本博客代码都是参考《Redis IN ACTION》这本书,由于书中代码都是python所写,所以本文代码为java语言编写,方便读者查阅
public class Chapter01 { private static final int ONE_WEEK_IN_SECONDS = 7 * 86400; //用来计算超过7天之后的文章不可以投票 private static final int VOTE_SCORE = 432; //432来源 这个常量是通过将一天的秒数(86400)除以文章展示一天所需的支持票数量(200 -支持票超过200就算有趣文章)得出的,文章每获得一张支持票,程序要需要将文章的评分增加432分 private static final int ARTICLES_PER_PAGE = 25; public static final void main(String[] args) { new Chapter01().run(); } public void run() { Jedis conn = new Jedis("192.168.32.128"); conn.select(15); // 初始化10篇文章 // for(int i=1;i<11;i++) // { // String articleId = postArticle(conn, "username_"+i, "A title"+i); // System.out.println("create a new article: " + articleId); // Map<String, String> articleData = conn.hgetAll("article:" + articleId); // for(Map.Entry<String, String> entry : articleData.entrySet()) // { // System.out.println(" " + entry.getKey() + ": " + entry.getValue()); // } // } // 投票代码开始 // articleVote(conn, "jack", "article:1"); // articleVote(conn, "jack", "article:2"); // articleVote(conn, "jack", "article:3"); // articleVote(conn, "jack", "article:4"); // articleVote(conn, "jack", "article:5"); // articleVote(conn, "jack", "article:6"); // articleVote(conn, "jack", "article:8"); // articleVote(conn, "jack", "article:9"); // articleVote(conn, "jack1", "article:1"); // articleVote(conn, "jack2", "article:1"); // articleVote(conn, "jack3", "article:1"); // articleVote(conn, "jack4", "article:1"); // articleVote(conn, "jack2", "article:3"); // articleVote(conn, "jack3", "article:3"); // String votes = conn.hget("article:1", "votes"); // System.out.println("We voted for the article, it now has votes: " + votes); //得到从高到低的排名 // System.out.println("The currently highest-scoring articles are:"); // List<Map<String,String>> articles = getArticles(conn, 1); // printArticles(articles); // 给文章分组 // addGroups(conn, "1", new String[]{"jack01-group","jack02-group"}); // addGroups(conn, "2", new String[]{"jack01-group","jack02-group"}); // addGroups(conn, "5", new String[]{"jack01-group","jack02-group"}); // addGroups(conn, "6", new String[]{"jack01-group","jack03-group"}); // addGroups(conn, "7", new String[]{"jack03-group","jack02-group"}); // addGroups(conn, "10", new String[]{"jack01-group","jack03-group"}); // addGroups(conn, "8", new String[]{"jack03-group","jack02-group"}); // addGroups(conn, "9", new String[]{"jack03-group","jack02-group"}); // addGroups(conn, "4", new String[]{"jack03-group","jack02-group"}); val articles = getGroupArticles(conn, "jack03-group", 1); printArticles(articles); } /** * 1,生成文章ID * 2,将发布者ID增加到已投票用户名单集合中 * 3,使用HMSET命令来存储文章相关信息 * 4,将文章初始评分和发布时间分别添加到2个相应的有序集合中 * @return */ public String postArticle(Jedis conn, String userName, String title) { String articleId = String.valueOf(conn.incr("article:")); String voted = "voted:" + articleId; //set conn.sadd(voted, userName); conn.expire(voted, ONE_WEEK_IN_SECONDS); ////hash long now = System.currentTimeMillis() / 1000; String article = "article:" + articleId; HashMap<String,String> articleData = new HashMap<String,String>(); articleData.put("title", title); articleData.put("user", userName); articleData.put("now", String.valueOf(now)); conn.hmset(article, articleData); //zset