来自:http://www.open-open.com/lib/view/open1424916275249.html 十年前,谷歌发表了 “BigTable” 的论文,论文中很多很酷的方面之一就是它所使用的文件组织方式,这个方法更一般的名字叫 Log Structured-Merge Tree。
LSM是当前被用在许多产品的文件结构策略:HBase, Cassandra, LevelDB, SQLite,甚至在mangodb3.0中也带了一个可选的LSM引擎(Wired Tiger 实现的)。
背景知识
简单的说,LSM被设计来提供比传统的B+树或者ISAM更好的写操作吞吐量,通过消去随机的本地更新操作来达到这个目标。
那么为什么这是一个好的方法呢?这个问题的本质还是磁盘随机操作慢,顺序读写快的老问题。这二种操作存在巨大的差距,无论是磁盘还是SSD。
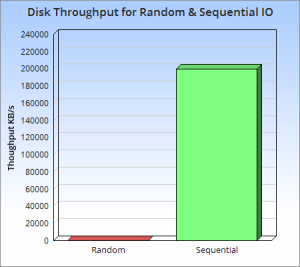
上图很好的说明了这一点,他们展现了一些反直觉的事实,顺序读写磁盘(不管是SATA还是SSD)快于随机读写主存,而且快至少三个数量级。这说明我们要避免随机读写,最好设计成顺序读写。
所以,让我们想想,如果我们对写操作的吞吐量敏感,我们最好怎么做?一个好的办法是简单的将数据添加到文件。这个策略经常被使用在日志或者堆文件,因为他们是完全顺序的,所以可以提供非常好的写操作性能,大约等于磁盘的理论速度,也就是200~300 MB/s。
因为简单和高效,基于日志的策略在大数据之间越来越流行,同时他们也有一些缺点,从日志文件中读一些数据将会比写操作需要更多的时间,需要倒序扫描,直接找到所需的内容。
这说明日志仅仅适用于一些简单的场景:1. 数据是被整体访问,像大部分数据库的WAL(write-ahead log) 2. 知道明确的offset,比如在Kafka中。
所以,我们需要更多的日志来为更复杂的读场景(比如按key或者range)提供高效的性能,这儿有4个方法可以完成这个,它们分别是:
- 二分查找: 将文件数据有序保存,使用二分查找来完成特定key的查找。
- 哈希:用哈希将数据分割为不同的bucket
- B+树:使用B+树 或者 ISAM 等方法,可以减少外部文件的读取
- 外部文件: 将数据保存为日志,并创建一个hash或者查找树映射相应的文件。
所有的方法都可以有效的提高了读操作的性能(最少提供了O(log(n)) ),但是,却丢失了日志文件超好的写性能。上面这些方法,都强加了总体的结构信息在数据上,数据被按照特定的方式放置,所以可以很快的找到特定的数据,但是却对写操作不友善,让写操作性能下降。
更糟糕的是,当我们需要更新hash或者B+树的结构时,需要同时更新文件系统中特定的部分,这就是上面说的比较慢的随机读写操作。这种随机的操作要尽量减少。
所以这就是 LSM 被发明的原理, LSM 使用一种不同于上述四种的方法,保持了日志文件写性能,以及微小的读操作性能损失。本质上就是让所有的操作顺序化,而不是像散弹枪一样随机读写。
The Base LSM Algorithm
从概念上说,最基本的LSM是很简单的 。将之前使用一个大的查找结构(造成随机读写,影响写性能),变换为将写操作顺序的保存到一些相似的有序文件(也就是sstable)中。所以每个文件包含短时间内的一些改动。因为文件是有序的,所以之后查找也会很快。文件是不可修改的,他们永远不会被更新,新的更新操作只会写到新的文件中。读操作检查所有的文件。通过周期性的合并这些文件来减少文件个数。
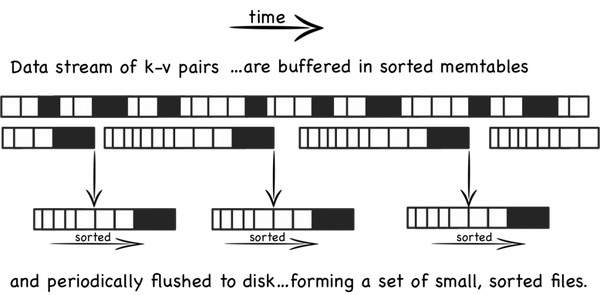
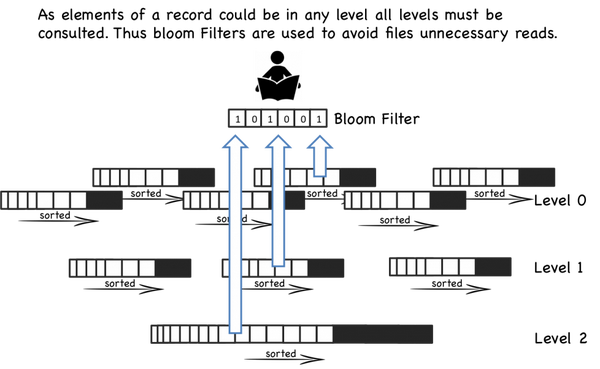
让我们更具体的看看,当一些更新操作到达时,他们会被写到内存缓存(也就是memtable)中,memtable使用树结构来保持key的有序,在大部 分的实现中,memtable会通过写WAL的方式备份到磁盘,用来恢复数据,防止数据丢失。当memtable数据达到一定规模时会被刷新到磁盘上的一 个新文件,重要的是系统只做了顺序磁盘读写,因为没有文件被编辑,新的内容或者修改只用简单的生成新的文件。
所以越多的数据存储到系统中,就会有越多的不可修改的,顺序的sstable文件被创建,它们代表了小的,按时间顺序的修改。
因为比较旧的文件不会被更新,重复的纪录只会通过创建新的纪录来覆盖,这也就产生了一些冗余的数据。所以系统会周期的执行合并操作(compaction)。 合并操作选择一些文件,并把他们合并到一起,移除重复的更新或者删除纪录,同时也会删除上述的冗余。更重要的是,通过减少文件个数的增长,保证读操作的性 能。因为sstable文件都是有序结构的,所以合并操作也是非常高效的。
当一个读操作请求时,系统首先检查内存数据(memtable),如果没有找到这个key,就会逆序的一个一个检查sstable文件,直到key 被找到。因为每个sstable都是有序的,所以查找比较高效(O(logN)),但是读操作会变的越来越慢随着sstable的个数增加,因为每一个 sstable都要被检查。(O(K log N), K为sstable个数, N 为sstable平均大小)。
所以,读操作比其它本地更新的结构慢,幸运的是,有一些技巧可以提高性能。最基本的的方法就是页缓存(也就是leveldb的 TableCache,将sstable按照LRU缓存在内存中)在内存中,减少二分查找的消耗。LevelDB 和 BigTable 是将 block-index 保存在文件尾部,这样查找就只要一次IO操作,如果block-index在内存中。一些其它的系统则实现了更复杂的索引方法。
即使有每个文件的索引,随着文件个数增多,读操作仍然很慢。通过周期的合并文件,来保持文件的个数,因些读操作的性能在可接收的范围内。即便有了合并操作,读操作仍然会访问大量的文件,大部分的实现通过布隆过滤器来避免大量的读文件操作,布隆过滤器是一种高效的方法来判断一个sstable中是否包 含一个特定的key。