原文:http://www.sohu.com/a/145065274_262549
今天主要有四个课题:
先聊一聊 DevOps;
然后跟大家聊一聊运维知识的体系和职业发展;
再是中小企业基于开源的 Web 架构演变;
最后是全链略自动化体系;
1、DevOps杂谈
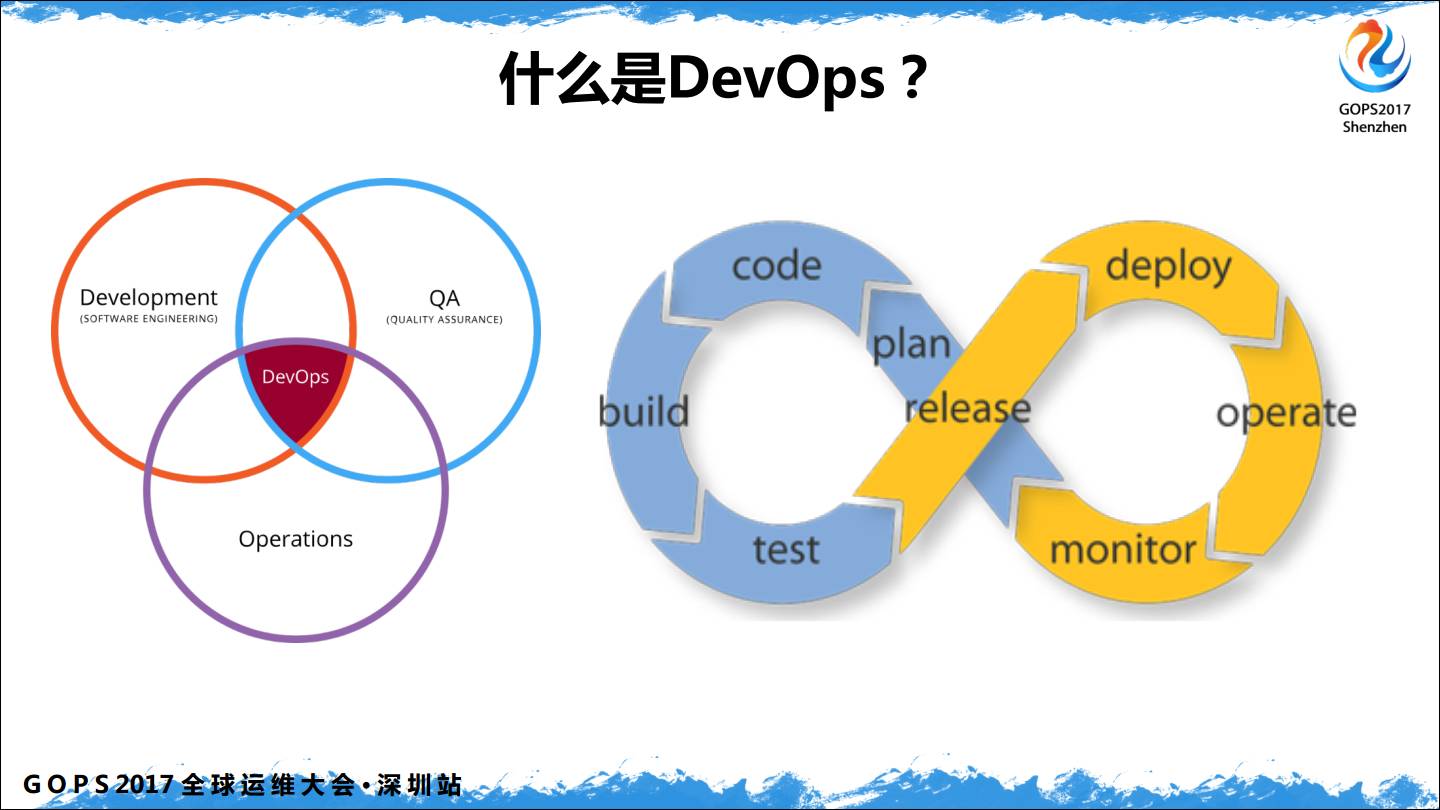
DevOps 我相信大家都已经不陌生了,这类的分享很多,DevOps 的1.0版本我认为是怎么做持续交付,上图右侧的是一个持续交付环。
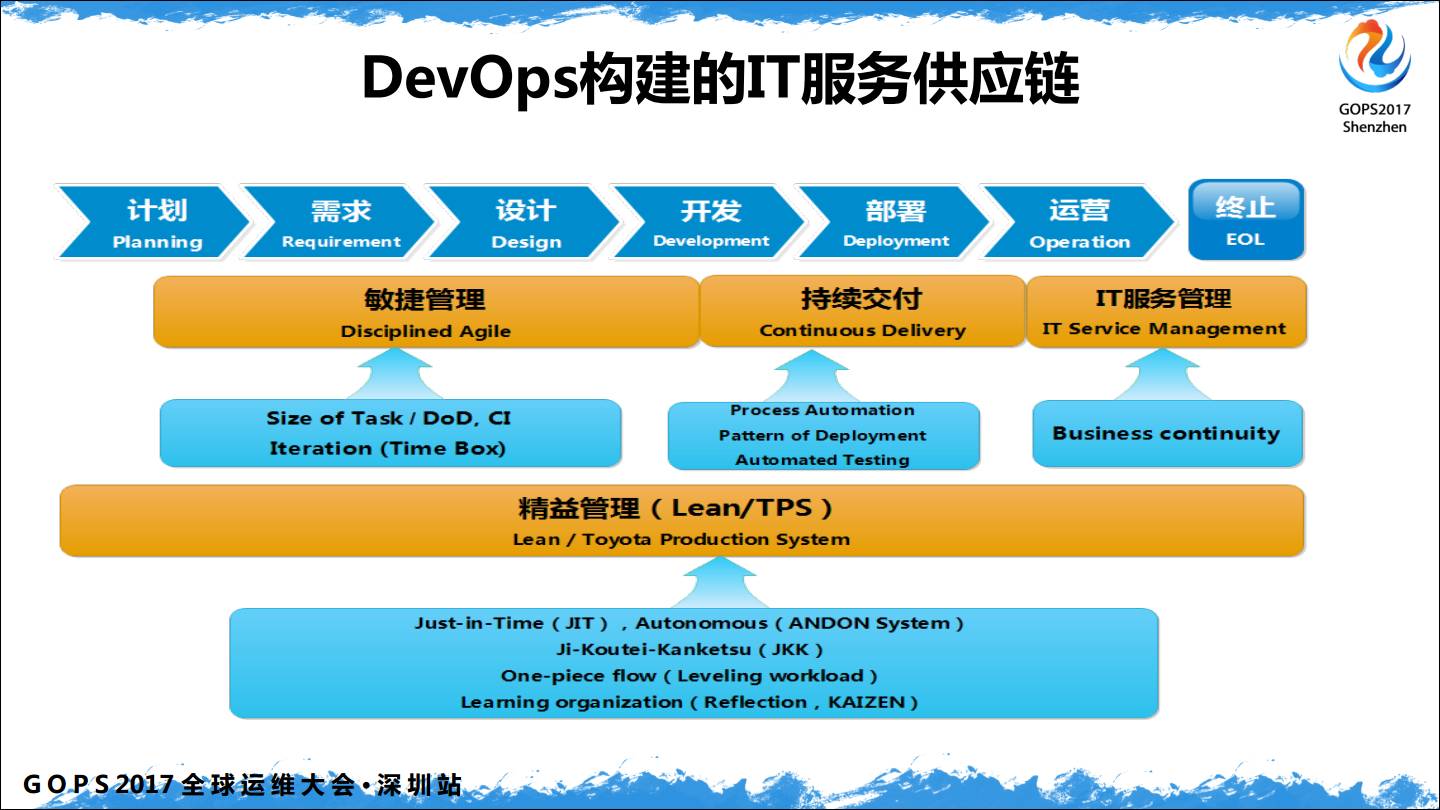
DevOps2.0 就是构建IT服务供应链,有人问我学DevOps 应该学什么?按照这些来学,敏捷、精益、持续交付和IT服务管理,想做好运维工作必须精通持续交付和IT服务管理,现在想成为一个DevOps 工程师,敏捷和精益也是必需要去学的。

DevOps 的 CALMS 文化,我个人总结了一个运维的文化,称之为”运维的批评与自我批评”,下面这张图是我们武警部队的例会,一般在每周二开的“民主生活会”,以班为单位,目的就是做批评与自我批评。

主要内容是每个人都发言,指出我们班在哪些方面做的不够好以及自身存在的问题。我认为批评与自我批评是一种非常棒的模式,值得推广。我个人做运维经理、总监的时候,我从来不会给团队成员说你想涨工资的话要努力工作,好好学习这些鼓励的话,我主要的激励方式是靠打击。

我之前有一个理论是“鼓励”员工跳槽。你埋怨工资低,为什么不跳槽?。很多时候工资低不是企业的问题,是个人能力问题。
完整的文章,请访问下面链接:
《我为什么“鼓励”员工离职?》

我相信大家对这个话题都有自己的理解,我先说一下我的理解,在说之前我先发一个警告,我这个话题比较偏激,因为我要用这种相对“偏激”的话术来影响身边的朋友,不一定是对的,但是可以引起大家的一些思考。

这就是我的运维“能力不行”论,其实总结起来就是要先从自身找原因,能让你快速的强大起来,所有的原因可能都是自身能力不足导致的。
举个例子,之前我在推动自动化部署落地时遇到很大的阻力,因为涉及到开发、测试、运维,很难推动。当时第一感觉是,队友是傻X。后来慢慢醒悟(因为我定期会做自我批评)。反思这个事情为什么会推行不下去,原因很简单,我的沟通能力不行!
大家认为成为一个更高级的工程师,拿更多的薪资是因为你的技术吗?大部分都不是,你拿多少钱不在于你技术的高低,而在于你能给公司带来多大的价值。有人觉得自己技术很牛,为什么工资没有那么高。你技术确实很厉害,但是没有给公司创造价值,这是切实的问题。这可能是你除技术外其它能力不行!
自动部署这个事情,我后来天天请做开发的哥们儿吃饭,大家觉得很奇怪,怎么用这样的手段?我天天找他,把关系处的很好,之后跟他说“兄弟,我现在要推自动化部署,怎么办?”找他协助,这也是一种能力,谁说人际交往能力不是我们工作必备的能力呢?当然其实后来我找了他四次之后这个事情才落地。
可能有人认为在第一次协商失败之后,就认为这个哥们儿不配合,不支持自己的工作。其实不是的,因为每个人都有自己的事情,你觉得重要的事情,别人未必觉得,千万不要先入为主!这是我的经验。

