划重点,这是一道面试必考题,我靠这道题刷掉了多少面试者✧(≖ ◡ ≖✿)嘿嘿
首先这是一道非常棒的面试题,可以考察面试者的很多方面,比如基本功,代码能力,逻辑能力,而且进可攻,退可守,针对不同级别的人可以考察不同难度,比如漂亮妹子就出1☆题,要是个帅哥那就得上5☆了,(*^__^*) 嘻嘻……
无论面试者多么优秀,漂亮的回答出问题,我总能够潇洒的再抛出一个问题,看着面试者露出惊异的眼神,默默一转身,深藏功与名
本文我将给大家破解深拷贝的谜题,由浅入深,环环相扣,总共涉及4种深拷贝方式,每种方式都有自己的特点和个性
深拷贝 VS 浅拷贝
再开始之前需要先给同学科普下什么是深拷贝,和深拷贝有关系的另个一术语是浅拷贝又是什么意思呢?如果对这部分部分内容了解的同学可以跳过
其实深拷贝和浅拷贝都是针对的引用类型,JS中的变量类型分为值类型(基本类型)和引用类型;对值类型进行复制操作会对值进行一份拷贝,而对引用类型赋值,则会进行地址的拷贝,最终两个变量指向同一份数据
// 基本类型
var a = 1;
var b = a;
a = 2;
console.log(a, b); // 2, 1 ,a b指向不同的数据
// 引用类型指向同一份数据
var a = {c: 1};
var b = a;
a.c = 2;
console.log(a.c, b.c); // 2, 2 全是2,a b指向同一份数据
对于引用类型,会导致a b指向同一份数据,此时如果对其中一个进行修改,就会影响到另外一个,有时候这可能不是我们想要的结果,如果对这种现象不清楚的话,还可能造成不必要的bug
那么如何切断a和b之间的关系呢,可以拷贝一份a的数据,根据拷贝的层级不同可以分为浅拷贝和深拷贝,浅拷贝就是只进行一层拷贝,深拷贝就是无限层级拷贝
var a1 = {b: {c: {}};
var a2 = shallowClone(a1); // 浅拷贝
a2.b.c === a1.b.c // true
var a3 = clone(a3); // 深拷贝
a3.b.c === a1.b.c // false
浅拷贝的实现非常简单,而且还有多种方法,其实就是遍历对象属性的问题,这里只给出一种,如果看不懂下面的方法,或对其他方法感兴趣,可以看我的这篇文章
function shallowClone(source) {
var target = {};
for(var i in source) {
if (source.hasOwnProperty(i)) {
target[i] = source[i];
}
}
return target;
}
最简单的深拷贝
深拷贝的问题其实可以分解成两个问题,浅拷贝+递归,什么意思呢?假设我们有如下数据
var a1 = {b: {c: {d: 1}};
只需稍加改动上面浅拷贝的代码即可,注意区别
function clone(source) {
var target = {};
for(var i in source) {
if (source.hasOwnProperty(i)) {
if (typeof source[i] === 'object') {
target[i] = clone(source[i]); // 注意这里
} else {
target[i] = source[i];
}
}
}
return target;
}
大部分人都能写出上面的代码,但当我问上面的代码有什么问题吗?就很少有人答得上来了,聪明的你能找到问题吗?
