https://blog.csdn.net/qtlyx/article/details/50780400

最后的效果就是这样的。很明显可以看到,左下角那个有点像三角函数的关系,Pearson系数(就是线性相关系数)为0,而MIC则有0.8。
摘自:http://tech.ifeng.com/a/20180323/44917506_0.shtml
最大信息系数
最大信息系数(MIC)于 2011 年提出,它是用于检测变量之间非线性相关性的最新方法。用于进行 MIC 计算的算法将信息论和概率的概念应用于连续型数据。
深入细节
由克劳德·香农于 20 世纪中叶开创的信息论是数学中一个引人注目的领域。
信息论中的一个关键概念是熵——这是一个衡量给定概率分布的不确定性的度量。概率分布描述了与特定事件相关的一系列给定结果的概率。

概率分布的熵是「每个可能结果的概率乘以其对数后的和」的负值
为了理解其工作原理,让我们比较下面两个概率分布:
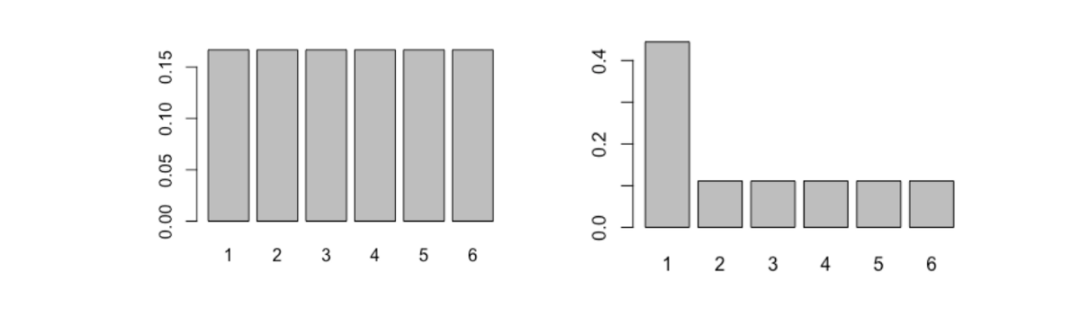
X 轴标明了可能的结果;Y 轴标明了它们各自的概率
左侧是一个常规六面骰子结果的概率分布;而右边的六面骰子不那么均匀。
从直觉上来说,你认为哪个的熵更高呢?哪个骰子结果的不确定性更大?让我们来计算它们的熵,看看答案是什么。
entropy <- function(x){
pr <- prop.table(table(x))
H <- sum(pr * log(pr,2))
return(-H)
}
dice1 <- 1:6
dice2 <- c(1,1,1,1,2:6)
entropy(dice1) # --> 2.585
entropy(dice2) # --> 2.281不出所料,常规骰子的熵更高。这是因为每种结果的可能性都一样,所以我们不会提前知道结果偏向哪个。但是,非常规的骰子有所不同——某些结果的发生概率远大于其它结果——所以它的结果的不确定性也低一些。
这么一来,我们就能明白,当每种结果的发生概率相同时,它的熵最高。而这种概率分布也就是传说中的「均匀」分布。
交叉熵是熵的一个拓展概念,它引入了第二个变量的概率分布。
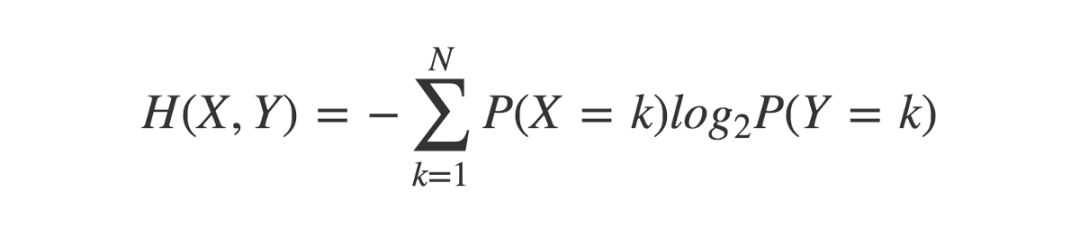
crossEntropy <- function(x,y){
prX <- prop.table(table(x))
prY <- prop.table(table(y))
H <- sum(prX * log(prY,2))
return(-H)
}
两个相同概率分布之间的交叉熵等于其各自单独的熵。但是对于两个不同的概率分布,它们的交叉熵可能跟各自单独的熵有所不同。
这种差异,或者叫「散度」可以通过 KL 散度(Kullback-Leibler divergence)量化得出。
两概率分布 X 与 Y 的 KL 散度如下:
概率分布 X 与 Y 的 KL 散度等于它们的交叉熵减去 X 的熵
KL 散度的最小值为 0,仅当两个分布相同。
KL_divergence <- function(x,y){
kl <- crossEntropy(x,y) - entropy(x)
return(kl)
}为了发现变量具有相关性,KL 散度的用途之一是计算两个变量的互信息(MI)。
