概述
本人在java开发过程中,有些知识点需要记录整理,我尽量严谨的叙述我学习的经过和心得,以便备份和和大家一起进步学习,此篇文章是在网上多出搜集整理验证,结尾会注明出处,今天学习一个java8新的功能Stream,严格来说stream是对集合对象功能的增强,它专注于对集合对象进行各种非常便利、高效的聚合操作(aggregate operation),或者大批量数据操作。Stream API借助于新出现的Lambda 表达式,极大的提高编程效率和程序可读性。同时它提供了串行和并行两种模式进行汇聚操作,并发模式能充分利用多核处理器的优势,使用fork/join并行方式来拆分任务和加速处理过程,stream可以很方便写出高性能的并发程序。所以说,Java 8 中首次出现的 java.util.stream 是一个函数式语言+多核时代综合影响的产物。
STREAM简介
Stream 不是集合元素,它不是数据结构并不保存数据,它是有关算法和计算的,它更像一个高级版本的 Iterator。原始版本的 Iterator,用户只能显式地一个一个遍历元素并对其执行某些操作;高级版本的 Stream,用户只要给出需要对其包含的元素执行什么操作,比如 “过滤掉长度大于 10 的字符串”、“获取每个字符串的首字母”等,Stream 会隐式地在内部进行遍历,做出相应的数据转换。
Stream 就如同一个迭代器(Iterator),单向,不可往复,数据只能遍历一次,遍历过一次后即用尽了,就好比流水从面前流过,一去不复返。
而和迭代器又不同的是,Stream 可以并行化操作,迭代器只能命令式地、串行化操作。顾名思义,当使用串行方式去遍历时,每个 item 读完后再读下一个 item。而使用并行去遍历时,数据会被分成多个段,其中每一个都在不同的线程中处理,然后将结果一起输出。Stream 的并行操作依赖于 Java7 中引入的 Fork/Join 框架(JSR166y)来拆分任务和加速处理过程。Java 的并行 API 演变历程基本如下:
1.0-1.4 中的 java.lang.Thread
5.0 中的 java.util.concurrent
6.0 中的 Phasers 等
7.0 中的 Fork/Join 框架
8.0 中的 Lambda
Stream 的另外一大特点是,数据源本身可以是无限的。
STREAM的构成
当我们使用一个流的时候,通常包含三个基本步骤:
获取一个数据源(source)→ 数据转换→执行操作获取想要的结果,每次转换原有 Stream 对象不改变,返回一个新的 Stream 对象(可以有多次转换),这就允许对其操作可以像链条一样排列,变成一个管道,如下图所示:
