先构建本篇博客的案列演示表:
create table a(a1 int primary key, a2 int ,index(a2)); --双字段都有索引 create table c(c1 int primary key, c2 int ,index(c2), c3 int); --双字段都有索引 create table b(b1 int primary key, b2 int); --有主键索引 insert into a values(1,1),(2,2),(3,3),(4,4),(5,5),(6,6),(7,7),(8,8),(9,9),(10,10); insert into b values(1,1),(2,2),(3,3),(4,4),(5,5),(6,6),(7,7),(8,8),(9,9),(10,10); insert into c values(1,1,1),(2,4,4),(3,6,6),(4,5,5),(5,3,3),(6,3,3),(7,2,2),(8,8,8),(9,5,5),(10,3,3);
1. 筛选条件放置在where和on上的不同?
在Mysql多表连接查询的执行细节(一) 这篇博客中,我已经讲解了两表的关联细节。where里可能有关于每张表的筛选条件,不同表的条件生效时期不同。对于驱动表,在执行一开始就会通过where上关于词表的条件筛选一条或者一批记录,然后通过on条件关联下一张表,将得到的结果集再用where上第二张表的条件做过滤,然后重复此过程直到所有表关联完毕。也就是对于驱动表,因为只有where生效,对于其他被驱动表,先被on关联,也就是on先生效,然后再用where过滤关联的结果集。同时对于外表连接,比如left join和right join,把条件放在on上,如果被关联表没有匹配上,那么外表还是能放入结果集的;而如果将条件放在where上,因为where是对关联后的结果做过滤,此时之前匹配的记录也会被筛选掉。
将条件放在where上:
select a.*,b.* from a left join b on a.a1=b.b1 where a.a2>3 and b.b2<5;
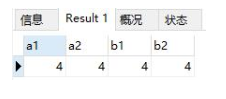
将条件放在on上:
select a.*,b.* from a left join b on a.a1=b.b1 and b.b2<5 where a.a2>3 ;
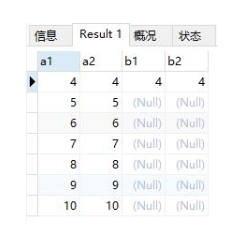
2. 外连接时外表是否一定为驱动表?
大部分情況下外表都是驱动表,这是因为外表在关联内表时,如果没有匹配的记录,那么会生成一条所有字段都为null的内表记录来和外表行关联,就像上图一样。用外表做驱动表,这样在Nested-Loop join时才能很容易的判断是内表是否有匹配的记录,判断是否用null来关联。但有些个别情况下,外表也可能是被驱动表,比如如下sql:
select a.*, c.* from a left join c on a.a2 = c.c2 where a.a2 = c.c3 ;
通过explain查看其执行计划:

a和c之间的关联条件既存在于on上也存在于where上,上文说过where是过滤两表关联的结果集的,当a和c表通过on关联之后得到结果,sql如下:
select a.*, c.* from a left join c on a.a2 = c.c2
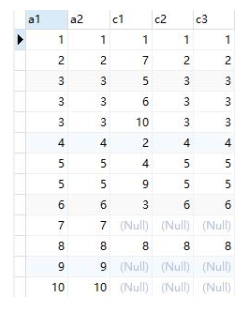
之后再通过where里的a.a2 = c.c3筛选上述结果。要知道mysql有个规定,null和任何值都不能相比,即使同为null也是如此:
select null=null; >> null
所以即使上述a1=7的记录行的a2值为null,a.a2 = c.c3 的值还是null,也就是此行结果被剔除。也就是a表通过on关联c表多出来的记录最终还是会被剔除,所以mysql针对这种情况作了一个优化,将left join转换为join,这样外表就有可能不作为驱动表,比如通过explain查看开始的sql:

3. 是否应该使用join连接查询?
对于多表间查询,可以使用join关联,也可以拆成多张表的单独查询。对于join关联查询,如果使用不当,很容易造成对被驱动表的多次扫描(Block Nested-Loop join),进而导致IO压力增大,同时多次的扫面被驱动表,会导致被驱动表的数据页被置入mysql buffer-pool的young区域,一次join就替换掉之前真正的热点数据页。
正常一次查询仅全表扫描一次数据的话,数据页会被放入buffer pool的old区域的前端,但是如果一个数据页在第一次使用时,如果不在buffer pool,那么会加载仅buffer pool,放在old区域的前端,但是如果这个数据页在buffer pool,且距离上次使用时间超过1S,也就是join查询时间拆过1S,那么就会把数据页放到buffer pool的young区域,也就是热点区域,这样会导致原先真正的热点数据被替换。这样即使join查询结束了,对mysql的性能有很直接的负面影响,也就是buffer pool内存命中率突然暴跌,查询时间突然变长,很多都需要读取磁盘,需要很长时间才能恢复。
所以,对于大表的关联查询,如果没有使用上索引,也就是on的字段没有索引,通过explain能看到Extra里有Using join buffer(Block Nested Loop),那么就不要使用join了。当然能使用上使用的join查询还是比单表查询来的快的,同时还能很方便的做结果筛选。
原文链接:https://blog.csdn.net/qq_27529917/article/details/87954427