引言
王者荣耀大家都玩过吧,没玩过的也应该听说过,作为时下最火的手机MOBA游戏,咳咳,好像跑题了。我们今天的重点是爬取王者荣耀所有英雄的所有皮肤,而且仅仅使用20行Python代码即可完成。
准备工作
爬取皮肤本身并不难,难点在于分析,我们首先得得到皮肤图片的url地址,话不多说,我们马上来到王者荣耀的官网:
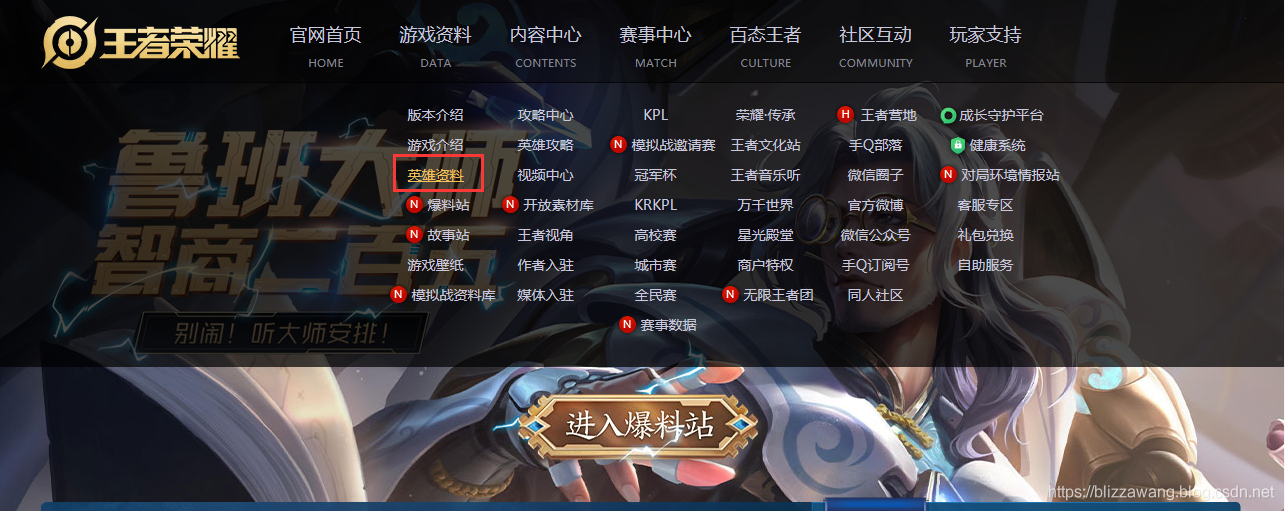
我们点击英雄资料,然后随意地选择一位英雄,接着F12打开调试台,找到英雄原皮肤的图片地址:
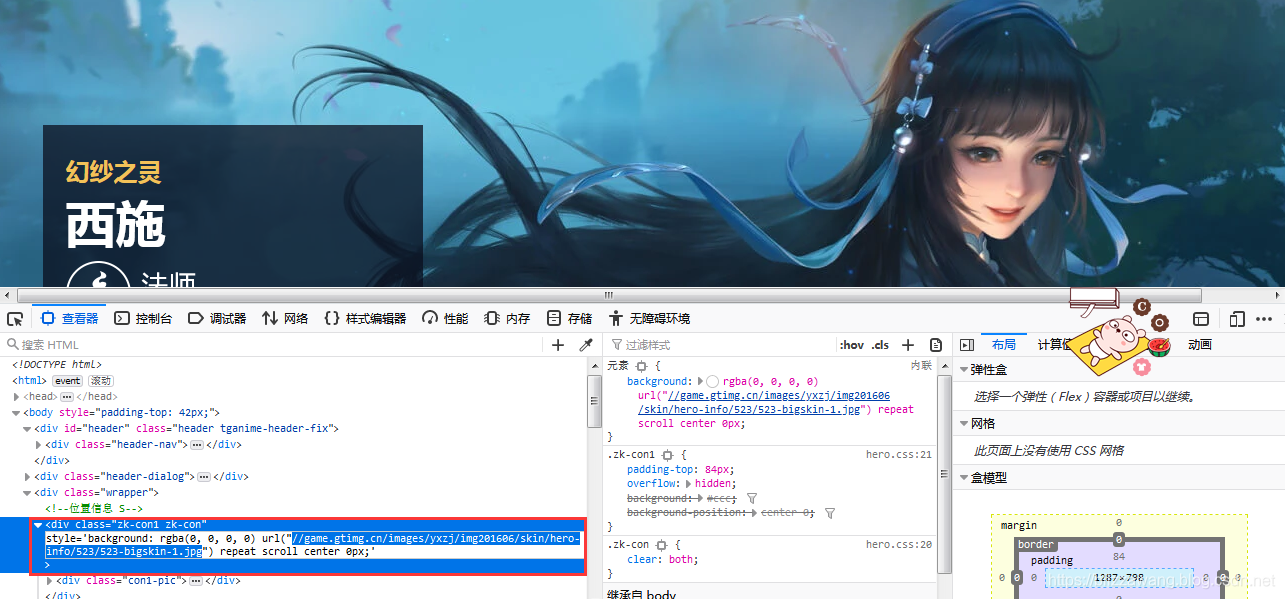
接着,我们切换一下英雄的皮肤,会发现图片地址没有明显的变化,只是最后的数字序号改变了,我们将两个皮肤图片的地址放在一起比较一下:
http://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/523/523-bigskin-1.jpg
http://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/523/523-bigskin-2.jpg
我们可以猜测,对于同一个英雄的皮肤图片地址,仅仅是最后的数字序号不同,为了证实我们的猜想,我们可以继续找出一个英雄的全皮肤图片,找一个皮肤多一点的,例如我这里找的是孙尚香,将它的所有皮肤图片地址放在一起比较:
http://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/111/111-bigskin-1.jpg
http://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/111/111-bigskin-2.jpg
http://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/111/111-bigskin-3.jpg
http://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/111/111-bigskin-4.jpg
http://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/111/111-bigskin-5.jpg
http://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/111/111-bigskin-6.jpg
http://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/111/111-bigskin-7.jpg
由此我们得出结论,同一个英雄的皮肤图片路径从1开始依次递增,我们再来看看不同英雄之间是如何区分的。会发现,不管皮肤图片如何改变,浏览器上方的地址始终是不变的,所以我们将两个不同英雄的url地址放到一起比较一下:
https://pvp.qq.com/web201605/herodetail/523.shtml
https://pvp.qq.com/web201605/herodetail/111.shtml
乍一看,似乎没有什么规律,但我们要从这里发现一点,就是最后的数字其实控制的是哪个英雄,我们暂且认为它是英雄的编号,可不幸的是,英雄编号之间好像没有什么规律,不用着急,我们再到官网上找找线索。