其实上面的代码问题太多了,先来举几个例子吧
- 没有对参数做检验
- 判断是否对象的逻辑不够严谨
- 没有考虑数组的兼容
(⊙o⊙),下面我们来看看各个问题的解决办法,首先我们需要抽象一个判断对象的方法,其实比较常用的判断对象的方法如下,其实下面的方法也有问题,但如果能够回答上来那就非常不错了,如果完美的解决办法感兴趣,不妨看看这里吧
function isObject(x) {
return Object.prototype.toString.call(x) === '[object Object]';
}
函数需要校验参数,如果不是对象的话直接返回
function clone(source) {
if (!isObject(source)) return source;
// xxx
}
关于第三个问题,嗯,就留给大家自己思考吧,本文为了减轻大家的负担,就不考虑数组的情况了,其实ES6之后还要考虑set, map, weakset, weakmap,/(ㄒoㄒ)/~~
其实吧这三个都是小问题,其实递归方法最大的问题在于爆栈,当数据的层次很深是就会栈溢出
下面的代码可以生成指定深度和每层广度的代码,这段代码我们后面还会再次用到
function createData(deep, breadth) {
var data = {};
var temp = data;
for (var i = 0; i < deep; i++) {
temp = temp['data'] = {};
for (var j = 0; j < breadth; j++) {
temp[j] = j;
}
}
return data;
}
createData(1, 3); // 1层深度,每层有3个数据 {data: {0: 0, 1: 1, 2: 2}}
createData(3, 0); // 3层深度,每层有0个数据 {data: {data: {data: {}}}}
当clone层级很深的话就会栈溢出,但数据的广度不会造成溢出
clone(createData(1000)); // ok clone(createData(10000)); // Maximum call stack size exceeded clone(createData(10, 100000)); // ok 广度不会溢出
其实大部分情况下不会出现这么深层级的数据,但这种方式还有一个致命的问题,就是循环引用,举个例子
var a = {};
a.a = a;
clone(a) // Maximum call stack size exceeded 直接死循环了有没有,/(ㄒoㄒ)/~~
关于循环引用的问题解决思路有两种,一直是循环检测,一种是暴力破解,关于循环检测大家可以自己思考下;关于暴力破解我们会在下面的内容中详细讲解
一行代码的深拷贝
有些同学可能见过用系统自带的JSON来做深拷贝的例子,下面来看下代码实现
function cloneJSON(source) {
return JSON.parse(JSON.stringify(source));
}
其实我第一次简单这个方法的时候,由衷的表示佩服,其实利用工具,达到目的,是非常聪明的做法
下面来测试下cloneJSON有没有溢出的问题,看起来cloneJSON内部也是使用递归的方式
cloneJSON(createData(10000)); // Maximum call stack size exceeded
既然是用了递归,那循环引用呢?并没有因为死循环而导致栈溢出啊,原来是JSON.stringify内部做了循环引用的检测,正是我们上面提到破解循环引用的第一种方法:循环检测
var a = {};
a.a = a;
cloneJSON(a) // Uncaught TypeError: Converting circular structure to JSON
破解递归爆栈
其实破解递归爆栈的方法有两条路,第一种是消除尾递归,但在这个例子中貌似行不通,第二种方法就是干脆不用递归,改用循环,当我提出用循环来实现时,基本上90%的前端都是写不出来的代码的,这其实让我很震惊
举个例子,假设有如下的数据结构
var a = {
a1: 1,
a2: {
b1: 1,
b2: {
c1: 1
}
}
}
这不就是一个树吗,其实只要把数据横过来看就非常明显了
a
/
a1 a2
| /
1 b1 b2
| |
1 c1
|
1
用循环遍历一棵树,需要借助一个栈,当栈为空时就遍历完了,栈里面存储下一个需要拷贝的节点
首先我们往栈里放入种子数据,key用来存储放哪一个父元素的那一个子元素拷贝对象
