HBASE基础知识总结
一,概要说明
文章首先回顾HBase 的数据模型和数据层级结构,对数据的每个层级的作用和架构进行了详细阐述;随后介绍了数据写入和读取的详细流程。先把架构图和流程图来坐镇。
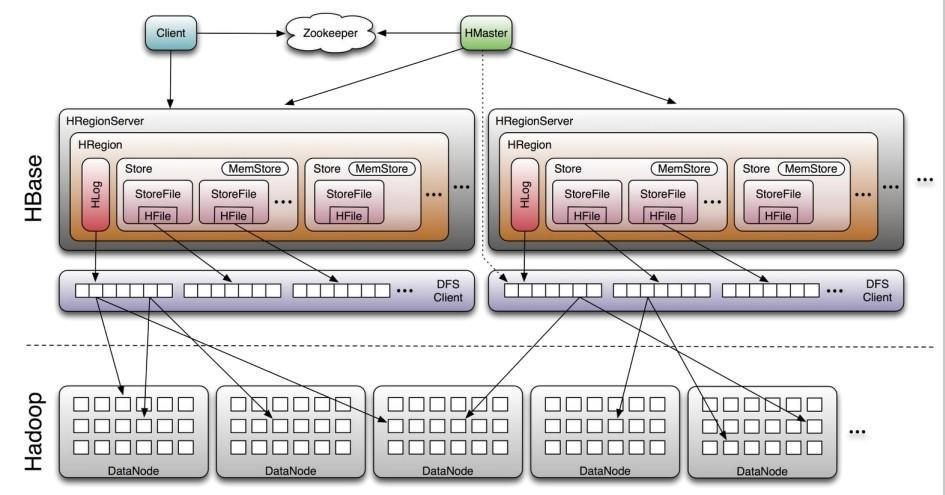
架构图

流程图
二,数据模型
1,重要概念回顾
Namespace :表命名空间,将多个表分到一个组进行统一管理。
Table:一个表由一个或者多个列族组成;数据属性比如:超时时间(TTL),压缩算法(COMPRESSION)等,都在列族的定义中定义;定义完列族后表是空的,只有添加了行,才有数据。
Row: 一个行包含多个列,这些列通过列族来分类;行中的数据所属列族只能从该表所定义的列族中选取;由于HBase是一个列式数据库,所以一个行中的数据可以分布在不同的服务器上。
Column Family:列族是多个列的集合,HBase会尽量把同一个列族的列放到同一个服务器上,这样可以提高存取性能,并且可以批量管理有关联的一堆列;所有的数据属性都是定义在列族上;在hbase中建表的不是列,而是列族。
Column Qualifier: 多个列组成一个行,列族和列经常使用 ColumnFamily:ColumnQualifier来一起表示,列是可以随便定义的,一个行中的列不限名字、不限数量。
Cell:单元格,一个列中可以存储多个版本的数据,而每个版本就称为一个单元格Cell,所以在HBase中的单元格跟传统关系型数据库的单元格概念不一样;HBase中的数据细粒度比传统数据结构更细一级,同一个位置的数据还细分成多个版本。
Timestamp:时间戳版本号,既可以把它称为是时间戳,也可以称为版本号,因为他是用来标定同一个列中多个单元格的版本号的。不指定版本号的时候,系统会自动当前的时间戳来作为版本号;当手动定义了一个数字来当做版本号的时候,这个Timestamp就真的是只有版本号的意义了。
2,几个小问题
hbase是否支持关联查询?
官方给的答案是干脆的,那就是不行,如果想实现数据之间的关联,就必须自己实现了,这是挑选noSQL的代价。
hbase是否支持ACID?
ACID是指 Atomicity(原子性)、Consistency(一致性)、Isolation(隔离性)、Durability(持久性)的首写字母,ACID是事务正确执行的保证,hbase部分支持了ACID。
表命名空间有什么用?