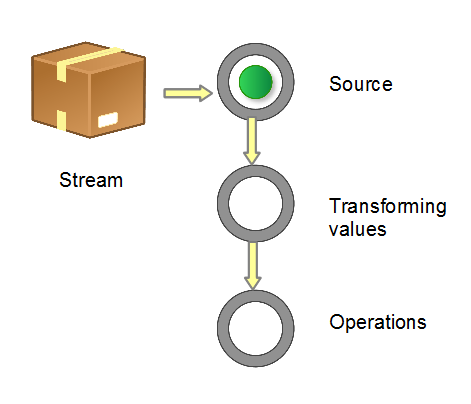
流的操作类型包括2种:
中间操作(Intermediate):一个流可以后面跟随零个或多个 intermediate 操作。其目的主要是打开流,做出某种程度的数据映射/过滤,然后返回一个新的流,交给下一个操作使用。这类操作都是惰性化的(lazy),就是说,仅仅调用到这类方法,并没有真正开始流的遍历。
结束操作(Terminal):一个流只能有一个 terminal 操作,当这个操作执行后,流就被使用“光”了,无法再被操作。所以这必定是流的最后一个操作。Terminal 操作的执行,才会真正开始流的遍历,并且会生成一个结果,或者一个 side effect。
在对于一个 Stream 进行多次转换操作 (Intermediate 操作),每次都对 Stream 的每个元素进行转换,而且是执行多次,这样时间复杂度就是 N(转换次数)个 for 循环里把所有操作都做掉的总和吗?其实不是这样的,转换操作都是 lazy 的,多个转换操作只会在 Terminal 操作的时候融合起来,一次循环完成。我们可以这样简单的理解,Stream 里有个操作函数的集合,每次转换操作就是把转换函数放入这个集合中,在 Terminal 操作的时候循环 Stream 对应的集合,然后对每个元素执行所有的函数。
还有一种操作叫做short-circuiting。用以指:
对于一个 intermediate 操作,如果它接受的是一个无限大(infinite/unbounded)的 Stream,但返回一个有限的新 Stream。
对于一个 terminal 操作,如果它接受的是一个无限大的 Stream,但能在有限的时间计算出结果。
当操作一个无限大的 Stream,而又希望在有限时间内完成操作,则在管道内拥有一个 short-circuiting 操作是必要非充分条件。
举例说明:
int sum = widgets.stream() .filter(w -> w.getColor() == RED) .mapToInt(w -> w.getWeight()) .sum();
stream() 获取当前小物件的 source,filter 和 mapToInt 为 intermediate 操作,进行数据筛选和转换,最后一个 sum() 为 terminal 操作,对符合条件的全部小物件作重量求和。
STREAM的使用
简单说,对 Stream 的使用就是实现一个 filter-map-reduce 过程,产生一个最终结果,或者导致一个副作用(side effect)。
