20181312 2019-2020-2 《Python程序设计》Python综合实践报告
课程:《Python程序设计》
班级:1813
姓名:谢绎
学号:20181312
实验教师:王志强
实验日期:2020年6月6日
必修/选修:公选课
1.实验内容
数据可视化:给歌手的歌词做词云展示
2. 实验设计
数据获取:使用 Python 爬虫获取 HTML,用 XPath 对歌曲的 ID、名称进行解析。
歌词合并:通过网易云音乐的 API 接口获取每首歌的歌词,将所有的歌词合并得到一个变量。
词云分析:创建 WordCloud 词云类,分析得到的歌词文本,最后得到可视化的图片。
3. 实验过程及结果
词云制作
词云也叫文字云,它帮助我们统计文本中高频出现的词,过滤掉某些常用词(比如“作曲”“作词”),将文本中的重要关键词进行可视化,方便分析者更好更快地了解文本的重点,同时还具有一定的美观度。
Python 提供了词云工具 WordCloud,使用pip install wordcloud安装后,就可以创建一个词云,构造方法如下:
from wordcloud import WordCloud
wc = WordCloud(
background_color='white',# 设置背景颜色
mask=backgroud_Image,# 设置背景图片
font_path='wc.ttf', # 设置字体,针对中文的情况需要设置中文字体,否则显示乱码,这里的wc.ttf是一种中文字体
max_words=100, # 设置最大的字数
stopwords=STOPWORDS,# 设置停用词,后面增加停用词列表
max_font_size=150,# 设置字体最大值
width=2000,# 设置画布的宽度
height=1200,# 设置画布的高度
random_state=30# 设置多少种随机状态,即多少种颜色
)
以上代码展示了WordCloudd的主要参数。创建好 WordCloud 类之后,就可以使用 wordcloud=generate(text) 方法生成词云,传入的参数 text 代表你要分析的文本,最后使用 wordcloud.tofile(“wordcloud.jpg”) 函数,将得到的词云图像直接保存为图片格式文件。
python自带可视化工具Matplotlib
import matplotlib.pyplot as plt
plt.imshow(wordcloud)
plt.axis("off")# 无需展示坐标轴,所以关闭
plt.show()# 查看图片
在pycharm中使用Matplotlib便可看到
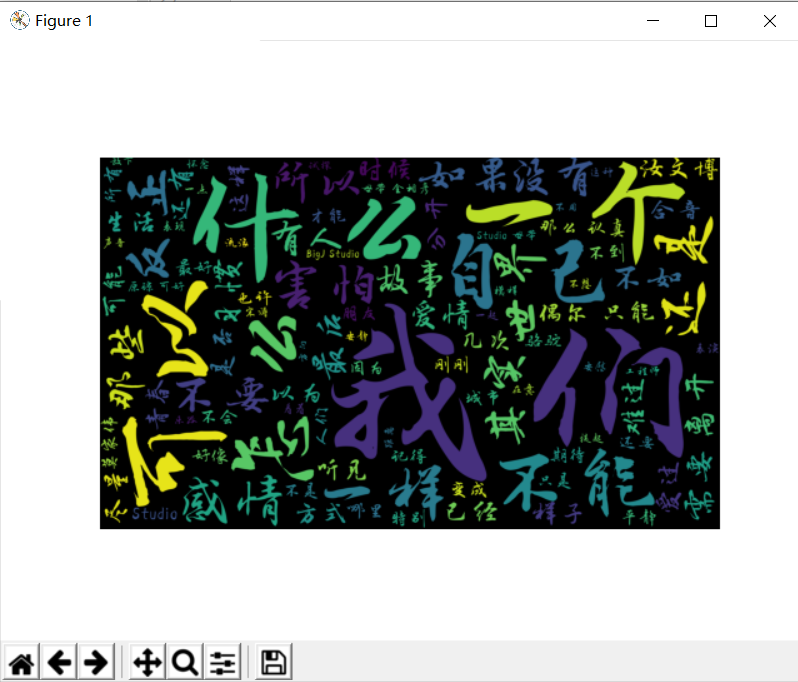
看到图片之后,发现了一些自己不想要的词,或者是与歌词无关的词,我们可以把这些词设置为停用词,编写 remove_stop_words 函数,从文本中去掉:
def remove_stop_words(f):
stop_words = ['学会', '就是', '什么'] #这是几个示例词语
for stop_word in stop_words:
f = f.replace(stop_word, '')
return f
在结算词云前调用 f = remove_stop_words(f) 方法,最后运行可以得到如下的结果:

Xpath介绍
XPath 是 XML 的路径语言,实际上是通过元素和属性进行导航,帮我们定位位置。它有几种常用的路径表达方式。

- xpath(‘node’) 选取了 node 节点的所有子节点
- xpath(’/div’) 从根节点上选取 div 节点
- xpath(’//div’) 选取所有的 div 节点
- xpath(’./div’) 选取当前节点下的 div 节点
- xpath(’…’) 回到上一个节点
- xpath(’//@id’) 选取所有的 id 属性
- xpath(’//book[@id]’) 选取所有拥有名为 id 的属性的 book 元素
- xpath(’//book[@id=“abc”]’) 选取所有 book 元素,且这些 book 元素拥有 id= "abc"的属性
- xpath(’//book/title | //book/price’) 选取 book 元素的所有 title 和 price 元素。
这里使用XPath定位,并且用到 Python 的解析库lxml。只需要调用 HTML 解析命令,然后再对 HTML 进行 XPath 函数的调用,即可完成解析。
例如:我们想要定位到 HTML 中的所有列表项目,可以采用如下代码。
from lxml import etree
html = etree.HTML(html)
result = html.xpath('//li')
JSON 介绍