表命名空间主要是用来对表分组,命名空间可以补缺hbase无法在实例上分库的缺憾,通过命名空间可以像关系型数据库一样将表分组,对于不同的组进行不同的环境设定,比如配额管理、安全管理。
hbase中有两个保留空间是预先定义好的:
hbase:系统表空间,用于组织hbase内部表。
default:那些没有定义表空间的表都被自动分配到这个表空间下。
三,HBase的存储数据方式
1,架构回顾
一个hbase集群由一个Master(也可以Master做成High Available)和多个RegionServer组成。
Master:负责启动的时候Region到具体的RegionServer,执行各种管理操作,比如Region的分割和合并,hbase中的Master的角色功能比其他类型集群弱很多,Hbase的Master很特别,因为数据的读取和写入和他没什么关系,它挂了业务系统照样运行。当然Master也不能宕机太久,有很多必要的操作,比如创建表、修改列族配置,以及重要的分割和合并都需要它的操作。
RegionServer:RegionSever上可以有一个或者多个region,我们读写的数据就是在Region上的,如果你的Hbase是基于hdfs的(单机可以基于本地磁盘),那么Region所有的数据存取操作都是调用了hdfs的客户端接口来实现的。
Region:表的一部分数据,hbase是一个自动分片的数据库,一个Region就相当于关系型数据库中分区表的一个分区,或者MongoDB的一个分片。
HDFS: Hbase集群不是直接和磁盘交互,而是和hdfs交互,所以hdfs是直接承载数据的载体。
Zookeeper :zookeeper在hbase中的比Masrer更重要,把Master关掉业务系统照样运行,能读能写。但是关闭zookeeper,就不能读取数据了,因为读取数据所需要的元数据表hbase:meta的位置存储在zookeeper上的。

2,RegionServer内部架构
一个RegionServer包含:
一个WAL:预写日志,WAL是Write-Ahead Log 的缩写,就是:预先写入。但操作到达Region的时候,HBase先把操作写到WAL里面去,HBase会把数据放到基于内存实现的Memstore里,等数据达到一定的数量时才刷写(flush)到最终存储的HFile内,而如果在这个过程中服务器当机或者断电了,那么数据就会丢失了。WAL是一个保险机制,数据在写Memstore之前,先被写到WAL了,这样当故障恢复的时候依旧可以从WAL中恢复数据。
多个Region:Region相当于一个数据分片,每一个Region都有起始rowKey和结束rowkey,代表了它所存储的row范围。

3,Region内部架构
每一个region内都包含有多个store实例,一个Store对应一个列族的数据,如果一个表有2个列族,那么在一个Region里面就有两个Store,Store内部有MemStore和HFile这两个组成部分:

4,预写日志
预写日志(Write-ahead log,WAL)就是设计来解决宕机之后的操作恢复问题的,数据达到Region的时候是先写入WAL,然后在被加载到Memstore,就算Region的机器宕了,由于WAL的数据是存储在HDFS上的,所以数据并不会丢失。
WAL是默认开启的,可以通过下面的代码关闭WAL:
Mutation.setDurability(Durability.SKIP_WAL);
Put、Append、Increment、Delete都是Mutation的子类,所以他们都有setDurability方法,这样可以让该数据操作快一点,但是最好不要这么做,因为当服务器宕机时候,数据就会丢失。如果实在想通过关闭WAL来提升性能,可以选择一部写入WAL。