然后遍历当前节点下的子元素,如果是对象就放到栈里,否则直接拷贝
function cloneLoop(x) {
const root = {};
// 栈
const loopList = [
{
parent: root,
key: undefined,
data: x,
}
];
while(loopList.length) {
// 深度优先
const node = loopList.pop();
const parent = node.parent;
const key = node.key;
const data = node.data;
// 初始化赋值目标,key为undefined则拷贝到父元素,否则拷贝到子元素
let res = parent;
if (typeof key !== 'undefined') {
res = parent[key] = {};
}
for(let k in data) {
if (data.hasOwnProperty(k)) {
if (typeof data[k] === 'object') {
// 下一次循环
loopList.push({
parent: res,
key: k,
data: data[k],
});
} else {
res[k] = data[k];
}
}
}
}
return root;
}
改用循环后,再也不会出现爆栈的问题了,但是对于循环引用依然无力应对
破解循环引用
有没有一种办法可以破解循环应用呢?别着急,我们先来看另一个问题,上面的三种方法都存在的一个问题就是引用丢失,这在某些情况下也许是不能接受的
举个例子,假如一个对象a,a下面的两个键值都引用同一个对象b,经过深拷贝后,a的两个键值会丢失引用关系,从而变成两个不同的对象,o(╯□╰)o
var b = 1;
var a = {a1: b, a2: b};
a.a1 === a.a2 // true
var c = clone(a);
c.a1 === c.a2 // false
如果我们发现个新对象就把这个对象和他的拷贝存下来,每次拷贝对象前,都先看一下这个对象是不是已经拷贝过了,如果拷贝过了,就不需要拷贝了,直接用原来的,这样我们就能够保留引用关系了,✧(≖ ◡ ≖✿)嘿嘿
但是代码怎么写呢,o(╯□╰)o,别急往下看,其实和循环的代码大体一样,不一样的地方我用// ==========标注出来了
引入一个数组uniqueList用来存储已经拷贝的数组,每次循环遍历时,先判断对象是否在uniqueList中了,如果在的话就不执行拷贝逻辑了
find是抽象的一个函数,其实就是遍历uniqueList
// 保持引用关系
function cloneForce(x) {
// =============
const uniqueList = []; // 用来去重
// =============
let root = {};
// 循环数组
const loopList = [
{
parent: root,
key: undefined,
data: x,
}
];
while(loopList.length) {
// 深度优先
const node = loopList.pop();
const parent = node.parent;
const key = node.key;
const data = node.data;
// 初始化赋值目标,key为undefined则拷贝到父元素,否则拷贝到子元素
let res = parent;
if (typeof key !== 'undefined') {
res = parent[key] = {};
}
// =============
// 数据已经存在
let uniqueData = find(uniqueList, data);
if (uniqueData) {
parent[key] = uniqueData.target;
break; // 中断本次循环
}
// 数据不存在
// 保存源数据,在拷贝数据中对应的引用
uniqueList.push({
source: data,
target: res,
});
// =============
for(let k in data) {
if (data.hasOwnProperty(k)) {
if (typeof data[k] === 'object') {
// 下一次循环
loopList.push({
parent: res,
key: k,
data: data[k],
});
} else {