互信息可以定义为「两个随机变量的联合分布和边缘分布之间的 KL 散度」。如果二者相同,MI 值取 0。如若不同,MI 值就为一个正数。二者之间的差异越大,MI 值就越大。
为了加深理解,我们首先简单回顾一些概率论的知识。
变量 X 和 Y 的联合概率就是二者同时发生的概率。例如,如果你抛掷两枚硬币 X 和 Y,它们的联合分布将反映抛掷结果的概率。假设你抛掷硬币 100 次,得到「正面、正面」的结果 40 次。联合分布将反映如下:
P(X=H, Y=H) = 40/100 = 0.4
jointDist <- function(x,y){
N <- length(x)
u <- unique(append(x,y))
joint <- c()
for(i in u){
for(j in u){
f <- x[paste0(x,y) == paste0(i,j)]
joint <- append(joint, length(f)/N)
}
}
return(joint)
}边缘分布是指不考虑其它变量而只关注某一特定变量的概率分布。假设两变量独立,二者边缘概率的乘积即为二者同时发生的概率。仍以抛硬币为例,假如抛掷结果是 50 次正面和 50 次反面,它们的边缘分布如下:
P(X=H) = 50/100 = 0.5 ; P(Y=H) = 50/100 = 0.5
P(X=H) × P(Y=H) = 0.5 × 0.5 = 0.25
marginalProduct <- function(x,y){
N <- length(x)
u <- unique(append(x,y))
marginal <- c()
for(i in u){
for(j in u){
fX <- length(x[x == i]) / N
fY <- length(y[y == j]) / N
marginal <- append(marginal, fX * fY)
}
}
return(marginal)
}
现在让我们回到抛硬币的例子。如果两枚硬币相互独立,边缘分布的乘积表示每个结果可能发生的概率,而联合分布则为实际得到的结果的概率。
如果两硬币完全独立,它们的联合概率在数值上(约)等于边缘分布的乘积。若只是部分独立,此处就存在散度。
这个例子中,P(X=H,Y=H) > P(X=H) × P(Y=H)。这表明两硬币全为正面的概率要大于它们的边缘分布之积。
联合分布和边缘分布乘积之间的散度越大,两个变量之间相关的可能性就越大。两个变量的互信息定义了散度的度量方式。
X 和 Y 的互信息等于「二者边缘分布积和的联合分布的 KL 散度」
mutualInfo <- function(x,y){
joint <- jointDist(x,y)
marginal <- marginalProduct(x,y)
Hjm <- - sum(joint[marginal > 0] * log(marginal[marginal > 0],2))
Hj <- - sum(joint[joint > 0] * log(joint[joint > 0],2))
return(Hjm - Hj)
}此处的一个重要假设就是概率分布是离散的。那么我们如何把这些概念应用到连续的概率分布呢?