很多时候我们总是认为别人有问题,其实真正是自己能力的问题。不管是什么原因,要记住,沟通也是运维必备技能之一,并不是掌握各种技术,很多时候软技能反而起很重要的作用。
我希望大家不要把运维能力局限于技术能力,尽量的把往外延伸。技术是成长的必备条件,但不是唯一条件。
2、运维知识体系与职业发展
大家过年回家有没有跟家人介绍自己的工作,什么是运维?,前些年,我在家里就遇到过这个问题,我认真的回答后,有一个做Java开发的弟弟,想了半天,说他知道,就是网管。
这说明大多数人都小看运维了,所以我根据自己的一些经历,编写了运维知识体系,就是要告诉他人,不要小看运维,运维掌握的知识并不比其它职位少,甚至要多很多。
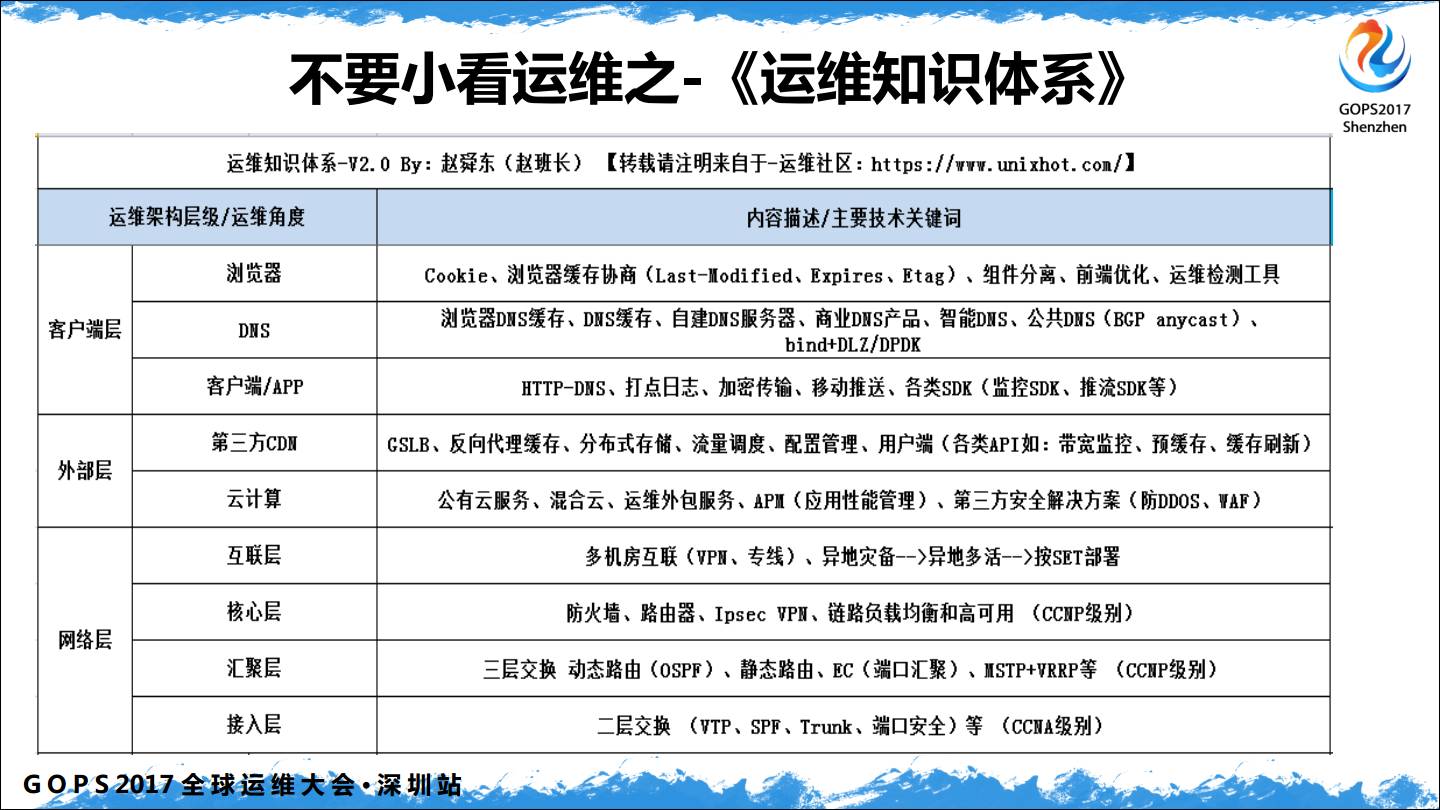
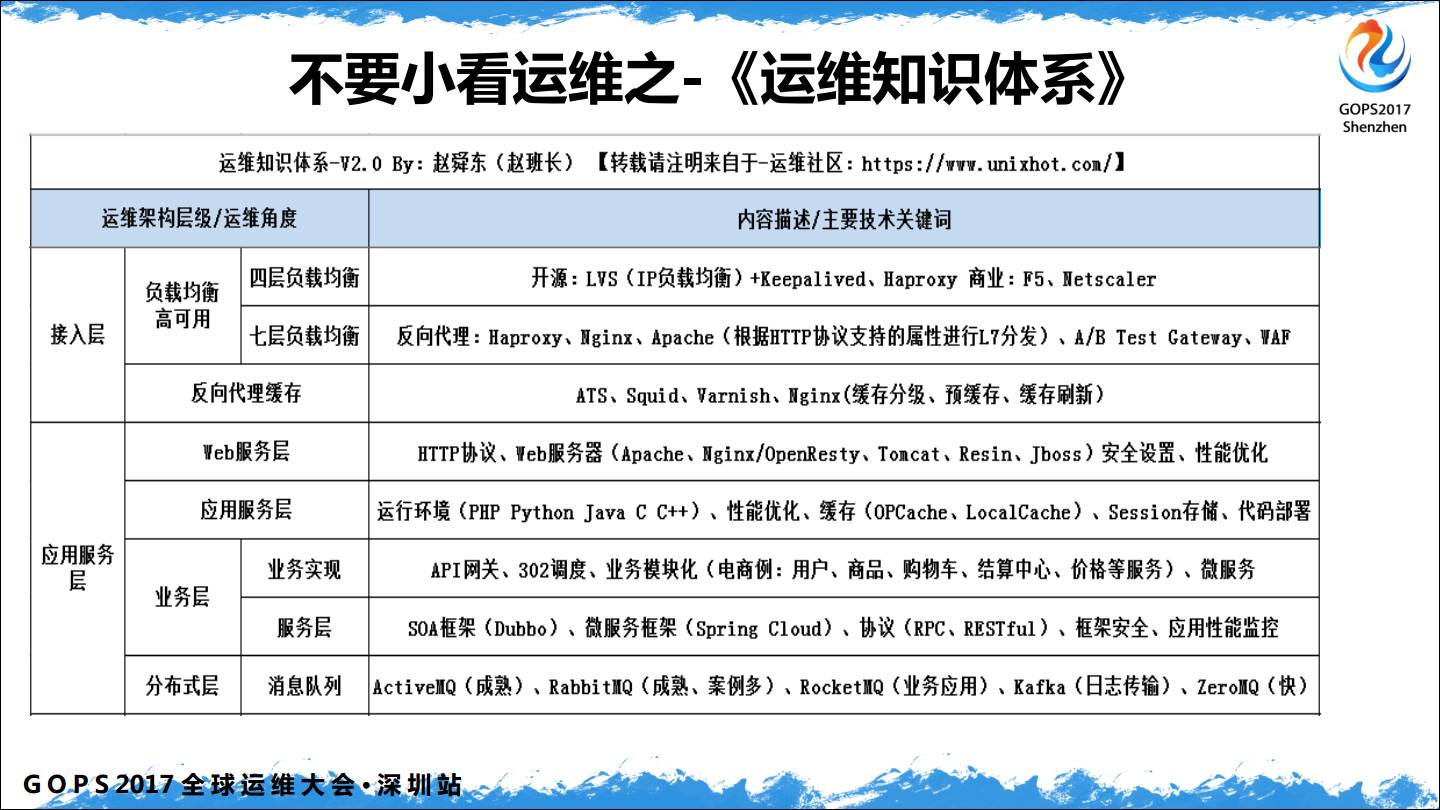
整体是按照一个HTTP请求从客户端发出到服务端所经历的层和涉及到的技术,并没有严格意义上的上下关系。
存储层并没有按照文件存储、块存储、对象存储这样的方式来进行划分,而是统称为文件存储和数据存储。

基础服务和容器层,操作系统层列举了运维必备的基础知识。
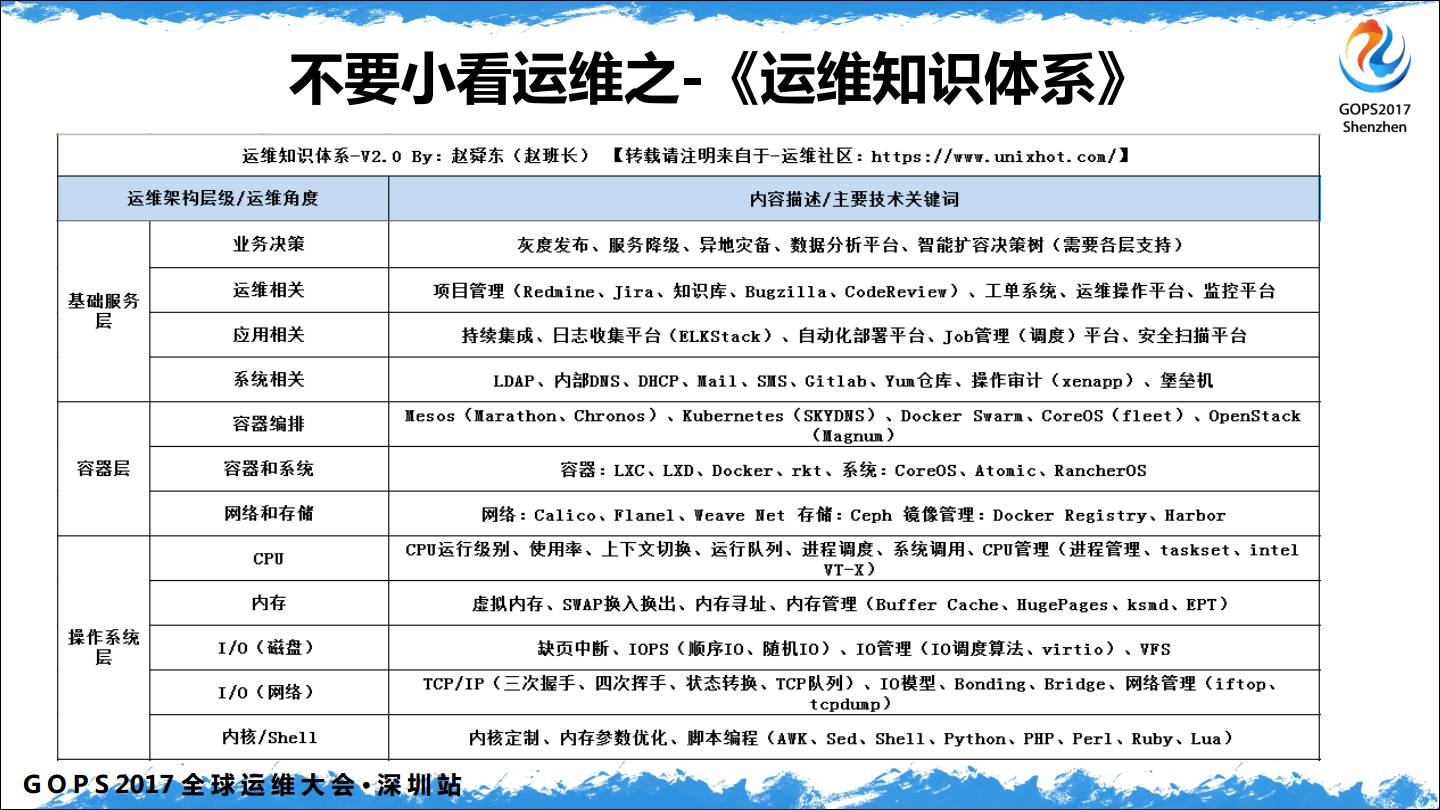
基础服务层,我们在做运维的时候有很多运维工具,自动化部署系统、监控系统都是我们做运维要做的,包括系统相关的如堡垒机这些。
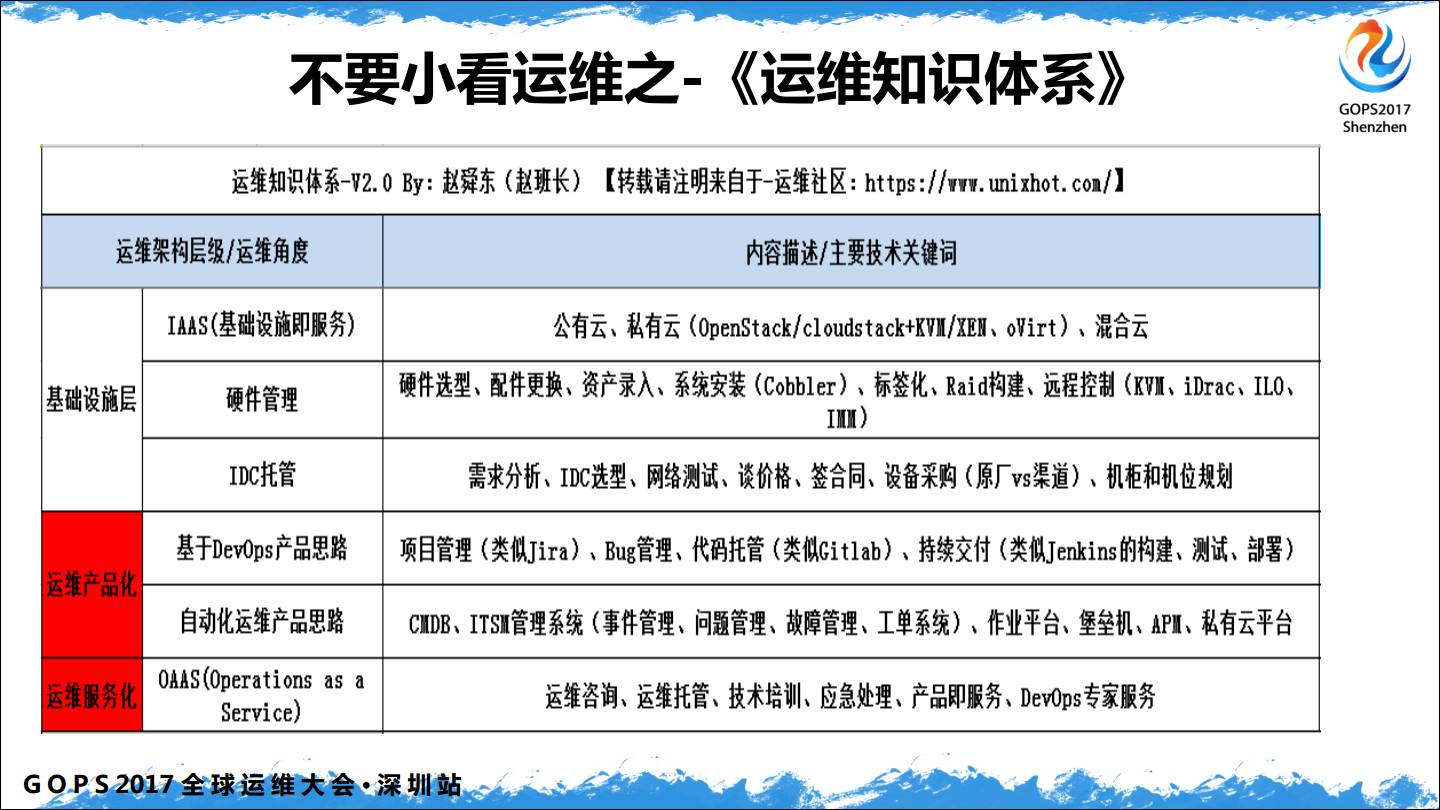
最后面我放了自己对运维产品化和服务化的一些理解。

