《Linux内核设计与实现》Chapter 18 读书笔记
一、准备开始
- 一个bug
- 一个藏匿bug的内核版本
- 知道这个bug最早出现在哪个内核版本中。
- 相关内核代码的知识和运气
想要成功进行调试:
- 让这些错误重现
- 抽象出问题
- 从代码中搜索
二、内核中的bug
1.内核bug的表象:
错误代码
同步时发生的错误,例如共享变量锁定不当
错误的管理硬件
降低所有程序的运行性能
毁坏数据
使得系统处于死锁状态
……
- 引用空指针会产生一个oops;垃圾数据会导致系统崩溃。
三、通过打印来调试
内核提供打印函数printk(),他是内核的格式化打印函数,它还有自己的一些特殊的功能:
1.健壮性
健壮性即在任何时候,任何地方都能调用它。
在中断上下文和进程上下文中被调用在任何持有锁时被调用在多处理器上同时被调用,并且不必使用锁。
printk()有用之处在于它随时都能被调用。
注意:该函数在终端没有初始化之前,某些地方不能用它。这种情况,需要用early_printk()代替,它在启动初期就可以在终端上打印,两者功能完全相同,但early_printk()缺少可移植性。
2.日志等级
printk()和printf()在使用上最主要的区别就是前者可以指定一个日志级别,内核根据这个级别来判断是否在终端上打印消息。内核把级别比某个特定值低的所有消息显示在终端上。
下表列举了所有可用的记录等级。
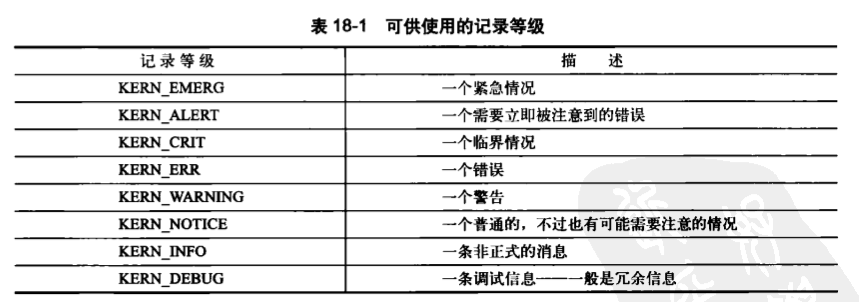
如果没有特别特别指定记录等级,函数会选用默认的DEFAULT_MESSAGE_LOGLEVEL,当前默认等级是KERN_WARNING,但它存在着变化的可能性。、,最好还是给自己的消息指定一个记录等级。
内核将最重要的等级KERN_EMERG定为"<0>",将最无关紧要的等级KERN_DEBUG定为"<7>",从0-7,对应表中从上到下
3.记录缓冲区
内核消息是被保存在一个LOG_BUF_LEN大小的环形队列中,该缓冲区的大小是可以在编译时设置CONFIG_LOG_BUF_SHIFT进行调整,但是在单处理器的系统上默认值是16kb。就是内核在同一时间只能保存16kb的内核消息,否则新消息就会覆盖老消息。该缓冲区之所以称为环形,因为读写都是按照环形队列方式操作的。
(1)环形队列的优点:
- 读写同步问题容易解决记录
- 记录的维护更加方便
(2)缺点:
- 可能会丢失消息
4.syslogd和klogd
用户空间的守护进程klogd从记录缓冲区中获取内核消息,再通过syslogd守护进程将他们保存在系统日志文件中。
(1)klogd
- 既可以从/proc/kmsg文件中,也可以通过syslog()系统调用读取这些消息。默认选择读取/proc方式实现。
- 两种方法klogd都会阻塞,直到有新的内核消息可供读出,唤醒之后将消息传给syslogd。
- 启动时,可以通过-c标志来改变终端的记录等级。
(2)syslogd
- 将它接收到的所有消息添加到一个文件中,该文件默认是/var/log/messages。
- 也可以通过/etc/syslog.conf配置文件重新指定。
5.从printf()到printk()的转换
四、oops
oops是内核告知用户有不幸发生的最常用的方式。
1.发布oops的过程:
向终端上输出错误消息 输出寄存器中保存的信息 输出可供跟踪的回溯线索
通常发送完oops之后,内核会处于一种不稳定状态。
2.关于oops发生的时机:
- 发生在中断上下文:内核根本无法继续,会陷入混乱,结果导致系统死机
- 发生在idle进程(pid为0)或init进程(pid为1),系统也会陷入混乱
- 发生在其他进程运行时,内核会杀死该进程并尝试着继续执行
3.oops发生的可能原因:
- 内存访问越界
- 非法的指令
- ……
4.ksymoops
将回溯线索中的地址转化成符号名称,调用ksymoops命令并提供System.map。
调用方法:
-
ksymoops saved_oops.txt
5.kallsyms
现在的版本中不需要使用kysmoops这个工具,因为可能会发生很多问题,新版本中引入了kallsyms特性:
- CONFIG_KALLSYMS 定义配置选项启用。
- CONFIG_KALLSYMS_ALL 存放函数名称;存放所有符号名称。
- CONFIG_KALLSYMS_EXTRA_PASS 引起内核构建中再次忽略内核的目标代码。
