简介
RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变、可分区、里面的元素可并行计算的集合。
Resilient:弹性,它表示的含义rdd的数据是可以保存在内存中或者是磁盘中。
Distributed:它的数据是分布式存储的,后期方便于进行分布式计算。
Dataset:它就是一个集合,集合里面可以存放了很多个元素。
RDD的属性
1 A list of partitions 一个分区列表,在这里表示一个rdd中有很多个分区(partitions),Spark任务的计算以分区为单位,每一个分区就是一个task。读取hdfs上文件产生的RDD分区数跟文件的block个数相等 rdd1=sc.textFile("/words.txt") 2 A function for computing each split Spark中RDD的计算是以分区为单位的,每个RDD都会实现compute函数以达到这个目的。compute函数会对迭代器进行复合,不需要保存每次计算的结果。 3 A list of dependencies on other RDDs 一个RDD会依赖于其他多个RDD,这里就涉RDD之间的依赖关系,RDD的每次转换都会生成新的RDD,Spark任务的容错机制就是根据这个特性而来,Spark可以通过这个依赖关系重新计算丢失的分区数据,
而不是对RDD的所有分区进行重新计算。 4 Optionally, a Partitioner for key-value RDDs (e.g. to say that the RDD is hash-partitioned) (可选性) 对于kv类型的RDD才会有分区函数(必须要产生shuffle),对于不是kv类型的RDD的分区函数是None,这个分区函数决定了数据会流入到下游的RDD哪个分区中; Spark提供了2种分区函数,第一种hashPartitioner, 使用key.hashcode%分区数=分区号 这个分区函数式默认值,第二种RangePartitioner,基于一定范围。
Partitioner函数不但决定了RDD本身的分片数量,也决定了parent RDD Shuffle输出时的分片数量。 5 Optionally, a list of preferred locations to compute each split on (e.g. block locations for an HDFS file) (可选性) 最优数据块的列表,这里涉及到数据的本地性和数据位置最优;Spark进行任务计算的时候,会优先考虑存有数据的节点来计算任务。
如何创建RDD?
1、通过一个已经存在的scala集合去构建 val rdd1=sc.parallelize(List(1,2,3,4)) 2、通过加载外部数据源去构建 val rdd2=sc.textFile("/words.txt") 3、通过一个已经存在rdd调用对应方法去构建 val rdd3=rdd2.flatMap(_.split(" "))
RDD编程算子分类
-
-
可以把一个rdd转换生成一个新的rdd,它会不会立即触发任务的运行,也就是说它是一个延迟加载。
-
比如 flatMap、map、reduceByKey、sortBy等。
-
-
2、Action (动作)
-
它会触发任务的真正运行
-
比如
-
collect------>它是把rdd的数据收集到Driver端。
-
saveAsTextFile----->它是把rdd的数据写入到磁盘中。
-
-
Transformation
RDD中的所有转换都是延迟加载的,也就是说,它们并不会直接计算结果。相反的,它们只是记住这些应用到基础数据集(例如一个文件)上的转换动作。只有当发生一个要求返回结果给Driver的动作或者将结果写入到外存储中,这些转换才会真正运行。这种设计让Spark更加有效率地运行。
|
转换 |
含义 |
|
map(func) |
返回一个新的RDD,该RDD由每一个输入元素经过func函数转换后组成 |
|
filter(func) |
返回一个新的RDD,该RDD由经过func函数计算后返回值为true的输入元素组成 |
|
flatMap(func) |
类似于map,但是每一个输入元素可以被映射为0或多个输出元素(所以func应该返回一个序列,而不是单一元素) |
|
mapPartitions(func) |