在英雄资料界面,我们打开F12调试台,通过抓取网络请求,我发现了几个文件:

点击网络,然后点击XHR,就可以看到这几个文件,看到文件的名字大家应该就清楚了,这些文件存储的就是英雄列表信息,我们点击查看一下:
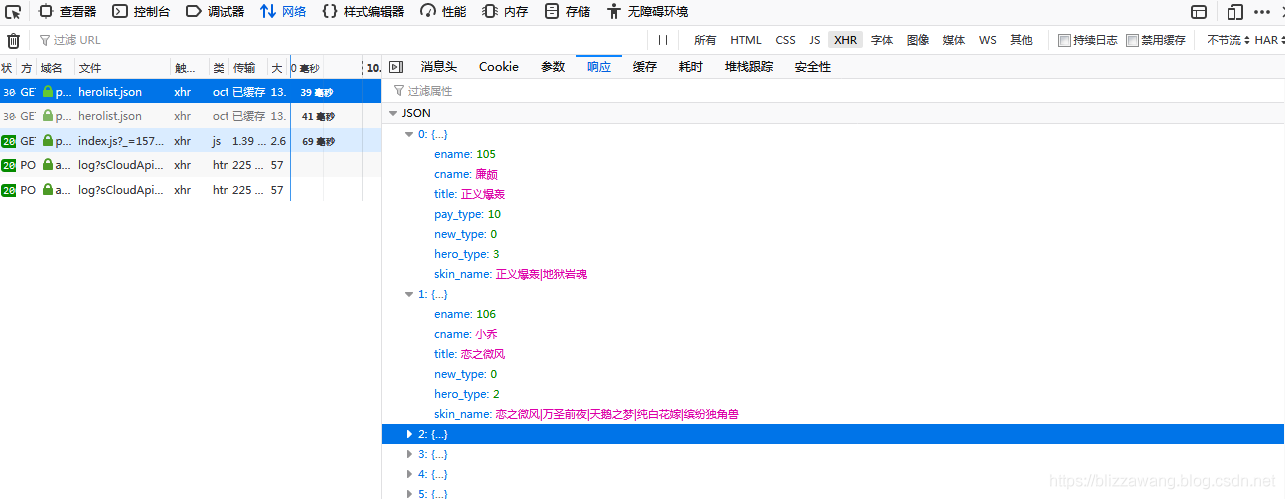
没错,这里存储的就是英雄信息,包括英雄的名字,英雄编号等等其它信息,我们可以试试这些信息的准确性,例如小乔的ename,也就是英雄编号为106,所以按照之前的想法,英雄小乔的详情地址应为:https://pvp.qq.com/web201605/herodetail/106.shtml
经过尝试后发现确实如此。
到这里,准备工作就完成了,其实进行到这里,整个工程就完成了一半了,接下来就是代码的实现了。
代码实现
首先我们创建一个Python文件,然后导入os和requests模块。
按照前面的步骤,我们首先需要获取到英雄列表信息,也就是herolist.json文件,文件地址为:https://pvp.qq.com/web201605/js/herolist.json,这在调试台中可以找到。
那么我们首先就要通过这个地址获取到英雄列表信息的json数据,然后解析json数据,将有用的信息提取出来:
url = 'https://pvp.qq.com/web201605/js/herolist.json'
herolist = requests.get(url) # 获取英雄列表json文件
herolist_json = herolist.json() # 转化为json格式
hero_name = list(map(lambda x: x['cname'], herolist.json())) # 提取英雄的名字
hero_number = list(map(lambda x: x['ename'], herolist.json())) # 提取英雄的编号
这样我们就获取到了英雄名字和编号,可以输出测试一下:
拿到了英雄编号之后,事情就变得很简单了,只需拼接一下url地址即可:
http://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/' + hero_number + '/' + hero_number + '-bigskin-1.jpg,这样可以获取到所有英雄的皮肤图片了,但是这里会有一个问题,英雄的皮肤是有多有少的,有的英雄只有两个皮肤,有的却有六七个,所以图片编号的最大值我们并不清楚,这里我采用了一个比较笨的办法,就是让一个变量从1到10依次递增去拼接图片地址,如果遇到没有的图片我们就不处理,因为没有一个英雄的皮肤超过了10个,所以我们就能获取到所有的图片了。下面看代码实现:
# 下载图片
def downloadPic():
i = 0
for j in hero_number:
# 创建文件夹
os.mkdir("C:\Users\Administrator\Desktop\wzry\" + hero_name[i])
# 进入创建好的文件夹
os.chdir("C:\Users\Administrator\Desktop\wzry\" + hero_name[i])
i += 1
for k in range(10):
# 拼接url
onehero_link = 'http://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/' + str(j) + '/' + str(
j) + '-bigskin-' + str(k) + '.jpg'
im = requests.get(onehero_link) # 请求url
if im.status_code == 200:
open(str(k) + '.jpg', 'wb').write(im.content) # 写入文件
实现非常地简单,代码注释也已经写得很清楚了,有了这个函数之后,我们只需调用一下,就可以下载图片了,整个程序的完整代码如下:
import os
import requests
url = 'https://pvp.qq.com/web201605/js/herolist.json'
herolist = requests.get(url) # 获取英雄列表json文件
herolist_json = herolist.json() # 转化为json格式
hero_name = list(map(lambda x: x['cname'], herolist.json())) # 提取英雄的名字
hero_number = list(map(lambda x: x['ename'], herolist.json())) # 提取英雄的编号
# 下载图片
def downloadPic():
i = 0
for j in hero_number:
# 创建文件夹
os.mkdir("C:\Users\Administrator\Desktop\wzry\" + hero_name[i])
# 进入创建好的文件夹
os.chdir("C:\Users\Administrator\Desktop\wzry\" + hero_name[i])
i += 1
for k in range(10):
# 拼接url
onehero_link = 'http://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/' + str(j) + '/' + str(
j) + '-bigskin-' + str(k) + '.jpg'
im = requests.get(onehero_link) # 请求url
if im.status_code == 200:
open(str(k) + '.jpg', 'wb').write(im.content) # 写入文件
downloadPic()
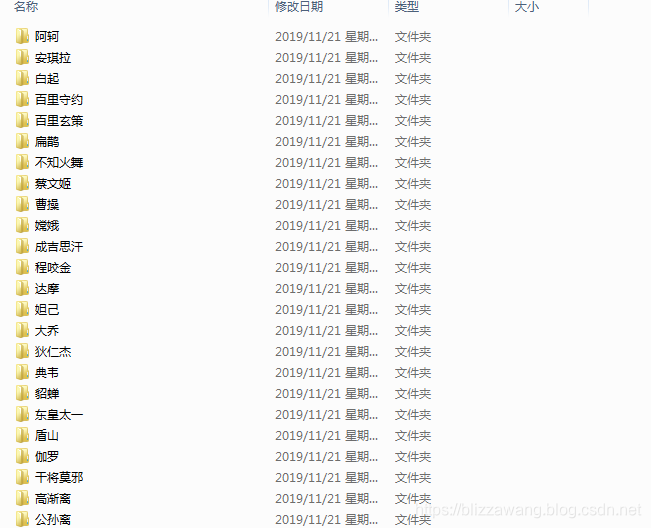
除去注释,接近20行的代码我们就完成了王者荣耀全英雄皮肤的爬取,是不是非常简单呢?我们可以测试一下这个程序,首先要在桌面上创建一个文件夹,名为wzry,因为这里的代码我已经写死了,如果要修改的话大家也可以进行修改,文件夹创建完成后点击运行即可,等待片刻,图片就全部下载完成了。

对于程序中json字符串的解析,我们还可以使用jsonpath模块来进行,使用该模块能够更加快捷地获取到我们想要的信息,解析方式如下:
hero_name = jsonpath.jsonpath(html_json, "$..cname")
hero_number = jsonpath.jsonpath(html_json, "$..ename")
该方法接收一个json字符串和解析规则,$..cname则表示从根目录下找寻任意位置的以cname为键的值,并放入字典中。
结尾
爬虫是非常有趣的,因为它非常直观,视觉冲击感强,写出来也很有成就感,爬虫虽然强大,但千万不能随意爬取隐私信息。
最后,如果对文中程序有更好的建议,欢迎评论区留言。