元学习要解决的问题是给你一堆猫狗图片(训练样本较多),然后给你一类黑天鹅图谱(样本少),让你训练一个模型,能够泛化能力好,识别猫狗和黑天鹅。
使用场景:某些AI分类的训练样本很少,数据分布不均衡,例如上面识别猫狗和黑天鹅的情形。
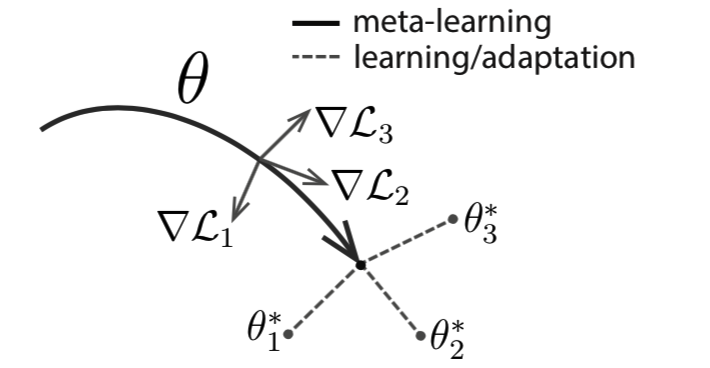
MAML的思想:先训练猫狗样本,得到初始识别模型,其参数为theta,然后根据黑天鹅的task去针对性迭代,产生新的theta*,在迭代过程中,要满足theta*对task很敏感!就是说识别猫狗的元模型要能快速适应识别黑天鹅。
一般元学习流程是:在训练数据 集和验证数据集上得到泛化性较强的初始 化网络参数,在测试时,将网络模型在测试 数据上进行少量几次梯度下降操作,以达到 “学习新任务”的目的,接着检验学习后的效 果。训练和测试一般流程如图 1 和图 2。see:http://cjc.ict.ac.cn/online/bfpub/lcf-20201214103607.pdf
------原文----
一文入门元学习(Meta-Learning)(附代码)
写在前面:迄今为止,本文应该是网上介绍【元学习(Meta-Learning)】最通俗易懂的文章了( 保命),主要目的是想对自己对于元学习的内容和问题进行总结,同时为想要学习Meta-Learning的同学提供一下简单的入门。笔者挑选了经典的paper详读,看了李宏毅老师深度学习课程元学习部分,并附了MAML的代码。为了通俗易懂,我将数学推导和工程实践分开两篇文章进行介绍。如果看不懂,欢迎来捶我( )~~
如果大家觉得有帮助,可以帮忙点个赞或者收藏一下,这将是我继续分享的动力~
以下是本文的主要框架:
- Introduction
- Meta Learning实施——以MAML为例
- Reptile
- What's more
全文大约4000字,阅读完大概需要12分钟。
1. Introduction
通常在机器学习里,我们会使用某个场景的大量数据来训练模型;然而当场景发生改变,模型就需要重新训练。但是对于人类而言,一个小朋友成长过程中会见过许多物体的照片,某一天,当Ta(第一次)仅仅看了几张狗的照片,就可以很好地对狗和其他物体进行区分。
元学习Meta Learning,含义为学会学习,即learn to learn,就是带着这种对人类这种“学习能力”的期望诞生的。Meta Learning希望使得模型获取一种“学会学习”的能力,使其可以在获取已有“知识”的基础上快速学习新的任务,如:
- 让Alphago迅速学会下象棋
- 让一个猫咪图片分类器,迅速具有分类其他物体的能力
需要注意的是,虽然同样有“预训练”的意思在里面,但是元学习的内核区别于迁移学习(Transfer Learning),关于他们的区别,我会在下文进行阐述。
接下来,我们通过对比机器学习和元学习这两个概念的要素来加深对元学习这个概念的理解。
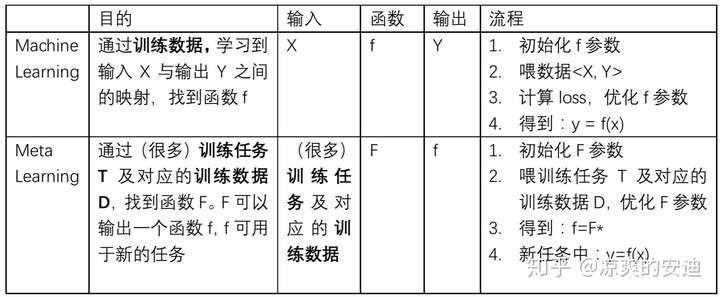
在机器学习中,训练单位是一条数据,通过数据来对模型进行优化;数据可以分为训练集、测试集和验证集。在元学习中,训练单位分层级了,第一层训练单位是任务,也就是说,元学习中要准备许多任务来进行学习,第二层训练单位才是每个任务对应的数据。
二者的目的都是找一个Function,只是两个Function的功能不同,要做的事情不一样。机器学习中的Function直接作用于特征和标签,去寻找特征与标签之间的关联;而元学习中的Function是用于寻找新的f,新的f才会应用于具体的任务。有种不同阶导数的感觉。又有种老千层饼的感觉,你看到我在第二层,你把我想象成第一层,而其实我在第五层。。。
2. Meta Learning实施——以MAML为例
我们先对比机器学习的过程来进一步理解元学习。如下图所示,机器学习的一般过程如下:
- 设计网络网络结构,如CNN、RNN等;
- 选定某个分布来初始化参数;(以上其实决定了初始的f的长相,选择不同的网络结构或参数相当于定义了不同的f);
- 喂训练数据,根据选定的Loss Function计算Loss;
- 梯度下降,逐步更新 ;
- 得到最终的f
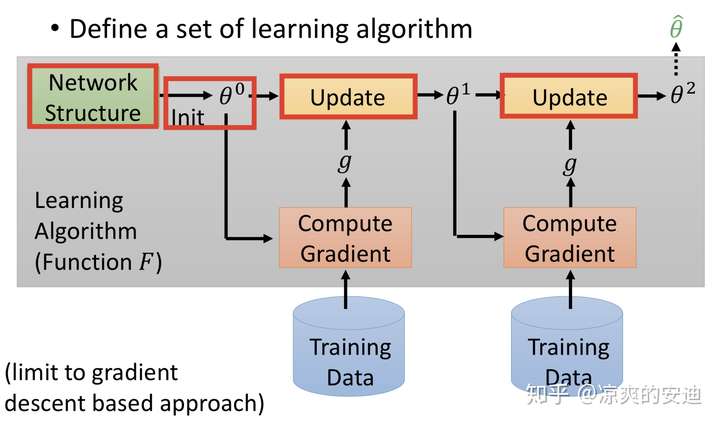 机器学习过程,引自李宏毅《深度学习》
机器学习过程,引自李宏毅《深度学习》
其中,红色方框里的“配置”都是由人为设计的,我们又叫做“超参数“。Meta Learning中希望把这些配置,如网络结构,参数初始化,优化器等由机器自行设计(注:此处区别于AutoML,迁移学习(Transfer Learning)和终身学习(Life Long Learning) ),使网络有更强的学习能力和表现。
上文已经提到,【元学习中要准备许多任务来进行学习,而每个任务又有各自的训练集和测试集】。我们结合一个具体的任务,来介绍元学习和MAML的实施过程。
有一个图像数据集叫Omniglot:https://github.com/brendenlake/omniglot。Omniglot包含1623个不同的火星文字符,每个字符包含20个手写的case。这个任务是判断每个手写的case属于哪一个火星文字符。
如果我们要进行N-ways,K-shot(数据中包含N个字符类别,每个字符有K张图像)的一个图像分类任务。比如20-ways,1-shot分类的意思是说,要做一个20分类,但是每个分类下只有1张图像的任务。我们可以依据Omniglot构建很多N-ways,K-shot任务,这些任务将作为元学习的任务来源。构建的任务分为训练任务(Train Task),测试任务(Test Task)。特别地,每个任务包含自己的训练数据、测试数据,在元学习里,分别称为Support Set和Query Set。
MAML的目的是获取一组更好的模型初始化参数(即让模型自己学会初始化)。我们通过(许多)N-ways,K-shot的任务(训练任务)进行元学习的训练,使得模型学习到“先验知识”(初始化的参数)。这个“先验知识”在新的N-ways,K-shot任务上可以表现的更好。
接下来介绍MAML的算法流程:
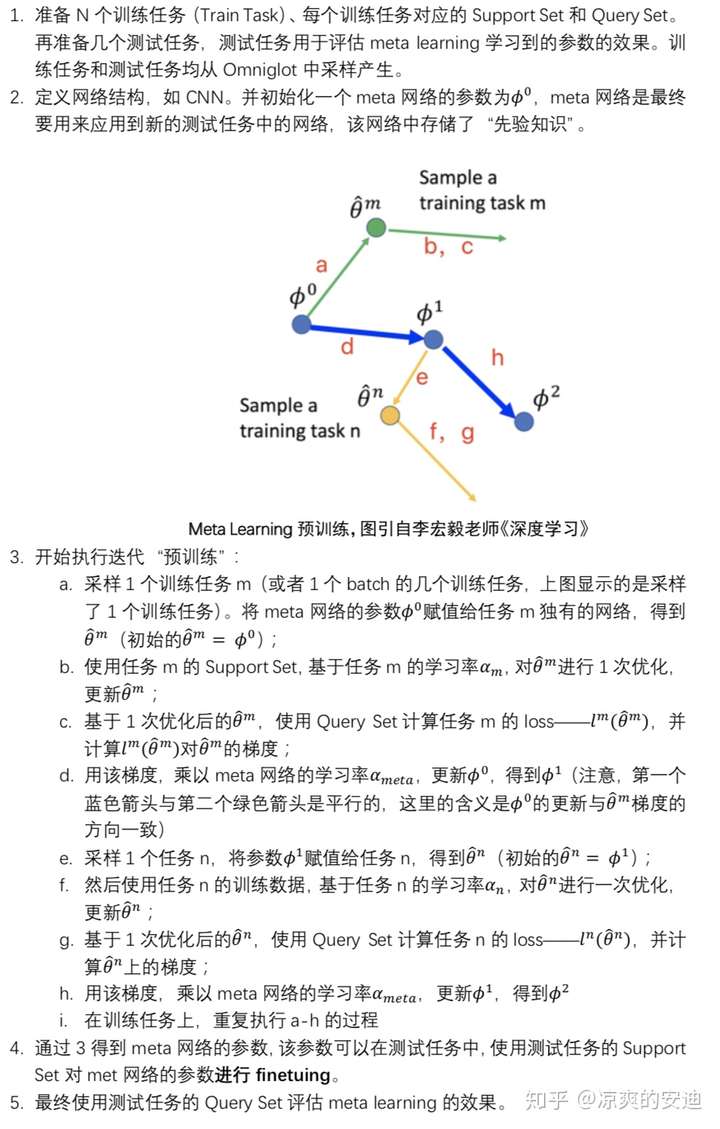 MAML算法流程
MAML算法流程
当然,在“预训练”阶段,也可以sample出1个batch的几个任务,那么在更新meta网络时,要使用sample出所有任务的梯度之和。
注意:在MAML中,meta网络与子任务的网络结构必须完全相同。
这里面有几个小问题:
- MAML的执行过程与model pretraining & transfer learning的区别是什么?
- 为何在meta网络赋值给具体训练任务(如任务m)后,要先更训练任务的参数,再计算梯度,更新meta网络?
- 在更新训练任务的网络时,只走了一步,然后更新meta网络。为什么是一步,可以是多步吗?
这三个问题是MAML中很核心的问题,大家可以先思考一下,我们将在后文进行解答。我们先看一下MAML的实现代码。
## 网络构建部分: refer: https://github.com/dragen1860/MAML-TensorFlow
#################################################
# 任务描述:5-ways,1-shot图像分类任务,图像统一处理成 84 * 84 * 3 = 21168的尺寸。
# support set:5 * 1
# query set:5 * 15
# 训练取1个batch的任务:batch size:4
# 对训练任务进行训练时,更新5次:K = 5
#################################################
print(support_x) # (4, 5, 21168)
print(query_x) # (4, 75, 21168)
print(support_y) # (4, 5, 5)
print(query_y) # (4, 75, 5)
print(meta_batchsz) # 4
print(K) # 5
model = MAML()
model.build(support_x, support_y, query_x, query_y, K, meta_batchsz, mode='train')
class MAML:
def __init__(self):
pass
def build(self, support_xb, support_yb, query_xb, query_yb, K, meta_batchsz, mode='train'):
"""
:param support_xb: [4, 5, 84*84*3]
:param support_yb: [4, 5, n-way]
:param query_xb: [4, 75, 84*84*3]
:param query_yb: [4, 75, n-way]
:param K: 训练任务的网络更新步数
:param meta_batchsz: 任务数,4
"""
self.weights = self.conv_weights() # 创建或者复用网络参数;训练任务对应的网络复用meta网络的参数
training = True if mode is 'train' else False
def meta_task(input):
"""
:param support_x: [setsz, 84*84*3] (5, 21168)
:param support_y: [setsz, n-way] (5, 5)
:param query_x: [querysz, 84*84*3] (75, 21168)
:param query_y: [querysz, n-way] (75, 5)
:param training: training or not, for batch_norm
:return:
"""
support_x, support_y, query_x, query_y = input
query_preds, query_losses, query_accs = [], [], [] # 子网络更新K次,记录每一次queryset的结果
## 第0次对网络进行更新
support_pred = self.forward(support_x, self.weights, training) # 前向计算support set
support_loss = tf.nn.softmax_cross_entropy_with_logits(logits=support_pred, labels=support_y) # support set loss
support_acc = tf.contrib.metrics.accuracy(tf.argmax(tf.nn.softmax(support_pred, dim=1), axis=1),
tf.argmax(support_y, axis=1))
grads = tf.gradients(support_loss, list(self.weights.values())) # 计算support set的梯度
gvs =