1.1 Action操作
前边提到的first() 、collect() 都是Action操作。常用的有:
collect():把数据返回驱动器程序中最简单、最常见的操作, 通常在单元测试中使用,数据量不能太大,因为放在内存中,数据量大会内存溢出。
reduce():类似sum() ,如:val sum = rdd.reduce((x, y) => x + y) ,结果同sum
fold():和reduce() 类似,多一个“初始值”,当初始值为零时效果同reduce(). fold(0) = reduce()
take(n) :返回RDD 中的n 个元素,并且尝试只访问尽量少的分区。
top(n) :从RDD 中获取前几个元素
count() :用来返回元素的个数
countByValue() :返回一个从各值到值对应的计数的映射表
sum():返回汇总

启动spark-shell
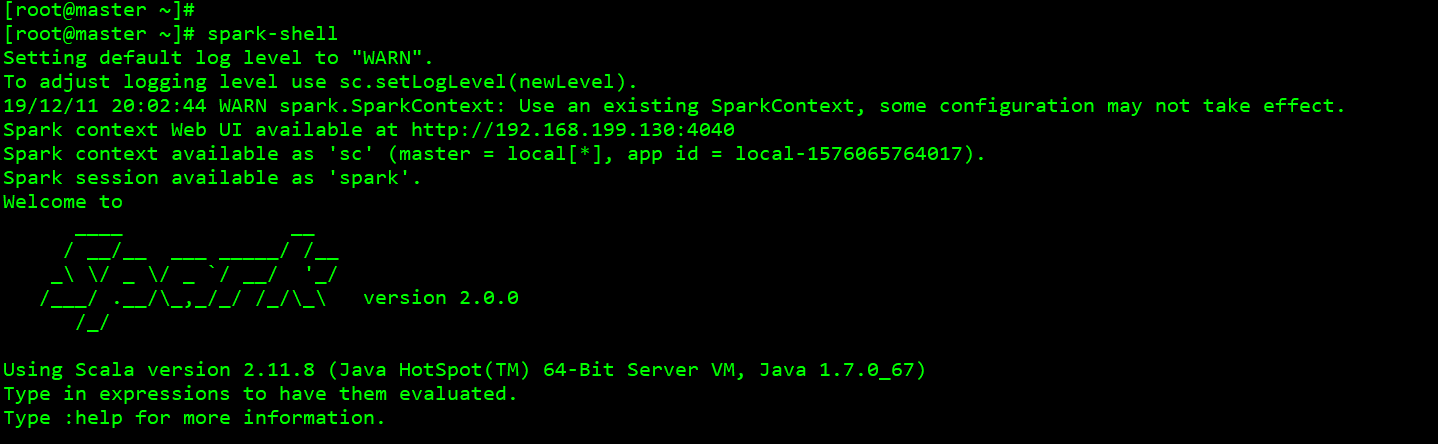
scala> val rdd=sc.parallelize(1 to 5)
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at parallelize at <console>:24
scala> rdd.count()
res0: Long = 5
scala> rdd.first()
res1: Int = 1
scala> rdd.take(2)
res2: Array[Int] = Array(1, 2)
scala> rdd.top(3)
res3: Array[Int] = Array(5, 4, 3)
scala> rdd.sum()
res4: Double = 15.0
scala> rdd.fold(0)((x,y)=>x+y)
res6: Int = 15
scala> rdd.fold(1)((x,y)=>x+y)
res7: Int = 17
fold(n) 的执行原理:
每个分区里进行这样的计算:初始值+sum(元素)
最后进行:初始值+sum(分区sum值)
初始值累加次数为分区数+1次
scala> val rdd = sc.parallelize(1 to 5,2) scala> rdd.fold(1)((x,y)=>x+y) res8: Int = 18 scala> rdd.fold(2)((x,y)=>x+y) res9: Int = 21
1.2 持久化函数persist()
RDD 是惰性(Lazy)求值的,当我们希望能多次使用同一个RDD时,RDD 调用行动操作,Spark 每次都会重算RDD 以及它的所有依赖, 这在迭代算法中消耗格外大。
如:
val rdd1 = rdd.map(x => x+1)
println(rdd1.first())
println(rdd1.count())
println(rdd1.sum())
println(rdd1.collect().mkString(","))
如果不做处理的话,每个Action函数执行时都会执行一遍rdd.map(x => x+1) ,消耗很大。
Spark提供rdd的persist()函数来解决这个重复计算的问题,persist()把需要重复使用的rdd存起来,这样仅第一个Action操作才会计算,其他Action操作不需要再计算。
当我们执行rdd的persist()时,计算出RDD 的节点会分别保存它们所求出的分区数据。如果一个有持久化数据的节点发生故障,Spark 会在需要用到缓存的数据时重算丢失的数据分区。
rdd的persist()有5种持久化级别,分别是:
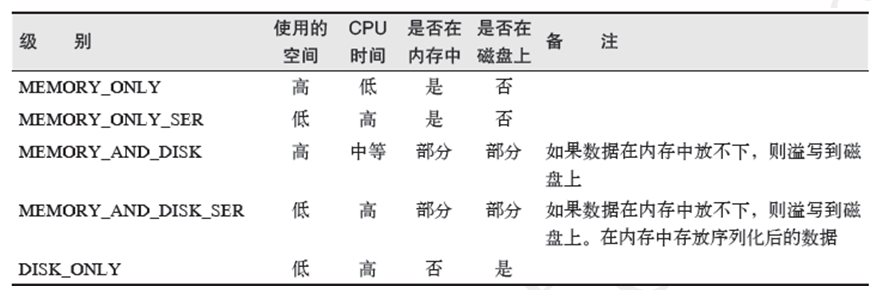
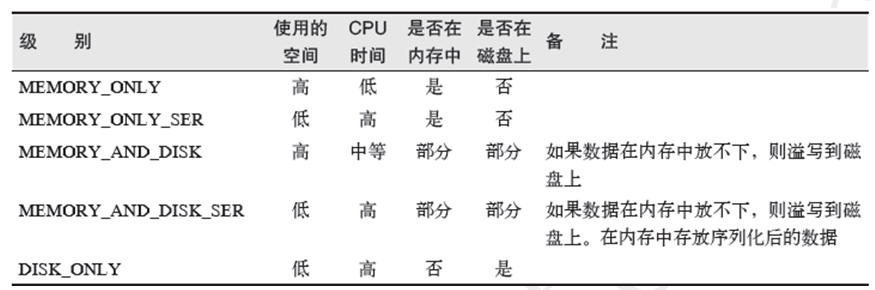
来自org.apache.spark.storage.StorageLevel 的定义。
默认情况下persist() 会把数据以序列化的形式缓存在JVM 的堆空间中。
这样上方案例可以优化为:
val rdd1 = rdd.map(x => x+1)
rdd1.persist(StorageLevel.DISK_ONLY)
println(rdd1.first())
println(rdd1.count())
println(rdd1.sum())
println(rdd1.collect().mkString(","))
rdd1.unpersist() //释放缓存,必须手工释放
如果觉得数据过于重要,怕存一份有风险,则可以存2份:
rdd1.persist(StorageLevel.MEMORY_ONLY_2)
值得注意:
如果要缓存的数据太多,内存中放不下,Spark 会自动利用最近最少使用(LRU)的缓存
策略把最老的分区从内存中移除。但是对于仅把数据存放在内存中的缓存级别,下一次要用到
已经被移除的分区时,这些分区就需要重新计算。
不必担心你的作业因为缓存了太多数据而被打断。