元数据,将RDD转换为DataFrame DataFrame studentDF = sqlContext.createDataFrame(clickRDD, structType); // 后面,就可以使用DataFrame了 studentDF.registerTempTable("log"); DataFrame sumFlowDF = sqlContext.sql("select ip,sum(upflow) as sum from log group by ip order by sum desc"); db1=new DBHelper(); final String sql="insert into upflow(ip,sum) values(?,?) "; sumFlowDF.javaRDD().foreach(new VoidFunction<Row>() { @Override public void call(Row t) throws Exception { // TODO Auto-generated method stub PreparedStatement pt = db1.conn.prepareStatement(sql); pt.setString(1,t.getString(0)); pt.setString(2,String.valueOf(t.getLong(1))); pt.executeUpdate(); } });; } }
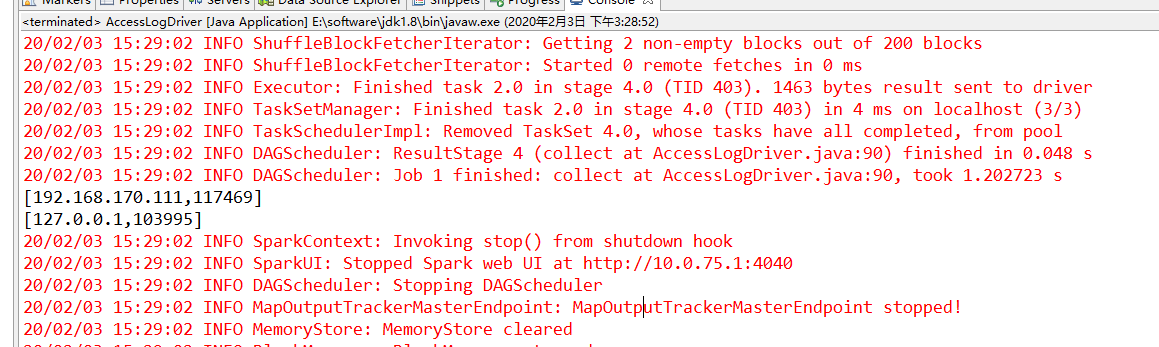
运行
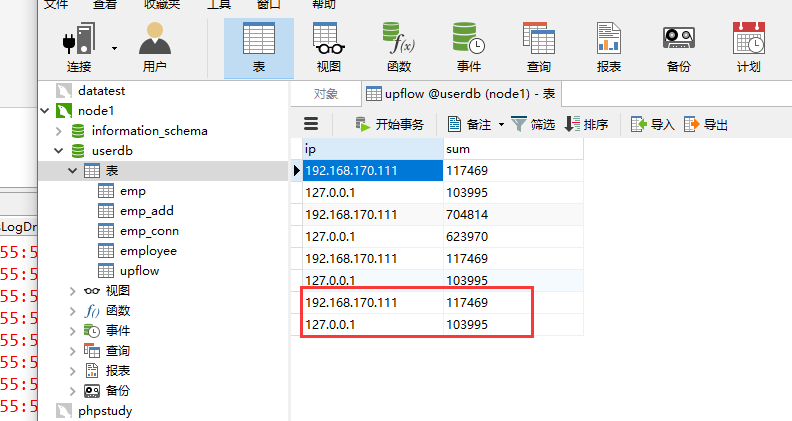
可以看到mysql数据库里面对了两条数据