http://cos.name/2013/03/lda-math-lda-text-modeling/
5. LDA 文本建模
5.1 游戏规则
对于上述的 PLSA 模型,贝叶斯学派显然是有意见的,doc-topic 骰子θ→m和 topic-word 骰子φ→k都是模型中的参数,参数都是随机变量,怎么能没有先验分布呢?于是,类似于对 Unigram Model 的贝叶斯改造, 我们也可以如下在两个骰子参数前加上先验分布从而把 PLSA 对应的游戏过程改造为一个贝叶斯的游戏过程。由于 φ→k和θ→m都对应到多项分布,所以先验分布的一个好的选择就是Drichlet 分布,于是我们就得到了 LDA(Latent Dirichlet Allocation)模型。
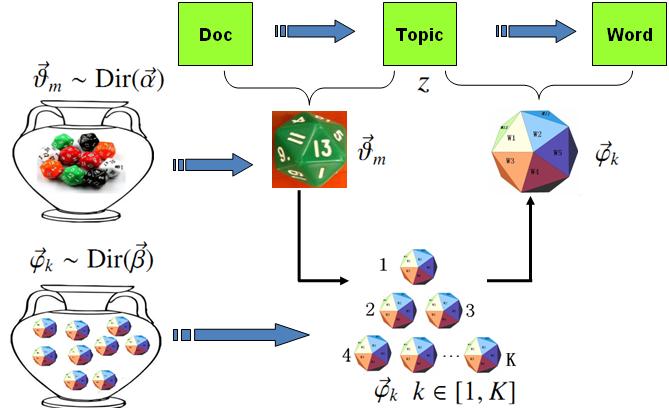 LDA模型
LDA模型
在 LDA 模型中, 上帝是按照如下的规则玩文档生成的游戏的
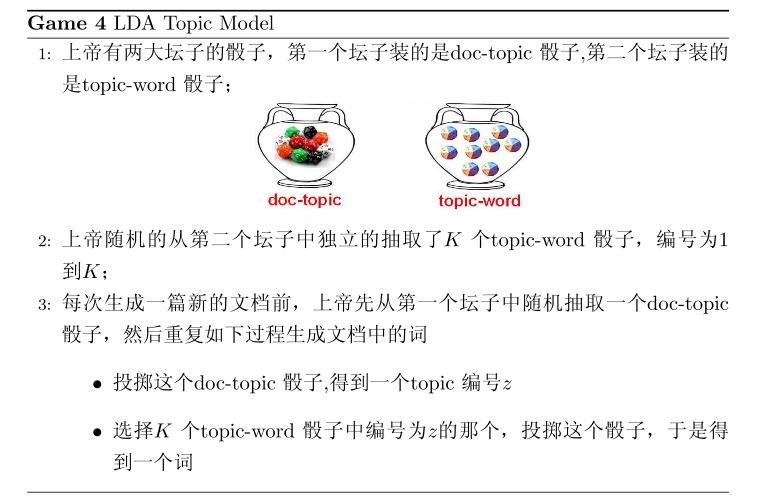
假设语料库中有 M 篇文档,所有的的word和对应的 topic 如下表示
其中, w→m 表示第m 篇文档中的词, z→m 表示这些词对应的 topic 编号。
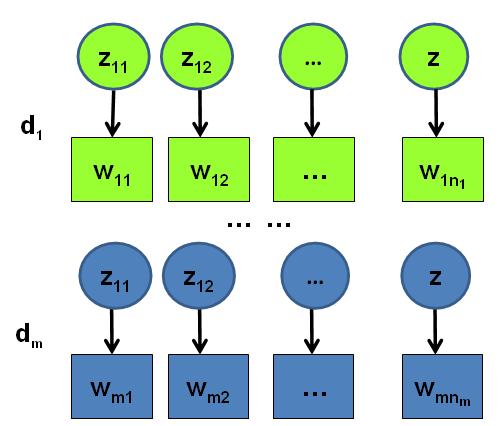 语料生成过程中的 word 和 topic
语料生成过程中的 word 和 topic
5.2 物理过程分解
使用概率图模型表示, LDA 模型的游戏过程如图所示。
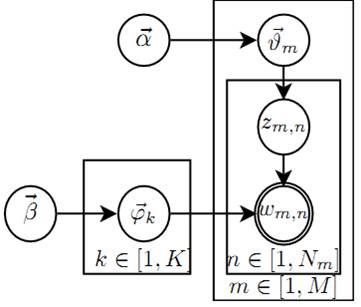 LDA概率图模型表示
LDA概率图模型表示
这个概率图可以分解为两个主要的物理过程:
- α→→θ→m→zm,n, 这个过程表示在生成第m 篇文档的时候,先从第一个坛子中抽了一个doc-topic 骰子 θ→m, 然后投掷这个骰子生成了文档中第 n 个词的topic编号zm,n;
- β→→φ→k→wm,n|k=zm,n, 这个过程表示用如下动作生成语料中第m篇文档的第 n个词:在上帝手头的K 个topic-word 骰子 φ→k 中,挑选编号为 k=zm,n的那个骰子进行投掷,然后生成 word wm,n;
理解 LDA最重要的就是理解这两个物理过程。 LDA 模型在基于 K 个 topic 生成语料中的 M 篇文档的过程中, 由于是 bag-of-words 模型,有一些物理过程是相互独立可交换的。由此, LDA 生成模型中, M 篇文档会对应于 M 个独立的 Dirichlet-Multinomial 共轭结构; K 个 topic 会对应于 K 个独立的 Dirichlet-Multinomial 共轭结构。所以理解 LDA 所需要的所有数学就是理解 Dirichlet-Multiomail 共轭,其它都就是理解物理过程。现在我们进入细节, 来看看 LDA 模型是如何被分解为 M+K个Dirichlet-Multinomial 共轭结构的。