res[k] = data[k];
}
}
}
}
return root;
}
function find(arr, item) {
for(let i = 0; i < arr.length; i++) {
if (arr[i].source === item) {
return arr[i];
}
}
return null;
}
下面来验证一下效果,amazing
var b = 1;
var a = {a1: b, a2: b};
a.a1 === a.a2 // true
var c = cloneForce(a);
c.a1 === c.a2 // true
接下来再说一下如何破解循环引用,等一下,上面的代码好像可以破解循环引用啊,赶紧验证一下
惊不惊喜,(*^__^*) 嘻嘻……
var a = {};
a.a = a;
cloneForce(a)
看起来完美的cloneForce是不是就没问题呢?cloneForce有两个问题
第一个问题,所谓成也萧何,败也萧何,如果保持引用不是你想要的,那就不能用cloneForce了;
第二个问题,cloneForce在对象数量很多时会出现很大的问题,如果数据量很大不适合使用cloneForce
性能对比
上边的内容还是有点难度,下面我们来点更有难度的,对比一下不同方法的性能
我们先来做实验,看数据,影响性能的原因有两个,一个是深度,一个是每层的广度,我们采用固定一个变量,只让一个变量变化的方式来测试性能
测试的方法是在指定的时间内,深拷贝执行的次数,次数越多,证明性能越好
下面的runTime是测试代码的核心片段,下面的例子中,我们可以测试在2秒内运行clone(createData(500, 1)的次数
function runTime(fn, time) {
var stime = Date.now();
var count = 0;
while(Date.now() - stime < time) {
fn();
count++;
}
return count;
}
runTime(function () { clone(createData(500, 1)) }, 2000);
下面来做第一个测试,将广度固定在100,深度由小到大变化,记录1秒内执行的次数
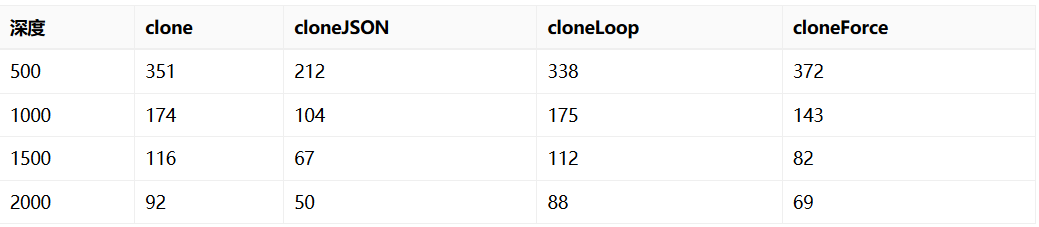
将上面的数据做成表格可以发现,一些规律
- 随着深度变小,相互之间的差异在变小
- clone和cloneLoop的差别并不大
- cloneLoop > cloneForce > cloneJSON
我们先来分析下各个方法的时间复杂度问题,各个方法要做的相同事情,这里就不计算,比如循环对象,判断是否为对象
- clone时间 = 创建递归函数 + 每个对象处理时间
- cloneJSON时间 = 循环检测 + 每个对象处理时间 * 2 (递归转字符串 + 递归解析)
- cloneLoop时间 = 每个对象处理时间
- cloneForce时间 = 判断对象是否缓存中 + 每个对象处理时间
cloneJSON的速度只有clone的50%,很容易理解,因为其会多进行一次递归时间
cloneForce由于要判断对象是否在缓存中,而导致速度变慢,我们来计算下判断逻辑的时间复杂度,假设对象的个数是n,则其时间复杂度为O(n2),对象的个数越多,cloneForce的速度会越慢
1 + 2 + 3 ... + n = n^2/2 - 1
关于clone和cloneLoop这里有一点问题,看起来实验结果和推理结果不一致,其中必有蹊跷
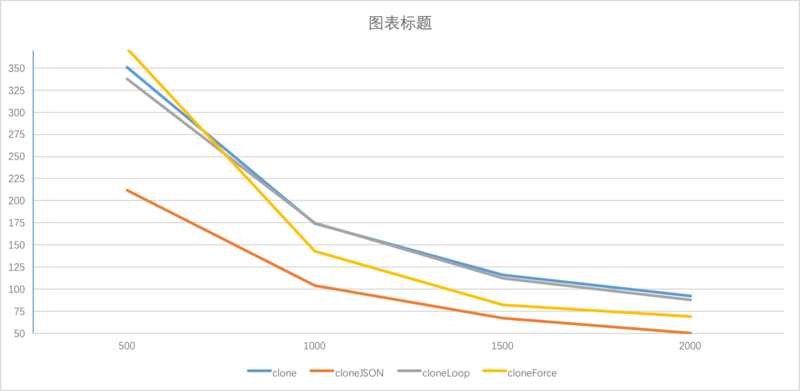
接下来做第二个测试,将深度固定在10000,广度固定为0,记录2秒内执行的次数

排除宽度的干扰,来看看深度对各个方法的影响
- 随着对象的增多,cloneForce的性能低下凸显
- cloneJSON的性能也大打折扣,这是因为循环检测占用了很多时间
- cloneLoop的性能高于clone,可以看出递归新建函数的时间和循环对象比起来可以忽略不计
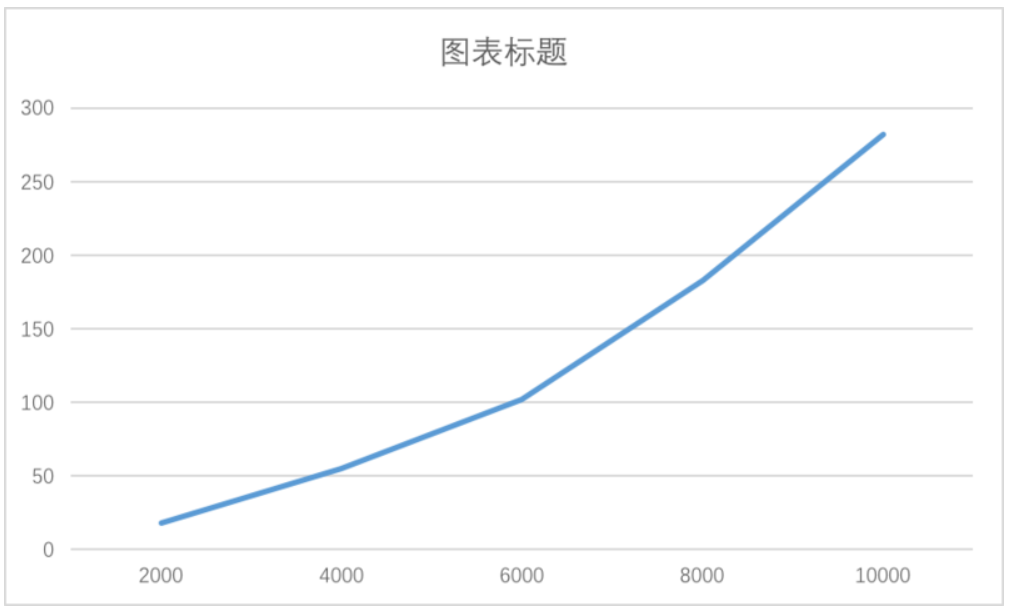
下面我们来测试一下cloneForce的性能极限,这次我们测试运行指定次数需要的时间
var data1 = createData(2000, 0); var data2 = createData(4000, 0); var data3 = createData(6000, 0); var data4 = createData(8000, 0); var data5 = createData(10000, 0); cloneForce(data1) cloneForce(data2) cloneForce(data3) cloneForce(data4) cloneForce(data5)
