1.修改工作空间编码方式为UTF-8
window-->properties-->General-->Workspace-->Other-->UTF-8

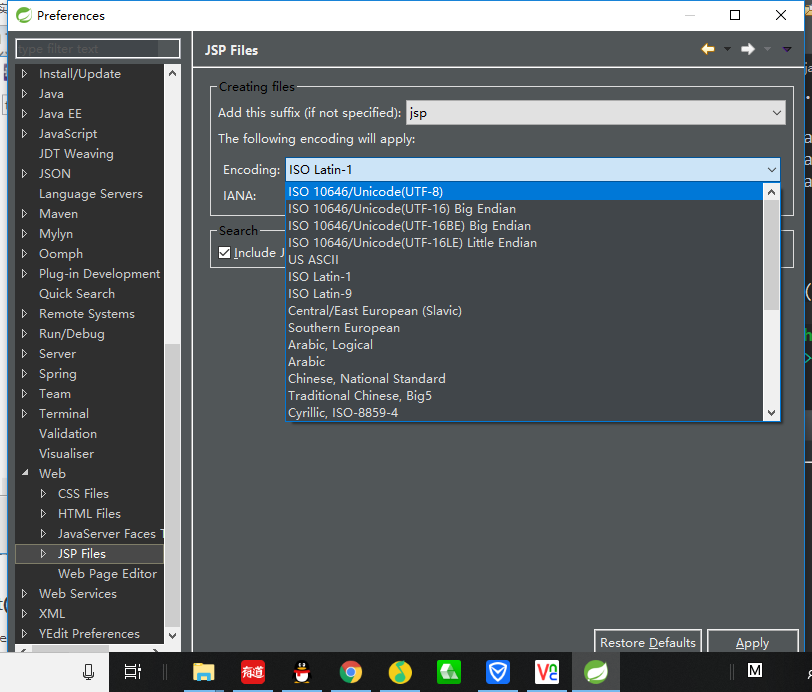
2.创建的jsp全部修改为UTF-8
修改jsp默认编码方式 window --> preference --> Web --> JSP Files --> Encoding 修改为UTF-8
3.在doGet()/doPost里面加上以下代码
request.setCharacterEncoding("UTF-8");
response.setContentType("text/html; charset=UTF-8");
4.对于get方式提交到Servlet的数据,中文乱码处理请参照下面示例
String username = request.getParameter("username");
username = new String(username.getBytes("ISO-8859-1"),"UTF-8");
5.mysql乱码处理,在原来的URL后面加上?useUnicode=true&characterEncoding=UTF-8
jdbcUrl=jdbc:mysql://localhos:3306/greadManagert?useUnicode=true&characterEncoding=UTF-8
- 如果在xml中识别不了&符号,要使用实体字符"&"加“;”来代替&,即
jdbcUrl=jdbc:mysql://localhos:3306/greadManagert?useUnicode=true&characterEncoding=UTF-8
6.修改tomcat配置文件server.xml,63行,加上URIEncoding="utf-8"
<Connector URIEncoding="utf-8" connectionTimeout="20000" port="8080" protocol="HTTP/1.1" redirectPort="8443"/>
7.配置乱码过滤器
<!-- 乱码过滤器 -->
<filter>
<filter-name>encodingFilter</filter-name>
<filter-class>org.springframework.web.filter.CharacterEncodingFilter</filter-class>
<async-supported>true</async-supported>
<init-param>
<param-name>encoding</param-name>
<param-value>UTF-8</param-value>
</init-param>
</filter>
<filter-mapping>
<filter-name>encodingFilter</filter-name>
<url-pattern>/*</url-pattern>
</filter-mapping>