类似于map,但独立地在RDD的每一个分片上运行,因此在类型为T的RDD上运行时,func的函数类型必须是Iterator[T] => Iterator[U] |
|
mapPartitionsWithIndex(func) |
类似于mapPartitions,但func带有一个整数参数表示分片的索引值,因此在类型为T的RDD上运行时,func的函数类型必须是 (Int, Interator[T]) => Iterator[U] |
|
union(otherDataset) |
对源RDD和参数RDD求并集后返回一个新的RDD |
|
intersection(otherDataset) |
对源RDD和参数RDD求交集后返回一个新的RDD |
|
distinct([numTasks])) |
对源RDD进行去重后返回一个新的RDD |
|
groupByKey([numTasks]) |
在一个(K,V)的RDD上调用,返回一个(K, Iterator[V])的RDD |
|
reduceByKey(func, [numTasks]) |
在一个(K,V)的RDD上调用,返回一个(K,V)的RDD,使用指定的reduce函数,将相同key的值聚合到一起,与groupByKey类似,reduce任务的个数可以通过第二个可选的参数来设置 |
|
sortByKey([ascending], [numTasks]) |
在一个(K,V)的RDD上调用,K必须实现Ordered接口,返回一个按照key进行排序的(K,V)的RDD |
|
sortBy(func,[ascending], [numTasks]) |
与sortByKey类似,但是更灵活 |
|
join(otherDataset, [numTasks]) |
在类型为(K,V)和(K,W)的RDD上调用,返回一个相同key对应的所有元素对在一起的(K,(V,W))的RDD |
|
cogroup(otherDataset, [numTasks]) |
在类型为(K,V)和(K,W)的RDD上调用,返回一个(K,(Iterable<V>,Iterable<W>))类型的RDD |
|
coalesce(numPartitions) |
减少 RDD 的分区数到指定值。 |
|
repartition(numPartitions) |
重新给 RDD 分区 |
|
repartitionAndSortWithinPartitions(partitioner)
|
重新给 RDD 分区,并且每个分区内以记录的 key 排序 |
Action
|
动作 |
含义 |
|
reduce(func) |
reduce将RDD中元素前两个传给输入函数,产生一个新的return值,新产生的return值与RDD中下一个元素(第三个元素)组成两个元素,再被传给输入函数,直到最后只有一个值为止。 |
|
collect() |
在驱动程序中,以数组的形式返回数据集的所有元素 |
|
count() |
返回RDD的元素个数 |
|
first() |
返回RDD的第一个元素(类似于take(1)) |
|
take(n) |
返回一个由数据集的前n个元素组成的数组 |
|
takeOrdered(n, [ordering]) |
返回自然顺序或者自定义顺序的前 n 个元素 |
|
saveAsTextFile(path) |
将数据集的元素以textfile的形式保存到HDFS文件系统或者其他支持的文件系统,对于每个元素,Spark将会调用toString方法,将它装换为文件中的文本 |
|
saveAsSequenceFile(path) |
将数据集中的元素以Hadoop sequencefile的格式保存到指定的目录下,可以使HDFS或者其他Hadoop支持的文件系统。 |
|
saveAsObjectFile(path) |
将数据集的元素,以 Java 序列化的方式保存到指定的目录下 |
|
countByKey() |
针对(K,V)类型的RDD,返回一个(K,Int)的map,表示每一个key对应的元素个数。 |
|
foreach(func) |
在数据集的每一个元素上,运行函数func |
|
foreachPartition(func) |
在数据集的每一个分区上,运行函数func |
RDD的依赖关系
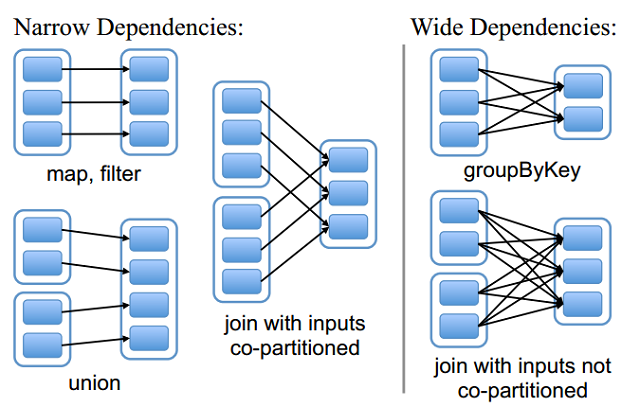
窄依赖
窄依赖指的是每一个父RDD的Partition最多被子RDD的一个Partition使用
窄依赖不会产生shuffle。
宽依赖
