现在我们已经拍好了需要训练的图片,接下来就是进行训练
流程图:

我们在这里用到了numpy库,NumPy是一个功能强大的Python库,主要用于对多维数组执行计算。
使用numpy的目的是减少python代码中的循环,以及提高数组运算的效率。
对于numpy性能的提升程度,我们可以从这段代码中直观感受到:
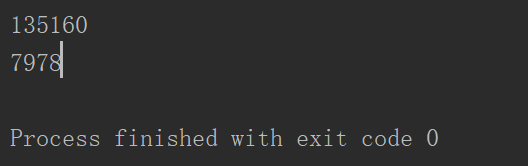
import datetime as dt import numpy as np n = 100000 start = dt.datetime.now() A, B = [], [] for i in range(n): A.append(i ** 2) B.append(i ** 3) C = [] for a,b in zip(A,B): C.append(a+b) t = (dt.datetime.now() -start).microseconds print(t) start = dt.datetime.now() A, B = np.arange(n)**2, np.arange(n)**3 C = A+B t = (dt.datetime.now() - start).microseconds print(t)
我们对列表进行了同样的操作,然后输出两种操作所需要的时间(微秒),可以看到numpy在效率上提高了两个数量级
训练模块的源代码:
import numpy as np from PIL import Image import os import cv2 def train(): path = 'D:/FaceData' # 创建opencv中的LBPH算法的人脸识别器 recognizer = cv2.face.LBPHFaceRecognizer_create() # 依然是运用人脸识别分类器 detector = cv2.CascadeClassifier('./haarcascade_frontalface_default.xml') def getImagesAndLabels(path): # os.path.join()函数: # 连接两个或更多的路径名组件 # os.listdir() 方法 # 用于返回指定的文件夹包含的文件或文件夹的名字的列表。这个列表以字母顺序排列 imagePaths = [os.path.join(path, f)for f in os.listdir(path)] faceSamples = [] ids = [] # 遍历每一张拍到的图片 for imagePath in imagePaths: # 打开图片,并转换成灰度图 PIL_img = Image.open(imagePath).convert('L') # 将原图片的多维数组转为numpy的数组 img_numpy = np.array(PIL_img, 'uint8') # id对应的值是当前用户的第几张照片 id = int(os.path.split(imagePath)[-1].split('.')[1]) # 检测人脸 faces = detector.detectMultiScale(img_numpy) for(x, y, w, h) in faces: # 将人脸范围的numpy数组数据保存到列表中 faceSamples.append(img_numpy[y : y + h, x : x + w]) # 将id值保存到列表中 ids.append(id) return faceSamples, ids faces, ids = getImagesAndLabels(path) # 对图片进行训练,将训练文件保存在指定路径 recognizer.train(faces, np.array(ids)) recognizer.write(r'face_trainer rainer.yml') print('{0} faces trained.'.format(len(np.unique(ids)))) if __name__ == '__main__': train()