由第一个物理过程,我们知道 α→→θ→m→z→m 表示生成第 m 篇文档中的所有词对应的topics,显然 α→→θ→m 对应于 Dirichlet 分布, θ→m→z→m 对应于 Multinomial 分布, 所以整体是一个 Dirichlet-Multinomial 共轭结构;
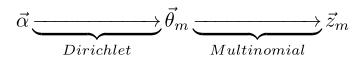
前文介绍 Bayesian Unigram Model 的小节中我们对 Dirichlet-Multinomial 共轭结构做了一些计算。借助于该小节中的结论,我们可以得到
其中 n→m=(n(1)m,⋯,n(K)m), n(k)m 表示第m篇文档中第k 个topic 产生的词的个数。进一步,利用 Dirichlet-Multiomial 共轭结构,我们得到参数 θ→m 的后验分布恰好是
由于语料中 M篇文档的 topics 生成过程相互独立,所以我们得到 M 个相互独立的 Dirichlet-Multinomial 共轭结构,从而我们可以得到整个语料中 topics 生成概率
目前为止,我们由M篇文档得到了 M 个 Dirichlet-Multinomial 共轭结构,还有额外K 个 Dirichlet-Multinomial 共轭结构在哪儿呢?在上帝按照之前的规则玩 LDA 游戏的时候,上帝是先完全处理完成一篇文档,再处理下一篇文档。文档中每个词的生成都要抛两次骰子,第一次抛一个doc-topic骰子得到 topic, 第二次抛一个topic-word骰子得到 word,每次生成每篇文档中的一个词的时候这两次抛骰子的动作是紧邻轮换进行的。如果语料中一共有 N 个词,则上帝一共要抛 2N次骰子,轮换的抛doc-topic骰子和 topic-word骰子。但实际上有一些抛骰子的顺序是可以交换的,我们可以等价的调整2N次抛骰子的次序:前N次只抛doc-topic骰子得到语料中所有词的 topics,然后基于得到的每个词的 topic 编号,后N次只抛topic-word骰子生成 N 个word。于是上帝在玩 LDA 游戏的时候,可以等价的按照如下过程进行:

以上游戏是先生成了语料中所有词的 topic, 然后对每个词在给定 topic 的条件下生成 word。在语料中所有词的 topic 已经生成的条件下,任何两个 word 的生成动作都是可交换的。于是我们把语料中的词进行交换,把具有相同 topic 的词放在一起
其中,w→(k) 表示这些词都是由第 k 个 topic 生成的, z→(k) 对应于这些词的 topic 编号,所以z→(k)中的分量都是k。
对应于概率图中的第二个物理过程 β→→φ→k→wm,n|k=zm,n,在 k=zm,n的限制下,语料中任何两个由 topic k 生成的词都是可交换的,即便他们不再同一个文档中,所以我们此处不再考虑文档的概念,转而考虑由同一个 topic 生成的词。考虑如下过程 β→→φ→k→w→(k) ,容易看出, 此时 β→→φ→k 对应于 Dirichlet 分布, φ→k→w→(k) 对应于 Multinomial 分布, 所以整体也还是一个 Dirichlet-Multinomial 共轭结构;
