做deep-sort多目标跟踪需要结合yolo_v3进行检测行人
由于我的项目中需要对人脸进行检测,所以需要训练针对人脸的模型
训练样本是来自WIDER-FACE人脸库。(有3w+的图片和标注框)
deep-sort结合yolo-v3的博客分享
https://blog.csdn.net/weixin_42755375/article/details/85723239
分享一篇博客(按照博客要求 可以完美训练自己的人脸模型)
https://blog.csdn.net/caroline_wendy/article/details/80924371
图一 使用原始模型, 图二使用新训练人脸模型


----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
如果不是使用人脸数据,而是自己的数据或voc格式数据,步骤其实差不多,只是得到train.txt的过程不一样,这里给出方法。
首先需要得到train.txt的py文件 voc_annotation.py
1 import xml.etree.ElementTree as ET 2 from os import getcwd 3 4 import sys 5 sys.path.append("/var/Data/pcr/ljf/project/rubbish_faster_rcnn/data/VOCself") 6 print(sys.path) 7 root_data="/var/Data/pcr/ljf/project/rubbish_faster_rcnn/data/" 8 sets=[('self', 'train'), ('self', 'val'), ('self', 'test')] 9 10 classes = ["trash"] 11 12 13 def convert_annotation(year, image_id, list_file): 14 in_file = open(root_data+'VOC%s/Annotations/%s.xml'%(year, image_id)) 15 tree=ET.parse(in_file) 16 root = tree.getroot() 17 18 for obj in root.iter('object'): 19 difficult = obj.find('difficult').text 20 cls = obj.find('name').text 21 if cls not in classes or int(difficult)==1: 22 continue 23 cls_id = classes.index(cls) 24 xmlbox = obj.find('bndbox') 25 b = (int(xmlbox.find('xmin').text), int(xmlbox.find('ymin').text), int(xmlbox.find('xmax').text), int(xmlbox.find('ymax').text)) 26 list_file.write(" " + ",".join([str(a) for a in b]) + ',' + str(cls_id)) 27 28 wd = getcwd() 29 30 for year, image_set in sets: 31 image_ids = open(root_data+'VOC%s/ImageSets/Main/%s.txt'%(year, image_set)).read().strip().split() 32 list_file = open('%s_%s.txt'%(year, image_set), 'w') 33 for image_id in image_ids: 34 # list_file.write('%s/VOC%s/JPEGImages/%s.jpg' % (wd, year, image_id)) 35 list_file.write('%sVOC%s/JPEGImages/%s.jpg'%(root_data, year, image_id)) 36 convert_annotation(year, image_id, list_file) 37 list_file.write(' ') 38 list_file.close()
注意:一开始VOC2007,也可以叫VOC2008之类,这样此处的txt就会成为2008_xxx.txt。此外,有一个很关键的地方需要注意,必须修改,不然此处生成的三个新的txt文件中仅仅比前面Main下的txt中多了图片路径而已,并不包含框box的信息,这样的话在后面的训练步骤,由于没有框的信息,仅仅是图片路径和名称信息,是训练不好的,即使可以得到训练后的h5文件,但是当用这样的h5文件去执行类似前面所说的测试图片识别,效果就是将整幅图框住,而不是框住你所要识别的部分。
故所要做的是:在执行voc_annotation.py之前,打开它,进行修改。将其中最上面的sets改为你自己的,比如2012改为我得2007,要和前面的目录年份保持一致。还需要将最上面的classes中的内容,改为你自己xml文件中object属性中name属性的值。你有哪些name值,就改为哪些,不然其中读取xml框信息的代码就不会执行。
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
最后是anchor值得获取,在训练自己得数据集时,不同的数据集有不同的anchor值,为9对数字。
在得到上一步的train.txt的基础上, 使用kmeans.py文件就可以得到anchor值