通过测试发现,其时间成指数级增长,当对象个数大于万级别,就会有300ms以上的延迟
总结
尺有所短寸有所长,无关乎好坏优劣,其实每种方法都有自己的优缺点,和适用场景,人尽其才,物尽其用,方是真理
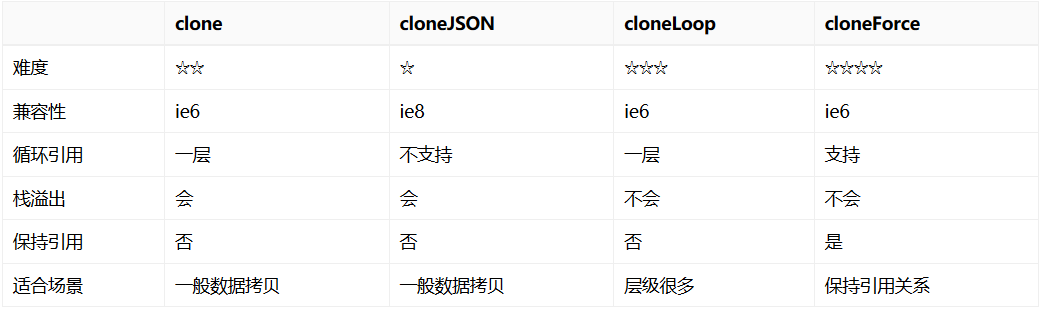
下面对各种方法进行对比,希望给大家提供一些帮助
本文的灵感都来自于@jsmini/clone,如果大家想使用文中的4种深拷贝方式,可以直接使用@jsmini/clone这个库
// npm install --save @jsmini/clone
import { clone, cloneJSON, cloneLoop, cloneForce } from '@jsmini/clone';
本文为了简单和易读,示例代码中忽略了一些边界情况,如果想学习生产中的代码,请阅读@jsmini/clone的源码
刷掉了多少面试者✧(≖ ◡ ≖✿)嘿嘿
首先这是一道非常棒的面试题,可以考察面试者的很多方面,比如基本功,代码能力,逻辑能力,而且进可攻,退可守,针对不同级别的人可以考察不同难度,比如漂亮妹子就出1☆题,要是个帅哥那就得上5☆了,(*^__^*) 嘻嘻……
无论面试者多么优秀,漂亮的回答出问题,我总能够潇洒的再抛出一个问题,看着面试者露出惊异的眼神,默默一转身,深藏功与名
本文我将给大家破解深拷贝的谜题,由浅入深,环环相扣,总共涉及4种深拷贝方式,每种方式都有自己的特点和个性
深拷贝 VS 浅拷贝
再开始之前需要先给同学科普下什么是深拷贝,和深拷贝有关系的另个一术语是浅拷贝又是什么意思呢?如果对这部分部分内容了解的同学可以跳过
其实深拷贝和浅拷贝都是针对的引用类型,JS中的变量类型分为值类型(基本类型)和引用类型;对值类型进行复制操作会对值进行一份拷贝,而对引用类型赋值,则会进行地址的拷贝,最终两个变量指向同一份数据
// 基本类型var a = 1;var b = a;a = 2;console.log(a, b); // 2, 1 ,a b指向不同的数据// 引用类型指向同一份数据var a = {c: 1};var b = a;a.c = 2;console.log(a.c, b.c); // 2, 2 全是2,a b指向同一份数据 |
对于引用类型,会导致a b指向同一份数据,此时如果对其中一个进行修改,就会影响到另外一个,有时候这可能不是我们想要的结果,如果对这种现象不清楚的话,还可能造成不必要的bug
那么如何切断a和b之间的关系呢,可以拷贝一份a的数据,根据拷贝的层级不同可以分为浅拷贝和深拷贝,浅拷贝就是只进行一层拷贝,深拷贝就是无限层级拷贝
var a1 = {b: {c: {}};var a2 = shallowClone(a1); // 浅拷贝a2.b.c === a1.b.c // truevar a3 = clone(a3); // 深拷贝a3.b.c === a1.b.c // false |
浅拷贝的实现非常简单,而且还有多种方法,其实就是遍历对象属性的问题,这里只给出一种,如果看不懂下面的方法,或对其他方法感兴趣,可以看我的这篇文章
function shallowClone(source) { var target = {}; for(var i in source) { if (source.hasOwnProperty(i)) { target[i] = source[i]; } } return target;} |
最简单的深拷贝
深拷贝的问题其实可以分解成两个问题,浅拷贝+递归,什么意思呢?假设我们有如下数据
var a1 = {b: {c: {d: 1}}; |
只需稍加改动上面浅拷贝的代码即可,注意区别
function clone(source) { var target = {}; for(var i in source) { if (source.hasOwnProperty(i)) { if (typeof source[i] === 'object') { target[i] = clone(source[i]); // 注意这里 } else { target[i] = source[i]; } } } return target;} |
大部分人都能写出上面的代码,但当我问上面的代码有什么问题吗?就很少有人答得上来了,聪明的你能找到问题吗?
