1、Python 列表表达式
[表达式 for 变量 in 列表] or [表达式 for 变量 in 列表 if 条件]

就是把得到的每一个 li 值 都放到 for 前面的表达式中计算 ,然后生成一个列表。
2、函数参数的传值
传入函数的是实际参数值的复制品,不管在函数中对这个复制品如何操作,实际参数值本身不会受到任何影响。
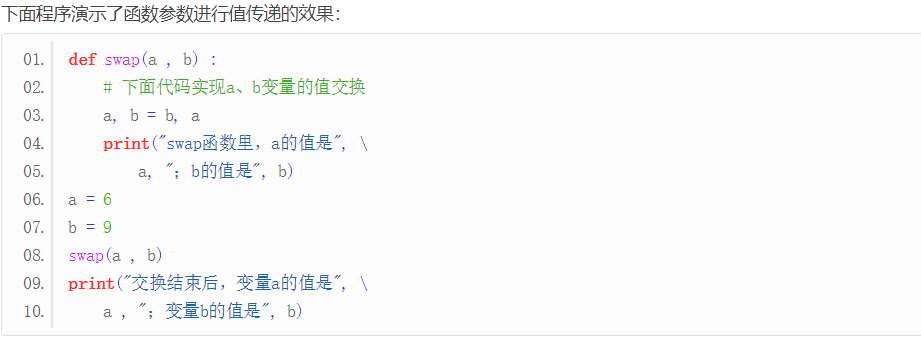
def用于写一个程序, 好在后面重复使用。直接执行函数就可以重复执行

从上面的运行结果来看,在 swap() 函数里,a 和 b 的值分别是 9、6,交换结束后,变量 a 和 b 的值依然是 6、9。从这个运行结果可以看出,程序中实际定义的变量 a 和 b,并不是 swap() 函数里的 a 和 b 。
如果实际参数的数据类型是可变对象(列表、字典),则函数参数的传递方式将采用引用传递方式。需要注意的是,引用传递方式的底层实现,采用的依然还是值传递的方式。