运维工作内容,这里只是做了一个典型的案例,在你们的公司可能不是这么划分的。不同的层面做的事是不一样。现在做运维其实开始场景化了。例如在招聘的时候,举个例子,我是做 CDN 的,我招人的时候肯定想招一个做 CDN 运维的。
做电商运维的,到另一家做电商的公司,发现薪资各方面都好谈。但是到一家做游戏的就不好谈,之前做电商的经验拿到游戏当中可能就不好使,或者不能发挥最大的价值。因为不同的业务对应不同的运维场景,需要的技术可能会有一些不同的倾向性。
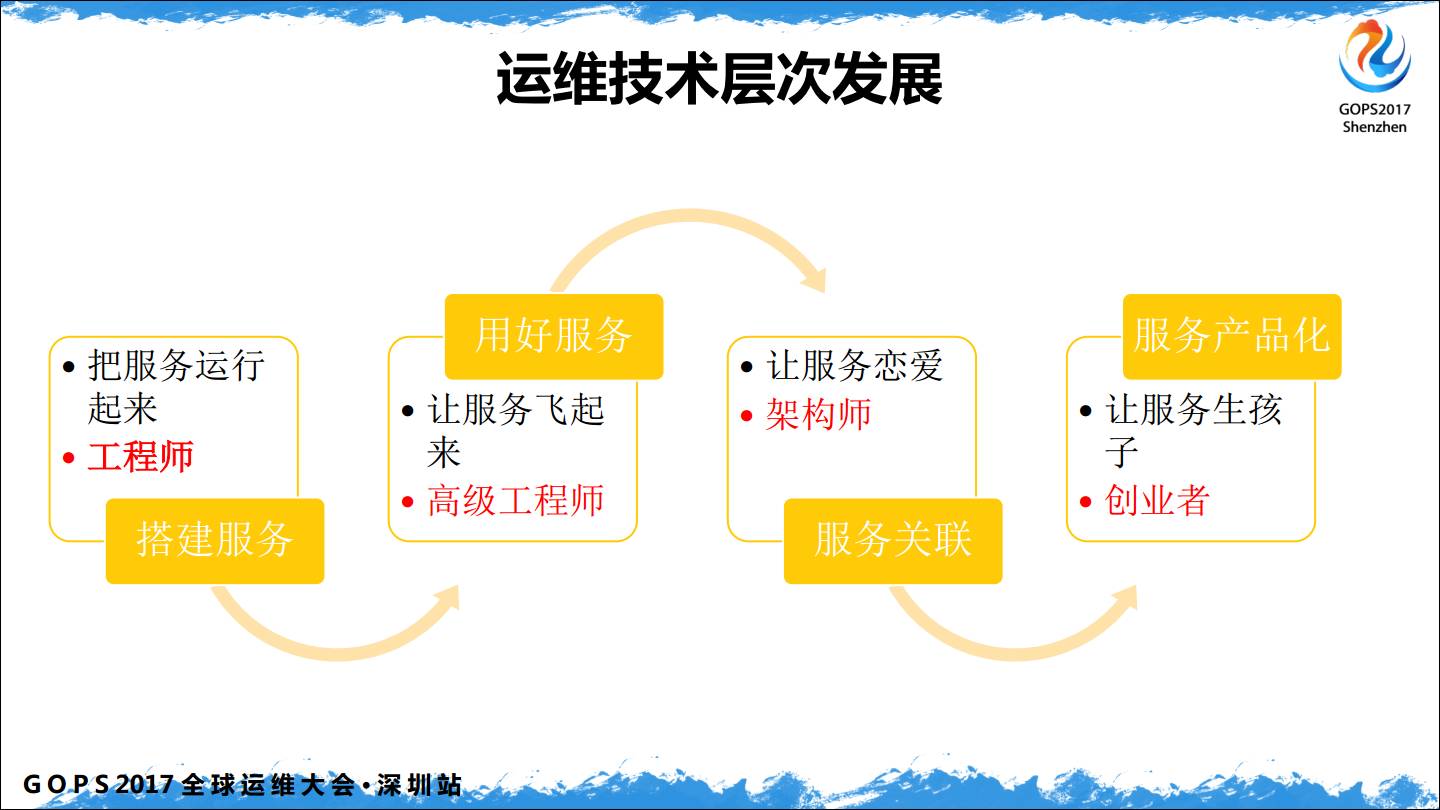
运维的技术层次,我做了一个发展的概述。
第一,搭建服务,这是我们运维最早做的时候,把服务搭建起来了,就会觉得很棒,很有成就感。
第二,如何才能成为一个高级工程师呢,就是用好服务,想要用好服务那就需要深入了解一个服务的底层知识,能够进行对应的性能调优,才能把服务用好。
第三,让服务恋爱,到这个级别我称之为架构师级别,可以让不同的服务根据不同的方式结合起来,完成对应的工作。
第四,让服务生孩子,就是产品化,这次大会咱们外面有很多展商,很多是面向运维的,运维的很多地方如监控、日志、作业平台、CMDB等等都可以做成一个产品来创业。
之前有人问我运维的职业发展,未来怎么样发展,觉得很迷茫。

这里我做了一个选择题,架构师、运维总监、某个领域的技术专家,云解决架构师、业务运维专家,培训讲师、DevOps 专家等等。可以看到未来的方向有很多,可横向(解决方案)、可纵向(某一个领域专家)等。
就像我刚才做的一个运维知识体系是用来让运维人员找准运维的边界,做好运维要掌握的知识很多,但是需要给自己划一个边界,刚才所说的所有关健词,只要掌握一个就可以够研究一辈子了,每一个领域深入下去会走的很深。
3、中小企业基于开源Web的架构演变
中小企业基于开源 Web 的架构演变,这个部分尽量加速略过。因为分享时间有限,我用了很多图来更直观的展示:单机、机群、文件、缓存、数据、异地灾备。
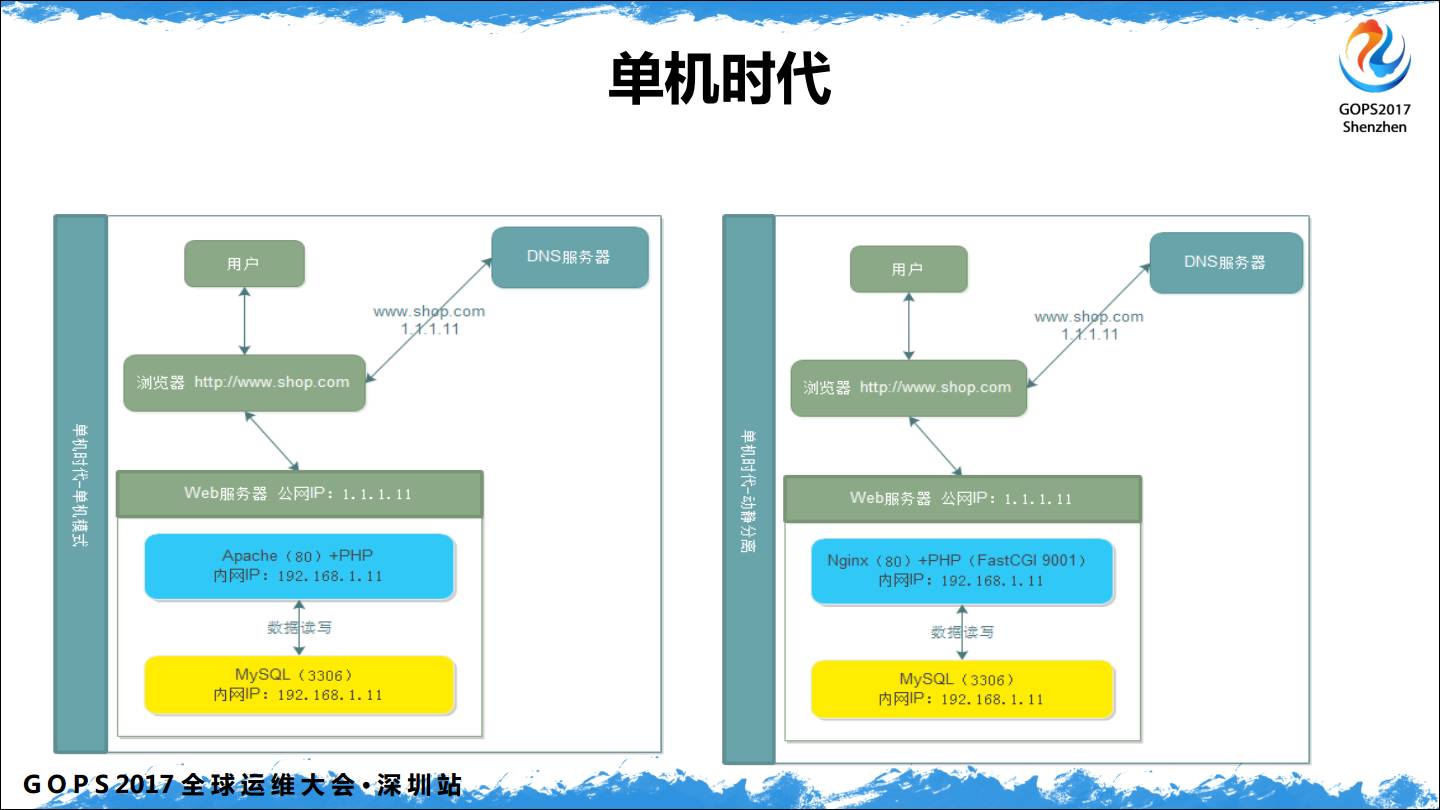
单机时代在Web架构上非常简单,单机时代我们关注的是单机的性能优化,这是很多人忽略的问题。
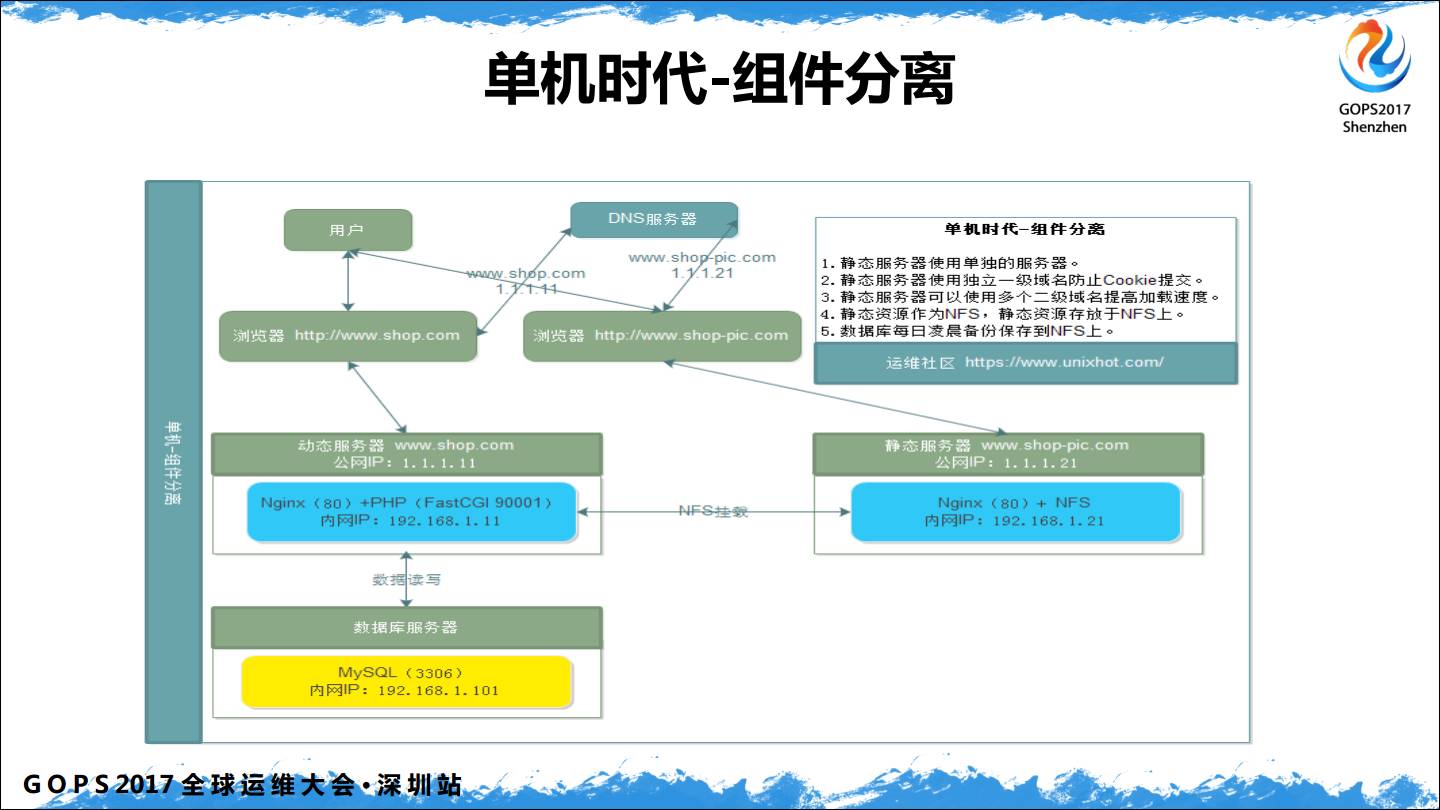
组建分离,我们的图片要使用独立的顶级域名。比如说我之前是做电商的,需要写很多cookie到用户浏览器,如果都在一个顶级下,由于Cookie作用域的关系,别人访问图片的时候浏览器也会发送cookie 到图片服务器,这完全没有必要,可以使用独立的顶级应用来避免Cookie提交。

单机时代主要关注的是Web 性能,咱们做运维的,尤其是想面试高级工程师,现在到公司面试问的全都是基础问题。原因很简单,会基础了,其他的不会没关系,只要基础扎实就可以很快掌握,但是基础知识不会,遇到问题就很难快速定位和解决。

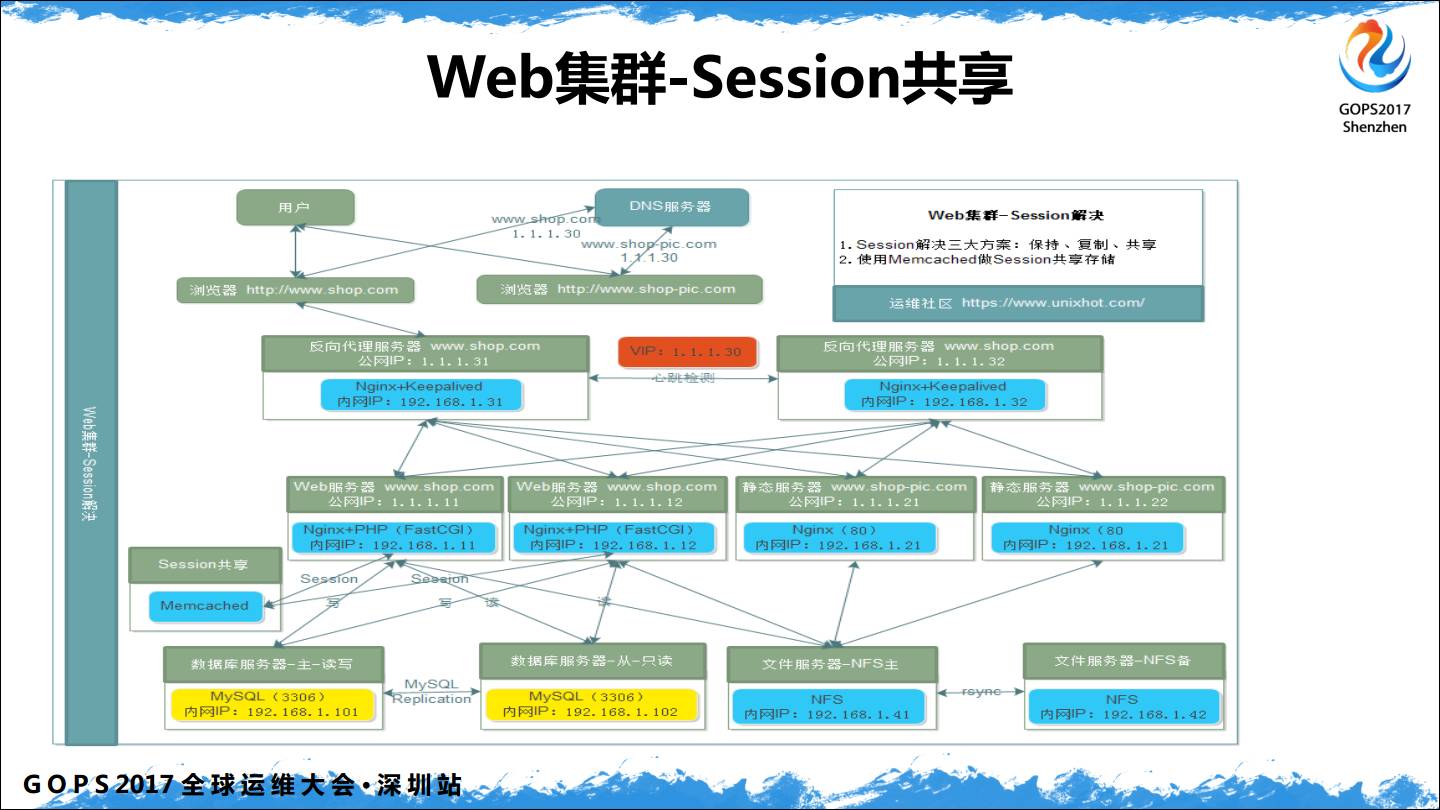
session 的处理方案总结起来有三种:一是会话保持,一个IP进来的可以固定访问到集群中的某一台后端机器上。还有就是 session 复制,基本上不建议使用,曾经6个节点的 Tomcat 集群做 Session 复制就会出现各种问题。最后 session 共享是终极解决方案。
很多人会被文档把思想固化住,要记住别人写的东西未必是正确的,我可以说我今天讲的也未必是正确的,一定要学会分析,然后沉淀成自己的东西。就像网上有一种文档,就是你照着做,一定不会成功。
阿里开源的 Dubbo 是一个成功的开源 SOA 框架,帮助了很多公司,不过现在我司的一些服务正在从 Dubbo 框架迁移到Spring Cloud。这里不讨论孰优孰劣,真的是看具体需求了。