其实上面的代码问题太多了,先来举几个例子吧
- 没有对参数做检验
- 判断是否对象的逻辑不够严谨
- 没有考虑数组的兼容
(⊙o⊙),下面我们来看看各个问题的解决办法,首先我们需要抽象一个判断对象的方法,其实比较常用的判断对象的方法如下,其实下面的方法也有问题,但如果能够回答上来那就非常不错了,如果完美的解决办法感兴趣,不妨看看这里吧
function isObject(x) { return Object.prototype.toString.call(x) === '[object Object]';} |
函数需要校验参数,如果不是对象的话直接返回
function clone(source) { if (!isObject(source)) return source; // xxx} |
关于第三个问题,嗯,就留给大家自己思考吧,本文为了减轻大家的负担,就不考虑数组的情况了,其实ES6之后还要考虑set, map, weakset, weakmap,/(ㄒoㄒ)/~~
其实吧这三个都是小问题,其实递归方法最大的问题在于爆栈,当数据的层次很深是就会栈溢出
下面的代码可以生成指定深度和每层广度的代码,这段代码我们后面还会再次用到
function createData(deep, breadth) { var data = {}; var temp = data; for (var i = 0; i < deep; i++) { temp = temp['data'] = {}; for (var j = 0; j < breadth; j++) { temp[j] = j; } } return data;}createData(1, 3); // 1层深度,每层有3个数据 {data: {0: 0, 1: 1, 2: 2}}createData(3, 0); // 3层深度,每层有0个数据 {data: {data: {data: {}}}} |
当clone层级很深的话就会栈溢出,但数据的广度不会造成溢出
clone(createData(1000)); // okclone(createData(10000)); // Maximum call stack size exceededclone(createData(10, 100000)); // ok 广度不会溢出 |
其实大部分情况下不会出现这么深层级的数据,但这种方式还有一个致命的问题,就是循环引用,举个例子
var a = {};a.a = a;clone(a) // Maximum call stack size exceeded 直接死循环了有没有,/(ㄒoㄒ)/~~ |
关于循环引用的问题解决思路有两种,一直是循环检测,一种是暴力破解,关于循环检测大家可以自己思考下;关于暴力破解我们会在下面的内容中详细讲解
一行代码的深拷贝
有些同学可能见过用系统自带的JSON来做深拷贝的例子,下面来看下代码实现
function cloneJSON(source) { return JSON.parse(JSON.stringify(source));} |
其实我第一次简单这个方法的时候,由衷的表示佩服,其实利用工具,达到目的,是非常聪明的做法
下面来测试下cloneJSON有没有溢出的问题,看起来cloneJSON内部也是使用递归的方式
cloneJSON(createData(10000)); // Maximum call stack size exceeded |
既然是用了递归,那循环引用呢?并没有因为死循环而导致栈溢出啊,原来是JSON.stringify内部做了循环引用的检测,正是我们上面提到破解循环引用的第一种方法:循环检测
var a = {};a.a = a;cloneJSON(a) // Uncaught TypeError: Converting circular structure to JSON |
破解递归爆栈
其实破解递归爆栈的方法有两条路,第一种是消除尾递归,但在这个例子中貌似行不通,第二种方法就是干脆不用递归,改用循环,当我提出用循环来实现时,基本上90%的前端都是写不出来的代码的,这其实让我很震惊
举个例子,假设有如下的数据结构
var a = { a1: 1, a2: { b1: 1, b2: { c1: 1 } }} |
这不就是一个树吗,其实只要把数据横过来看就非常明显了
a / a1 a2 | / 1 b1 b2 | | 1 c1 | 1 |
用循环遍历一棵树,需要借助一个栈,当栈为空时就遍历完了,栈里面存储下一个需要拷贝的节点
首先我们往栈里放入种子数据,key用来存储放哪一个父元素的那一个子元素拷贝对象
然后遍历当前节点下的子元素,如果是对象就放到栈里,否则直接拷贝