STREAM的构造和转换
构造流的几种常见方法:
// 1. Individual values
Stream stream = Stream.of("a", "b", "c");
// 2. Arrays
String [] strArray = new String[] {"a", "b", "c"};
stream = Stream.of(strArray);
stream = Arrays.stream(strArray);
// 3. Collections
List<String> list = Arrays.asList(strArray);
stream = list.stream();
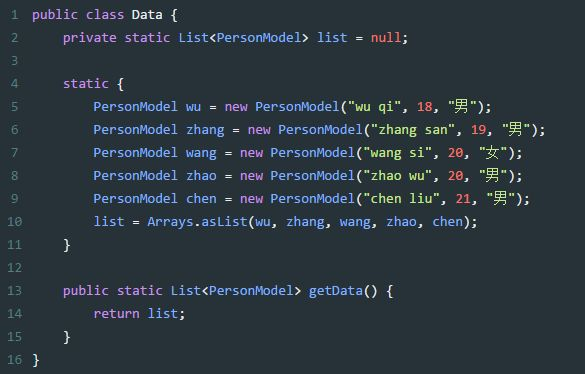
需要注意的是,对于基本数值型,目前有三种对应的包装类型 Stream:
IntStream、LongStream、DoubleStream。当然我们也可以用 Stream<Integer>、Stream<Long> >、Stream<Double>,但是 boxing 和 unboxing 会很耗时,所以特别为这三种基本数值型提供了对应的 Stream。
数值流的构造:
IntStream.of(new int[]{1, 2, 3}).forEach(System.out::println);
IntStream.range(1, 3).forEach(System.out::println);
IntStream.rangeClosed(1, 3).forEach(System.out::println);
流转换其他结构:
// 1. Array String[] strArray1 = stream.toArray(String[]::new); // 2. Collection List<String> list1 = stream.collect(Collectors.toList()); List<String> list2 = stream.collect(Collectors.toCollection(ArrayList::new)); Set set1 = stream.collect(Collectors.toSet()); Stack stack1 = stream.collect(Collectors.toCollection(Stack::new)); // 3. String String str = stream.collect(Collectors.joining()).toString();
注意:一个 Stream 只可以使用一次,上面的代码为了简洁而重复使用了数次。