宽依赖指的是多个子RDD的Partition会依赖同一个父RDD的Partition
宽依赖会产生shuffle。
Lineage(血统)
血统就是记录下对应rdd的元数据信息和转化行为
好处:后期某个rdd部分分区数据丢失之后,可以通过血统这层关系重新计算恢复得到。
比如:val rdd2 = rdd1.map((_,1)) 如果rdd2的partition 1这个分区的数据丢了,就可以根据血统关系,找到rdd1的partition 1的数据重新map一次就可以得出结果了
rdd的容错机制就是根据血统而来的。
1、cache cache默认是把数据缓存在内存中,其本质调用了persist方法并传的把数据缓存到内存这个选项的参数 2、persist persist可以把数据保存在内存或者是磁盘,方法中可以传入缓存级别,这里缓存级别都封装在StorageLevel中。
可以通过对rdd调用cache和persist实现数据的缓存,这里并不是调用之后就立即触发缓存操作,需要后面有对应的action操作才会真正实现数据的缓存。 好处:可以加快后续对该数据的访问,避免重新计算。
object StorageLevel { //缓存级别 val NONE = new StorageLevel(false, false, false, false) val DISK_ONLY = new StorageLevel(true, false, false, false) val DISK_ONLY_2 = new StorageLevel(true, false, false, false, 2) val MEMORY_ONLY = new StorageLevel(false, true, false, true) val MEMORY_ONLY_2 = new StorageLevel(false, true, false, true, 2) val MEMORY_ONLY_SER = new StorageLevel(false, true, false, false) val MEMORY_ONLY_SER_2 = new StorageLevel(false, true, false, false, 2) val MEMORY_AND_DISK = new StorageLevel(true, true, false, true) val MEMORY_AND_DISK_2 = new StorageLevel(true, true, false, true, 2) val MEMORY_AND_DISK_SER = new StorageLevel(true, true, false, false) val MEMORY_AND_DISK_SER_2 = new StorageLevel(true, true, false, false, 2) val OFF_HEAP = new StorageLevel(true, true, true, false, 1) /** * Persist this RDD with the default storage level (`MEMORY_ONLY`). * cache方法默认调用的persist方法 并传的枚举中的缓存到内存的选项 */ def persist(): this.type = persist(StorageLevel.MEMORY_ONLY) /** * Persist this RDD with the default storage level (`MEMORY_ONLY`). */ def cache(): this.type = persist()
//把rdd加入缓存 rdd.cache //把rdd的缓存清除 rdd.unpersist
什么时候需要使用缓存?
某个rdd的数据会重复使用多次
某个rdd的数据计算逻辑复杂或者费时
DAG有向无环图
DAG(Directed Acyclic Graph)叫做有向无环图,原始的RDD通过一系列的转换就形成了DAG,根据RDD之间依赖关系的不同将DAG划分成不同的Stage(调度阶段)。对于窄依赖,partition的转换处理在一个Stage中完成计算。对于宽依赖,由于有Shuffle的存在,只能在parent RDD处理完成后,才能开始接下来的计算,因此宽依赖是划分Stage的依据。
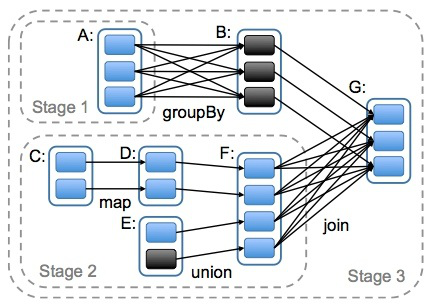
那么Stage又是什么呢
Stage也就是阶段的意思,为什么划分Stage?