function cloneLoop(x) { const root = {}; // 栈 const loopList = [ { parent: root, key: undefined, data: x, } ]; while(loopList.length) { // 深度优先 const node = loopList.pop(); const parent = node.parent; const key = node.key; const data = node.data; // 初始化赋值目标,key为undefined则拷贝到父元素,否则拷贝到子元素 let res = parent; if (typeof key !== 'undefined') { res = parent[key] = {}; } for(let k in data) { if (data.hasOwnProperty(k)) { if (typeof data[k] === 'object') { // 下一次循环 loopList.push({ parent: res, key: k, data: data[k], }); } else { res[k] = data[k]; } } } } return root;} |
改用循环后,再也不会出现爆栈的问题了,但是对于循环引用依然无力应对
破解循环引用
有没有一种办法可以破解循环应用呢?别着急,我们先来看另一个问题,上面的三种方法都存在的一个问题就是引用丢失,这在某些情况下也许是不能接受的
举个例子,假如一个对象a,a下面的两个键值都引用同一个对象b,经过深拷贝后,a的两个键值会丢失引用关系,从而变成两个不同的对象,o(╯□╰)o
var b = 1;var a = {a1: b, a2: b};a.a1 === a.a2 // truevar c = clone(a);c.a1 === c.a2 // false |
如果我们发现个新对象就把这个对象和他的拷贝存下来,每次拷贝对象前,都先看一下这个对象是不是已经拷贝过了,如果拷贝过了,就不需要拷贝了,直接用原来的,这样我们就能够保留引用关系了,✧(≖ ◡ ≖✿)嘿嘿
但是代码怎么写呢,o(╯□╰)o,别急往下看,其实和循环的代码大体一样,不一样的地方我用// ==========标注出来了
引入一个数组uniqueList用来存储已经拷贝的数组,每次循环遍历时,先判断对象是否在uniqueList中了,如果在的话就不执行拷贝逻辑了
find是抽象的一个函数,其实就是遍历uniqueList
// 保持引用关系function cloneForce(x) { // ============= const uniqueList = []; // 用来去重 // ============= let root = {}; // 循环数组 const loopList = [ { parent: root, key: undefined, data: x, } ]; while(loopList.length) { // 深度优先 const node = loopList.pop(); const parent = node.parent; const key = node.key; const data = node.data; // 初始化赋值目标,key为undefined则拷贝到父元素,否则拷贝到子元素 let res = parent; if (typeof key !== 'undefined') { res = parent[key] = {}; } // ============= // 数据已经存在 let uniqueData = find(uniqueList, data); if (uniqueData) { parent[key] = uniqueData.target; break; // 中断本次循环 } // 数据不存在 // 保存源数据,在拷贝数据中对应的引用 uniqueList.push({ source: data, target: res, }); // ============= for(let k in data) { if (data.hasOwnProperty(k)) { if (typeof data[k] === 'object') { // 下一次循环 loopList.push({ parent: res, key: k, data: data[k], }); } else { res[k] = data[k]; } } } } return root;}function find(arr, item) { for(let i = 0; i < arr.length; i++) { if (arr[i].source === item) { return arr[i]; } } return null;} |
下面来验证一下效果,amazing
var b = 1;var a = {a1: b, a2: b};a.a1 === a.a2 // truevar c = cloneForce(a);c.a1 === c.a2 // true |
接下来再说一下如何破解循环引用,等一下,上面的代码好像可以破解循环引用啊,赶紧验证一下
惊不惊喜,(*^__^*) 嘻嘻……
var a = {};a.a = a;cloneForce(a) |
看起来完美的cloneForce是不是就没问题呢?cloneForce有两个问题
第一个问题,所谓成也萧何,败也萧何,如果保持引用不是你想要的,那就不能用cloneForce了;
第二个问题,cloneForce在对象数量很多时会出现很大的问题,如果数据量很大不适合使用cloneForce
性能对比
上边的内容还是有点难度,下面我们来点更有难度的,对比一下不同方法的性能