JSON 是一种轻量级的交互方式,在 Python 中有 JSON 库,可以将 JSON 对象转换成为 Python 对象,使得对数据进行的解析变得更方便。
这是一段将 JSON 格式转换成 Python 对象的代码示例:
import json
jsonData = '{"a":1,"b":2,"c":3,"d":4,"e":5}';
input0 = json.loads(jsonData)
print input0
给毛不易的歌词制作词云
- 准备阶段
- Python爬虫获取HTML歌曲列表
- 用XPath对歌曲的 ID、名称进行解析
- 通过网易云音乐的 API 接口获取每首歌的歌词
- 将所有的歌词合并得到一个歌词文本变量
- 词云分析
- 创建 WordCloud 词云类设置词云模型
- 通过歌词生成词云
- 词云可视化
- 根据图片增加停用词并重复前两步直到满意为止
基于以上流程,设计出了如下代码:
import requests
import re
from wordcloud import WordCloud
import matplotlib.pyplot as plt
import jieba
from lxml import etree
headers = {
'Referer': 'http://music.163.com',
'Host': 'music.163.com',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'User-Agent': 'Chrome/10'
}
# 得到某一首歌的歌词
def get_song_lyric(headers, lyric_url):
res = requests.request('GET', lyric_url, headers=headers)
if 'lrc' in res.json():
lyric = res.json()['lrc']['lyric']
new_lyric = re.sub(r'[d:.[]]', '', lyric)
return new_lyric
else:
return ''
print((res.json()))
# 去掉停用词
def remove_stop_words(f):
stop_words = ['作词', '作曲', '编曲', 'Arranger', '录音', '混音', '人声', 'Vocal', '弦乐', 'Keyboard', '键盘', '编辑', '助理', 'Assistants', 'Mixing', 'Editing', 'Recording', '音乐', '制作', 'Producer', '发行', 'produced', 'and', 'distributed', '不易', '李越', '李杨', '李游', '国际', '首席', '韦伟', '爱乐乐团', 'TEC', '版权', '祝薇', 'Production', '毛', '智慧', 'Oldbanana', '配唱', '合唱团', '哇哇 哇哇', '工作室', '和 声', '宋涛', 'mpany', 'Backing', 'Produced', '出品人', 'Choirs', 'Arranged', '李朋', '钢琴', '编写', '刘卓', 'Guitar', 'Company', '公司', 'Co', 'Ltd', '刘磊', 'Liu', 'Lei', '李健', '赵兆', 'Wajijiwa', 'Entertainment', 'Tianjin', '版权', 'Philharmonic', 'Orchestra', 'Avi', 'NY', 'Studio', '何文锐', 'He', '唧唧', 'EFO', 'Li', 'Yue', 'Mao', 'Buyi', '薛峰', '贝斯', 'Bass', '大狗', 'Mastering', 'Joe', '郭舒文', 'by', 'Sound', 'WenRui', 'OP', 'LaPorta', 'International', 'Master', 'Strings', 'Sterling', '邢铜', '母带', 'Beijing', '吉他', 'guitar', '光合', '声动', '野火', '春风', 'mposer', 'Arrangement', '哇哇 出品', '韩阳', 'Drum', 'Ry', 'Merrill', 'Lyricist', '哇哇 /( /) /, /n出品', '哇哇 ×', '哇哇', '出品 哇哇']
for stop_word in stop_words:
f = f.replace(stop_word, '')
return f
# 生成词云
def create_word_cloud(f):
print('根据词频,开始生成词云!')
