141. 对x开根
实现 int sqrt(int x) 函数,计算并返回 x 的平方根。
样例
Example 1:
Input: 0
Output: 0
Example 2:
Input: 3
Output: 1
Explanation:
return the largest integer y that y*y <= x.
Example 3:
Input: 4
Output: 2
挑战
O(log(x))
class Solution:
"""
@param x: An integer
@return: The sqrt of x
"""
def sqrt(self, x):
# write your code here
l, r = 0, x
while l + 1 < r:
mid = (l + r) >> 1
if mid*mid > x:
r = mid
else:
l = mid
if r*r == x:
return r
return l
183. 木材加工
有一些原木,现在想把这些木头切割成一些长度相同的小段木头,需要得到的小段的数目至少为 k。当然,我们希望得到的小段越长越好,你需要计算能够得到的小段木头的最大长度。
样例
Example 1
Input:
L = [232, 124, 456]
k = 7
Output: 114
Explanation: We can cut it into 7 pieces if any piece is 114cm long, however we can't cut it into 7 pieces if any piece is 115cm long.
Example 2
Input:
L = [1, 2, 3]
k = 7
Output: 0
Explanation: It is obvious we can't make it.
挑战
O(n log Len), Len为 n 段原木中最大的长度
注意事项
木头长度的单位是厘米。原木的长度都是正整数,我们要求切割得到的小段木头的长度也要求是整数。无法切出要求至少 k 段的,则返回 0 即可。
木头长度的范围在 1 到 max(L),在这个范围内二分出一个长度 length,然后看看以这个 wood length 为前提的基础上,能切割出多少木头,如果少于 k 根,说明要短一些才行,如果多余 k,说明可以继续边长一些。
class Solution:
"""
@param L: Given n pieces of wood with length L[i]
@param k: An integer
@return: The maximum length of the small pieces
"""
def woodCut(self, L, k):
# write your code here
def cut_piece(length):
ans = 0
for i in L:
ans += i // length
return ans
if not L:
return 0
l, r = 1, max(L)
while l + 1 < r:
mid = (l + r) >> 1
if cut_piece(mid) >= k:
l = mid
else:
r = mid
if cut_piece(r) >= k:
return r
if cut_piece(l) >= k:
return l
return 0
看到了吧,其实二分答案的模板还是很简单的,就是二分的模板!!!
437. 书籍复印
给定 n 本书, 第 i 本书的页数为 pages[i]. 现在有 k 个人来复印这些书籍, 而每个人只能复印编号连续的一段的书, 比如一个人可以复印 pages[0], pages[1], pages[2], 但是不可以只复印 pages[0], pages[2], pages[3] 而不复印 pages[1].
所有人复印的速度是一样的, 复印一页需要花费一分钟, 并且所有人同时开始复印. 怎样分配这 k 个人的任务, 使得这 n 本书能够被尽快复印完?
返回完成复印任务最少需要的分钟数.
样例
样例 1:
输入: pages = [3, 2, 4], k = 2
输出: 5
解释: 第一个人复印前两本书, 耗时 5 分钟. 第二个人复印第三本书, 耗时 4 分钟.
样例 2:
输入: pages = [3, 2, 4], k = 3
输出: 4
解释: 三个人各复印一本书.
挑战
时间复杂度 O(nk)
注意事项
书籍页数总和小于等于2147483647
基于答案值域的二分法。 答案的范围在 max(pages)~sum(pages) 之间,每次二分到一个时间 time_limit 的时候,用贪心法从左到右扫描一下 pages,看看需要多少个人来完成抄袭。 如果这个值 <= k,那么意味着大家花的时间可能可以再少一些,如果 > k 则意味着人数不够,需要降低工作量。
时间复杂度 O(nlog(sum))
是该问题时间复杂度上的最优解法
class Solution:
"""
@param pages: an array of integers
@param k: An integer
@return: an integer
"""
def copyBooks(self, pages, k):
if not pages:
return 0
start, end = max(pages), sum(pages)
while start + 1 < end:
mid = (start + end) // 2
if self.get_least_people(pages, mid) <= k:
end = mid
else:
start = mid
if self.get_least_people(pages, start) <= k:
return start
return end
def get_least_people(self, pages, time_limit):
count = 0
time_cost = 0
for page in pages:
if time_cost + page > time_limit:
count += 1
time_cost = 0
time_cost += page
return count + 1
633. 寻找重复的数
给出一个数组 nums 包含 n + 1 个整数,每个整数是从 1 到 n (包括边界),保证至少存在一个重复的整数。假设只有一个重复的整数,找出这个重复的数。
样例
Example 1:
Input:
[5,5,4,3,2,1]
Output:
5
Example 2:
Input:
[5,4,4,3,2,1]
Output:
4
注意事项
1.不能修改数组(假设数组只能读)
2.只能用额外的O(1)的空间
3.时间复杂度小于O(n^2)
4.数组中只有一个重复的数,但可能重复超过一次
- x轴是 0, 1, 2, ... n。
- y轴是对应的 <=x 的数的个数,比如 <=0 的数的个数是0,就在(0,0)这个坐标画一个点。<=n 的数的个数是 n+1 个,就在 (n,n+1)画一个点。
把所有的点连接起来之后,是一个类似下图的折线:
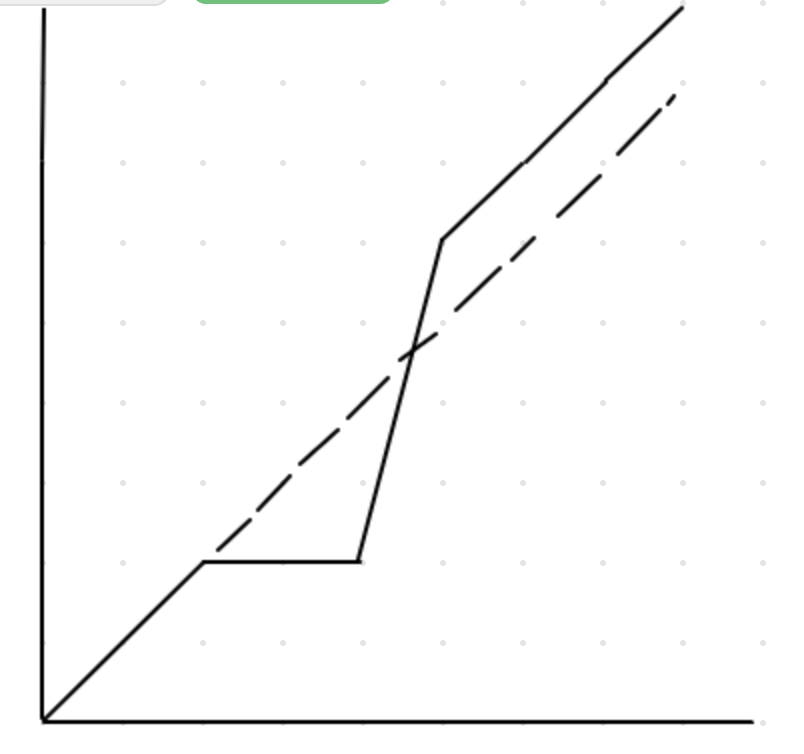
我们可以知道这个折线图的有如下的一些属性:
- 大部分时候,我们会沿着斜率为 1 的那条虚线前进
- 如果出现了一些空缺的数,就会有横向的折线
- 一旦出现了重复的数,就会出现一段斜率超过 1 的折线
- 斜率超过 1 的折线只会出现一次
试想一下,对比 y=x 这条虚线,当折线冒过了这条虚线出现在这条虚线的上方的时候,一定是遇到了一个重复的数。 一旦越过了这条虚线以后,就再也不会掉到虚线的下方或者和虚线重叠。 因为折线最终会停在 (n,n+1) 这个位置,如果要从 y=x 这条虚线或者这条虚线的下方到达 (n,n+1) 这个位置, 一定需要一个斜率 > 1的折线段,而这个与题目所说的重复的数只有一个就是矛盾的。因此可以证明,斜率超过1 的折线只会出现1次, 且会将折线整体带上 y=x 这条虚线的上方。因此第一个在 y=x 上方的 x 点,就是我们要找的重复的数。
时间复杂度是 O(nlogn)
public class Solution {
/**
* @param nums an array containing n + 1 integers which is between 1 and n
* @return the duplicate one
*/
public int findDuplicate(int[] nums) {
// Write your code here
int l = 1;
int r = nums.length - 1; // n
while (l + 1 < r) {
int mid = l + (r - l) / 2;
if (count(nums, mid) <= mid) {
l = mid;
} else {
r = mid;
}
}
if (count(nums, l) <= l) {
return r;
}
return l;
}
private int count(int[] nums, int mid) {
int cnt = 0;
for (int item : nums) {
if (item <= mid) {
cnt++;
}
}
return cnt;
}
} 617. 子数组的最大平均值 II
给出一个整数数组,有正有负。找到这样一个子数组,他的长度大于等于 k,且平均值最大。
样例
Example 1:
Input:
[1,12,-5,-6,50,3]
3
Output:
15.667
Explanation:
(-6 + 50 + 3) / 3 = 15.667
Example 2:
Input:
[5]
1
Output:
5.000
注意事项
保证数组的大小 >= k
基于二分答案的方法 二分出 average 之后,把数组中的每个数都减去 average,然后的任务就是去求这个数组中,是否有长度 >= k 的 subarray,他的和超过 0。
class Solution:
"""
@param: nums: an array with positive and negative numbers
@param: k: an integer
@return: the maximum average
"""
def maxAverage(self, nums, k):
if not nums:
return 0
start, end = min(nums), max(nums)
while end - start > 1e-5:
mid = (start + end) / 2
if self.check_subarray(nums, k, mid):
start = mid
else:
end = mid
return start
def check_subarray(self, nums, k, average):
prefix_sum = [0]
for num in nums:
prefix_sum.append(prefix_sum[-1] + num - average)
min_prefix_sum = 0
for i in range(k, len(nums) + 1):
if prefix_sum[i] - min_prefix_sum >= 0:
return True
min_prefix_sum = min(min_prefix_sum, prefix_sum[i - k + 1])
return False