在同一stage中,并没有宽依赖的存在,都是窄依赖,对于一个partition的数据的计算就是一个task,由于一个rdd有多个partition,这样可以保证有很多个task并行进行计算
如何划分Stage
简单来说宽依赖是划分stage的依据 1,从最后一个产生的rdd往前推,创建一个新的stage把最后一个rdd加入进去 2,往前推,如果遇到窄依赖就直接将这个rdd加入到原本的stage中 3,如果遇到宽依赖就新建一个stage,将当前rdd加入到新的stage中 stage和stage之间也是有关系的,前面的stage运行完成之后,后面stage中的task才会运行,也就是说后面stage的输入数据时前面stage的输出数据
spark容错机制 checkpoint
什么是checkpoint
rdd设置缓存的2种方式: (1)cache 默认是把数据缓存在内存中,后续操作起来非常快,但是也不是特别安全,比如进程或者是服务器挂掉了,这个时候内存中的数据肯定是丢失。 (2)persist 有丰富的缓存级别,可以把数据持久化写入到本地磁盘中。后续需要大量的io操作,这种方式比cache把数据放在内存中风险降低了,
如果服务器磁盘损坏或者是系统管理员误操作把磁盘中的数据清除了,最后也导致数据丢失了。 checkpoint:提供了一个相对而言更加可靠的持久化数据方式。可以把rdd的数据保存HDFS上,利用hdfs高容错性来保证数据的不丢失。
如何使用checkpoint
1、通过sparkContext对象设置数据保存在HDFS上的目录 sc.setCheckpointDir("hdfs目录") 2、对需要进行checkpoint操作的rdd调用checkpoint方法 rdd1.checkpoint 3、后面也需要一个action操作来触发checkpoint rdd1.collect
checkpoint、cache、persist的区别
cache和persist都可以对rdd的数据进行缓存,需要一个action去触发缓存操作,但是它不会改变rdd的血统这层关系。
checkpoint对rdd的数据进行持久化保存,保证在hdfs上,需要一个action去触发持久化的操作,但是它会改变rdd血统。
在执行action操作,首先对于这个action操作它会生成一个job,当前这个job执行完成之后,接下来又会开启一个新的job来执行rdd的checkpoint操作。
spark运行架构
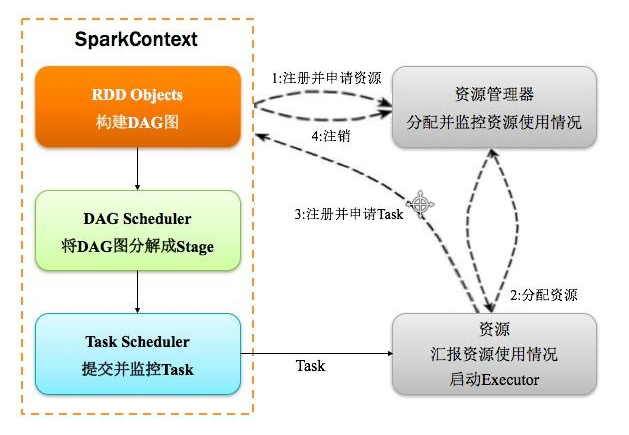
1,构建Spark Application的运行环境(启动SparkContext),SparkContext向资源管理器(可以是Standalone、Mesos或YARN)注册并申请运行Executor资源; 2,资源管理器分配Executor资源并启动Executor,Executor运行情况将随着心跳发送到资源管理器上; 3,SparkContext构建成DAG图,将DAG图分解成Stage,并把Taskset发送给Task Scheduler。
Executor向SparkContext申请Task,Task Scheduler将Task发放给Executor运行同时SparkContext将应用程序代码发放给Executor。 4,Task在Executor上运行,运行完毕释放所有资源。
Spark运行架构特点:
1,每个Application获取专属的executor进程,该进程在Application期间一直驻留,并以多线程方式运行tasks。
2,Spark任务与资源管理器无关,只要能够获取executor进程,并能保持相互通信就可以了。
3,提交SparkContext的Client应该靠近Worker节点(运行Executor的节点),最好是在同一个Rack里,因为Spark程序运行过程中SparkContext和Executor之间有大量的信息交换;
如果想在远程集群中运行,最好使用RPC将SparkContext提交给集群,不要远离Worker运行SparkContext。
4,Task采用了数据本地性和推测执行的优化机制。
spark任务调度
各个RDD之间存在着依赖关系,这些依赖关系就形成有向无环图DAG,DAGScheduler对这些依赖关系形成的DAG进行Stage划分,划分的规则很简单,从后往前回溯,遇到窄依赖加入本stage,遇见宽依赖进行Stage切分。完成了Stage的划分。DAGScheduler基于每个Stage生成TaskSet,并将TaskSet提交给TaskScheduler。TaskScheduler 负责具体的task调度,最后在Worker节点上启动task。
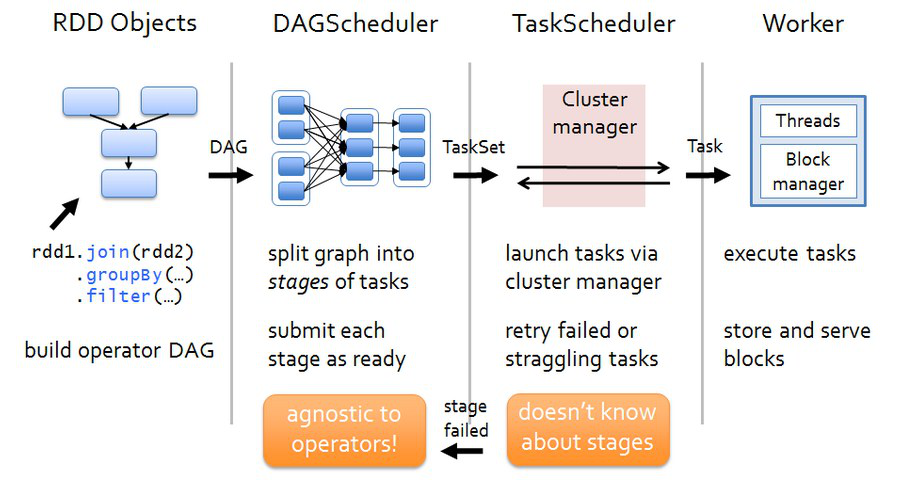
DAGScheduler (1)DAGScheduler对DAG有向无环图进行Stage划分。 (2)记录哪个RDD或者 Stage 输出被物化(缓存),通常在一个复杂的shuffle之后,通常物化一下(cache、persist),方便之后的计算。 (3)重新提交shuffle输出丢失的stage(stage内部计算出错)给TaskScheduler (4)将 Taskset 传给底层调度器 a)– spark-cluster TaskScheduler b)– yarn-cluster YarnClusterScheduler c)– yarn-client YarnClientClusterScheduler
TaskScheduler (1)为每一个TaskSet构建一个TaskSetManager 实例管理这个TaskSet 的生命周期 (2)数据本地性决定每个Task最佳位置 (3)提交 taskset( 一组task) 到集群运行并监控 (4)推测执行,碰到计算缓慢任务需要放到别的节点上重试 (5)重新提交Shuffle输出丢失的Stage给DAGScheduler
(1)Driver会运行客户端main方法中的代码,代码就会构建SparkContext对象,在构建SparkContext对象中,会创建DAGScheduler和TaskScheduler,然后按照rdd一系列的操作生成DAG有向无环图。
最后把DAG有向无环图提交给DAGScheduler。 (2)DAGScheduler拿到DAG有向无环图后,按照宽依赖进行stage的划分,这个时候会产生很多个stage,每一个stage中都有很多可以并行运行的task,把每一个stage中这些task封装在一个taskSet集合中,
最后提交给TaskScheduler。 (3)TaskScheduler拿到taskSet集合后,依次遍历每一个task,最后提交给worker节点的exectuor进程中。task就以线程的方式运行在worker节点的executor进程中。