基于统计的异常检测方法S-H-ESD[twitter]
Automatic Anomaly Detection in the Cloud Via Statistical Learning[1]
原文主要介绍了twitter云系统中利用统计学习实现异常检测的自动化,下面直接介绍相关方法。
Grubbs Test
表示一组时间序列,Grubbs test 检测单变量数据集的“最异常点“。前提假设数据分布是正态的。Grubbs test假设定义如下:
:数据集中没有异常点
: 数据集中有至少一个异常点
Grubbs‘ test 统计量定义如下
其中 和
分别表示数据集的均值和方差。对于双边检验,当满足式(2)时,以显著性水平
拒绝原假设
其中 表示自由度
,显著性水平
的
分布的上临界值。对于单边检验,
变为
[2]。但是缺点是数据集中存在多个异常点则不适合,因为
分布表不会更新。下面介绍多异常点的检测算法ESD(Extreme Studentized Deviate)[3]。
ESD
ESD可以检测时间序列数据的多异常点。需要指定异常点比例的upper bound是k,最差的情况是至多49.9%。实际中,数据集的异常比例一般不超过5%。ESD假设定义如下:
:数据集中没有异常点
: 数据集中有至多
个异常点
检验统计量和临界值分别定义如下
其中 ,ESD会重复
次检验,当
时,则有至少
个异常点。对于Grubbs Test和ESD的区别[4],主要两点:一是ESD会根据不同的离群值调整临界值;二是ESD一直会检验
个离群点,而Grubbs test可能会提前结束检验(当“最异常点”检验时
成立)。比如下面Rosner paper中的数据,设置
,第一次和第二次检验接受原假设,由于剔除前两个值之后临界值
的变化,在第三次检验拒绝了原假设,因此最终得到三个异常点。
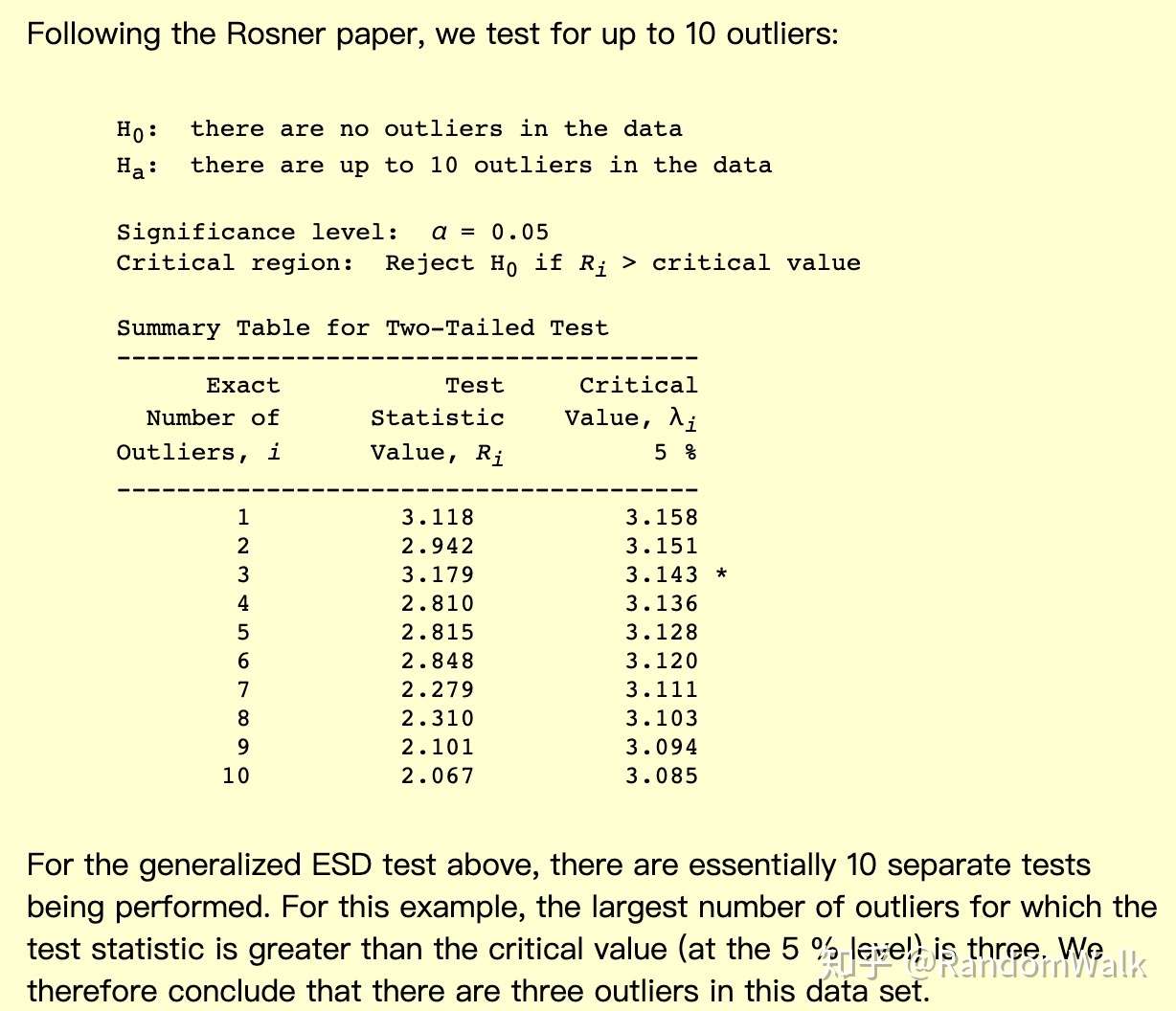 前10离群点中第三个点检测为异常,则至少有3个异常点