Mutation.setDurability(Durability.ASYNC WAL);
这样设定后就Region会等到条件满足的时候才把操作写入WAL,这里提到的时间间隔主要在这里设置:hbase.regionserver.optionallogflushinterval 。这个时间间隔的意思就是hbase间隔多久会把操作从内存写入WAL,默认值是1S。
5,WAL滚动
WAL是一个环状的滚动日志结构,因为这种结构写入效果最高,而且保证空间不会持续变大。
WAL的检查间隔由 hbase.regionserver.logroll.period 来定义,默认值是1H,检查的内容就是把当前WAL中的操作跟实际持久化到HDFS上的操作比较,看哪些操作已经被持久化了,被持久化的操作就会迁移到 .oldlogs 文件夹内(这个文件夹在hdfs上的)。
一个WAL实例包含有多个WAL文件,WAL文件的最大数量通过hbase.regionserver.maxlogs (默认是 32)参数来定义。
其他的滚动触发条件是:
当WAL所在的块(block)快要满了。
当WAL所占的空间大于或者等于这个阙值,该阙值的计算公式是:hbase.regionserver.hlog.blocksize * hbase.regionserver.logroll.multiplier;
参数解释:hbase.regionserver.hlog.blocksize 是标定存储系统的块大小的,你如果是基于hdfs的,那么只需要把这个值设定成HDFS的块大小即可。
hbase.regionserver.logroll.multiplier 是一个百分比,默认设置0.95 ,如果WAL文件所占的空间大于或者等于95%的快大小,则这个WAL文件就会被归档到 .oldlogs 文件夹内
WAL文件被创建出来后会放到 .log 文件夹这个文件夹也是基于hdfs,一旦WAL文件被判定要归档,则会被迁移到 .oldlogs 文件夹,Master会负责定期的去清理 .oldlogs 文件夹,判断的条件是“没有任何引用指向这个WAL文件” 。目前有2种服务可能会引用WAL文件:
TTL进程:该进程会保证WAL文件一直存活到 hbase.master.logcleaner.ttl 定义的超时时间(默认10分钟)为止。
备份(replication)机制:如果开启了hbase的备份机制,那么hbase要保证备份集群已经完全不需要这个WAL文件了,才会删除这个WAL文件。这里提到的replication 不是文件的备份数,而是0.90版本加入的特性,这个特性用于把一个集群的数据实时备份到另外一个集群。
6,Store内部结构
在store中有两个重要组成部分:
MemStore:每个Store中有一个MemStore实例,数据写入WAL之后就会被放入MemStore。MemStore是内存的存储对象,只有当MemStore满了的时候才会将数据刷写(flush)到Hfile中。
Hfile:在Store中有多个Hfile,当MemStore满了之后就会在hdfs上生成一个新的Hfile,然后把MemStore中的内容写到这个Hfile中。Hfile直接跟HDFS打交道,他是数据的存储实体。
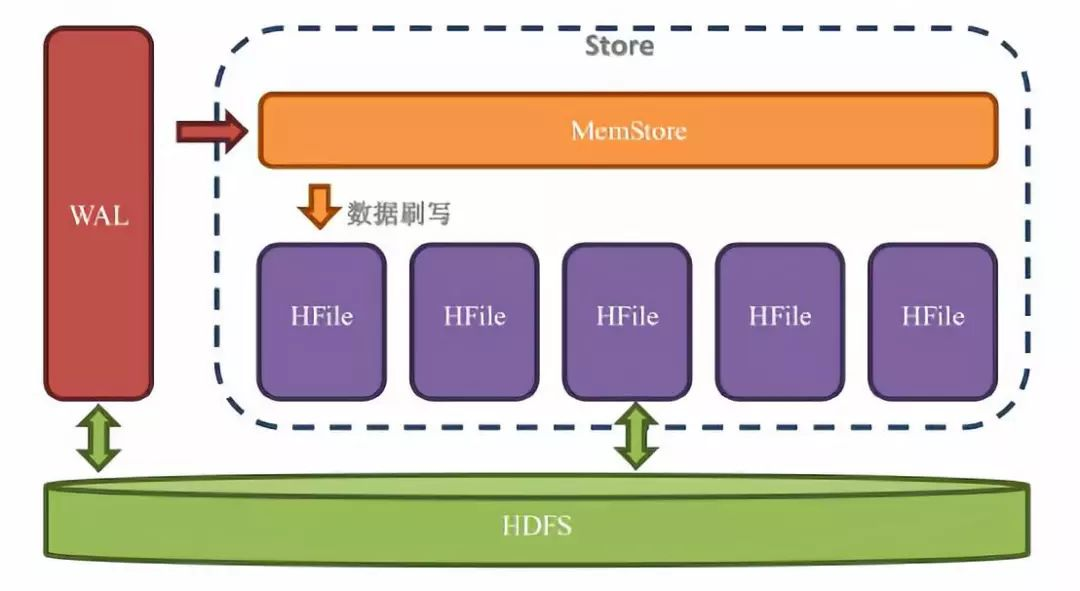
WAL是存储在hdfs上的,MemStore是存储的内存上的,Hfile又是存储在hdfs上的;数据是先写入WAL,再被写入MemStore,最后持久化到hfile中。数据在进入hfile之前已经被存储到hdfs一次了,为什么还需要被放入MemStore?