架构再往下发展就涉及到分布式部署,看看腾讯的分享,它们在这方面会做的比较好。
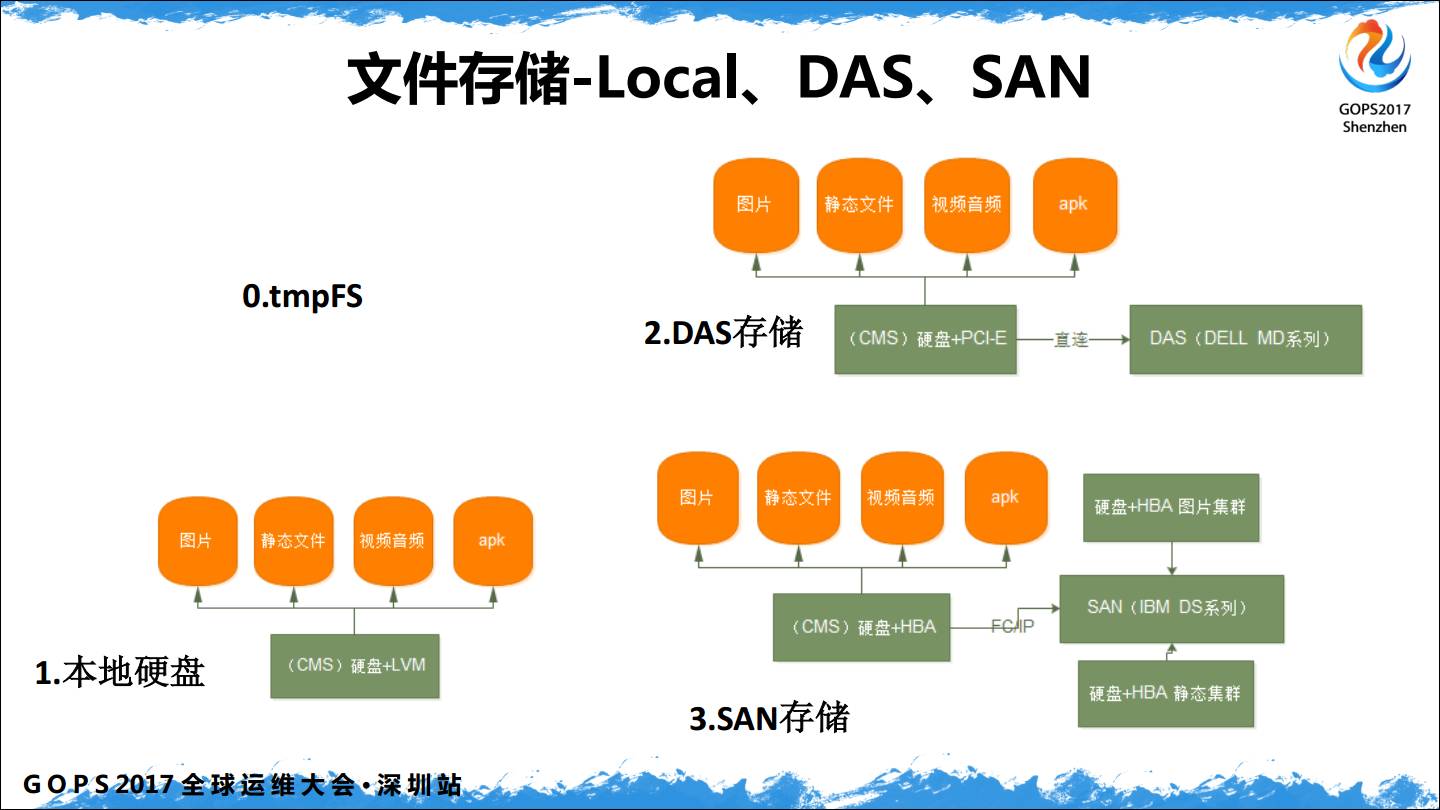
存储层面:0.tmpFS,最早玩 Squid 的时候,直接是挂载一个 tmpfs 文件存储,性能特别的快,因为 tmpfs 是占用系统的共享内存。
1. 本地硬盘
2.DAS 存储
3.SAN 存储都是块存储类型。
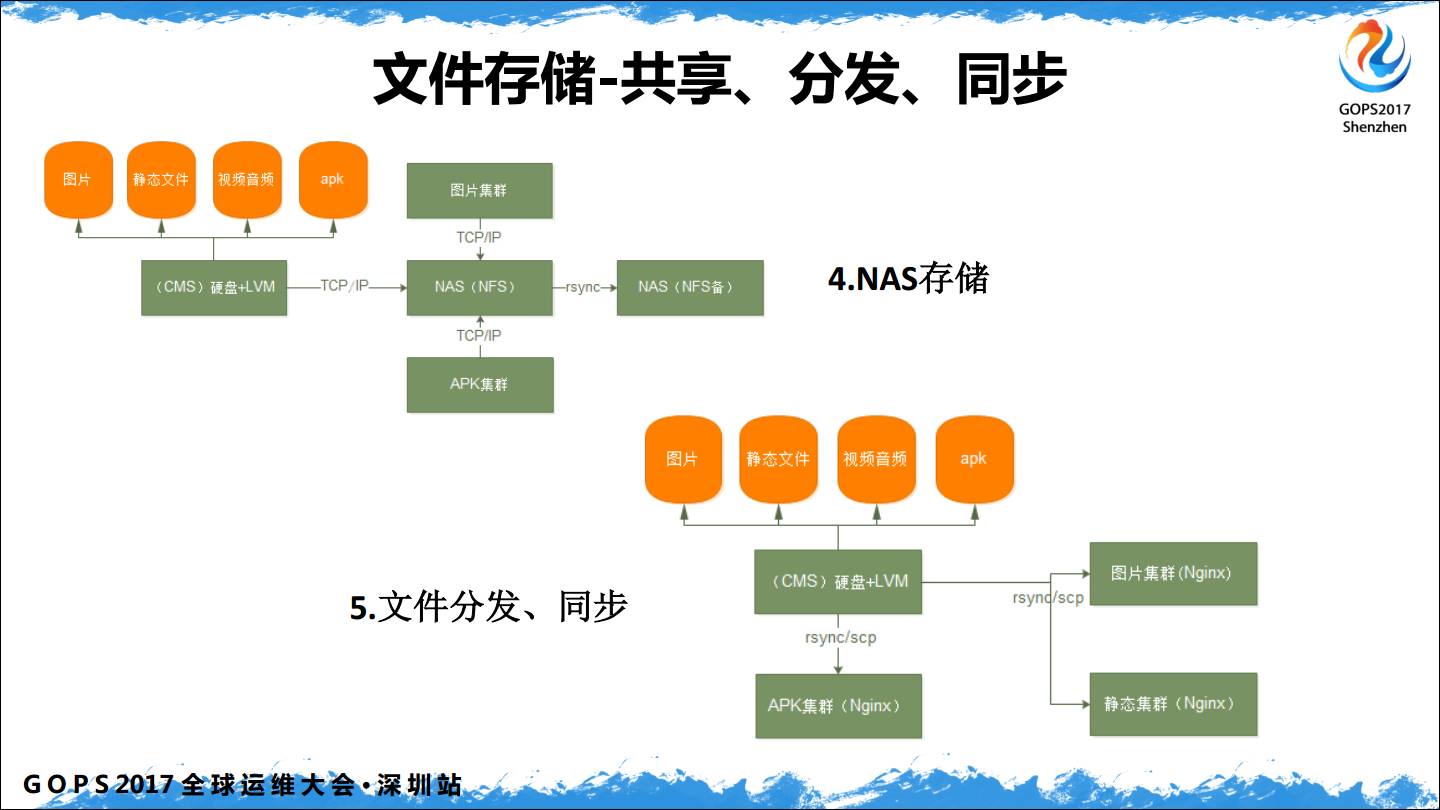
在做Web架构的时候,除了块存储用的最多的就是文件存储。在集群架构中,文件存储可以使用例如 NFS 的共享存储,还可以使用文件的分发和同步。还可以进行多级的分发。
我司是在标准化的原则上,统一用分布式的文件系统 Glusterfs 来做,早期图片是用的MooseFS 。还有一个系统是用FASTDFS,对于做小视频或听书类的服务,每个文件大概是5M-20M左右,用FASTDFS 特别合适。