五、内核调试配置选项
1.配置选项
为了方便调试和测试内核代码,内核提供了许多配置选项。它们都在内核配置编辑器的内核开发菜单项中,都依赖于CONFIG_DEBUG_KERNEL。
- slab layer debugging slab层调试选项
- high-memory debugging 高端内存调试选项
- I/O mapping debugging I/O映射调试选项
- spin-lock debugging 自旋锁调试选项
- stack-overflow debugging 栈溢出检查选项
- sleep-inside-spinlock checking 自旋锁内睡眠选项
2.原子操作
指那些能够不分隔执行的东西;在执行时不能中断否则就是完不成的代码。
六、引发bug并打印信息
1.最常用的内核调用:BUG()和BUG_ON()
被调用时会引发oops,导致栈的回溯和错误信息的打印。
大部分体系结构把它们定义成某种非法操作,可以把这些调用当做断言使用,想要断言某种情况不该发生:
if (bad_thing) BUG(); 或以更好的形状: BUG_ON(bad_thing);
多数开发者认为BUG_ON()比BUG()更清晰、更可读。
2.BUILD_BUG_ON()
与BUG_ON()作用相同,仅在编译时调用。
3.panic()
可以用其引发更严重的错误,它不但会打印错误信息,还会挂起整个系统,所以,只应该在最糟糕的情况下使用它。
4.dump_stack()
只在终端上打印寄存器上下文和函数的跟踪线索。
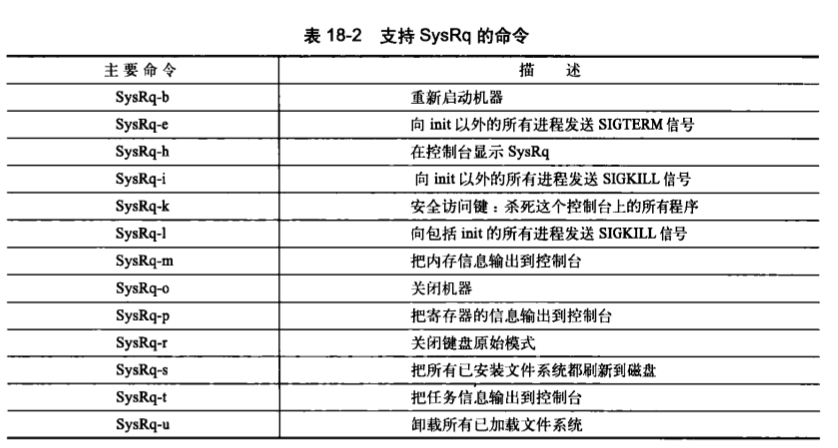
七、神奇的系统请求键
神奇的系统请求键(Magic SysRq key)这个功能可以通过定义CONFIG_MAGIC_SYSRQ配置选项来启用。SysRq(系统请求)键在大多数键盘上都是标准键。该功能被启用时,无论内核出于什么状态,都可以通过特殊的组合键和内核进行通信。
1.启动命令
echo 1 > /proc/sys/kernel/sysrq
八、内核调试器的传奇
1.gdb
(1)针对内核启动调试器的方法和对进程的方法大致相同
gdb vmlinux /proc/kcore /*vmlinux文件是未压缩的内核映像; /proc/kcore是一个参数选项,作为core文件来用,只有超级用户才能读取此文件的数据。 */
(2)打印一个变量的值
p global_variable
(3)反汇编一个函数
disassemble function
(4)局限性
- 不能修改内核数据;
- 不能单步执行内核代码;
- 不能加断点
2.kgdb
是一个补丁,可在远端主机上通过串口利用gdb的所有功能对内核进行调试。
九、探测系统
1.使用uid作为选择条件
一般,只要保留原有的算法而把新算法加入到其他位置上,基本就能保证安全。可以把用户id(UID)作为选择条件来实现这种功能,通过某种选择条件,安排到底执行哪种算法。
if (current-> uid !=7777) { /* 老算法…… */ } else { /* 新算法…… */ }
除了uid=7777的用户以外,其他所有的用户都是用的老算法,所以这个7777用户可以专门用来测试新算法。
2.使用条件变量
如果代码与进程无关,或者希望有一个针对所有情况都能使用的机制来控制某个特性,可以使用条件变量。
(1)方法
创建一个全局变量作为一个条件选择开关:
- 如果该变量为0,就使用某一个分支上的代码;
- 否则,选择另外一个分支。
3.使用统计量
需要掌握某个特定事件的发生规律的时候,通过创建统计量,并提供某种机制访问其统计结果。
注意:这种实现不是SMP安全的
4.重复频率限制
当系统的调试信息过多的时候,可以采取:
(1)重复频率限制
(2)发生次数限制
十、用二分查找法找出引发罪恶的变更
十一、使用Git进行二分搜索
$ git bisect start ;进行二分搜索 $ git bisect bad <revision> ;引发提供一个出现问题的最高内核版本 $ git bisect bad ;若当前内核版本就是bug的元凶,那不必提供内核版本 $ git bisect good v2.6.28 ;最新可正常运行的内核版本 $ git bisect good ;这个版本正常 $ git bisect bad ;这个版本有异常
十二、当所有努力都失败时:社区
- Linux内核邮件列表(LKML)