f = remove_stop_words(f)
cut_text = " ".join(jieba.cut(f, cut_all=False, HMM=True))
wc = WordCloud(
font_path="wc.ttf",
max_words=100,
width=2000,
height=1200,
)
print(cut_text)
wordcloud = wc.generate(cut_text)
# 写词云图片
wordcloud.to_file("wordcloudmby.jpg")
# 显示词云文件
plt.imshow(wordcloud)
plt.axis("off")
plt.show()
# 得到指定歌手页面 热门前50的歌曲ID,歌曲名
def get_songs(artist_id):
page_url = 'https://music.163.com/artist?id=' + artist_id
# 获取网页HTML
res = requests.request('GET', page_url, headers=headers)
# 用XPath解析 前50首热门歌曲
html = etree.HTML(res.text)
href_xpath = "//*[@id='hotsong-list']//a/@href"
name_xpath = "//*[@id='hotsong-list']//a/text()"
hrefs = html.xpath(href_xpath)
names = html.xpath(name_xpath)
# 设置热门歌曲的ID,歌曲名称
song_ids = []
song_names = []
for href, name in zip(hrefs, names):
song_ids.append(href[9:])
song_names.append(name)
print((href, ' ', name))
return song_ids, song_names
# 设置歌手ID,毛不易为12138269
artist_id = '12138269'
[song_ids, song_names] = get_songs(artist_id)
# 所有歌词
all_word = ''
# 获取每首歌歌词
for (song_id, song_name) in zip(song_ids, song_names):
# 歌词API URL
lyric_url = 'http://music.163.com/api/song/lyric?os=pc&id=' + song_id + '&lv=-1&kv=-1&tv=-1'
lyric = get_song_lyric(headers, lyric_url)
all_word = all_word + ' ' + lyric
print(song_name)
# 根据词频 生成词云
create_word_cloud(all_word)
get_songs 函数可以得到指定歌手页面中热门前 50 的歌曲 ID,歌曲名。在这个函数里,使用requests.request 函数获取毛不易歌手页面的 HTML。这里需要传入指定的请求头(headers),否则获取不到完整的信息。然后用 XPath 解析并获取指定的内容,这个模块中,获取的是歌曲的链接和名称。
这里展示一个URL:music.163.com/#/song?id=417859631,用XPath定位到/song?id=417859631,那么歌曲ID就是字符串第9位之后的内容。
通过分析 HTML 代码,能看到一个关键的部分:id=‘hotsong-list’。这个部分代表热门歌曲列表,也正是我们想要解析的内容。为了获取这个热门歌曲列表下面所有的链接,XPath 解析就可以写成 //*[@id=‘hotsong-list’]//a。能看到歌曲链接是 href 属性,歌曲名称是这个链接的文本。
获得歌曲 ID 之后,我们还需要知道这个歌曲的歌词,对应代码中的get_song_lyric 函数,在这个函数里调用了网易云的歌词 API 接口,比如http://music.163.com/api/song/lyric?os=pc&id=536099160&lv=-1&kv=-1&tv=-1。
获取的歌词文件里面还保存了时间信息,为了需要去掉这部分,这里使用了re.sub 函数,通过正则表达式匹配,将[]中数字信息去掉,方法为 re.sub(r’[d:.[]]’,’’,lyric)。
最后还需要设置一些歌词中常用的停用词,比如“作词”“作曲”“编曲”等,编写remove_stop_words 函数,将歌词文本中的停用词去掉,不过最终的停用词列表还需要在得到图片后不断增加完善,才能得到满意的词云展示图。

4. 实验过程中遇到的问题和解决过程
-
问题1:在生成词云模型时,出现报错OSError: cannot open resource
-
问题1解决方案:
错误原因是在WordCloud对象中的字体路径没有设置正确
wc = WordCloud( font_path="wc.ttf", max_words=100, width=2000, height=1200, )随后我将字体与代码放到了同一文件夹,就把font_path设置正确了。
-
问题2:在pip install wordcloud时,出现报错ERROR: Command errored out with exit status 1……
-
问题2解决方案:
通过查阅资料,我发现需要自己下载正确的wordcloud库才能安装。
https://blog.csdn.net/weixin_44517500/article/details/99683286
参考资料
全课总结
一学期的python课结束了。这一学期下来,有费尽心思也调不出对的代码抓狂的时候,也有历经大起大落debug终于守得云开见月明的时候。《Python程序设计》既然叫做“程序设计”,那便是一门实践性很强的课程。我们只有边做才能边学,在做中学,才能收获最多的知识,最牢固的记忆,这比沉浸于理论有趣得多。
在这之前我已经学过了《C语言程序设计》,对于程序设计已有初步了解,在Python学习的过程中,我发现它比C语言简单,也比C语言难。简单之处在于Python易于理解,可读性比C语言强,C语言中几行才能实现的功能在Python中就被封装到了一个函数中;难的地方在于它有太多太多的库和配套的函数,可能就算穷尽许多年也无法将其全部学完,而C语言的库函数不多,花上一些时间便能全部学完。
我意识到,Python作为一种工具能帮助我们解决问题,它提供了很多对接各种需求的接口,而我们只需将基本的操作学会,其他复杂或是高级的库就需要我们“现学现卖”了。
这学期课程所学的基础知识:
- 变量赋值及其命名规则
- 运算符及其优先级
- 基本数据类型
- 循环语句
- 列表、元组、字典、集合及其常用功能
- 字符串
- 函数
- 文件操作及异常处理
这学期课程所学的进阶知识:
- 面向对象程序设计
- 正则表达式
- Python操作数据库
- Python网络编程(Socket)
- Python爬虫开发
在之后的学习过程中,自学将占据90%以上的空间,而老师布置作业的难度与方式很大程度上提高了我的自学能力,使我不得不努力学习课堂以外的知识。另外一点,我觉得这门课作为一门选修课需要看的视频资源太多了,有点费时间,希望能减少一部分。