讲完集群和存储,就到了Web架构中的缓存,我编写了一个《Web 缓存知识体系》,因为我在学习缓存的时候发现所有人的文章都是一个点,想把整个面都串起来的文章找不到,所以就自己把缓存的体系串联起来。我们通常所的缓存,会包括读缓存Cache和写缓冲Buffer。这里只聊读缓存 Cache。
DNS 缓存,浏览器的 DNS 缓存,比如说 firefox 默认缓存60秒,操作系统DNS 缓存,DNS 缓存服务器,应用程序 DNS 缓存。浏览器是分发在千家万户的缓存代理,用好会非常的方便,所以浏览器缓存协商的三种方式是运维必会的,基于最后修改时间、Etag和过期时间。
代理层的缓存,反向代理反存,包括Web缓存,包括 Opcache 缓存。我之前在项目做过一个实验,我们是 PHP5.5,我开了 Opcahe 之后,我们的用户态CPU使用率从70%下降了40%左右。
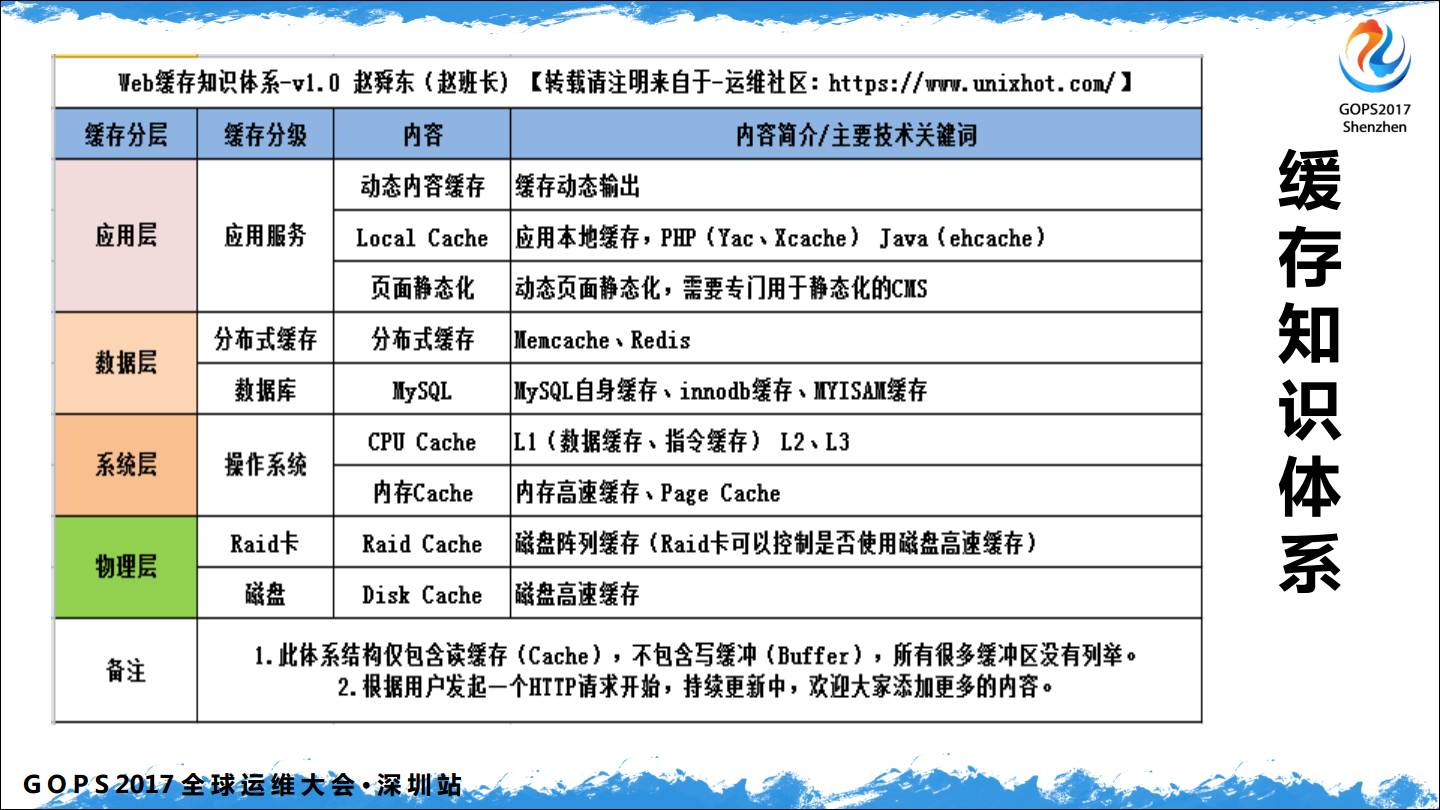
做电商的对页面静态化比较了解,一般我们会有一个CMS系统,从后端服务集群获取到产品详细页、列表页等这些需要静态化的服务,然后将获取到的HTML本地缓存进行对应的修改后,直接使用Nginx发布出去。
聊完缓存在Web架构中,比较重要的就是数据库了
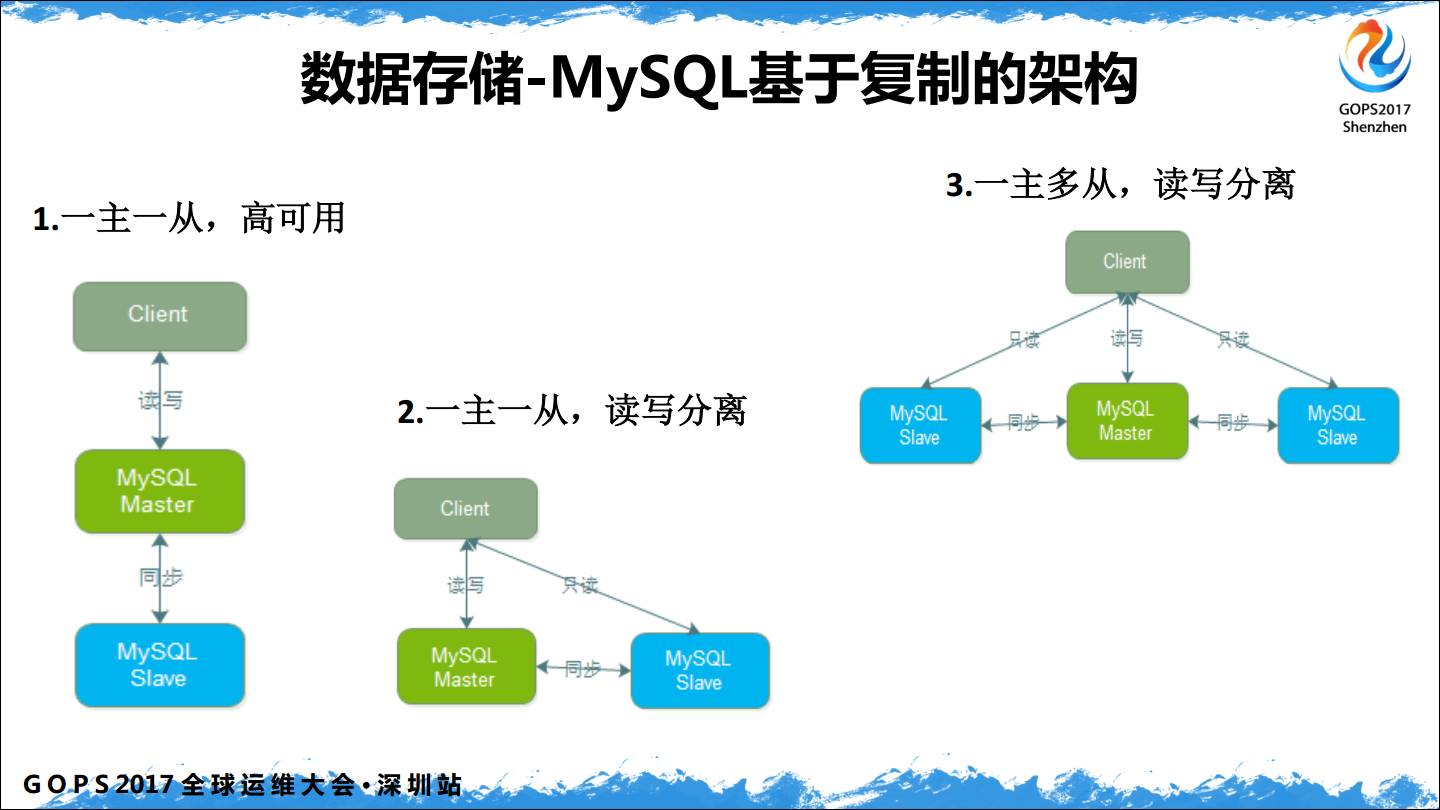
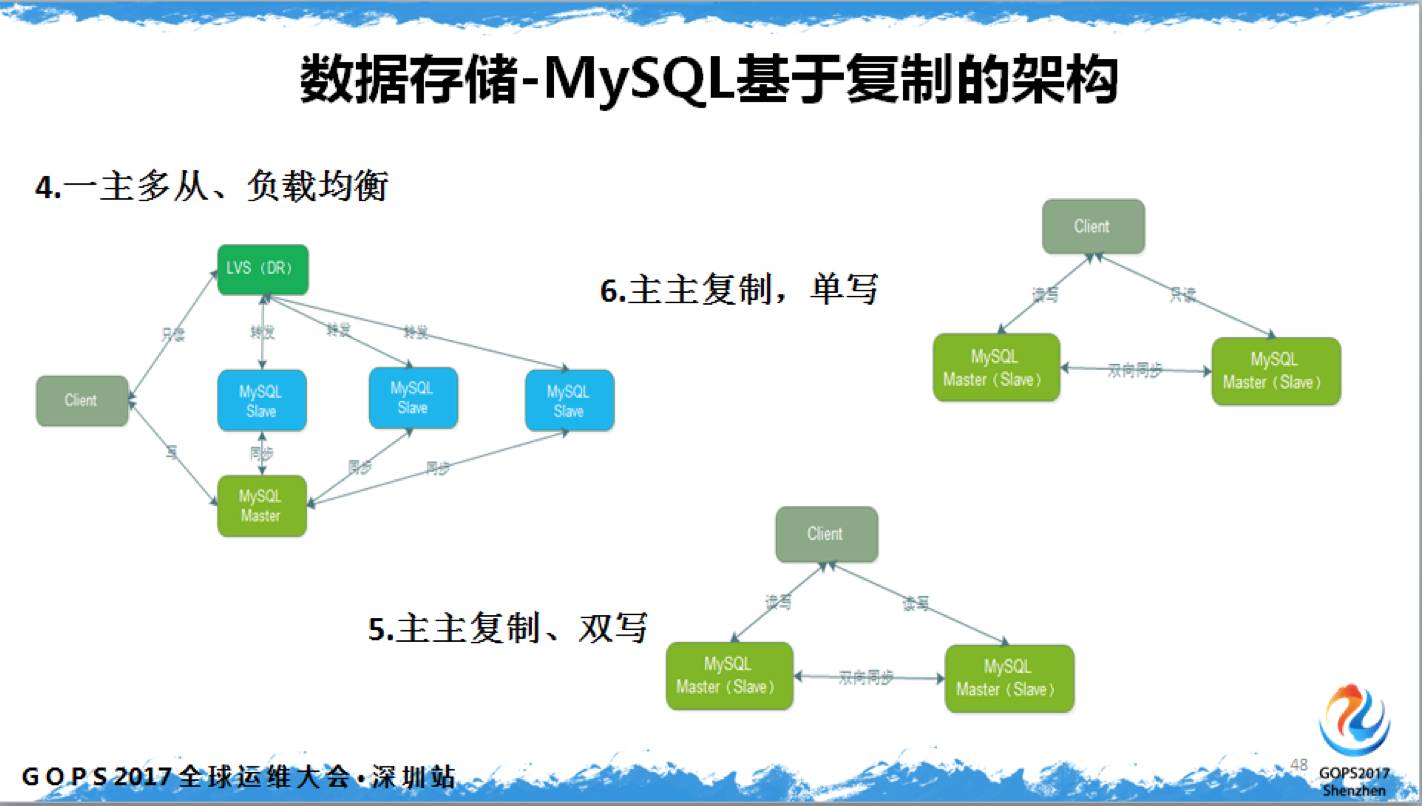
拿MySQL 的主从复制做例,目前我们用的最多的是主主复制,单写,因为双写有很多双写的问题,所以用单写的方式来做。
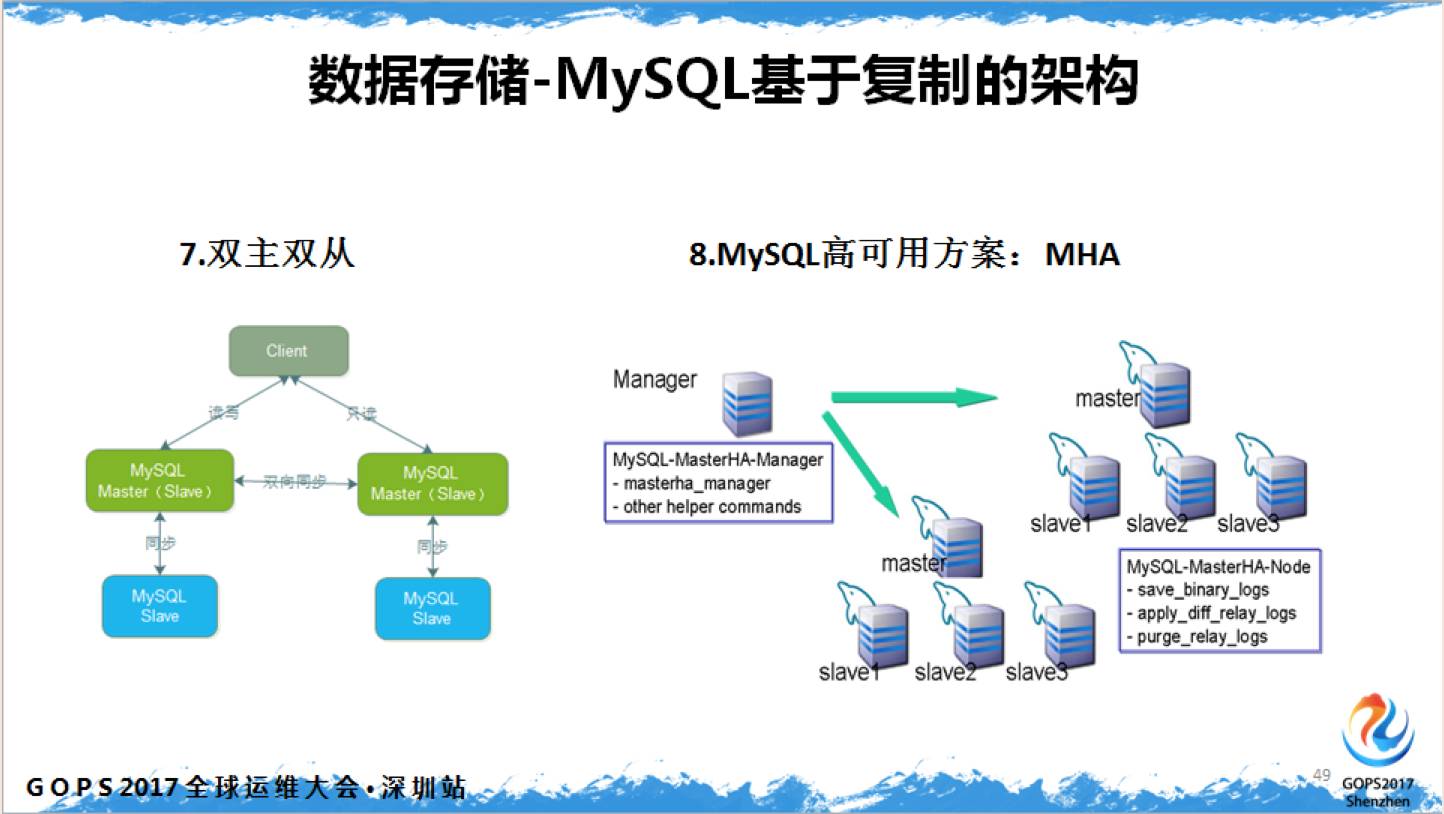
目前使用最多的方案就是 MHA 了,之前使用 MySQL MMM 问题很多。
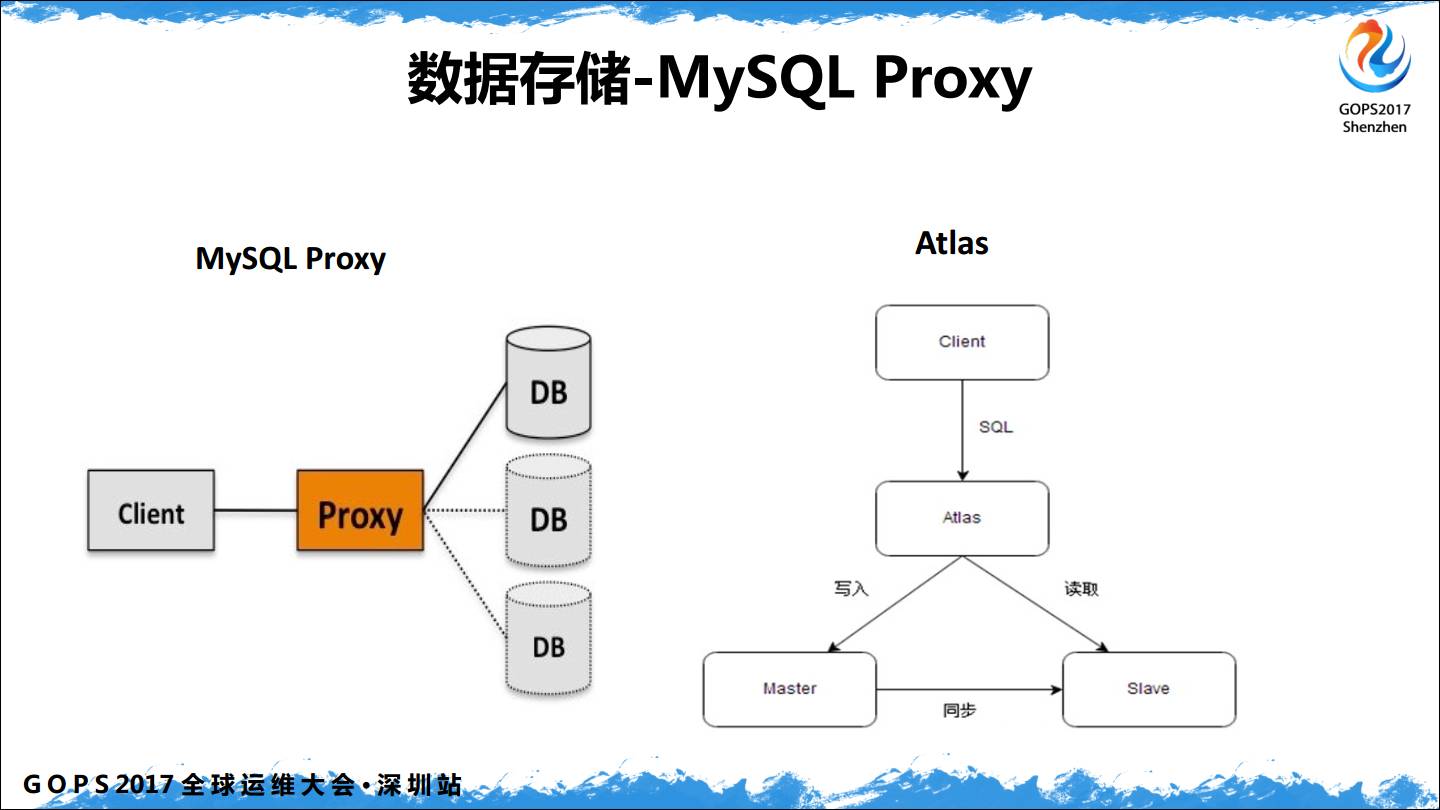
MySQL Proxy 的方案之前试用过 MySQL Proxy 和 Atlas,这个要看具体的需求,我不直接推荐。
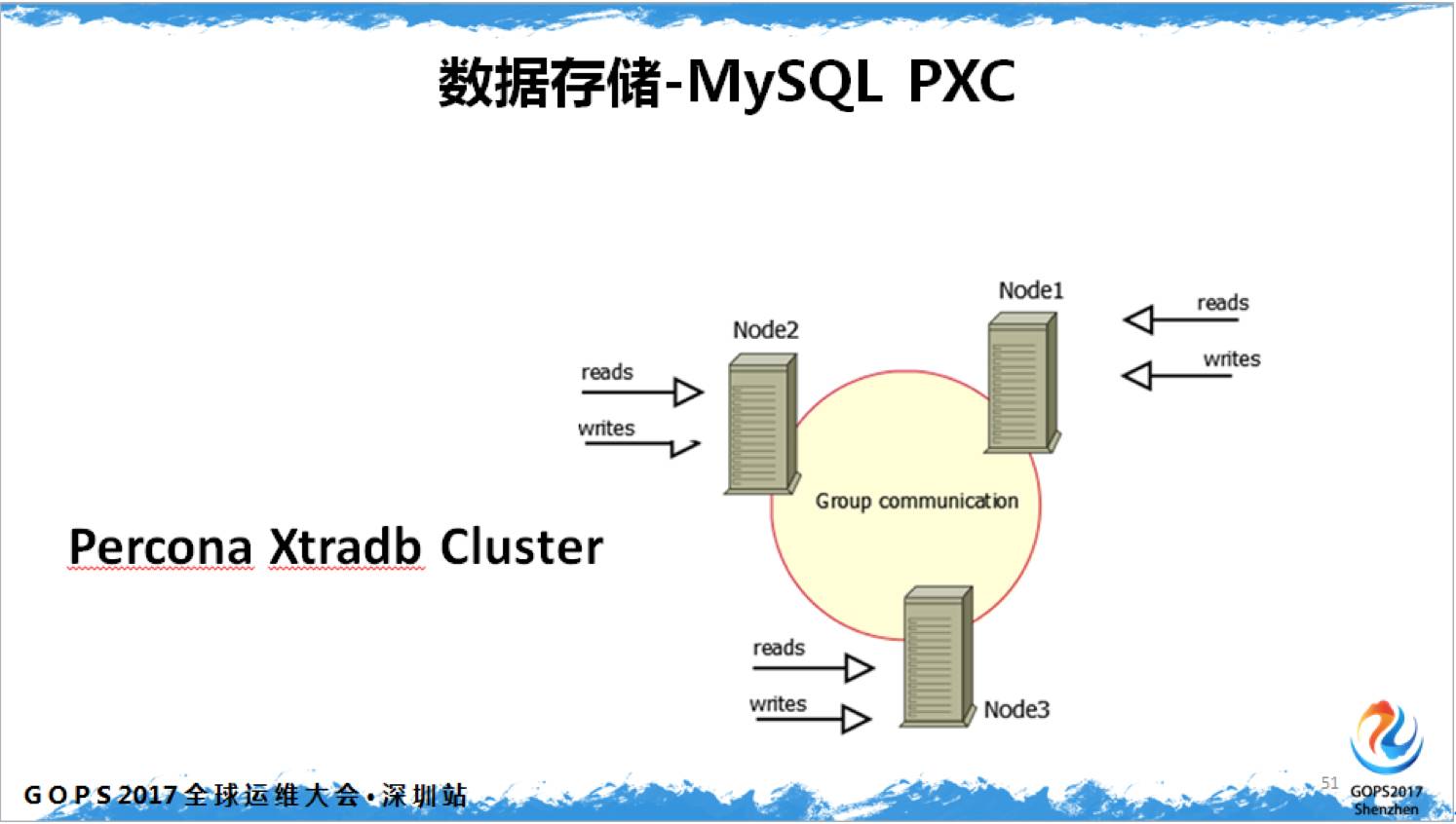
MySQL PXC是我推荐的一个方案,当然和 Atlas 解决的问题不同。
如果从 DAL 层的观点出发,MyCAT 目前应用案例相对比较多一些
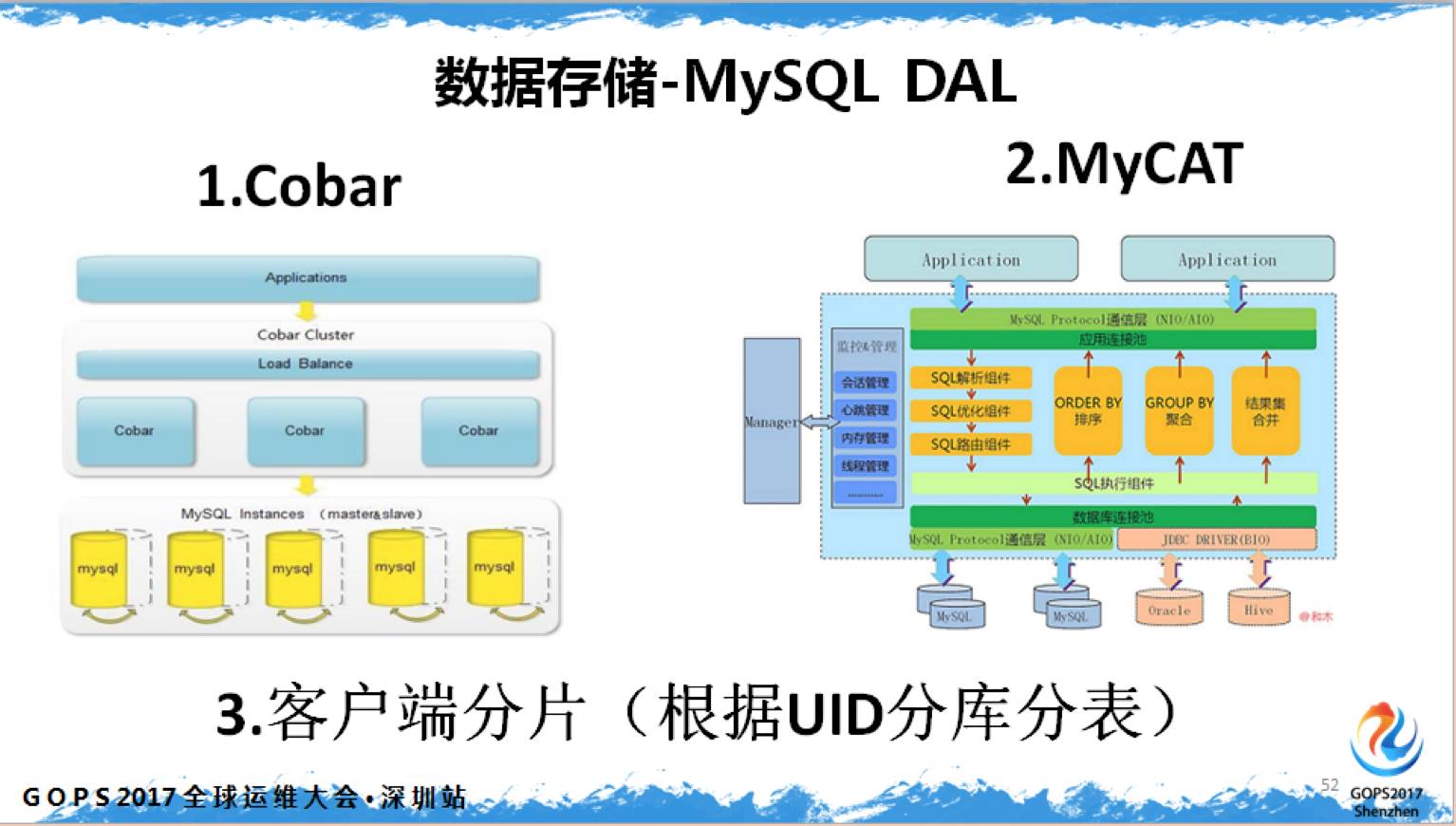
但是真的要把 MyCAT 玩明白需要一个团队,中小企业成本有限,很多使用客户端分片不仅保险,而且成本低。当然运维成本就高了。
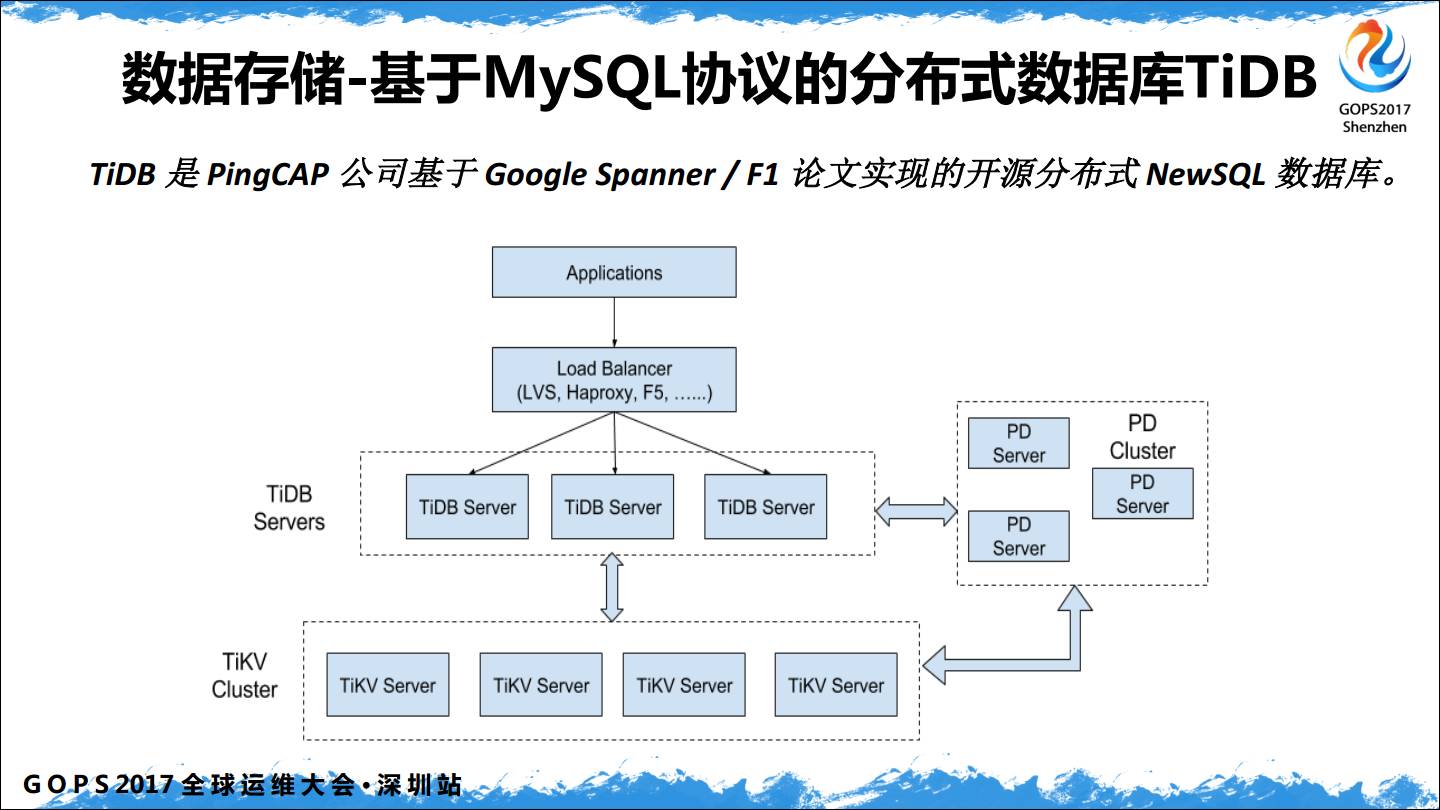
最后推荐一下 Tidb,底层是分布式 KV系统,在 Tidb 这层实现了 MySQL 协议,访问它几乎就像访问 MySQL 一样。
最后聊聊异地灾备:

创业公司倒闭机房着火哪个机率大?很多人会回答是创业公司,但是!说一个真实的案例,天津塘沽事故的时候,我们的服务器在托管在天津塘沽机房,当时我们启动了临时紧急灾备,把数据全部往其它机房都做了备份。
对于很多互联网公司来说,不管公司市值多少个亿,要是机房真的没了,整个公司就没了,一点都不夸张。所以我强烈建议,不要考虑几率,灾备必须做,可以实现低等级的灾备,但是有胜于无。
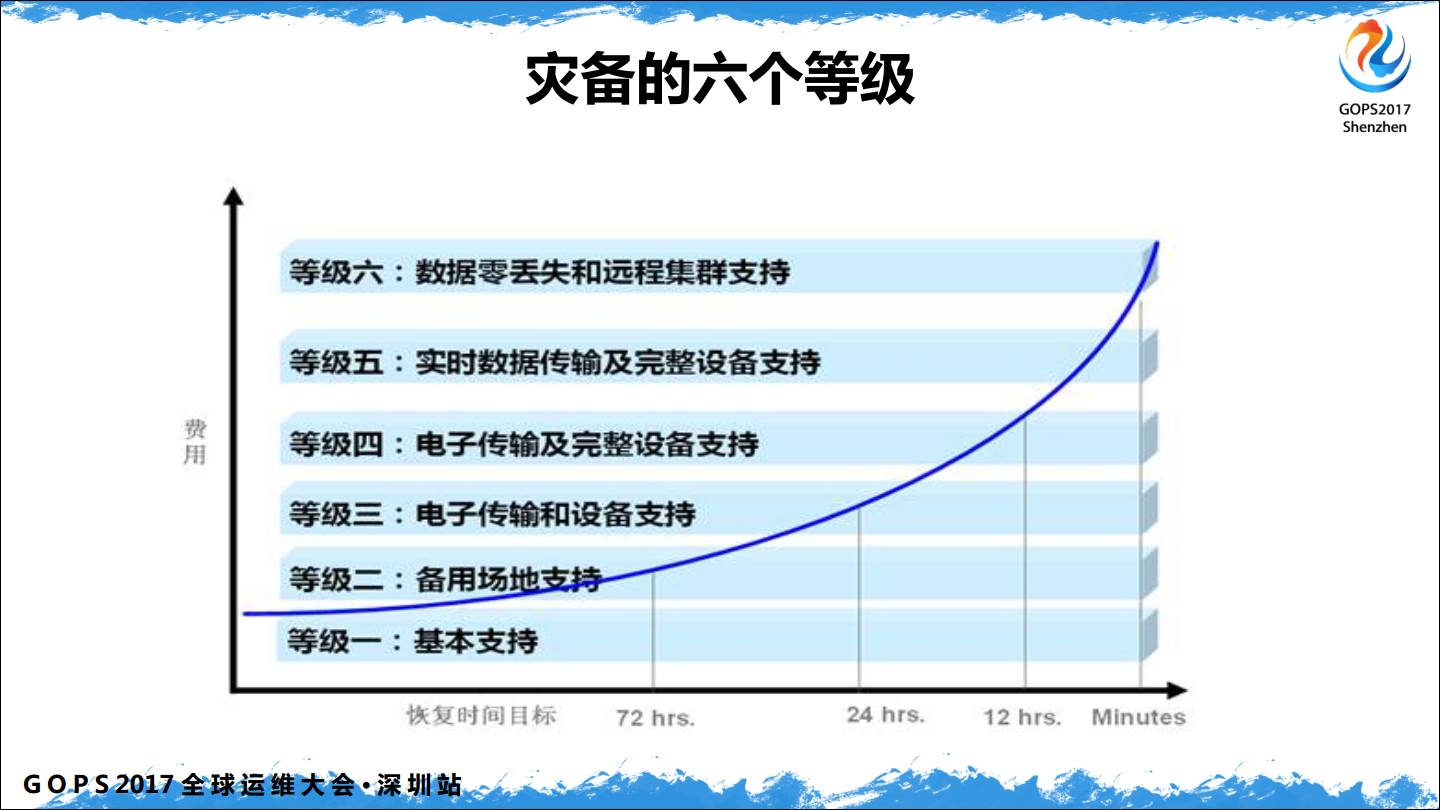
根据灾备国家标准六个等级七个要素,我们做了一个分层、分阶段的建设,先有后完善。