流的操作
接下来,当把一个数据结构包装成 Stream 后,就要开始对里面的元素进行各类操作了。常见的操作可以归类如下。
- Intermediate:
map (mapToInt, flatMap 等)、 filter、 distinct、 sorted、 peek、 limit、 skip、 parallel、 sequential、 unordered
- Terminal:
forEach、 forEachOrdered、 toArray、 reduce、 collect、 min、 max、 count、 anyMatch、 allMatch、 noneMatch、 findFirst、 findAny、 iterator
- Short-circuiting:
anyMatch、 allMatch、 noneMatch、 findFirst、 findAny、 limit
以下使用代码来讲解几个比较常见的操作:
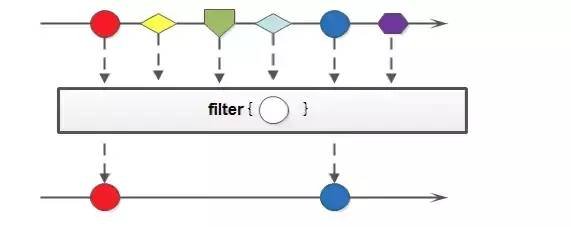
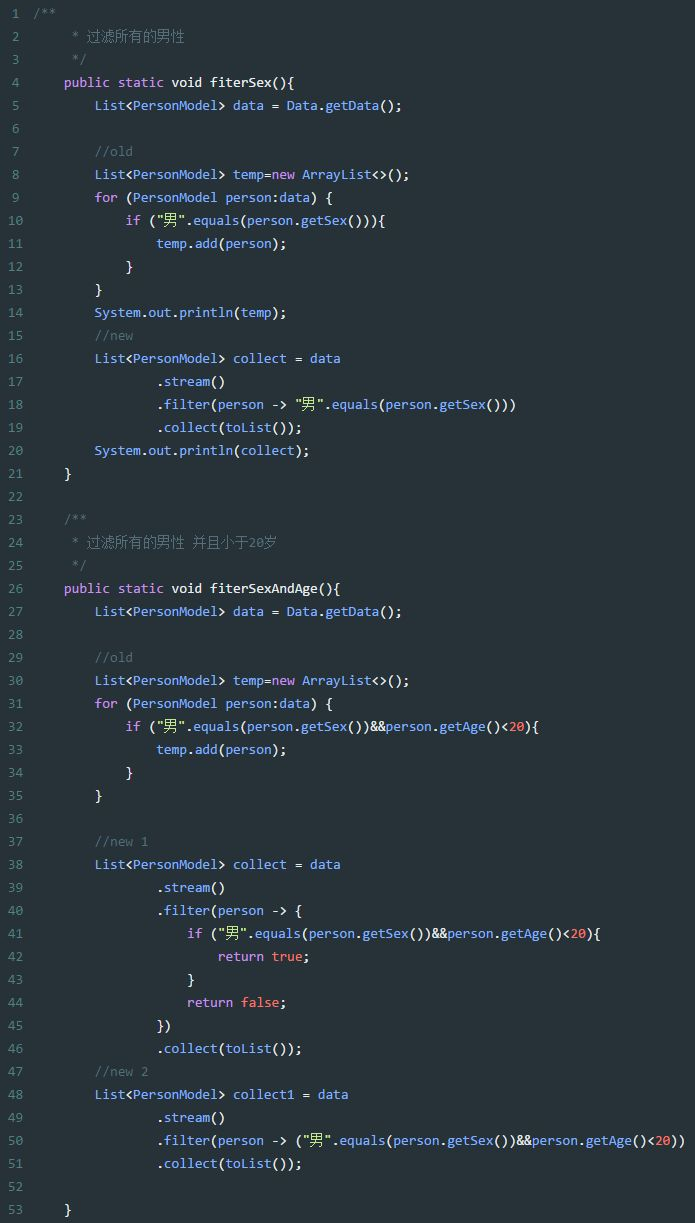
filter的使用实例:
1、遍历数据并检查其中的元素时使用。
2、filter接受一个函数作为参数,该函数用Lambda表达式表示。
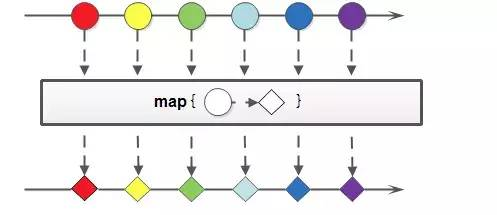
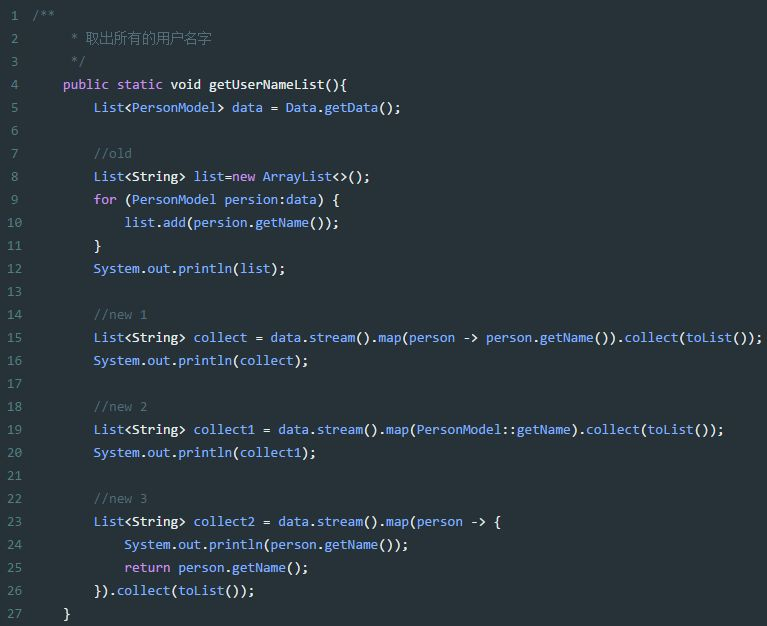
map的使用实例:
1、map生成的是个一对一映射,for的作用
2、比较常用
3、而且很简单。
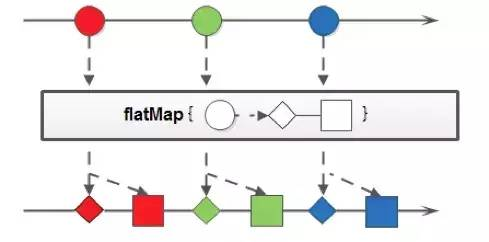
flatmap的使用实例:
1、顾名思义,跟map差不多,更深层次的操作
2、但还是有区别的
3、map和flat返回值不同
4、Map 每个输入元素,都按照规则转换成为另外一个元素。
还有一些场景,是一对多映射关系的,这时需要 flatMap。
5、Map一对一
6、Flatmap一对多
7、map和flatMap的方法声明是不一样的
(1) <r> Stream<r> map(Function mapper);
(2) <r> Stream<r> flatMap(Function> mapper);
(3) map和flatMap的区别:我个人认为,flatMap的可以处理更深层次的数据,入参为多个list,结果可以返回为一个list,而map是一对一的,入参是多个list,结果返回必须是多个list。通俗的说,如果入参都是对象,那么flatMap可以操作对象里面的对象,而map只能操作第一层。

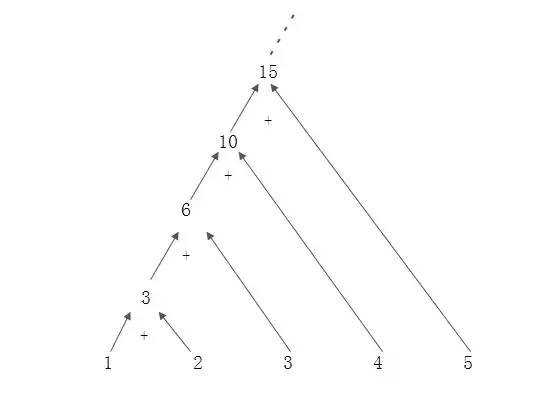
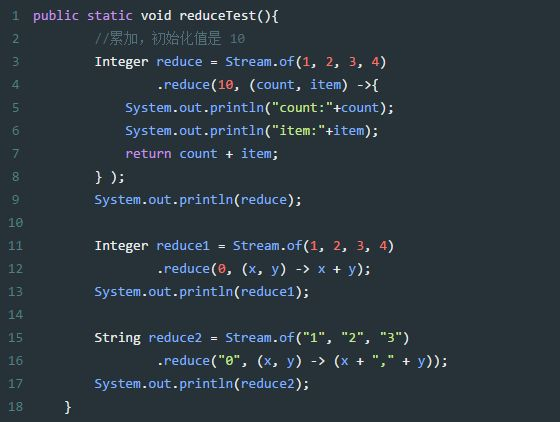
reduce的使用实例:
1、感觉类似递归
2、数字(字符串)累加
3、个人没咋用过。
collect实例的使用:
1、collect在流中生成列表,map,等常用的数据结构
2、toList()
3、toSet()
4、toMap()
5、自定义

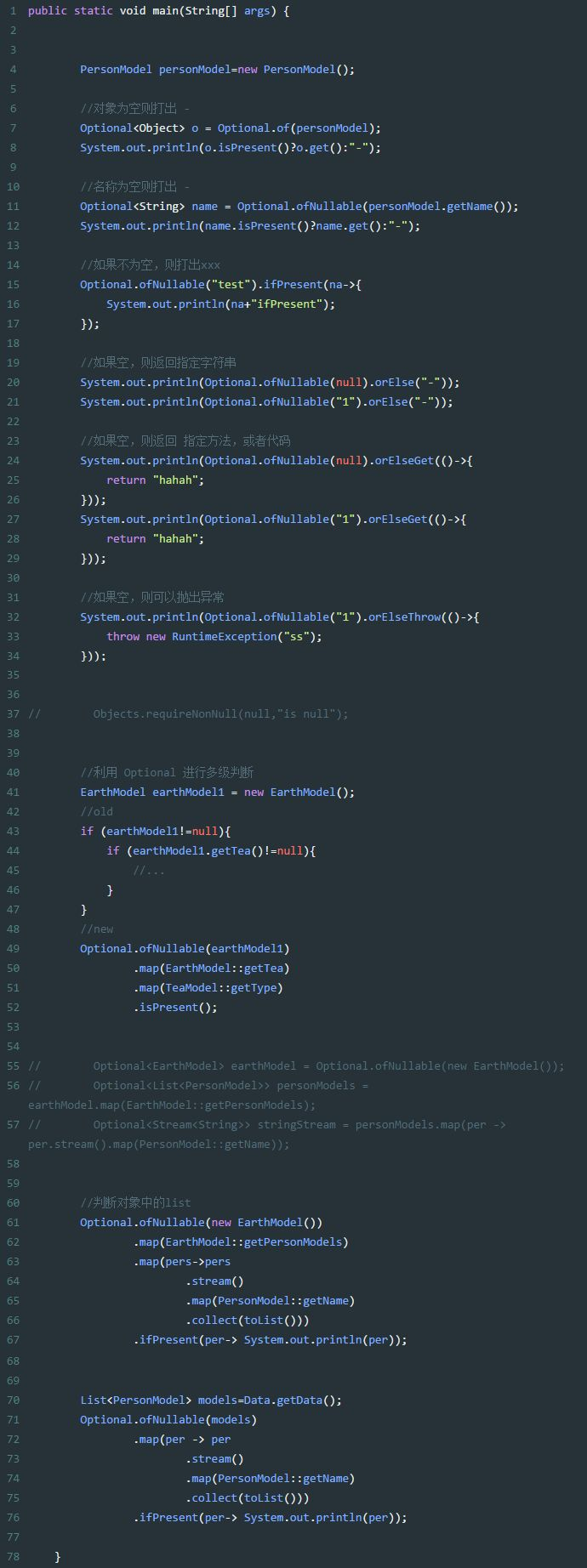
optional使用实例:
1、Optional 是为核心类库新设计的一个数据类型,用来替换 null 值。
2、人们对原有的 null 值有很多抱怨,甚至连发明这一概念的Tony Hoare也是如此,他曾说这是自己的一个“价值连城的错误”
3、用处很广,不光在lambda中,哪都能用
4、Optional.of(T),T为非空,否则初始化报错
5、Optional.ofNullable(T),T为任意,可以为空
6、isPresent(),相当于 !=null
7、ifPresent(T), T可以是一段lambda表达式 ,或者其他代码,非空则执行
并发的使用实例
1、stream替换成parallelStream或 parallel
2、输入流的大小并不是决定并行化是否会带来速度提升的唯一因素,性能还会受到编写代码的方式和核的数量的影响
3、影响性能的五要素是:数据大小、源数据结构、值是否装箱、可用的CPU核数量,以及处理每个元素所花的时间。

调试的使用实例:
1、list.map.fiter.map.xx 为链式调用,最终调用collect(xx)返回结果
2、分惰性求值和及早求值
3、判断一个操作是惰性求值还是及早求值很简单:只需看它的返回值。如果返回值是 Stream,那么是惰性求值;如果返回值是另一个值或为空,那么就是及早求值。使用这些操作的理想方式就是形成一个惰性求值的链,最后用一个及早求值的操作返回想要的结果。
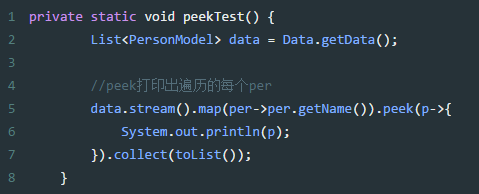
4、通过peek可以查看每个值,同时能继续操作流。
结束
仅此感谢网上共享的技术大拿们:
https://www.ibm.com/developerworks/cn/java/j-lo-java8streamapi/
https://www.jianshu.com/p/9fe8632d0bc2
https://blog.csdn.net/Hello_World_QWP/article/details/80245129