df.dropna
dropna(axis=0, how='any', thresh=None, subset=None, inplace=False) 主要参数说明: Parameters ---------- axis : {0 or 'index', 1 or 'columns'}, or tuple/list thereof Pass tuple or list to drop on multiple axes how : {'any', 'all'} * any : if any NA values are present, drop that label * all : if all values are NA, drop that label thresh : int, default None int value : require that many non-NA values subset : array-like Labels along other axis to consider, e.g. if you are dropping rows these would be a list of columns to include inplace : boolean, default False
If True, do operation inplace and return None
>>>df = pd.DataFrame([[np.nan, 2, np.nan, 0], [3, 4, np.nan, 1], [np.nan, np.nan, np.nan, np.nan], [1,2,3,4]], columns=list('ABCD')) >>>df.dropna() A B C D 3 1.0 2.0 3.0 4.0 >>>df.dropna(how='any') A B C D 3 1.0 2.0 3.0 4.0 >>>df.dropna(how='all') A B C D 0 NaN 2.0 NaN 0.0 1 3.0 4.0 NaN 1.0 3 1.0 2.0 3.0 4.0
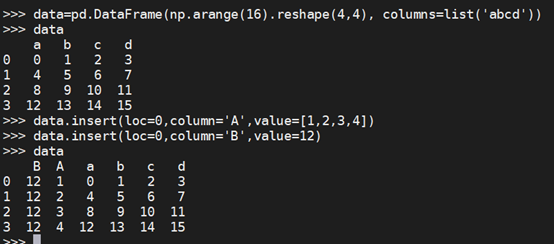
df.insert
insert(loc, column, value, allow_duplicates=False) 参数: loc: int型,表示第几列;若在第一列插入数据,则 loc=0 column: 给插入的列取名,如 column='新的一列' value:数字,array,series等都可(可自己尝试) allow_duplicates: 是否允许列名重复,选择Ture表示允许新的列名与已存在的列名重复。
>>> data=pd.DataFrame(np.arange(16).reshape(4,4), columns=list('abcd')) >>> data.insert(loc=0,column='A',value=[1,2,3,4]) >>> data.insert(loc=0,column='B',value=12)
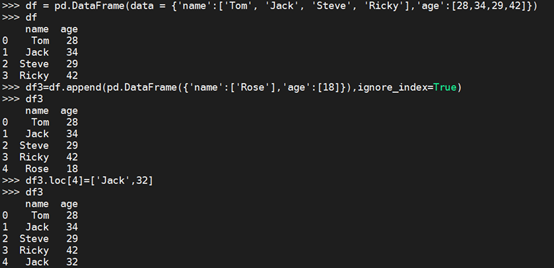
df.append
append(other, ignore_index=False, verify_integrity=False, sort=False) Parameters ---------- other : DataFrame or Series/dict-like object, or list of these The data to append. ignore_index : bool, default False If True, do not use the index labels. verify_integrity : bool, default False If True, raise ValueError on creating index with duplicates. sort : bool, default False
>>> df = pd.DataFrame(data = {'name':['Tom', 'Jack', 'Steve', 'Ricky'],'age':[28,34,29,42]})
>>> df3=df.append(pd.DataFrame({'name':['Rose'],'age':[18]}),ignore_index=True)
>>> df3.loc[4]=['Jack',32]