前10离群点中第三个点检测为异常,则至少有3个异常点
S-ESD
考虑ESD有如下两个限制:一是对于具有季节性的时间序列异常不能很好的识别,下图1中很多周期性变化的点并非异常点;二是多峰分布的数据点,一些低峰异常数据点不能被识别出来,如图2。
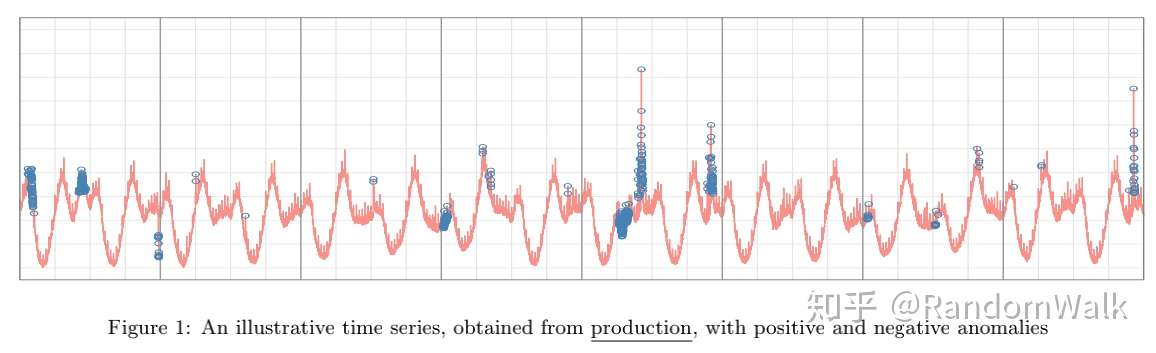 图1 时间序列图
图1 时间序列图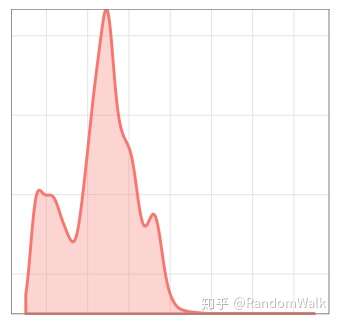 图2 数据分布图
图2 数据分布图
因此介绍S-ESD(Seasonal-ESD),Algorithm 1 中主要的不同是对时间序列数据进行STL分解,剔除其中的季节项,中位数做为趋势项(STL Variant),对残差项进行ESD检验。STL variant不同于STL主要考虑图3的情形,(a)中的STL分解得到的残差项,其中红色阴影部分存在spurious anomalies(这些点在原时间序列中并非异常)。

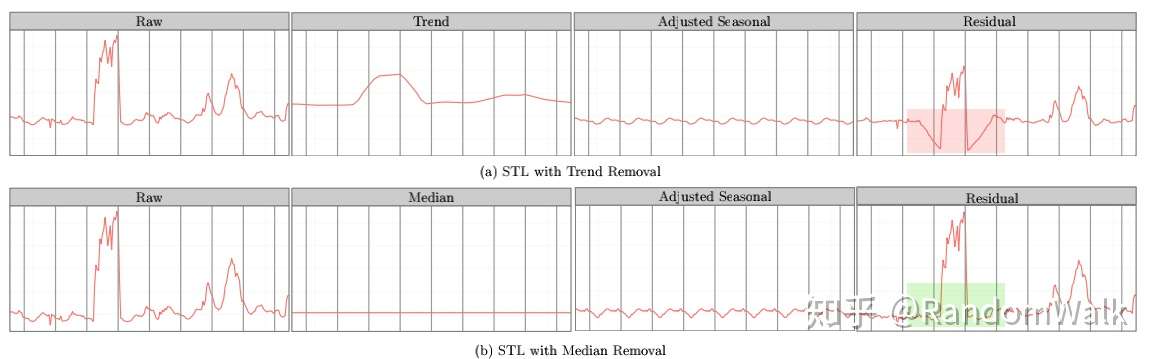 图3 STL和变形STL分解对比图
图3 STL和变形STL分解对比图
(局部异常和全局异常可识别性)S-ESD通过分解之后对残差项进行ESD检验,不仅可检验全局异常点,而且可以检验出如图4的局部异常点,这些异常点在原始数据中介于季节项的最大值和最小值之间,直接对原始数据ESD检验则无法识别。
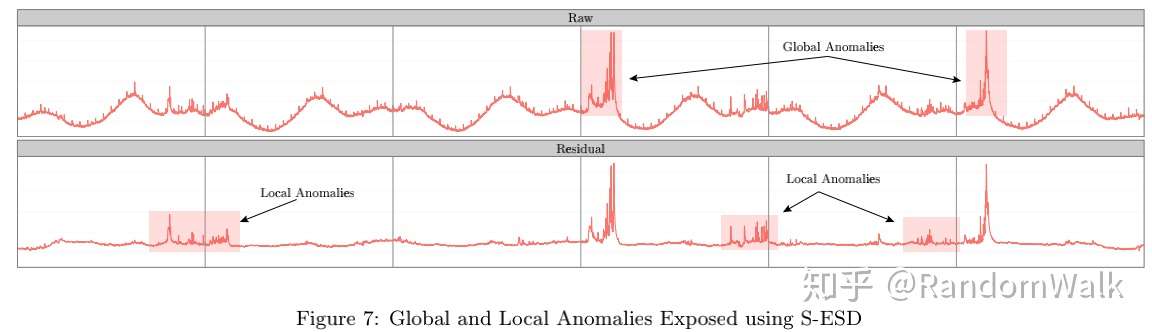 图4 局部异常和全局异常对比
图4 局部异常和全局异常对比
S-H-ESD
但是S-ESD也有局限性,就是对于数据中含有异常点数量较多时,很难识别较多的异常点。因此下面介绍Seasonal Hybrid ESD (S-H-ESD),首先介绍MAD。
MAD