我们当时的原则是先有,后完善,非对称配置。徘徊在”冷备”和”双活”之间,例如在 Nginx 上根据 IP 地址做分流,分一些量到灾备机房,保证备用机房的服务是真正可用的,然后定期做这样的测试。基本上是用了最低的成本做好了运维最后的防线。所以不要说自己是中小企业没钱,没钱有没钱的做法,但是不能不做。
4、自动化运维发展历程
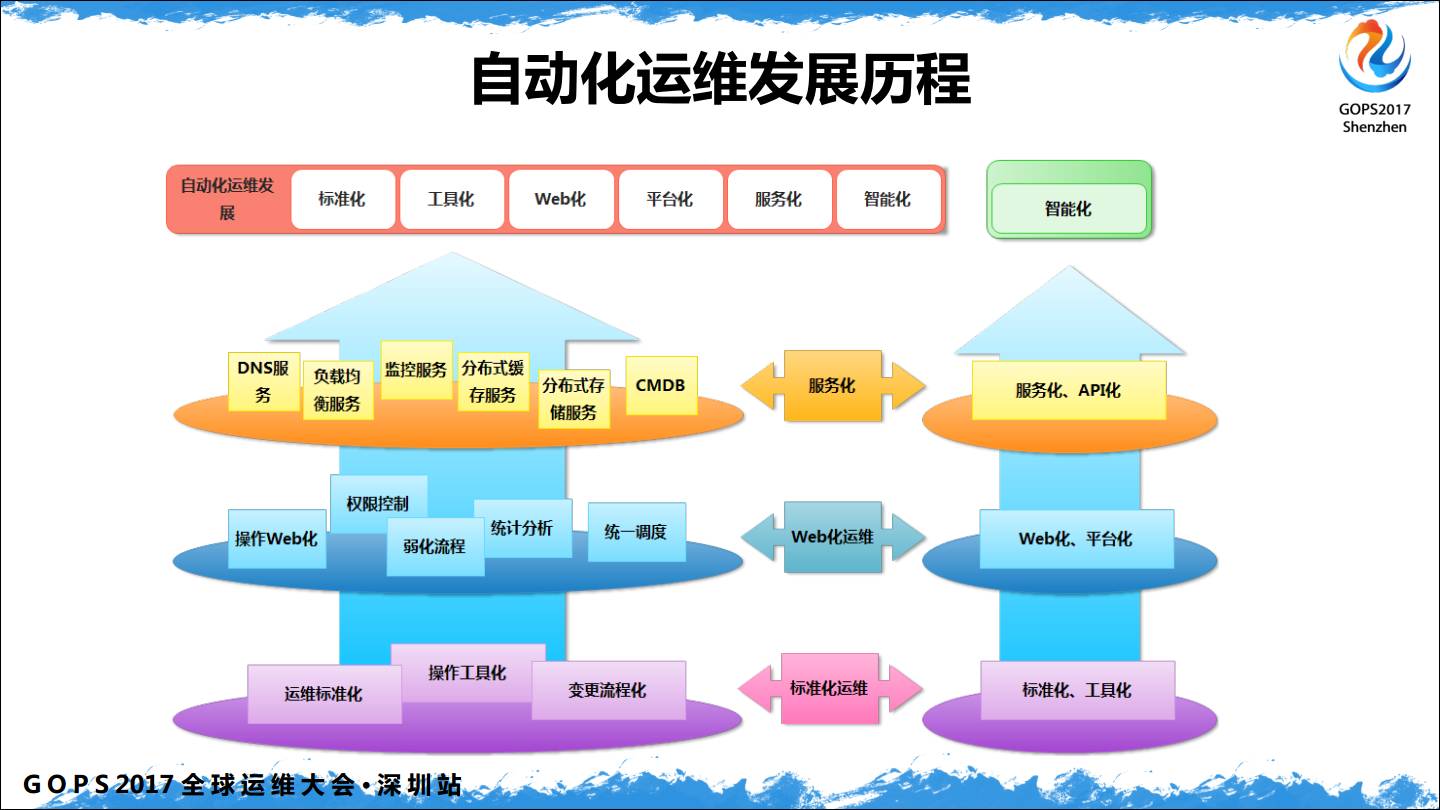
自动化运维发展历程,做自动化运维可能需要需要经历标准化、工具化、Web化、平台化、服务化、智能化。所有不以解决运维痛点的自动化运维都是耍流氓,现在很多公司都在做自动化运维平台。我这里有一个痛点案例:

我们有一个oracle数据库要升级打补丁,涉及到停库,先停备库打补丁,未来再停主库打补丁。需求是查找所有业务系统中03:00-06:00的所有定时任务(我们很多操作数据库的定时任务是crontab管理的),确定哪些定时任务连接需要停机数据库。如果你有上千台服务器,自杀的心都有了。
虽然最后是解决了,但是告诉我们只有标准化、工具化是解决不了问题的,所以要往Web化发展,后来我们做了一个作业平台,把定时作业全部通过作业平台管理起来。想加一个定时任务,提交工单,工单把所有任务记录下来,然后可以做查询。
所以要分析自身情况,找准痛点,不要盲目的做。
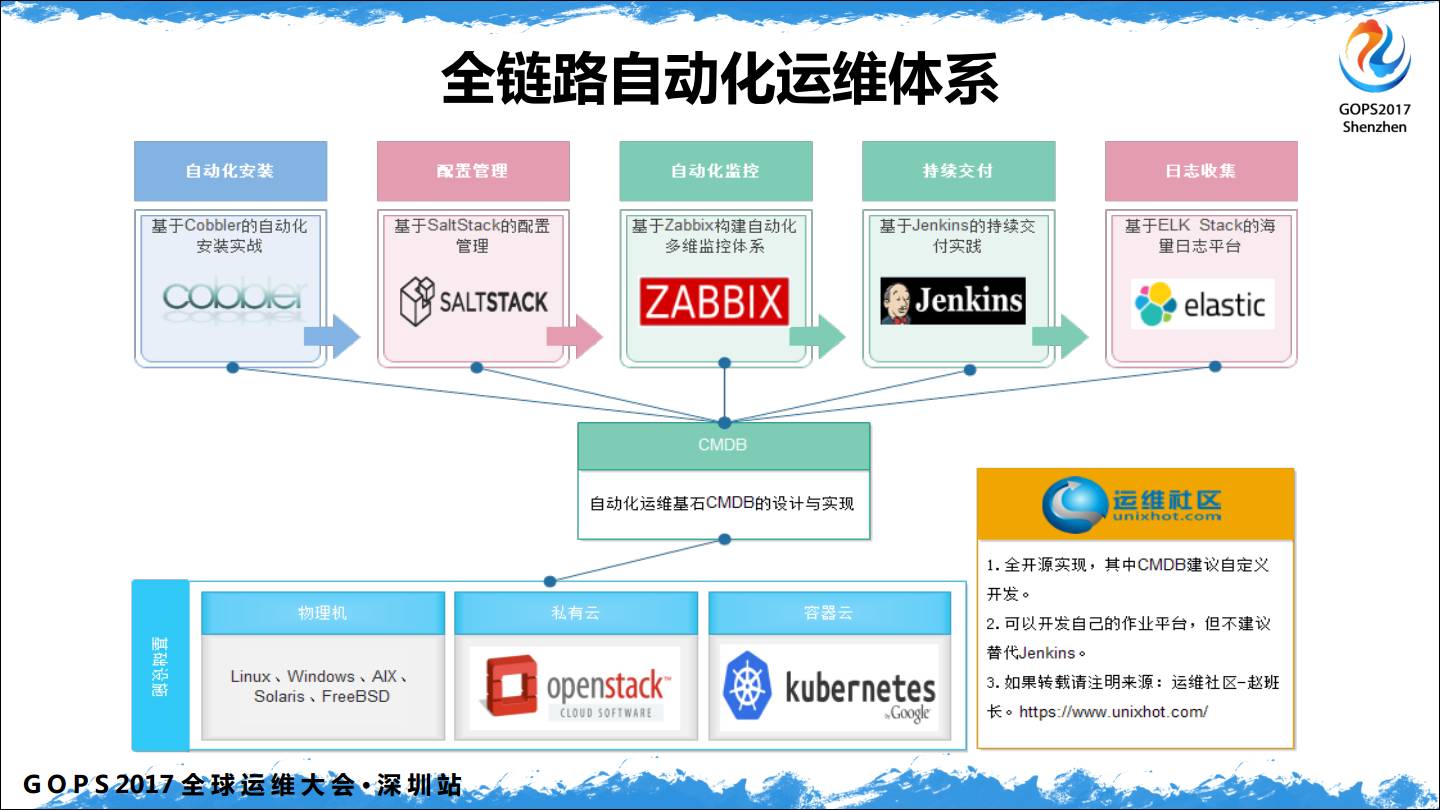
基于开源的全链路自动化运维体系是按照一个项目上线的流程来整理的。从传统的角度来说:
-
自动化系统安装:从自动化安装开始入手,使用Cobbler可以在企业中构建的自动化装机平台和私有Yum仓库;
-
配置管理:系统安装完毕后,然后我们需要在系统上运行服务,进行管理和配置,SaltStack可以帮助我们进行远程执行和配置管理,当然云管理也是SaltStack的非常棒的功能;
-
自动化监控:系统安装完毕后,我们需要做的第一件事情就是监控,可以基于Zabbix构建自动化、分布式、多维度的监控体系;
-
持续交付:应用服务使用SaltStack部署并运行后,我们需要将应用代码部署到集群中,使用Jenkins可以完成持续交付相关的工作。
-
日志收集:代码上线后在业务运行中,会产生不同类型的日志,那么紧接着我们通过ELKStack(Elastic Stack)来构建一个日志收集、存储、和展示平台。
-
基础设施自动化:可以使用OpenStack、Kubernetes来进行基础设施的虚拟化和容器化。
最后所有的数据库放在 CMDB。所以说这是一个全链路的自动化体系。
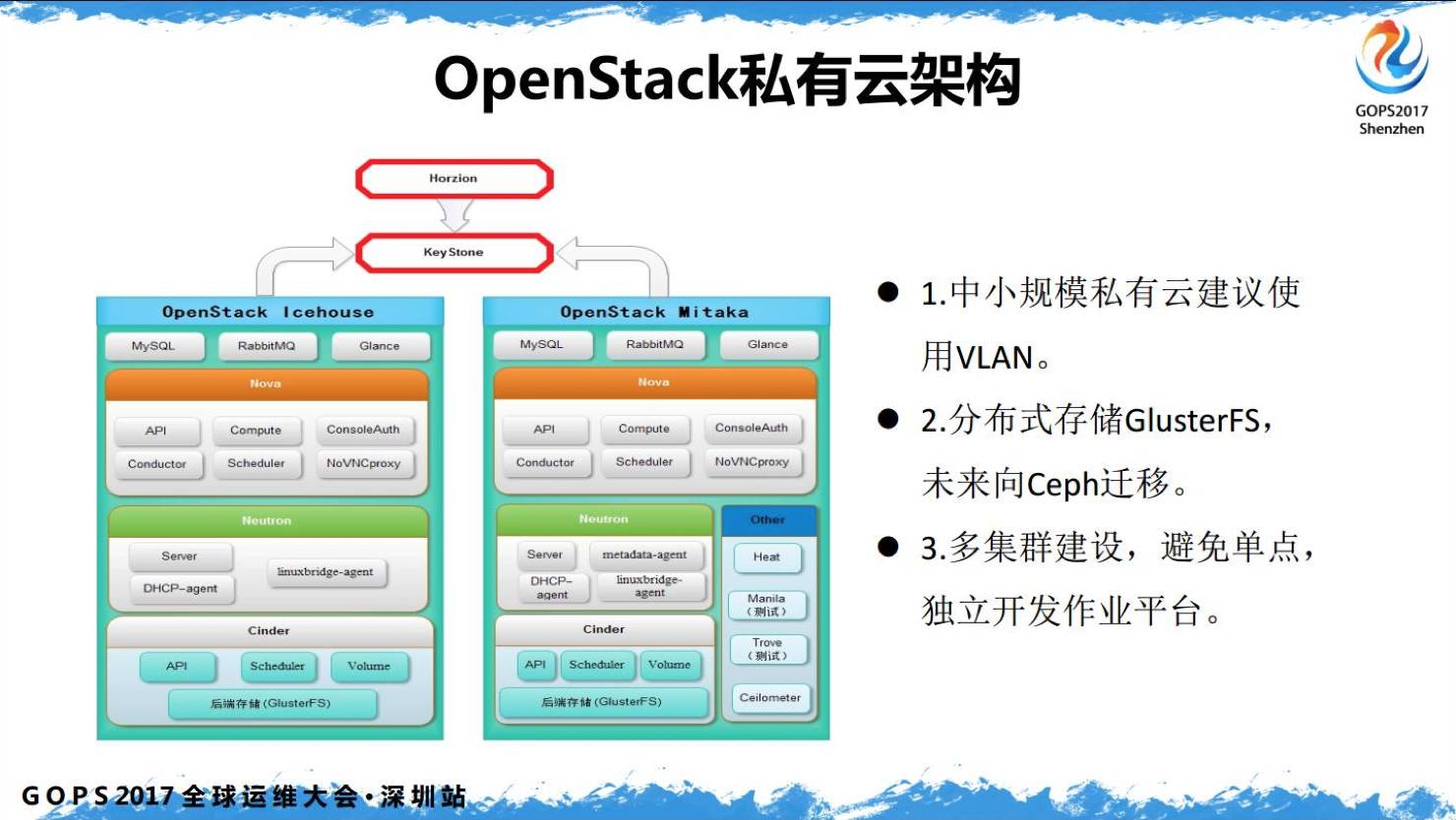
从几个层面介绍一下,一个是 OpenStack,我们两个版本,一个I版,一个M版,做的多区域。