分箱算法
其中一种方法是量化数据(使变量离散化)。这是通过分箱算法(bining)实现的,它能将连续的数据点分配对应的离散类别。
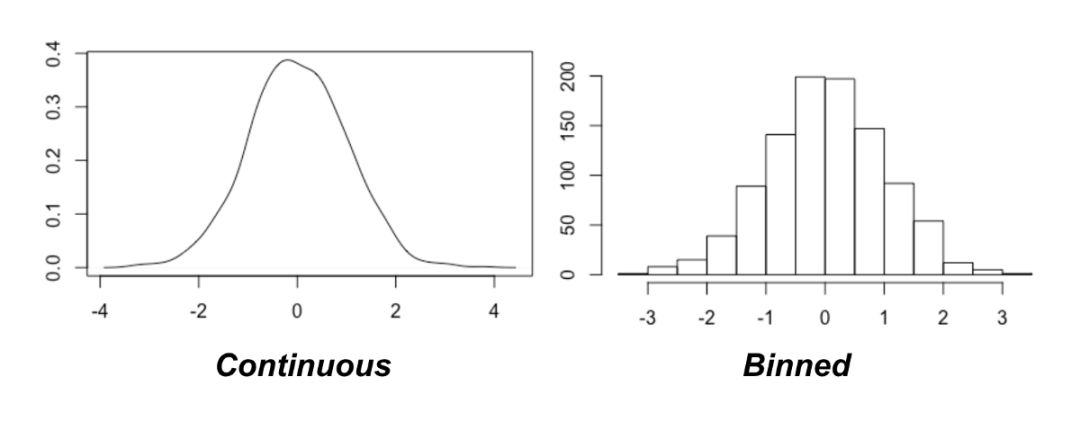
此方法的关键问题是到底要使用多少「箱子(bin)」。幸运的是,首次提出 MIC 的论文给出了建议:穷举!
也就是说,去尝试不同的「箱子」个数并观测哪个会在变量间取到最大的互信息值。不过,这提出了两个挑战:
-
要试多少个箱子呢?理论上你可以将变量量化到任意间距值,可以使箱子尺寸越来越小。
-
互信息对所用的箱子数很敏感。你如何公平比较不同箱子数目之间的 MI 值?
第一个挑战从理论上讲是不能做到的。但是,论文作者提供了一个启发式解法(也就是说,解法不完美,但是十分接近完美解法)。他们也给出了可试箱子个数的上限。
最大可用箱子个数由样本数 N 决定
至于如何公平比较取不同箱子数对 MI 值的影响,有一个简单的做法……就是归一化!这可以通过将每个 MI 值除以在特定箱子数组合上取得的理论最大值来完成。我们要采用的是产生最大归一化 MI 总值的箱子数组合。
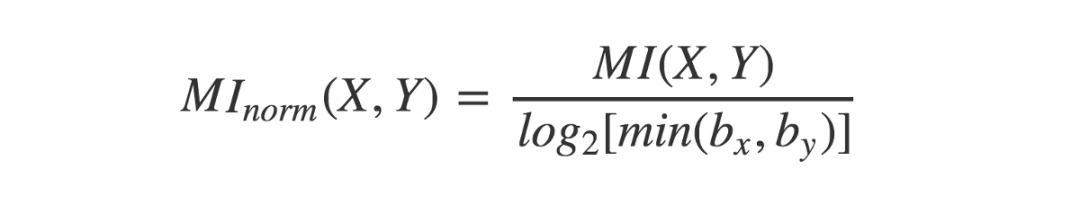
互信息可以通过除以最小的箱子数的对数来归一化
最大的归一化互信息就是 X 和 Y 的最大信息系数(MIC)。我们来看看一些估算两个连续变量的 MIC 的代码。
MIC <- function(x,y){
N <- length(x)
maxBins <- ceiling(N ** 0.6)
MI <- c()
for(i in 2:maxBins) {
for (j in 2:maxBins){
if(i * j > maxBins){
next
}
Xbins <- i; Ybins <- j
binnedX <-cut(x, breaks=Xbins, labels = 1:Xbins)
binnedY <-cut(y, breaks=Ybins, labels = 1:Ybins)
MI_estimate <- mutualInfo(binnedX,binnedY)
MI_normalized <- MI_estimate / log(min(Xbins,Ybins),2)
MI <- append(MI, MI_normalized)
}
}
return(max(MI))
}
x <- runif(100,-10,10)
y <- x**2 + rnorm(100,0,10)
MIC(x,y) # --> 0.751
以上代码是对原论文中方法的简化。更接近原作的算法实现可以参考 R package minerva(https://cran.r-project.org/web/packages/minerva/index.html)。
在 Python 中的实现请参考 minepy module(https://minepy.readthedocs.io/en/latest/)。
MIC 能够表示各种线性和非线性的关系,并已得到广泛应用。它的值域在 0 和 1 之间,值越高表示相关性越强。