答:这是因为hdfs上的文件只能创建、追加、删除,但是不能修改,对于数据库来说,按顺序存放数据是非常的重要的,这是性能的保障,所以我们不能按照数据到来的顺序来写入磁盘。
可以使用内存先把数据整理成顺序存放,然后在一起写入硬盘,这就是MemStore存在的意义,虽然MemStore是存储在内存中的,hfile和wal是存储在hdfs中,但由于数据在写入MemStore之前,要先被写入WAL,所以增加MemStore的大小不能加速写入速度。MemStore存在的意义是维持数据按照rowkey顺序排列,而不是作为一个缓存。
7,MemStore
设计MemStore的原因有以下几点:
由于hdfs上的文件不可修改,为了让数据顺序存储从而提高读取效率,hbase使用了LSM树结构来存储数据,数据会先在MemStore中整理成LSM树,最后在刷写到hfile上。
优化数据的存储,比如一个数据添加后就马上删除了,这样在刷写的时候就可以直接不把这个数据写到hdfs上的。
不过不要想当然地认为读取也是先读取MemStore再读取磁盘哦,读取的时候有一个专门的缓存叫BlockCache,这个BlockCache如果开启了,就是先读BlockCache,读不到才是读hfile+MemStore。
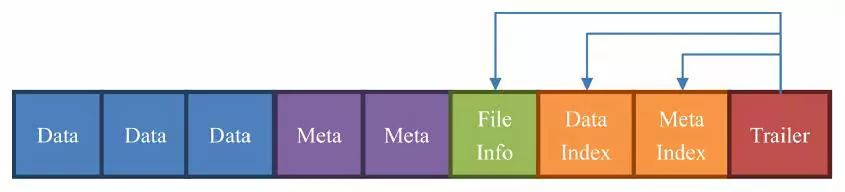
8,HFile(StoreFile)
hfile是数据存储的实际载体,我们创建的所有表、列等数据都存储在hfile里面,hfile由一个个块组成,在hbase中一个快的大小默认为64KB,由列族上的BLOCKSIZE属性定义,这些块区分了不同的角色:
其实叫 HFile 或者 StoreFile 都没错,在物理存储上我们管 MemStore 刷写而成的文件叫 HFile,StoreFile 就是 HFile 的抽象类而已。
Data:数据块。每个 HFile 有多个 Data 块,我们存储在 HBase 表中的数据就在这里,Data 块其实是可选的,但是几乎很难看到不包含 Data 块的 HFile;
Meta:元数据块。Meta 块是可选的,Meta 块只有在文件关闭的时候才会写入。Meta 块存储了该 HFile 文件的元数据信息,在 v2 之前布隆过滤器(Bloom Filter)的信息直接放在 Meta 里面存储,v2 之后分离出来单独存储;
FileInfo:文件信息,其实也是一种数据存储块。FileInfo 是 HFile 的必要组成部分,是必选的,它只有在文件关闭的时候写入,存储的是这个文件的信息,比如最后一个 Key(LastKey),平均的 Key 长度(AvgKeyLen)等;
DataIndex:存储 Data 块索引信息的块文件。索引的信息其实也就是 Data 块的偏移值(offset),DataIndex 也是可选的,有 Data 块才有 DataIndex;