我们先来做实验,看数据,影响性能的原因有两个,一个是深度,一个是每层的广度,我们采用固定一个变量,只让一个变量变化的方式来测试性能
测试的方法是在指定的时间内,深拷贝执行的次数,次数越多,证明性能越好
下面的runTime是测试代码的核心片段,下面的例子中,我们可以测试在2秒内运行clone(createData(500, 1)的次数
function runTime(fn, time) { var stime = Date.now(); var count = 0; while(Date.now() - stime < time) { fn(); count++; } return count;}runTime(function () { clone(createData(500, 1)) }, 2000); |
下面来做第一个测试,将广度固定在100,深度由小到大变化,记录1秒内执行的次数
| 深度 | clone | cloneJSON | cloneLoop | cloneForce |
|---|---|---|---|---|
| 500 | 351 | 212 | 338 | 372 |
| 1000 | 174 | 104 | 175 | 143 |
| 1500 | 116 | 67 | 112 | 82 |
| 2000 | 92 | 50 | 88 | 69 |
将上面的数据做成表格可以发现,一些规律
- 随着深度变小,相互之间的差异在变小
- clone和cloneLoop的差别并不大
- cloneLoop > cloneForce > cloneJSON

我们先来分析下各个方法的时间复杂度问题,各个方法要做的相同事情,这里就不计算,比如循环对象,判断是否为对象
- clone时间 = 创建递归函数 + 每个对象处理时间
- cloneJSON时间 = 循环检测 + 每个对象处理时间 * 2 (递归转字符串 + 递归解析)
- cloneLoop时间 = 每个对象处理时间
- cloneForce时间 = 判断对象是否缓存中 + 每个对象处理时间
cloneJSON的速度只有clone的50%,很容易理解,因为其会多进行一次递归时间
cloneForce由于要判断对象是否在缓存中,而导致速度变慢,我们来计算下判断逻辑的时间复杂度,假设对象的个数是n,则其时间复杂度为O(n2),对象的个数越多,cloneForce的速度会越慢
1 + 2 + 3 ... + n = n^2/2 - 1 |
关于clone和cloneLoop这里有一点问题,看起来实验结果和推理结果不一致,其中必有蹊跷
接下来做第二个测试,将深度固定在10000,广度固定为0,记录2秒内执行的次数
| 宽度 | clone | cloneJSON | cloneLoop | cloneForce |
|---|---|---|---|---|
| 0 | 13400 | 3272 | 14292 | 989 |
排除宽度的干扰,来看看深度对各个方法的影响
- 随着对象的增多,cloneForce的性能低下凸显
- cloneJSON的性能也大打折扣,这是因为循环检测占用了很多时间
- cloneLoop的性能高于clone,可以看出递归新建函数的时间和循环对象比起来可以忽略不计
下面我们来测试一下cloneForce的性能极限,这次我们测试运行指定次数需要的时间
var data1 = createData(2000, 0);var data2 = createData(4000, 0);var data3 = createData(6000, 0);var data4 = createData(8000, 0);var data5 = createData(10000, 0);cloneForce(data1)cloneForce(data2)cloneForce(data3)cloneForce(data4)cloneForce(data5) |
通过测试发现,其时间成指数级增长,当对象个数大于万级别,就会有300ms以上的延迟

总结
尺有所短寸有所长,无关乎好坏优劣,其实每种方法都有自己的优缺点,和适用场景,人尽其才,物尽其用,方是真理
下面对各种方法进行对比,希望给大家提供一些帮助
| clone | cloneJSON | cloneLoop | cloneForce | |
|---|---|---|---|---|
| 难度 | ☆☆ | ☆ | ☆☆☆ | ☆☆☆☆ |
| 兼容性 | ie6 | ie8 | ie6 | ie6 |
| 循环引用 | 一层 | 不支持 | 一层 | 支持 |
| 栈溢出 | 会 | 会 | 不会 | 不会 |
| 保持引用 | 否 | 否 | 否 | 是 |
| 适合场景 | 一般数据拷贝 | 一般数据拷贝 | 层级很多 | 保持引用关系 |
本文的灵感都来自于@jsmini/clone,如果大家想使用文中的4种深拷贝方式,可以直接使用@jsmini/clone这个库
// npm install --save @jsmini/cloneimport { clone, cloneJSON, cloneLoop, cloneForce } from '@jsmini/clone'; |
本文为了简单和易读,示例代码中忽略了一些边界情况,如果想学习生产中的代码,请阅读@jsmini/clone的源码