像上图的架构是可以用 SaltStack 进行自动化的配置管理。
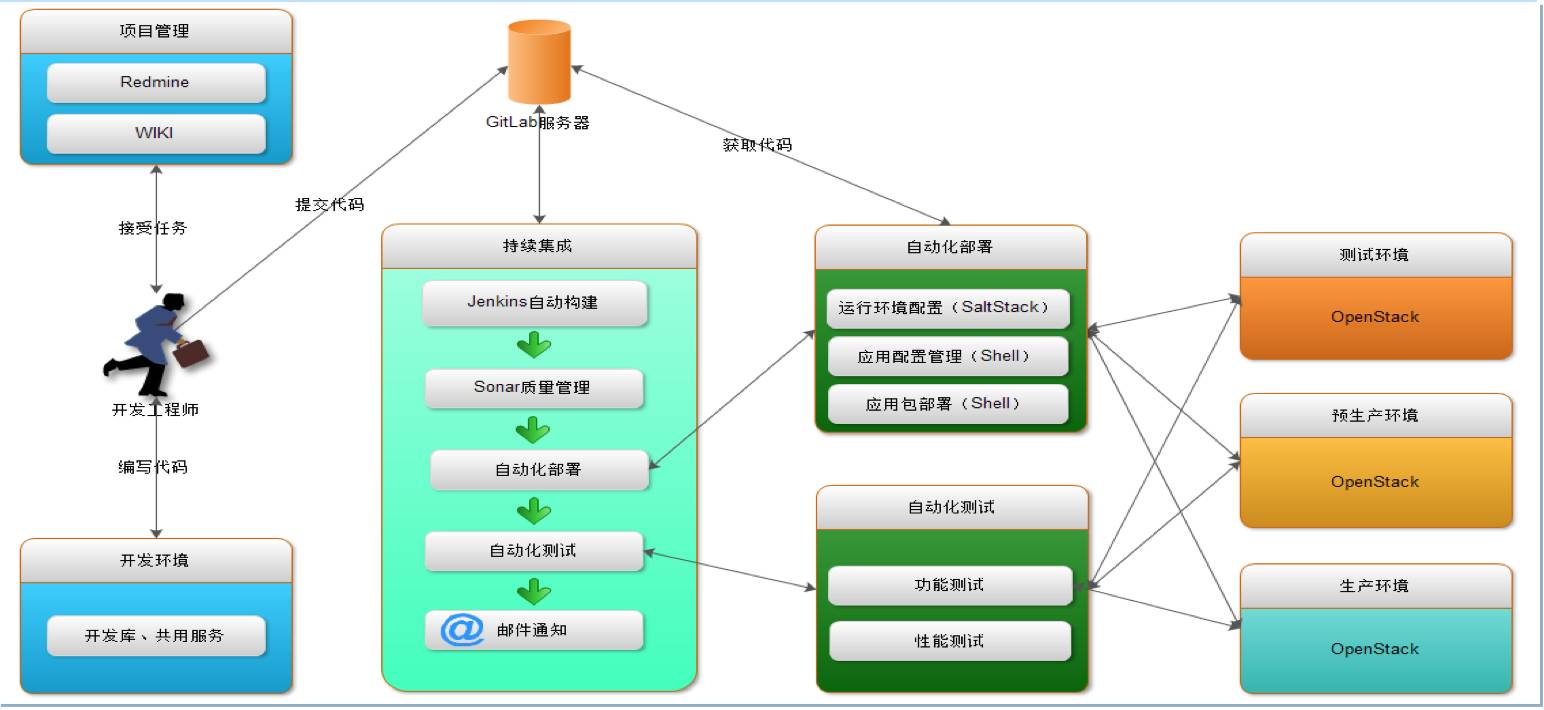
基于Jenkins 的持续交付。做自动运维要做一个体系,要解决全链路的问题,而不是做某一个层面,要把整个方面全考虑到位。
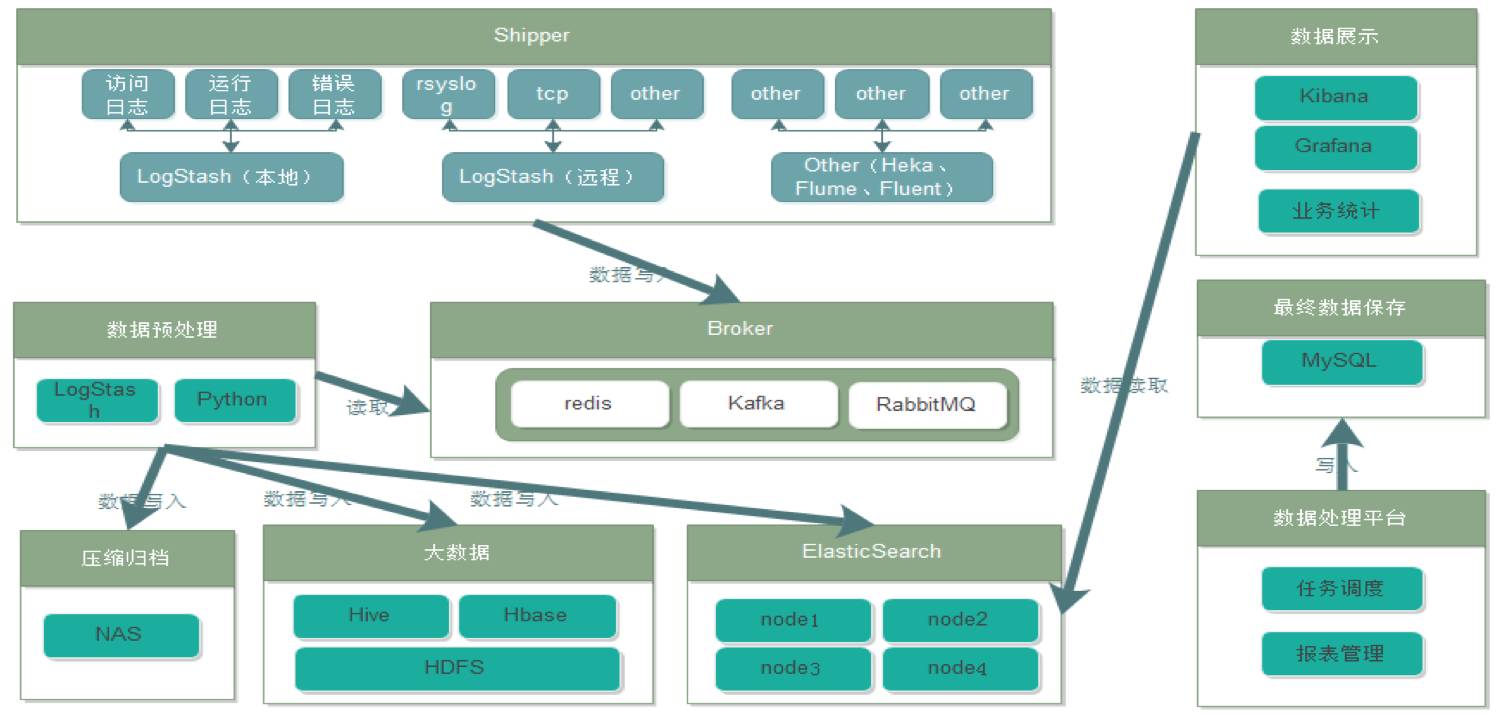
上图是我们基于 ELK 做的日志数据分析平台,我们这个有大数据的部分,会把数据全部写在 Kafka 里面,然后从 Kafka读出来,一部分写在 ES 里面,一部分写在 Hadoop 里面。
然后基于 Hadoop 做数据分析和处理。 ES 主要是用于搜索和运维。这里想强调一点,如果你的业务也用ES的话,你要把运维的 ES 和业务的 ES 分开。
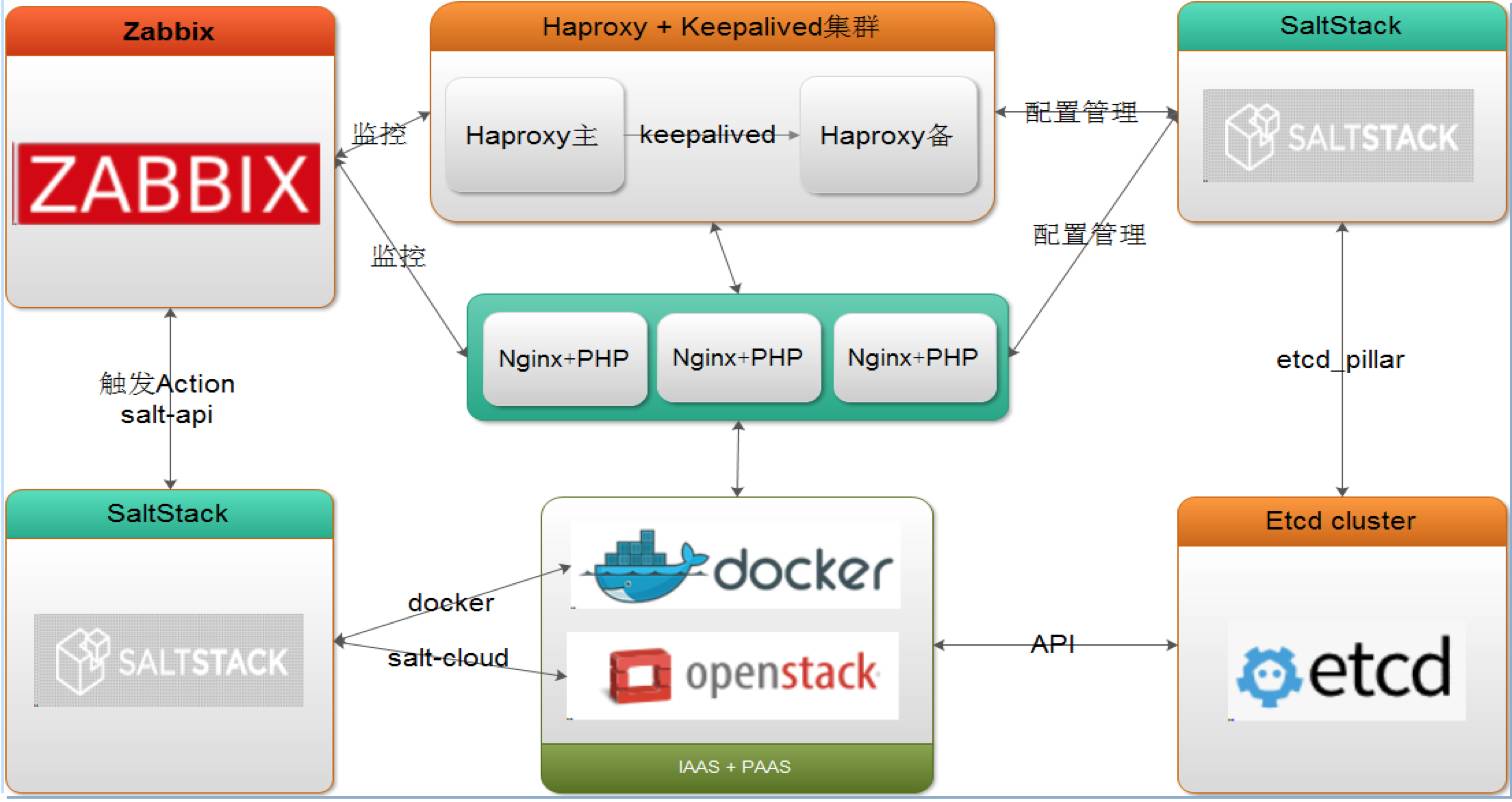
我做了一套基于全开源的智能化扩容的实现。例如 Zabbix 触发扩容,调用 Salt-Cloud 创建 OpenStack 虚拟机,将信息写入到 etcd,然后调用 SaltStack 进行环境部署,调用 Jenkins 进行代码部署,调用自动化测试进行测试。
最后 SaltStack 管理 Haproxy 的配置文件,进行自动重载,完成扩容工作。当然这只是一个简图,有 CMDB 的话,可以直接替换掉 etcd。
5、未来展望
下一步怎么走?刚才讲的做运维是标准化、工具化、平台化、服务化、智能化,下一步是产品化,对于一些运维老司机,在运维行业深耕多年,找准机会就可以创业去了。
技术成就梦想,最后,希望所有运维人都能够持续学习,不断成长,事实证明,运维不仅仅可以背黑锅,还可以站在舞台的正中央。我为自己是一个运维人而自豪!