MetaIndex:存储 Meta 块索引信息的块文件。MetaIndex 块也是可选的,有 Meta 块才有 MetaIndex;
Trailer:必选的,它存储了 FileInfo、DataIndex、MetaIndex 块的偏移值。
三,增删改查的真正面目
hbase是一个可以随机读写的数据库,而它所基于的持久化层hdfs却是要么新增,要么整个删除,不能修改的系统。那hbase怎么实现我们的增删改查呢?真实的情况是这样的:hbase几乎总是在做新增操作:
当你新增一个单元格的时候,hbase在hdfs上新增一条数据;
当你修改一个单元格的时候,hbase在hdfs又新增一条数据,只是版本号比之前的大(或者你自己定义);
当你删除一个单元格的时候,hbase还是新增一条数据!只是这条数据没有value,类型为delete,这条数据叫墓碑标记(Tombstone)。
由于数据库在使用过程中积累了很多增删改查操作,数据的连续性和顺序性必然会被破坏。为了提升性能,hbase每间隔一段时间都会进行一次合并(compaction),合并的对象为Hfile文件。合并分为 minor compaction 和major compaction,在hbase进行major compaction的时候,它会把多个hfile合并成一个hfile,在这个过程中,一旦检测到有被打上墓碑标记的记录,在和并的过程中就忽略这条记录,这样在新产生的hfile中,就没有这条记录了,自然也就相当于真正的删除了。
四,数据结构总结
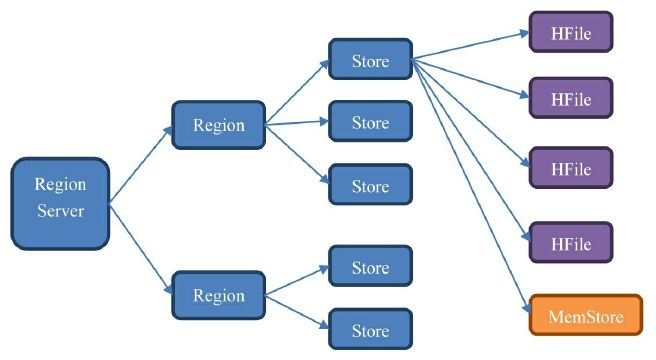
hbae的数据的内部结构大体如下:
一个RegionServer包含多个Region,划分规则是:一个表的一段键值在一个RegionServer上会产生一个Region。不过当某一行的数据量太大了,hbase也会把这个Region根据列族切分到不同的机器上去:
一个Region包含多个Store,划分规则是:一个列族一个Store,如果一个表只有一个列族,那么这个表在这个机器上的每一个Region里面都有一个Store;
一个 Store 里面只有一个 Memstore;
一个 Store 里面有多个 HFile,每次 Memstore 的刷写(flush)就产生一个新的 HFile 出来。
五,KeyValue的写入和读出
1,写入
一个keyvalue被持久化到hdfs的过程如下:
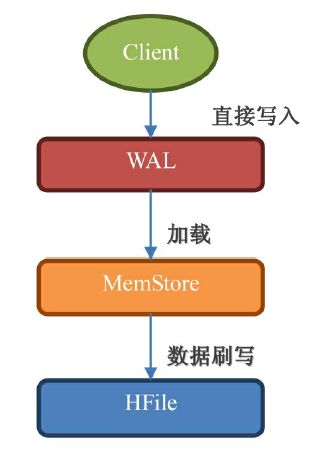
WAL:数据被发出之后第一时间被写入 WAL,由于 WAL 是基于 HDFS 来实现的,所以也可以说现在单元格就已经被持久化了,但是 WAL 只是一个暂存的日志,它是不区分 Store 的,这些数据是不能被直接读取和使用;
Memstore:数据随后会立即被放入 Memstore 中进行整理,Memstore 会负责按照 LSM 树的结构来存放数据,这个过程就像我们在打牌的时候,抓牌之后在手上对牌进行整理的过程;
