假设有一张6000万行数据的testdb表,预计testdb全表扫描1次需要2个小时,参考过程如下:
1、在1点钟,用户A发出了select * from testdb;此时不管将来testdb怎么变化,正确的结果应该是用户A会看到在1点钟这个时刻的内容。
2、在1点30分,用户B执行了update命令,更新了testdb表中的第4100万行的这条记录,这时,用户A的全表扫描还没有到达第4100万条。毫无疑问,这个时候,第4100万行的这条记录是被写入了回滚段,假设是回滚段UNDOTS1,如果用户A的全表扫描到达了第4100万行,是应该会正确的从回滚段UNDOTS1中读取出1点钟时刻的内容的。
3、这时,用户B将他刚才做的操作提交了,但是这时,系统仍然可以给用户A提供正确的数据,因为那第4100万行记录的内容仍然还在回滚段UNDOTS1里,系统可以根据SCN到回滚段里找到正确的数据,但要注意到,这时记录在UNDOTS1里的第4100万行记录已经发生了重大的改变:就是第4100万行在回滚段UNDOTS1里的数据有可能随时被覆盖掉,因为这条记录已经被提交了!
4、由于用户A的查询时间漫长,而业务在一直不断的进行,UNDOTS1回滚段在被多个不同的transaction使用着,这个回滚段里的extent循环到了第4100万行数据所在的extent,由于这条记录已经被标记提交了,所以这个extent是可以被其他transaction覆盖掉的!
5、到了1点45分,用户A的查询终于到了第4100万行,而这时已经出现了第4条说的情况,需要到回滚段UNDOTS1去找数据,但是已经被覆盖掉了,这时就出现了ORA-01555错误。
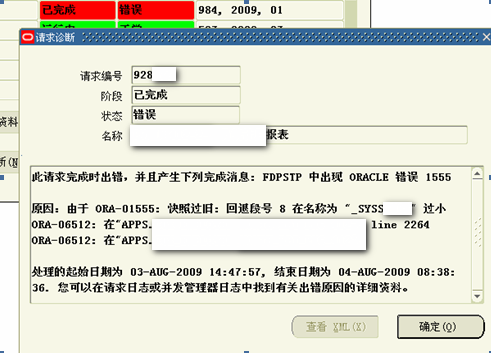
原因分析:"报表"程序执行时间漫长,在程序查询的过程中其他用户对"报表"进行了更新,被更新的数据写入了回滚段,当程序到回滚段找数据时,发现数据已经被覆盖掉,于是就出现了ORA-01555错误。另外"报表"程序执行效率不高也会造成ORA-01555错误。
解决办法:
1、扩大回滚段,因为回滚段是循环使用的,如果回滚段足够大,那么那些被提交的数据就能保存足够长的时间,使那些大事务完成一致性读取。之前EBS系统UNDO表空间为9GB,目前为10GB。见下图:

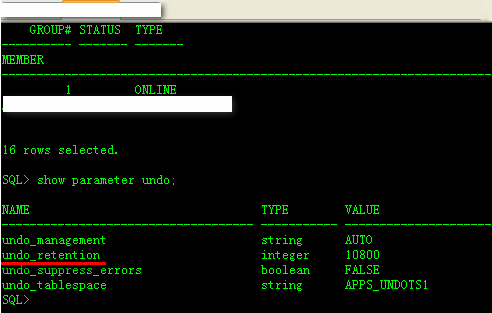
2、增加undo_retention时间,因为UNDO回滚段是循环使用,里面的数据可能随时被循环覆盖掉,如果设置undo_retention时间更长,那么在retention规定的时间内,任何其他事务都不能覆盖这些数据。目前EBS系统undo_retention为10800秒(3个小时)。见下图:
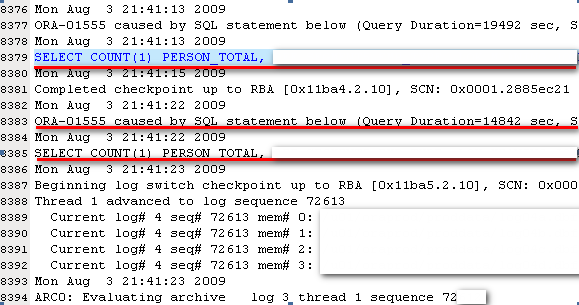
3、最重要的一点就是优化程序相关查询语句,减少查询语句的一致性读,降低读取不到回滚段数据的风险。所有的出错信息都会纪录到数据库日志alert_PROD.log文件中,下图红线部分是一条SQL查询词句,ORA-01555很有可能是这条语句造成,把这条语句提供给开发人员来分析和优化程序代码。