用sklearn 最方便:

在MNIST手写字数据集中,我们导入的数据和标签都是预先处理好的,但是在实际的训练中,数据和标签往往需要自己进行处理。
以手写数字识别为例,我们需要将0-9共十个数字标签转化成onehot标签。例如:数字标签“6”转化为onehot标签就是[0,0,0,0,0,0,1,0,0,0].
首先获取需要处理的标签的个数:
batch_size = tf.size(labels)
1
假设输入了6张手写字图片,那么对应的标签数为6,batch_size=6.
tf.size(input) 函数为获取输入tensor的元素数量。
例:设 t = [[1,2],[3,4]],则 tf.size(t) 的结果为4。
然后我们知道onehot标签的shape为[batch_size,10],采用稀疏编码的方法,在onehot标签中选择能够代表标签的位置,将其置为1,其余位置置为0。因此要选择onehot中需要置为1的位置的坐标。
labels = tf.expand_dims(labels, 1) indices = tf.expand_dims(tf.range(0, batch_size, 1), 1) concated = tf.concat([indices, labels],1)
这里得到的concated就是所要置为1 的位置的坐标了。
tf.expand_dims(input, axis=None)函数表示给定输入tensor,在输入shape的维度索引轴axis处插入为1的尺寸。 尺寸索引轴从0开始; 如果axis为负数,则从后向前计数。列表内容
例:
t2是shape为[2,3,5]的一个tensor,则:
shape(expand_dims(t2, 0)) ==> [1, 2, 3, 5] shape(expand_dims(t2, 2)) ==> [2, 3, 1, 5] shape(expand_dims(t2, 3)) ==> [2, 3, 5, 1] shape(expand_dims(t2, -1)) ==> [2, 3, 5, 1]
tf.range(start, limit, delta=1)函数是用来生成tensor等差序列,序列在start到limit之间(包含start不包含limit),步长为dalta。
tf.concat(values,concat_dim )函数用来连接两个tensor。老版本的是concat_dim参数在前,values参数在后。
参数:
values:表示两个或者一组待连接的tensor.
concat_dim:表示在哪一维上连接,必须是一个数.
如果concat_dim=0,表示在第一个维度上连,相当于叠放到列上;如果concat_dim是1,表示在第二个维度上连。
例:
t1 = [[1, 2, 3], [4, 5, 6]] t2 = [[7, 8, 9], [10, 11, 12]] tf.concat(0, [t1, t2]) == > [[1, 2, 3], [4, 5, 6], [7, 8, 9], [10, 11, 12]] tf.concat(1, [t1, t2]) ==> [[1, 2, 3, 7, 8, 9], [4, 5, 6, 10, 11, 12]]
这里要注意的是,如果values是两个向量,它们是无法调用tf.concat()函数来进行连接的,因为向量对应的shape只有一个维度,不能在第二维上连了。虽然实际中两个向量可以在行上相连,但是放在程序里是会报错的。
如果要连接两个向量,必须要调用tf.expand_dims()函数来扩维,这也就是在调用tf.concat()函数前先调用tf.expand_dims()函数的原因。
最后,将坐标给定的位置置为1,其余位置置为0,生成onehot标签。
onehot_labels = tf.sparse_to_dense(concated, tf.stack([batch_size, 10]), 1.0, 0.0)
输出了一个对应标签位为1,其余位为0的,shape为[batch_size,10]的onehot标签。
tf.sparse_to_dense(sparse_indices, output_shape, sparse_values, default_value)可以用来生成稀疏矩阵。
参数:
sparse_indices:稀疏矩阵中那些个别元素对应的索引值。
有三种情况:
sparse_indices是个数,那么它只能指定一维矩阵的某一个元素.
sparse_indices是个向量,那么它可以指定一维矩阵的多个元素.
sparse_indices是个矩阵,那么它可以指定二维矩阵的多个元素.
output_shape:输出的稀疏矩阵的shape.
sparse_values:个别元素的值,即第一个参数选中的位置的值.
分为两种情况:
sparse_values是个数,那么所有索引指定的位置都用这个数.
sparse_values是个向量,那么输出矩阵的某一行向量里某一行对应的数(因此这里向量的长度应该和输出矩阵的行数应该对应,不然会报错).
default_value:未指定元素的默认值,如果是稀疏矩阵,则应该为0.
tf.stack(values, axis=0)函数将一系列rank-R的tensor打包为一个rank-(R+1)的tensor,老版本里用的是tf.ack()函数。
例:
x = [1,4] y = [2,5] z = [3,6] tf.stack([x, y, z]) => [[1, 4], [2, 5], [3, 6]] # 沿着第一维stack tf.stack([x, y, z], axis=1) => [[1, 2, 3], [4, 5, 6]]
举个栗子可以更直观的理解这段代码:
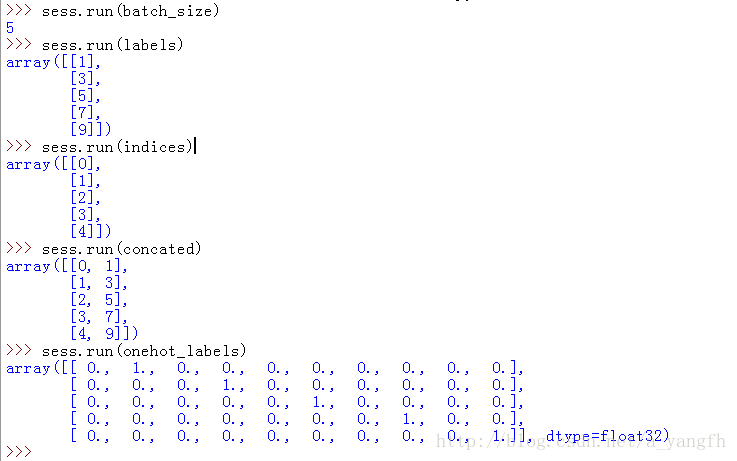
假设一个batch有5个样本,其label分别为1,3,5,7,9,则
import tensorflow as tf sess = tf.Session() labels = [1,3,5,7,9] batch_size = tf.size(labels) labels = tf.expand_dims(labels, 1) indices = tf.expand_dims(tf.range(0, batch_size, 1), 1) concated = tf.concat([indices, labels],1) onehot_labels = tf.sparse_to_dense(concated, tf.stack([batch_size, 10]), 1.0, 0.0)
采用sess.run()函数来查看每一个函数的输出,结果为:
————————————————
原文链接:https://blog.csdn.net/a_yangfh/article/details/77911126