HFile: 最后,当 Memstore 太大了达到尺寸上的阀值,或者达到了刷写时间间隔阀值的时候,HBaes 会把这个 Memstore 的内容刷写到 HDFS 系统上,称为一个存储在硬盘上的 HFile 文件。至此,我们可以称为数据真正地被持久化到硬盘上,就算宕机,断电,数据也不会丢失了;
2.读出
由 于有 MemStore(基于内存)和 HFile(基于HDFS)这两个机制,你一定会立马想到先读取 MemStore,如果找不到,再去 HFile 中查询。这是显而易见的机制,可惜 HBase 在处理读取的时候并不是这样的。实际的读取顺序是先从 BlockCache 中找数据,找不到了再去 Memstore 和 HFile 中查询数据。
墓碑标记和数据不在一个地方,读取数据的时候怎么知道这个数据要删除呢?如果这个数据比它的墓碑标记更早被读到,那在这个时间点真是不知道这个数据会被删 除,只有当扫描器接着往下读,读到墓碑标记的时候才知道这个数据是被标记为删除的,不需要返回给用户。
所以 HBase 的 Scan 操作在取到所需要的所有行键对应的信息之后还会继续扫描下去,直到被扫描的数据大于给出的限定条件为止,这样它才能知道哪些数据应该被返回给用户,而哪些应该被舍弃。所以你增加过滤条件也无法减少 Scan 遍历的行数,只有缩小 STARTROW 和 ENDROW 之间的行键范围才可以明显地加快扫描的速度。
在 Scan 扫描的时候 store 会创建 StoreScanner 实例,StoreScanner 会把 MemStore 和 HFile 结合起来扫描,所以具体从 MemStore 还是 HFile 中读取数据,外部的调用者都不需要知道具体的细节。当 StoreScanner 打开的时候,会先定位到起始行键(STARTROW)上,然后开始往下扫描。
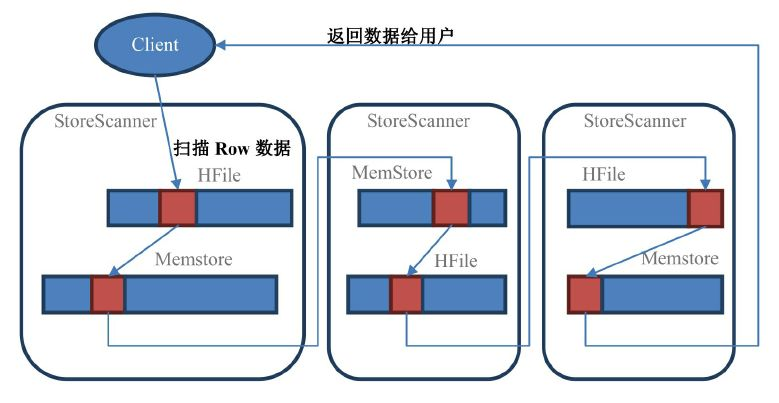
其中红色块部分都是属于指定 row 的数据,Scan 要把所有符合条件的 StoreScanner 都扫描过一遍之后才会返回数据给用户。
六,Region的定位
Region查找流程:
客户端先通过Zookeeper的 /hbase/meta-region-server 节点查询到哪台RegionServer上有hbase:meta表:
客户端链接含有hbase:meta表的RegionServer,hbase:meta表存储了所有Region的行键范围信息,通过这个表就可以查询出要存取的rowkey属于哪个Region的范围里面,以及这个Region又是属于哪个RegionServer;
获取这些信息后,客户端就可以直连其中一台拥有要存取的rowkey的RegionServer,并直接对其操作。
客户端会把meta信息缓存起来,下次操作就不要进行以上加载hbase:meta的步骤了。
