大数据
-
概述
-
大数据是新处理模式才能具备更多的决策力,洞察力,流程优化能力,来适应海量高增长率,多样化的数据资产。
-
-
大数据面临的问题
- 怎么存储海量数据(kb,mb,gb,tb,pb,eb,zb)
- 怎么对数据进行降噪处理(对数据进行清洗,使得数据变废为宝,提取有用的数据,减少不必要的数据资源空间的释放)
-
处理方案
- hadoop 是一种分布式文件存储系统来解决存储的问题,其中hdfs用来解决数据存储问题,mapReduce来解决如何进行建造处理
-
hadoop是什么?
-
由来?
-
根据google发布的3篇文章
-
google File System
-
Google MapReduce 获得启发 hadoop之父 Doug Cutting 用java语言解决大数据所面临的问题
-
- 概述
- hadoop 是apache基金会的一款开源的分布式的基础架构,它实现了高容错率,乃至高吞吐量,低成本,由于hadoop用java语言编写可以用在linux是非常可靠的,hadoop核心设计是hdfs和mapReudce以及Hbase分别对应这又google3篇文章,解决了大数据所面临的问题
- hdfs 分布式文件存储系统
- mapreduce 分布式计算框架 只需要少量的java代码 就能实现分布式计算
- hbase 基于HDFS 的列式存储的NoSql
- hadoop 是apache基金会的一款开源的分布式的基础架构,它实现了高容错率,乃至高吞吐量,低成本,由于hadoop用java语言编写可以用在linux是非常可靠的,hadoop核心设计是hdfs和mapReudce以及Hbase分别对应这又google3篇文章,解决了大数据所面临的问题
- hdfs
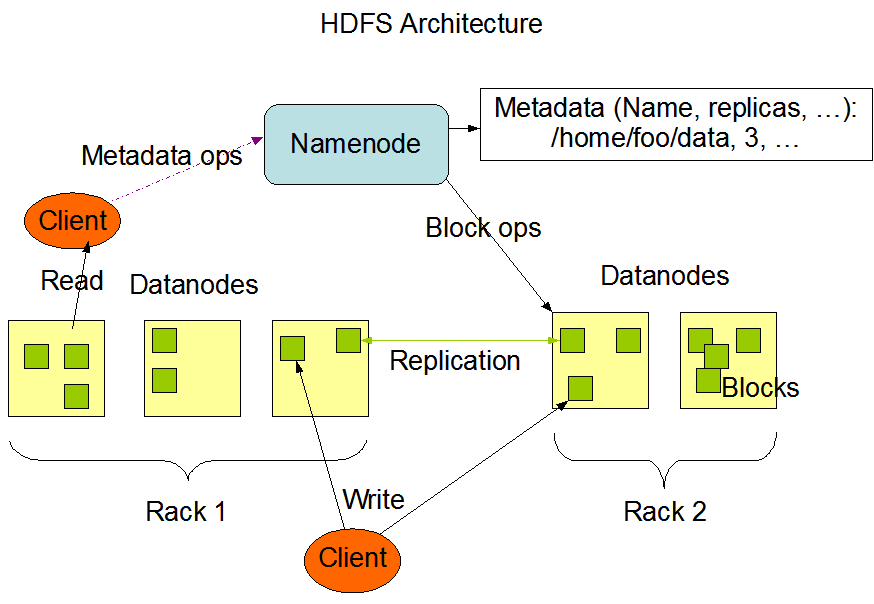
- 分布式文件存储系统,其中有nameNode,dataNode,block,nameNode负责管理着dataNode,dataNode负责接收读写请求和nameNode协调工作,负责block快的创建和复制,nameNode存储着元数据,datanode和block中的映射关系
-
-
- nameNode 存储元数据 (用来描述数据的数据),负责管理dataNode 与dataNode 协调
- dataNode 负责nameNode的读写请求,用来存储数据块的节点,向nameNode报告自己的快信息
- block 数据快 hdfs 最小默认128mb 为一块,没一块默认有3个副本
- rack 机架 用来放置存储节点,提高容错率,高吞吐量。优化存储和计算
-
nameNode和SecondaryNameNode 之间的关系

fsimage 元数据的备份 会被加载到内存当中去
edits 读写请求的日志文件
nameNode 会在启动的时候加载 fsimage 和 edits ,这2个文件不会凭空出现,所以要格式化nameNode
当用户在操作文件时,由于edits的增加,导致了nameNode启动会越来越慢,所以就出现了SecondaryNameNode 可以简单来说,他是nameNode的一个副本,当到达检查点的时候,也就是hdfs 默认 1个小时 或者 日志操作量级达到100w条的时候,此时SecondaryNameNode会将fsimage和edits加载过来进行合并,此时,若是有读写请求过来的时候会被加载到一个叫edits-inprogess的文件进行记录读写请求,fsimage和edits合并之后会成为一个新的fsimage,而此时edits-inprogess会改名为edits
-
- 小问题 : 为什么 一个块的大小默认是128mb
- 在hadoop 1x 的时候默认快的大小为64 但是随着硬盘的变大 在hadoop2x的时候 快的大小 变成了128m ,此时默认最佳状态是寻址时间是传输速度的100/1
- 小问题 : 为什么 一个块的大小默认是128mb
- mapReduce
-
- 概念 : 分布式计算框架。用于大规模的数据计算,采用并行计算,充分的利用了dataNode的物理存储机制,采用了(Map)映射(Reduce)规约,他极大的方便了程序员不会分布式并行编程的情况下,将自己的程序运行在分布式系统上 ,思想就是 将一个键值对 放在map 里 然后 使用Reduce 进行统筹规划,保证所有的映射的键值队中每一个共享的键组
- mapReduce最擅长做的就是分而治之 ;
- 分 就是把一个庞大复杂的任务分解成若干个简单的任务来处理,简单的任务包含有3层
- 相对于原来的数据要大大缩小
- 所有的任务中并行计算,且互不干扰
- 就近计算原则
- 治之 Reduce 负责对map计算的结果进行统筹汇总
- 要实现mapReduce 首先得借助一个资源调度平台 Yarn
-
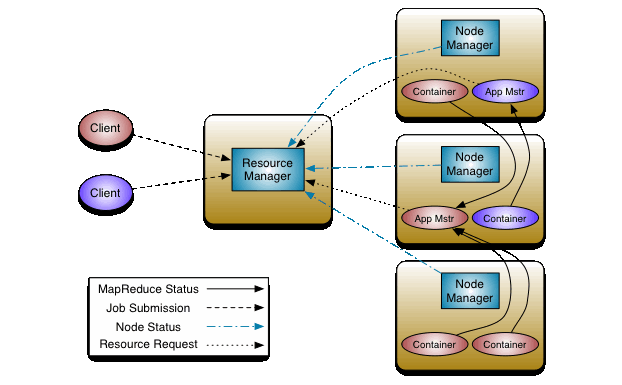
- Yarn
-
- 概念 Yarn 作为资源调度平台 ,其中有一个最大的管理者,ResourceManager 负责着资源的统筹分配,还有各个节点的管理着,NodeManager 负责向ResourceManager进行资源状态的报告,在NodeManager 中还有一个 MRAppMaster ,负责 申请计算资源,协调计算任务并和NodeManager一起执行监视任务
- ResourceManager 负责对集群的整体资源和计算做统筹规划
- NodeManager 管理主机上的计算组员,负责报告自身的状态信息
- MRAppMaster 负责向ResourceManager负责申请资源,协调计算任务
- YarnChild 做实际的计算任务
- Container 计算资源的抽象单位
-