贝叶斯网络python实战(以泰坦尼克号数据集为例,pgmpy库)

 16815
16815  收藏 140
收藏 140本文的相关数据集,代码见文末百度云
贝叶斯网络简介
贝叶斯网络是一种置信网络,一个生成模型。(判别模型,生成模型的区分可以这样:回答p(label|x)即样本x属于某一类别的可能的,就是判别模型,而回答p(x,label) 和p(x|label)的,即回答在给定的类别中找样本x及样本分布情况的,即为生成模型。生成模型给出的联合分布比判别网络能给出更多的信息,对其求边缘分布即可得p(label|x) p(x|label))同时贝叶斯网络还是一个简单的白盒网络,提供了高可解释性的可能。相比于大热的几乎无所不能的深度神经网络,贝叶斯网络仍有他的优势和应用场景。比如在故障分析,疾病诊断里,我们不仅需要回答是不是,更重要的是回答为什么,并给出依据。这样的场景下,以贝叶斯网络为代表的一些可解释好的白盒网络更加有优势。
贝叶斯推断思路
与频率派直接从数据统计分析构建模型不同,贝叶斯派引入一个先验概率,表达对事件的已有了解,然后利用观测数据对先验知识进行修正,如通常把抛硬币向上的概率认为是0.5,这是个很朴素的先验知识,若是实验结果抛出了500-500的结果,那么证明先验知识是可靠的,合适的,若是出现100-900结果,那么先验知识会被逐渐修改(越来越相信这是个作弊硬币),当实验数据足够多的时候,先验知识就几乎不再体现,这时候得到与频率派几乎相同的结果。如图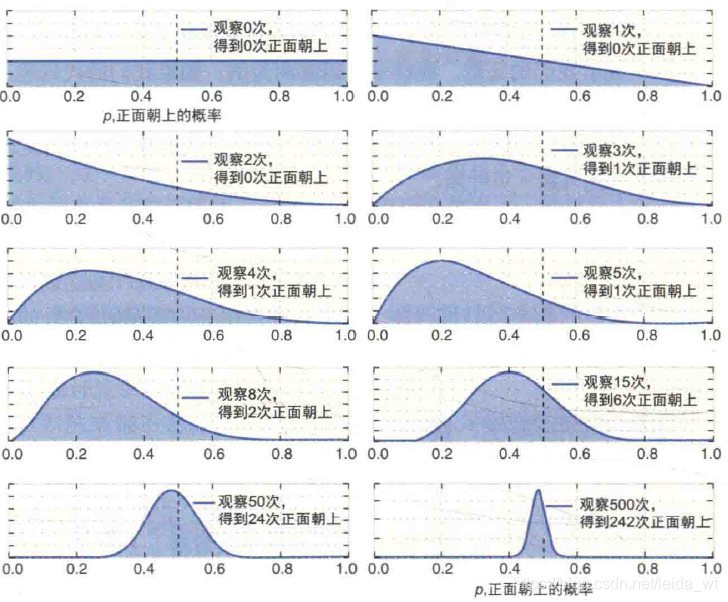
具体例子推导可见here
贝叶斯网络
贝叶斯网络结构如下所示,其是有特征节点和链接构成的有向无环图。节点上是概率P(A),P(B)… 连接上是条件概率P(A|B) P(A|C) … 即若有A指向B的连接,则连接代表的就应为P(B|A),更多信息可参考以下内容,这里不再赘述,贝叶斯网络结构本身不困难,其难点主要在于推理算法等数值计算问题,如为应用则无需深究。
贝叶斯网络发展及其应用综述
《贝叶斯网络引论》@张连文
静态贝叶斯网络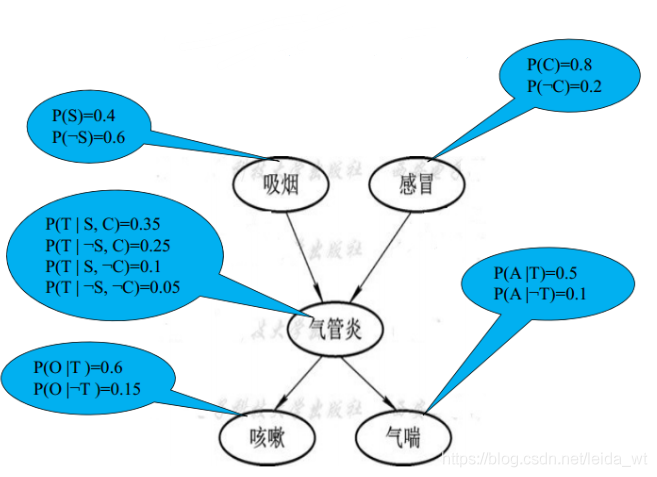
贝叶斯网络的实现
相关工具一直很丰富,matlab,R上都有成熟的工具。这里使用了python下的pgmpy,轻量好用,不像pymc那样容易安装困难。
安装:
conda install -c ankurankan pgmpy
或
pip install pgmpy
应用步骤
1.先确定以那些变量(特征)为节点,这里还包括由特征工程特征选择之类的工作。当然若有专业知识的参与会得到更合理的特征选择。
2.确定网络结构(拓扑)用以反应变量节点之间的依赖关系。也就是明确图的结构。这里既可以在有专家参与的情况下手工设计,也可以自动找到高效合适的网络,称为结构学习。贝叶斯网络的结构对最终网络性能很关键,若是构建所谓全连接贝叶斯网(即各个变量间两两相连),虽没有遗漏关联,但会导致严重的过拟合,因为数据量很难支撑起全连接直接海量的条件概率。
3.明确每条边上的条件概率。和结构一样,参数也可由专家手工确定(先验),亦可通过数据自动学习(即参数学习),或两者同时进行。
下面以一个经典数据集为例展示如何利用pgmpy包进行贝叶斯网络建模
泰坦尼克数据集背景介绍
ref:https://www.jianshu.com/p/9b6ee1fb7a60
https://www.kaggle.com/c/titanic
这是kaggle经典数据集,主要是让参赛选手根据训练集中的乘客数据和存活情况进行建模,进而使用模型预测测试集中的乘客是否会存活。乘客特征总共有11个,以下列出。这个数据集特征明确,数据量不大,很适合应用贝叶斯网络之类的模型来做,目前最好的结果是正确率应该有80+%(具体多少因为答案泄露不好讲了)