1 import numpy as np 2 3 4 class YOLO_Kmeans: 5 6 def __init__(self, cluster_number, filename): 7 self.cluster_number = cluster_number 8 self.filename = r"./self_train.txt" 9 10 def iou(self, boxes, clusters): # 1 box -> k clusters 11 n = boxes.shape[0] 12 k = self.cluster_number 13 14 box_area = boxes[:, 0] * boxes[:, 1] 15 box_area = box_area.repeat(k) 16 box_area = np.reshape(box_area, (n, k)) 17 18 cluster_area = clusters[:, 0] * clusters[:, 1] 19 cluster_area = np.tile(cluster_area, [1, n]) 20 cluster_area = np.reshape(cluster_area, (n, k)) 21 22 box_w_matrix = np.reshape(boxes[:, 0].repeat(k), (n, k)) 23 cluster_w_matrix = np.reshape(np.tile(clusters[:, 0], (1, n)), (n, k)) 24 min_w_matrix = np.minimum(cluster_w_matrix, box_w_matrix) 25 26 box_h_matrix = np.reshape(boxes[:, 1].repeat(k), (n, k)) 27 cluster_h_matrix = np.reshape(np.tile(clusters[:, 1], (1, n)), (n, k)) 28 min_h_matrix = np.minimum(cluster_h_matrix, box_h_matrix) 29 inter_area = np.multiply(min_w_matrix, min_h_matrix) 30 31 result = inter_area / (box_area + cluster_area - inter_area) 32 return result 33 34 def avg_iou(self, boxes, clusters): 35 accuracy = np.mean([np.max(self.iou(boxes, clusters), axis=1)]) 36 return accuracy 37 38 def kmeans(self, boxes, k, dist=np.median): 39 box_number = boxes.shape[0] 40 distances = np.empty((box_number, k)) 41 last_nearest = np.zeros((box_number,)) 42 np.random.seed() 43 clusters = boxes[np.random.choice( 44 box_number, k, replace=False)] # init k clusters 45 while True: 46 47 distances = 1 - self.iou(boxes, clusters) 48 49 current_nearest = np.argmin(distances, axis=1) 50 if (last_nearest == current_nearest).all(): 51 break # clusters won't change 52 for cluster in range(k): 53 clusters[cluster] = dist( # update clusters 54 boxes[current_nearest == cluster], axis=0) 55 56 last_nearest = current_nearest 57 58 return clusters 59 60 def result2txt(self, data): 61 f = open("yolo_anchors.txt", 'w') 62 row = np.shape(data)[0] 63 for i in range(row): 64 if i == 0: 65 x_y = "%d,%d" % (data[i][0], data[i][1]) 66 else: 67 x_y = ", %d,%d" % (data[i][0], data[i][1]) 68 f.write(x_y) 69 f.close() 70 71 def txt2boxes(self): 72 f = open(self.filename, 'r') 73 dataSet = [] 74 for line in f: 75 infos = line.split(" ") 76 print(infos) 77 length = len(infos) 78 for i in range(1, length): 79 width = int(infos[i].split(",")[2]) - 80 int(infos[i].split(",")[0]) 81 height = int(infos[i].split(",")[3]) - 82 int(infos[i].split(",")[1]) 83 dataSet.append([width, height]) 84 result = np.array(dataSet) 85 f.close() 86 return result 87 88 def txt2clusters(self): 89 all_boxes = self.txt2boxes() 90 print(all_boxes) 91 result = self.kmeans(all_boxes, k=self.cluster_number) 92 result = result[np.lexsort(result.T[0, None])] 93 self.result2txt(result) 94 print("K anchors: {}".format(result)) 95 print("Accuracy: {:.2f}%".format( 96 self.avg_iou(all_boxes, result) * 100)) 97 98 99 if __name__ == "__main__": 100 cluster_number = 9 101 filename = r"../self_trainval.txt" 102 kmeans = YOLO_Kmeans(cluster_number, filename) 103 kmeans.txt2clusters()
使用方法:修改第8行 self.filename的值为自己得到的train.txt文件
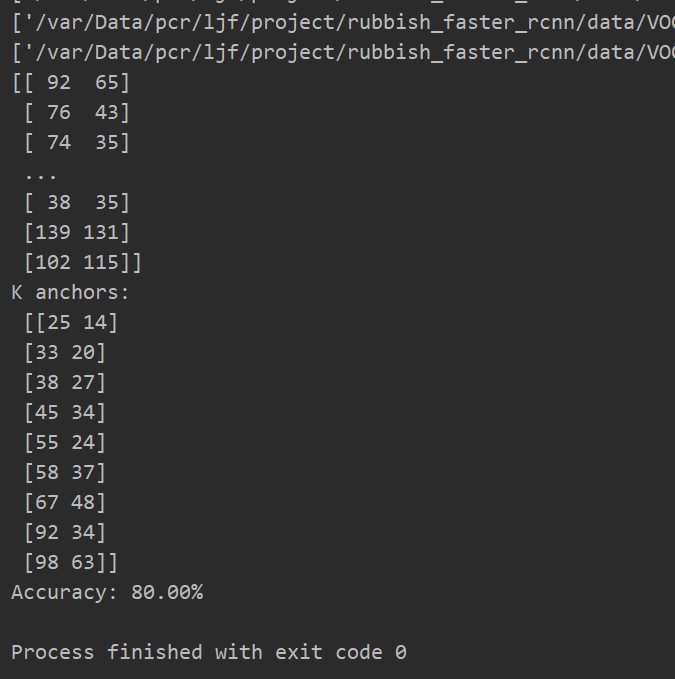
最后如下 anchor为
[25 14]
[33 20]
[38 27]
[45 34]
[55 24]
[58 37]
[67 48]
[92 34]
[98 63]
参考:https://blog.csdn.net/m0_37857151/article/details/81330699