考虑到ESD的检验统计量中的均值和方差对于过大的异常值较为敏感,于是选择利用MAD(Median Absolute Deviation)进行代替,如下
更一般的可以使用 或者
。
因此S-H-ESD相比S-ESD,是把ESD中的均值方差计算的统计量替换成MAD,图5比较了两种方法的效果,S-H-ESD对于异常点的识别率更高,同时由于计算中位数,时间复杂度也相对会更高。
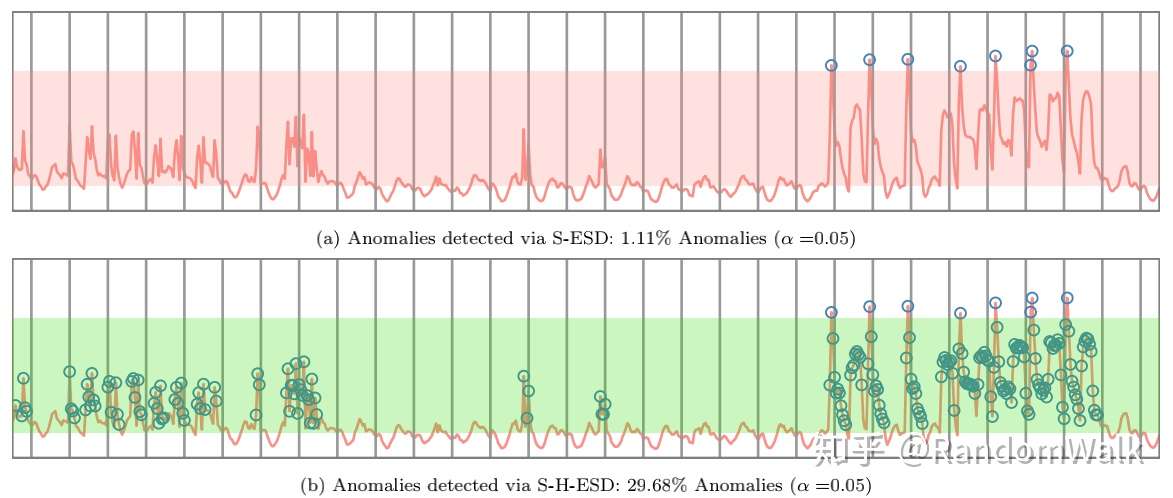 图5 S-ESD和S-H-ESD对比
图5 S-ESD和S-H-ESD对比
python实现
推荐pyculiarity,原文的github地址是R的实现[5]。
参考
- ^Hochenbaum J, Vallis O S, Kejariwal A. Automatic anomaly detection in the cloud via statistical learning[J]. arXiv preprint arXiv:1704.07706, 2017.
- ^Francisco Augusto Alcaraz Garcia. Tests to identify outliers in data series. Pontifical Catholic University of Rio de Janeiro, Industrial Engineering Department, Rio de Janeiro, Brazil, 2012.
- ^Bernard Rosner. On the detection of many outliers. Technometrics, 17(2):221–227, 1975.
- ^https://www.itl.nist.gov/div898/handbook/eda/section3/eda35h3.htm
- ^https://github.com/twitter/AnomalyDetection