从上面的运行结果来看,在 swap() 函数里,dw 字典的 a、b 两个元素的值被交换成功。不仅如此,当 swap() 函数执行结束后,主程序中 dw 字典的 a、b 两个元素的值也被交换了。这很容易造成一种错觉,即在调用 swap() 函数时,传入 swap() 函数的就是 dw 字典本身,而不是它的复制品。但这只是一种错觉,下面还是结合示意图来说明程序的执行过程。
程序开始创建了一个字典对象,并定义了一个 dw 引用变量(其实就是一个指针)指向字典对象,这意味着此时内存中有两个东西:对象本身和指向该对象的引用变量。
通过上面介绍可以得出如下两个结论:
- 不管什么类型的参数,在 Python 函数中对参数直接使用“=”符号赋值是没用的,直接使用“=”符号赋值并不能改变参数。
- 如果需要让函数修改某些数据,则可以通过把这些数据包装成列表、字典等可变对象,然后把列表、字典等可变对象作为参数传入函数,在函数中通过列表、字典的方法修改它们,这样才能改变这些数据。
3、排序函数
sort()和sorted()都属于Python list的排序方法,sort()属于永久性排列,直接改变该list; sorted属于暂时性排列,会产生一个新的序列。
#sorted()
>>> sorted([5, 2, 3, 1, 4])
[1, 2, 3, 4, 5]
#sort()
>>> L = [5, 2, 3, 1, 4]
>>> L.sort()
>>> print L
[1, 2, 3, 4, 5]
把一句话的每个单词按照开头的字母排序
'''
a = my_str.upper()
print(a)
b = a.split(' ') //将字符串进行切片。用‘ ’将其隔开
print(b)
b.sort() //将每个字符串按首字母排序。升序
print(b)
#your solution here
'''
#python list 排序def my_key1(x): return x % 10aList = [4, 5, 1, 2, 12, 34, 56, 9 ,80]aList.sort() #默认按升序排列print(aList)aList.sort(reverse = True) #按降序排列print(aList)#www.iplaypy.comaList.sort(key = my_key1) #根据key函数,按照个位数进行升序排列print(aList)def my_key2(x): return x[1]aList = [(4,'ab'), (56,'c'), (1,'bb'), (102, 'a')]aList.sort(key = my_key2) #按照每个元组的第2分量,即字符串排序print(aList)递归的特点:
- 必须有一个明确的结束条件,要不就会变成死循环了,最终撑爆系统
- 每次进入更深一层递归时,问题规模相比上次递归都应有所减少
- 递归执行效率不高,递归层次过多会导致栈溢出
 //阶层
//阶层
 //斐波拉契
//斐波拉契
 //用二分法找指定值。从中间开始找
//用二分法找指定值。从中间开始找
5、字符集
| 序号 | 年份 | 编码 | 标准协会 | 特点 | 二进制长度 | 字符长度 | 表现 |
| 1 | 1967 | ASCII | 美国国家标准学会 (American National Standard Institute , ANSI ) |
只能表示英文/数字/控制符符/现世符 不能表示中文 |
7位或8位二进制数组 | 1个字节 | 0~31,127(共33位)表示控制字符或者通信专用字符 32~126(共95为)表示字符,32是空格 48~57表示0~9个阿拉伯数字 65~90表示26个大写英文字母 97~122表示26个小写英文字母 其他表示标点符号和运算符号等 128~255是扩展ASCII,每个字符的第8位用于确定附加的128个特俗符号字符/图形/外来字母 |
| 2 | 1981 | GB2312 | 中国国家标准总局 | 可以表示中文,图形字符 古汉字不能支持 |
2组8进制位 | 2个字节 | 3755个一级汉字 3008个二级汉字 682个拉丁/希腊字母/日文片假名/片假名字母/俄语西里尔字母 |
| 3 | 1995 | GBK | 中华人民共和国 全国信息技术标准化技术委员会 |
兼容GB2312 windowns中文版系统的编码 |
2组8进制位 | 2个字节 | GB 2312 中的全部汉字、非汉字符号。 BIG5 中的全部汉字。 与 ISO 10646 相应的国家标准 GB 13000 中的其它 CJK 汉字,以上合计 20902 个汉字。 其它汉字、部首、符号,共计 984 个。 |
| 4 | 2001 | GB18030 | 信息产业部和国家质量技术监督局 | 1字节与ASCII兼容 2字节与DBK兼容 |
1/2/4个字节 | 70244多个,各种少数民族字符 | |
| 5 | 1994 | Unicode | 非营利机构统一码联盟 | 跨语言跨平台 英文浪费一半以上空间存储 |
至少2个字节 | 英文1个字节 中文2个字节 |
16位来统一表示所有的字符 原来8位全部扩充到16位 |
| 6 | 6 | UTF-8 | Ken Thompson RFC 3629 Unicode实现方式 |
伴随互联网出现 每次传输8位数据 使编码无国界 万国码 |
可变长 | ASCII1个字节 欧洲字符2个字节 中文3个字节 |
编码体积大 |
6、get命令
一: 初始化本地仓库,并提交内容到本地
需要先打开 命令行终端,然后通过 cd 命令切换到需要添加到github 的项目的目录下,然后依次执行如下命令, 具体命令及其含义如下:
1). touch README.md
创建说明文档,
2). git init
初始化本地仓库
3). git add .
添加全部已经修改的文件,准备commit 提交
该命令效果等同于 git add -A
4). git commit -m ‘提交说明’
将修改后的文件提交到本地仓库,如:git commit -m ‘增加README.md说明文档
二: 连接到远程仓库,并将代码同步到远程仓库
1). git remote add origin 远程仓库地址
连接到远程仓库并为该仓库创建别名 , 别名为origin . 这个别名是自定义的,通常用origin ; 远程仓库地址,就是你自己新建的那个仓库的地址,复制地址的方法参考 第二张图。
如:git remote add origin https://github.com/CnPeng/MyCustomAlertDialog.git 这段代码的含义是: 连接到github上https://github.com/CnPeng/MyCustomAlertDialog.git 这个仓库,并创建别名为origin . (之后push 或者pull 的时候就需要使用到这个 origin 别名)
2). git push -u origin master
创建一个 upStream (上传流),并将本地代码通过这个 upStream 推送到 别名为 origin 的仓库中的 master 分支上
-u ,就是创建 upStream 上传流,如果没有这个上传流就无法将代码推送到 github;同时,这个 upStream 只需要在初次推送代码的时候创建,以后就不用创建了
另外,在初次 push 代码的时候,可能会因为网络等原因导致命令行终端上的内容一直没有变化,耐心等待一会就好。
三:继续修改本地代码,然后提交并推送到github
做完上面三个步骤之后,就实现了将本地代码同步到github的功能,接下来要做的事情就是继续修改代码,然后提交并推送到github
1). git add .
添加全部修改的代码,准备提交
2). git commit -m ‘提交说明’
将修改后的代码先提交到本地仓库
3). git pull
如果是多人协作开发的话,一定要先 pull ,将 github 的代码拉取到本地,这样在 merge 解决冲突的时候稍微简便些。默认拉取到 master分支(如果只是自己做这个项目,可以忽略pull)
4). git push
将代码推送到 github , 默认推送到 别名为 origin 的仓库中的 master 分支上。
5). 注意事项:
如果有多个远程仓库 或者 多个分支, 并且需要将代码推送到指定仓库的指定分支上,那么在 pull 或者 push 的时候,就需要 按照下面的格式书写:
git pull 仓库别名 仓库分支名
7、with open
用python的时候,会经常遇到文件数据库的open,但总会不小心忘了close
用with open 语句就能很好的解决这个问题,它会在语句执行完后,自动执行close()
要以读文件的模式打开一个文件对象,使用Python内置的open()函数,传入文件名和标示符:
f = open('/Users/michael/test.txt', 'r') //文件地址,读写格式 ‘w’写格式 ‘rb’二进制 如果要读取非utf-8文本文件 后面还要加一个encoding='gbk'
如果文件打开成功,接下来,调用read()方法可以一次读取文件的全部内容,Python把内容读到内存,用一个str对象表示:
f.read() 'Hello, world!'
最后一步是调用close()方法关闭文件。文件使用完毕后必须关闭,因为文件对象会占用操作系统的资源,并且操作系统同一时间能打开的文件数量也是有限的:
f.close()
用with open用完了之后会自己调用close()方法
with open('/path/to/file', 'r') as f:
print(f.read())
8、列表的拆解
一、将大列表拆分为小列表
>>> a = [1,2,3,4,5,6,7,8,9,0]
>>> n = 3
>>> c= [a[i:i+n] for i in range(0, len(a), n)]
二、将大列表套小列表转化为一个列表

>>> a [[1], [2], [3]] >>> b = [] >>> [b.extend(li) for li in a] [None, None, None] >>> b [1, 2, 3]
9、解压赋值
* tuple ** dict
1.字符串解压

2.列表解压
