爬虫 --- 小试牛刀
一、python 连接测试URL
- 运行环境: python3.7 win7x64
- 使用工具: VS Code
- python 第三方库: requests (自行安装 >>> cmd --->pip install requests, 具体不做介绍)
- requests 库简介
| 函数 | 说明 |
| get(url [, timeout=n]) | 对应HTTP的GET方式,设定请求超时时间为n秒 |
| post(url, data={'key':'value'}) | 对应HTTP的POST方式,字典用于传输客户数据 |
| delete(url) | 对应HTTP的DELETE方式 |
| head(url) | 对应HTTP的HEAD方式 |
| options(url) | 对应HTTP的OPTIONS方式 |
| put(url, data={'key':'value'}) | 对应HTTP的PUT方式,字典用于传输客户数据 |
其中,最常用的是get方法,它能够获得url的请求,并返回一个response对象作为响应。有了响应对象,就能为所欲为了,你觉得呢 ^x^
| 属性 | 说明 |
| status_code | HTTP请求的返回状态(???咨询一下) |
| encoding | HTTP响应内容的编码方式 |
| text | HTTP响应内容的字符串形式 |
| content | HTTP响应内容的二进制形式 |
| 方法 | 说明 |
| json() | 若http响应内容中包含json格式数据, 则解析json数据 |
| raise_for_status() | 若http返回的状态码不是200, 则产生异常 |
5. 好了,我们开工 >>>
① 导入库
from requests import get
② 设定url, 并使用get方法请求页面得到响应
url = "http://www.baidu.com" r = get(url, timeout=3) print("获得响应的状态码:", r.status_code) print("响应内容的编码方式:", r.encoding)
运行结果:
获得响应的状态码: 200
响应内容的编码方式: ISO-8859-1
③ 获取网页内容
url_text = r.text print("网页内容:", r.text) print("网页内容长度:", len(url_text))
运行结果:
网页内容: <!DOCTYPE html><!--STATUS OK--><html> <head> ... 京ICPè¯030173å· ... </body> </html>
网页内容长度: 2381
惊不惊讶? 激不激动? 好不好玩? >>> 好吧,如果看到我上面 标蓝 加粗 的不明字体,你可能会 》》》问 》》》为什么?
还记得上面的编码方式吗?没错,就是他!!!
这是因为HTML代码也有自己的编码方式,我们需要使用相同的编码方式。下图是HTML语言的编码方式设置

知道了原因,那就好搞了!
④ 重新获取网页内容
r.encoding = "utf-8" url_text = r.text print("网页内容:", r.text) print("网页内容长度:", len(url_text))
运行结果:
网页内容: <!DOCTYPE html> <!--STATUS OK--><html> <head> ... 意见反馈</a> 京ICP证030173号 <img src=//www.baidu.com/img/gs.gif> </p> </div> </div> </div> </body> </html>
网页内容长度: 2287
很明显,这次可以了 ^v^
二、python 疯狂连接URL
- 使用上述的连接测试 "经验", 找个网站进行疯狂连接
- 在此,选取搜狗网站
- 上代码
url = "http://www.sogou.com" # 搜狗 for i in range(200): print("Test %d:" % (i+1), end=" ") response = get(url, timeout=5) # 判断连接状态 if response.status_code == 200: print("Conncect successful!") else: print("Conncect UNsuccessful!")
运行结果:
Test 1: Conncect successful!
Test 2: Conncect successful!
Test 3: Conncect successful!
Test 4: Conncect successful!
Test 5: Conncect successful!................
Test 199: Conncect successful!
Test 200: Conncect successful!
结果有200行,我就不 一 一 输出了。试一下呗,你也可以的哦 ^_^
三、获取网页的各个属性标签内容
(我也不知道这个标题什么意思, 感觉很牛但看不懂, 才怪呢!你肯定看得懂!)
这里,选取一个很厉害的网站做演示
URL = https://www.runoob.com/
步骤说明:
1. 找个url, 上面有了, 其实随便一个都是OK的
2. 抓取网页内容,这个上面有详解,不难
3. 本次使用 BeautifulSoup 第三方库,需要自行下载【详情介绍】
4. 开工
前面提供了 URL,现在抓取网页内容
1 # -*- encoding:utf-8 -*- 2 from requests import get 3 def getText(url): 4 try: 5 r = get(url, timeout=5) 6 r.raise_for_status() 7 r.encoding = 'utf-8' 8 return r.text 9 except Exception as e: 10 print("Error:", e) 11 return ''
然后再引入 beautifulsoup库,不过与其他的库有点不一样,别写错了哟
from bs4 import BeautifulSoup
之后创建一个 beautifulsoup 对象
1 url = "https://www.runoob.com/" 2 html = getText(url) 3 soup = BeautifulSoup(html)
好了,现在想要干嘛就干嘛 ↓↓↓
① 获取 head 标签
print("head:", soup.head) print("head:", len(soup.head))
由于结果比较多,就只输出第二个结果
head: 33
② 获取 body 标签
print("body:", soup.body) print("body:", len(soup.body))
由于结果比较多,就只输出第二个结果
body: 39
③ 获取 title 标签
print("title:", soup.title)
title: <title>菜鸟教程 - 学的不仅是技术,更是梦想!</title>
④ 获取 title 的内容
print("title_string:", soup.title.string)
title_string: 菜鸟教程 - 学的不仅是技术,更是梦想!
