<!--第一种标签为 field标签: 主要是用来指定字段名称的, Lucene中是有用户在程序中指定, solr中需要提前在配置文件中指定--> <field name="text" type="text_general" indexed="true" stored="false" multiValued="true"/> <!--name: 字段的名称 type: 字段的类型 indexed: 是否索引 stored: 是否保存 multiValued: 是否多值, 这个字段, 类似存储一个数组 这里有两个不允许删除的: 一个是 _version__ 一个是 _root__ 这两个是solr内部需要使用的字段 有一个字段的名称必须为id,其类型都不允许进行修改 原因是id字段已经被主键使用uniqueKey 其余的是一些初始化好的字段 --> <!--第二种标签为dynamicField, 被称为是动态域 --> <dynamicField name="*_is" type="int" indexed="true" stored="true" multiValued="true"/> <!--此种标签是为程序的扩展所使用的, 因为我们不可能把所有的字段全部定义好, 所以就需要动态域来进行动态扩展--> <!--第三种标签为 uniqueKey: 必要标签, 表名文档的唯一属性, 一般默认为id--> <uniqueKey>id</uniqueKey> <!--Lucene中是自己进行维护, solr中, 需要自己指定--> <!--第四种标签为 copyField: 被称为是复制域--> <copyField source="cat" dest="text"/> <!--source: 表名要复制那个字段的值 dest: 复制到那个字段上 此种标签主要是为了查询所使用的, 例如, 当查询Text字段的时候, 实质上相当于查询title和name两个字段--> <!--第五种标签: fieldType 字段类型定义标签--> <fieldType name="managed_en" class="solr.TextField" positionIncrementGap="100"> <analyzer> <tokenizer class="solr.StandardTokenizerFactory"/> <filter class="solr.ManagedStopFilterFactory" managed="english" /> <filter class="solr.ManagedSynonymFilterFactory" managed="english" /> </analyzer> </fieldType> <!--此种标签是用来定义字段的类型的,可以指定此字段使用何种分词器进行分词-->
-
将三个文件放置在tomcat>webapps>solr>WEB-INF>lib下(此步骤在部署solr到tomcat中的时候, 就已经导入了)

-
将三个文件放置在tomcat>webapps>solr>WEB-INF>classes下(此步骤, 在部署solr到tomcat中的时候, 已经导入)
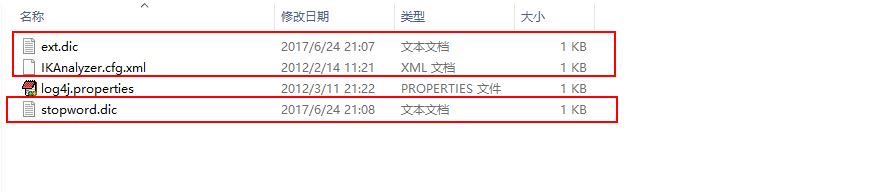
第三步, 在schema.xml配置文件中自定义一个字段类型, 引入ik分词器
<fieldType name="text_ik" class="solr.TextField"> <analyzer class="org.wltea.analyzer.lucene.IKAnalyzer"/> </fieldType>

第四步: 为对应的字段设置为text_ik类型即可
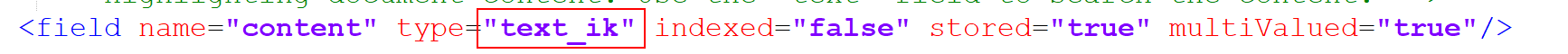
最终的配置文件:
<?xml version="1.0" encoding="UTF-8" ?> <schema name="example" version="1.5"> <!-- 不删除 --> <field name="_version_" type="long" indexed="true" stored="true"/> <field name="_root_" type="string" indexed="true" stored="false"/> <!--不删除 id: 文档的唯一标识 在lucene中文档唯一的id是lucene自己维护的,, 在solr中,需要程序员自己维护 id字段了的设置内容, 尽量的不要动 --> <field name="id" type="string" indexed="true" stored="true" required="true" multiValued="false" /> <!-- field: 用来定义字段的 name: 字段的名称 type: 字段类型 indexed: 是否分词 stored: 是否保存 multiValued: 是否是多值(当前的这个字段可以是一个数组) --> <field name="name" type="text_ik" indexed="true" stored="true"/> <field name="title" type="text_ik" indexed="true" stored="true" /> <field name="content" type="text_ik" indexed="true" stored="true" /> <!--此字段主要用来做查询使用的--> <field name="text" type="text_ik" indexed="true" stored="false" multiValued="true"/>
<!-- dynamicField: 动态域 为了程序的扩展使用的, 因为有时候无法在配置文件中将所以的字段全部定义了 对于solr来讲, 提供了动态域, 只需要用户在添加索引的时候字段名称的后缀名和动态域的名称一致就可以 --> <dynamicField name="*_c" type="text_ik" indexed="true" stored="true"/> <!-- Field to use to determine and enforce document uniqueness. Unless this field is marked with required="false", it will be a required field --> <!-- uniqueKey: 文档的唯一标识的字段是谁 --> <uniqueKey>id</uniqueKey> <!-- copyField: 复制域 source: 来源字段 dest: 目标字段 复制域的作用是用来做查询的, 将其他几个字段的值全部的复制到目标字段中 当进行查询的时候, 如果查询的是text字段, 相当于查询了cat和name字段了 --> <copyField source="content" dest="text"/> <copyField source="name" dest="text"/> <!-- fieldType: 字段的类型 name: 类型的名称 class: 类型原生的类 在这个标签中, 可以用来规定资格字段类型的分词效果 可以通过这个标签设置新的字段类型,例如 ik分词器 --> <fieldType name="string" class="solr.StrField" sortMissingLast="true" /> <!-- boolean type: "true" or "false" --> <fieldType name="boolean" class="solr.BoolField" sortMissingLast="true"/> <fieldType name="int" class="solr.TrieIntField" precisionStep="0" positionIncrementGap="0"/> <fieldType name="float" class="solr.TrieFloatField" precisionStep="0" positionIncrementGap="0"/> <fieldType name="long" class="solr.TrieLongField" precisionStep="0" positionIncrementGap="0"/> <fieldType name="double" class="solr.TrieDoubleField" precisionStep="0" positionIncrementGap="0"/> <!--ik分词器配置--> <fieldType name="text_ik" class="solr.TextField"> <analyzer class="org.wltea.analyzer.lucene.IKAnalyzer"/> </fieldType> </schema>