PassengerId => 乘客ID
Pclass => 客舱等级(1/2/3等舱位)
Name => 乘客姓名
Sex => 性别
Age => 年龄
SibSp => 兄弟姐妹数/配偶数
Parch => 父母数/子女数
Ticket => 船票编号
Fare => 船票价格
Cabin => 客舱号
Embarked => 登船港口
在开始建模之前,先进行下特征工程,处理原始数据集的缺项等。这里前面处理主要采用https://www.jianshu.com/p/9b6ee1fb7a60的方法(他应用pandas清理数据的技巧很值得一学),我在他的处理后,进一步进行了一些离散化处理,以使得数据符合贝叶斯网络的要求(贝叶斯网络也有支持连续变量的版本,但因为推理,学习的困难,目前还用的很少),最后保留5个特征。
'''
PassengerId => 乘客ID
Pclass => 客舱等级(1/2/3等舱位)
Name => 乘客姓名
Sex => 性别 清洗成male=1 female=0
Age => 年龄 插补后分0,1,2 代表 幼年(0-15) 成年(15-55) 老年(55-)
SibSp => 兄弟姐妹数/配偶数
Parch => 父母数/子女数
Ticket => 船票编号
Fare => 船票价格 经聚类变0 1 2 代表少 多 很多
Cabin => 客舱号 清洗成有无此项,并发现有的生存率高
Embarked => 登船港口 清洗na,填S
'''
# combine train and test set.
train=pd.read_csv('./train.csv')
test=pd.read_csv('./test.csv')
full=pd.concat([train,test],ignore_index=True)
full['Embarked'].fillna('S',inplace=True)
full.Fare.fillna(full[full.Pclass==3]['Fare'].median(),inplace=True)
full.loc[full.Cabin.notnull(),'Cabin']=1
full.loc[full.Cabin.isnull(),'Cabin']=0
full.loc[full['Sex']=='male','Sex']=1
full.loc[full['Sex']=='female','Sex']=0
full['Title']=full['Name'].apply(lambda x: x.split(',')[1].split('.')[0].strip())
nn={'Capt':'Rareman', 'Col':'Rareman','Don':'Rareman','Dona':'Rarewoman',
'Dr':'Rareman','Jonkheer':'Rareman','Lady':'Rarewoman','Major':'Rareman',
'Master':'Master','Miss':'Miss','Mlle':'Rarewoman','Mme':'Rarewoman',
'Mr':'Mr','Mrs':'Mrs','Ms':'Rarewoman','Rev':'Mr','Sir':'Rareman',
'the Countess':'Rarewoman'}
full.Title=full.Title.map(nn)
# assign the female 'Dr' to 'Rarewoman'
full.loc[full.PassengerId==797,'Title']='Rarewoman'
full.Age.fillna(999,inplace=True)
def girl(aa):
if (aa.Age!=999)&(aa.Title=='Miss')