⑤ 查找特定 id 的内容
print("special_id:", soup.find(id='cd-login'))
special_id: <div id="cd-login"> <!-- 登录表单 -->
<div class="cd-form">
<p class="fieldset"> ......
⑥ 查找所有的 a 标签
a: [<a href="/">菜鸟教程 -- 学的不仅是技术,更是梦想!</a>, <a class="current" data-id="index" href="//www.runoob.com/" title="菜鸟教程">首页</a>, ......
⑦ 摘取所有的中文字符
1 import re 2 def getChinese(text): 3 text_unicode = text.strip() # 将字符串进行处理, 包括转化为unicode 4 string = re.compile('[^u4e00-u9fff]') 5 # 中文编码范围是 u4e00-u9ffff 6 # 中文、数字编码范围是 u4e00-u9fa50 7 chinese = "".join(string.split(text_unicode)) 8 return chinese
print("Chinese:", getChinese(html))
Chinese: 菜鸟教程学的不仅是技术更是梦想菜鸟教程提供了编程的基础技术教程 ......
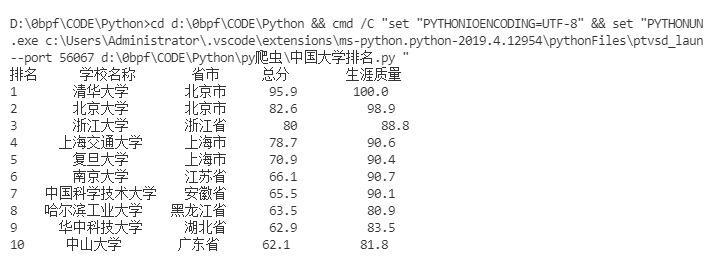
四、爬取中国大学排名
此处就不细讲,直接上代码
1 # -*- coding: utf-8 -*- 2 ''' 3 获取中国大学的排名 4 @author: bpf 5 ''' 6 import requests 7 from bs4 import BeautifulSoup 8 import pandas 9 # 1. 获取网页内容 10 def getHTMLText(url): 11 try: 12 r = requests.get(url, timeout = 30) 13 r.raise_for_status() 14 r.encoding = 'utf-8' 15 return r.text 16 except Exception as e: 17 print("Error:", e) 18 return "" 19 20 # 2. 分析网页内容并提取有用数据 21 def fillTabelList(soup): # 获取表格的数据 22 tabel_list = [] # 存储整个表格数据 23 Tr = soup.find_all('tr') 24 for tr in Tr: 25 Td = tr.find_all('td') 26 if len(Td) == 0: 27 continue 28 tr_list = [] # 存储一行的数据 29 for td in Td: 30 tr_list.append(td.string) 31 tabel_list.append(tr_list) 32 return tabel_list 33 34 # 3. 可视化展示数据 35 def PrintTableList(tabel_list, num): 36 # 输出前num行数据 37 print("{1:^2}{2:{0}^10}{3:{0}^5}{4:{0}^5}{5:{0}^8}".format(chr(12288), "排名", "学校名称", "省市", "总分", "生涯质量")) 38 for i in range(num): 39 text = tabel_list[i] 40 print("{1:{0}^2}{2:{0}^10}{3:{0}^5}{4:{0}^8}{5:{0}^10}".format(chr(12288), *text)) 41 42 # 4. 将数据存储为csv文件 43 def saveAsCsv(filename, tabel_list): 44 FormData = pandas.DataFrame(tabel_list) 45 FormData.columns = ["排名", "学校名称", "省市", "总分", "生涯质量", "培养结果", "科研规模", "科研质量", "顶尖成果", "顶尖人才", "科技服务", "产学研合作", "成果转化"] 46 FormData.to_csv(filename, encoding='utf-8', index=False) 47 48 if __name__ == "__main__": 49 url = "http://www.zuihaodaxue.cn/zuihaodaxuepaiming2016.html" 50 html = getHTMLText(url) 51 soup = BeautifulSoup(html, features="html.parser") 52 data = fillTabelList(soup) 53 #print(data) 54 PrintTableList(data, 10) # 输出前10行数据 55 saveAsCsv("D:\University_Rank.csv", data)
运行结果: