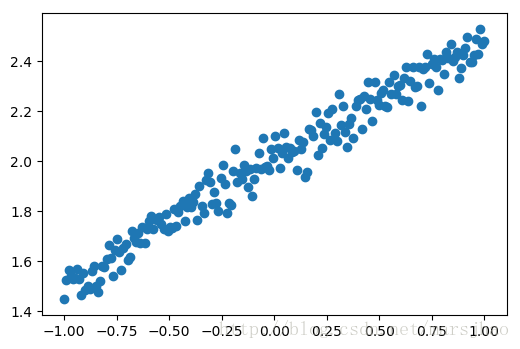
神经网络可以用来模拟回归问题 (regression),实质上是单输入单输出神经网络模型,例如给下面一组数据,用一条线来对数据进行拟合,并可以预测新输入 x 的输出值。
一、详细解读
我们通过这个简单的例子来熟悉Keras构建神经网络的步骤:
1.导入模块并生成数据
首先导入本例子需要的模块,numpy、Matplotlib、和keras.models、keras.layers模块。Sequential是多个网络层的线性堆叠,可以通过向Sequential模型传递一个layer的list来构造该模型,也可以通过.add()方法一个个的将layer加入模型中。layers.Dense 意思是这个神经层是全连接层。
2.建立模型
然后用 Sequential 建立 model,再用 model.add 添加神经层,添加的是 Dense 全连接神经层。参数有两个,(注意此处Keras 2.0.2版本中有变更)一个是输入数据的维度,另一个units代表神经元数,即输出单元数。如果需要添加下一个神经层的时候,不用再定义输入的纬度,因为它默认就把前一层的输出作为当前层的输入。在这个简单的例子里,只需要一层就够了。
3.激活模型
model.compile来激活模型,参数中,误差函数用的是 mse均方误差;优化器用的是 sgd 随机梯度下降法。
4.训练模型
训练的时候用 model.train_on_batch 一批一批的训练 X_train, Y_train。默认的返回值是 cost,每100步输出一下结果。
5.验证模型
用到的函数是 model.evaluate,输入测试集的x和y,输出 cost,weights 和 biases。其中 weights 和 biases 是取在模型的第一层 model.layers[0] 学习到的参数。从学习到的结果你可以看到, weights 比较接近0.5,bias 接近 2。
Weights= [[ 0.49136472]]
biases= [ 2.00405312]
6.可视化学习结果
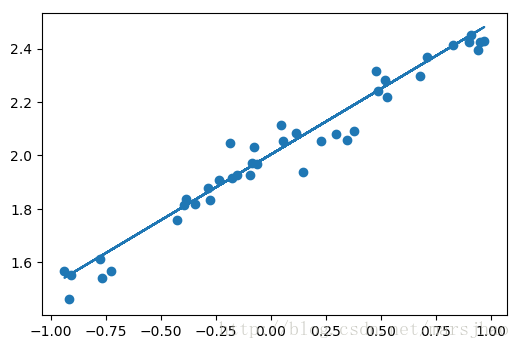
最后可以画出预测结果,与测试集的值进行对比。
二、完整代码
import numpy as np
np.random.seed(1337)
from keras.models import Sequential
from keras.layers import Dense
import matplotlib.pyplot as plt
# 生成数据
X = np.linspace(-1, 1, 200) #在返回(-1, 1)范围内的等差序列
np.random.shuffle(X) # 打乱顺序
Y = 0.5 * X + 2 + np.random.normal(0, 0.05, (200, )) #生成Y并添加噪声
# plot
plt.scatter(X, Y)
plt.show()
X_train, Y_train = X[:160], Y[:160] # 前160组数据为训练数据集
X_test, Y_test = X[160:], Y[160:] #后40组数据为测试数据集
# 构建神经网络模型
model = Sequential()
model.add(Dense(input_dim=1, units=1))
# 选定loss函数和优化器
model.compile(loss='mse', optimizer='sgd')
# 训练过程
print('Training -----------')
for step in range(501):
cost = model.train_on_batch(X_train, Y_train)
if step % 50 == 0:
print("After %d trainings, the cost: %f" % (step, cost))
# 测试过程
print('
Testing ------------')
cost = model.evaluate(X_test, Y_test, batch_size=40)
print('test cost:', cost)
W, b = model.layers[0].get_weights()
print('Weights=', W, '
biases=', b)
# 将训练结果绘出
Y_pred = model.predict(X_test)
plt.scatter(X_test, Y_test)
plt.plot(X_test, Y_pred)
plt.show()
三、其他补充
1. numpy.linspace
numpy.linspace(start, stop, num=50, endpoint=True,retstep=False,dtype=None)
返回等差序列,序列范围在(start,end),生成num个元素的np数组,如果endpoint为False,则生成num+1个但是返回num个,retstep=True则在其后返回步长.
>>> np.linspace(2.0, 3.0, num=5)
array([ 2. , 2.25, 2.5 , 2.75, 3. ])
>>> np.linspace(2.0, 3.0, num=5, endpoint=False)
array([ 2. , 2.2, 2.4, 2.6, 2.8])
>>> np.linspace(2.0, 3.0, num=5, retstep=True)
(array([ 2. , 2.25, 2.5 , 2.75, 3. ]), 0.25)