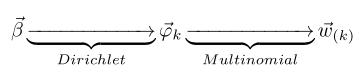
同样的,我们可以得到
其中 n→k=(n(1)k,⋯,n(V)k), n(t)k 表示第k 个topic 产生的词中 word t的个数。进一步,利用 Dirichlet-Multiomial 共轭结构,我们得到参数 φ→k 的后验分布恰好是
而语料中 K个 topics 生成words 的过程相互独立,所以我们得到 K 个相互独立的 Dirichlet-Multinomial 共轭结构,从而我们可以得到整个语料中词生成概率
结合 (*) 和 (**) 于是我们得到
此处的符号表示稍微不够严谨, 向量 n→k, n→m 都用 n 表示, 主要通过下标进行区分,k 下标为 topic 编号, m 下标为文档编号。
5.3 Gibbs Sampling
有了联合分布 p(w−→,z→), 万能的 MCMC 算法就可以发挥作用了!于是我们可以考虑使用 Gibbs Sampling 算法对这个分布进行采样。当然由于 w−→ 是观测到的已知数据,只有 z→是隐含的变量,所以我们真正需要采样的是分布 p(z→|w−→)。在 Gregor Heinrich 那篇很有名的LDA 模型科普文章 Parameter estimation for text analysis 中,是基于 (***) 式推导 Gibbs Sampling 公式的。此小节中我们使用不同的方式,主要是基于 Dirichlet-Multinomial 共轭来推导 Gibbs Sampling 公式,这样对于理解采样中的概率物理过程有帮助。
语料库z→ 中的第i个词我们记为zi, 其中i=(m,n)是一个二维下标,对应于第m篇文档的第 n个词,我们用 ¬i 表示去除下标为i的词。那么按照 Gibbs Sampling 算法的要求,我们要求得任一个坐标轴 i 对应的条件分布 p(zi=k|z→¬i,w−→) 。假设已经观测到的词 wi=t, 则由贝叶斯法则,我们容易得到
由于zi=k,wi=t 只涉及到第 m 篇文档和第k个 topic,所以上式的条件概率计算中, 实际上也只会涉及到如下两个Dirichlet-Multinomial 共轭结构
- α→→θ→m→z→m
- β→→φ→k→w→(k)
其它的 M+K−2 个 Dirichlet-Multinomial 共轭结构和zi=k,wi=t是独立的。
由于在语料去掉第i 个词对应的 (zi,wi),并不改变我们之前讨论的 M+K 个 Dirichlet-Multinomial 共轭结构,只是某些地方的计数会减少。所以θ→m,φ→k 的后验分布都是 Dirichlet:
使用上面两个式子,把以上想法综合一下,我们就得到了如下的 Gibbs Sampling 公式的推导
=
=
=
=
=
=
=