conn.zadd("score:", now + VOTE_SCORE, article); //发布的时候 默认作者本人为文章投票 conn.zadd("time:", now, article); return articleId; } /** * 文章投票 * 1,每一票对应一个常量 * @return */ public void articleVote(Jedis conn, String user, String article) { long cutoff = (System.currentTimeMillis() / 1000) - ONE_WEEK_IN_SECONDS; if (conn.zscore("time:", article) < cutoff){ //计算是否超过文章投票截止时间 System.out.println("文章发布时间太长了"); return; } String articleId = article.substring(article.indexOf(':') + 1); if (conn.sadd("voted:" + articleId, user) == 1) { //如果值不==1 则用户已经投过此文章了 1 标识原set中没有,本次添加成功 //增加score的分值,使其增加VOTE_SCORE conn.zincrby("score:", VOTE_SCORE, article); //修改文章中votes的票数,使其增加1 conn.hincrBy(article, "votes", 1); } } /** * 分页数据 * @param conn * @param page * @return */ public List<Map<String,String>> getArticles(Jedis conn, int page) { return getArticles(conn, page, "score:"); } /** * 根据order获取排名靠前的数据 * @param conn * @param page * @param order * @return */ public List<Map<String,String>> getArticles(Jedis conn, int page, String order) { int start = (page - 1) * ARTICLES_PER_PAGE; int end = start + ARTICLES_PER_PAGE - 1; Set<String> ids = conn.zrevrange(order, start, end); List<Map<String,String>> articles = new ArrayList<Map<String,String>>(); for (String id : ids){ Map<String,String> articleData = conn.hgetAll(id); articleData.put("id", id); articles.add(articleData); } return articles; } /** * 文章分组 * @return */ public void addGroups(Jedis conn, String articleId, String[] toAdd) { String article = "article:" + articleId; for (String group : toAdd) { conn.sadd("group:" + group, article); } } public List<Map<String,String>> getGroupArticles(Jedis conn, String group, int page) { return getGroupArticles(conn, group, page, "score:"); } /** * 按顺序得到某一组内的文章 * 这里会使用到关系型数据库里面的 * Redis Zinterstore 命令计算给定的一个或多个有序集的交集 默认情况下,结果集中某个成员的分数值是所有给定集下该成员分数值之和。 * 使用 WEIGHTS 选项,你可以为 每个 给定有序集 分别 指定一个乘法因子(multiplication factor),每个给定有序集的所有成员的 score 值在传递给聚合函数(aggregation function)之前都要先乘以该有序集的因子。 * 使用 AGGREGATE 选项,你可以指定并集的结果集的聚合方式。默认使用的参数 SUM ,可以将所有集合中某个成员的 score 值之 和 作为结果集中该成员的 score 值;使用参数 MIN ,可以将所有集合中某个成员的 最小 score 值作为结果集中该成员的 score 值;而参数 MAX 则是将所有集合中某个成员的 最大 score 值作为结果集中该成员的 score 值。 * @return */ public List<Map<String,String>> getGroupArticles(Jedis conn, String group, int page, String order) { String key = order + group; if (!conn.exists(key)) { ZParams params = new ZParams().aggregate(ZParams.Aggregate.MAX); conn.zinterstore(key, params, "group:" + group, order); conn.expire(key, 60); } return getArticles(conn, page, key); } private void printArticles(List<Map<String,String>> articles){ for (Map<String,String> article : articles){ System.out.println(" id: " + article.get("id")); for (Map.Entry<String,String> entry : article.entrySet()){ if (entry.getKey().equals("id")){ continue; } System.out.println(" " + entry.getKey() + ": " + entry.getValue()); } } } }
文章中redis采用单机模式,这里小编在写上面代码的时候遇到一个问题,至今没找到原因,有路过的大神希望不吝赐教:
一开始上面代码是使用springboot + rediscluster 模式实现,但是使用redistemplate 执行 zinterstore 的时候报出
ZINTERSTORE can only be executed when all keys map to the same slot
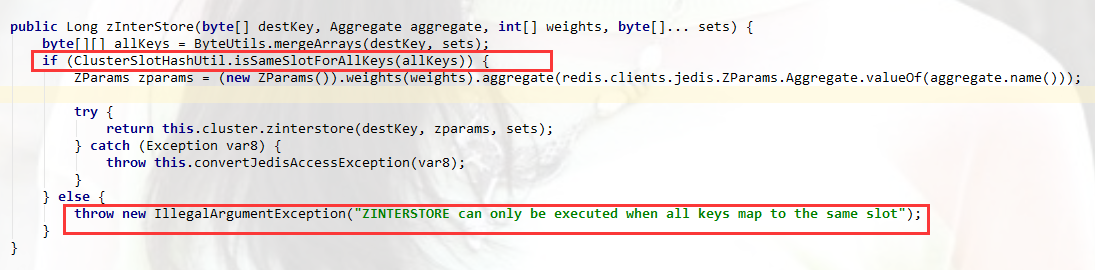
我们知道redis cluster 值是有16384个卡槽分布在集群的master上存储数据的,每个master分别存储部分数据,这里难道需要我把数据集中到一个slot中才能调用此方法吗?找了很久也没找到合适的解决方案,有了解过的朋友希望留言告知。