注:部分答案引用网络文章
简答题
1、Spring项目启动后的加载流程
(1)使用spring框架的web项目,在tomcat下,是根据web.xml来启动的。web.xml中负责配置启动springmvc和启动spring,其中,在
<servlet> <servlet-name>springMVC(名字任意)</servlet-name> <servlet-class>org.springframework.web.servlet.DispatcherServlet</servlet-class> <init-param> <param-name>contextConfigLocation</param-name> <param-value>/WEB-INF/springmvc.xml</param-value> </init-param> <load-on-startup>1</load-on-startup> </servlet> <servlet-mapping> <servlet-name>springMVC</servlet-name> <url-pattern>/</url-pattern> </servlet-mapping>中启动spring mvc并进行资源路径映射
在
<listener>
<listener-class>org.springframework.web.context.ContextLoaderListener</listener-class>
</listener>
<context-param>
<param-name>contextConfigLocation</param-name>
<param-value>classpath*:applicationContext.xml</param-value>
</context-param>
中通过ContextLoaderListener启动spring容器,同时自动装配applicationContext.xml中的配置信息。
(2)spring中对一些orm框架的启动,包括Mybatis/hibernate。orm框架的启动基本都是通过sqlsessionFactory bean来启动的,并配置各种bean到ioc容器中。包括datasource等:
<!-- MyBatis配置 -->
<bean id="sqlSessionFactory" class="org.mybatis.spring.SqlSessionFactoryBean">
<property name="dataSource" ref="dataSource" />
<!-- 显式指定Mapper文件位置 -->
<property name="mapperLocations" value="classpath*:/mybatis/*/*Mapper.xml" />
<!-- mybatis配置文件路径 -->
<property name="configLocation" value="classpath:/mybatis/config.xml" />
</bean>
(3)web应用程序中,spring相当于程序运行的平台,spring对整个程序提高供ioc支持和aop支持。spring提供注解如@service @repository @component将各种类注册到ioc容器中。通过设置scan package的方式,spring在启动时候会扫描包下的所有注解,并将它们注册到ioc容器中。并针对@autowired @resource,将一些bean从ioc容器中获取填充到bean的构造属性中(@autowired @resource只针对类成员变量,不针对方法的局部变量)。spring会根据配置自动扫描包中的注解:
<!-- 启用spring mvc注解 -->
<context:annotation-config />
<context:component-scan base-package="com.kuangchi.*" />
即所有的bean注入都在applicationContext.xml中配置的
注:正是spring的ioc支持了controller层注入service,service注入dao。打通了各层之间的桥梁,省去了原来的new service(),new Dao()的方法。
延伸:(1)spring IOC的好处:1方便测试,被测试类的依赖类可以通过spring IOC注入进来,2 方便维护,只要接口不变,重写实现类,修改配置即可 ,3 默认IOC容器管理的bean都是单例的,不会被回收掉,4 面向接口开发,service里直接是接口就可以了,解耦 , 5 用AOP作增强
(2)spring的面向接口编程:由于依赖接口,可通过依赖注入随时替换dao接口的实现类,而应用程序完全不用了解接口与底层数据库操作交互的细节。
2、SpringMVC请求响应流程
SpringMVC框架是一个基于请求驱动的Web框架,并且使用了‘前端控制器’模型来进行设计,再根据‘请求映射规则’分发给相应的页面控制器进行处理。
整体流程:
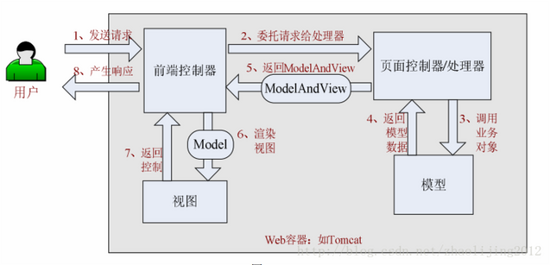
()1、 首先用户发送请求到前端控制器,前端控制器根据请求信息(如 URL)来决定选择哪一个页面控制器进行处理并把请求委托给它,即以前的控制器的控制逻辑部分;图中的 1、2 步骤;
()2、 页面控制器接收到请求后,进行功能处理,首先需要收集和绑定请求参数到一个对象,这个对象在 Spring Web MVC 中叫命令对象,并进行验证,然后将命令对象委托给业务对象进行处理;处理完毕后返回一个 ModelAndView(模型数据和逻辑视图名);图中的 3、4、5 步骤;
()3、 前端控制器收回控制权,然后根据返回的逻辑视图名,选择相应的视图进行渲染,并把模型数据传入以便视图渲染;图中的步骤 6、7;
()4、 前端控制器再次收回控制权,将响应返回给用户,图中的步骤 8;至此整个结束。
核心流程:
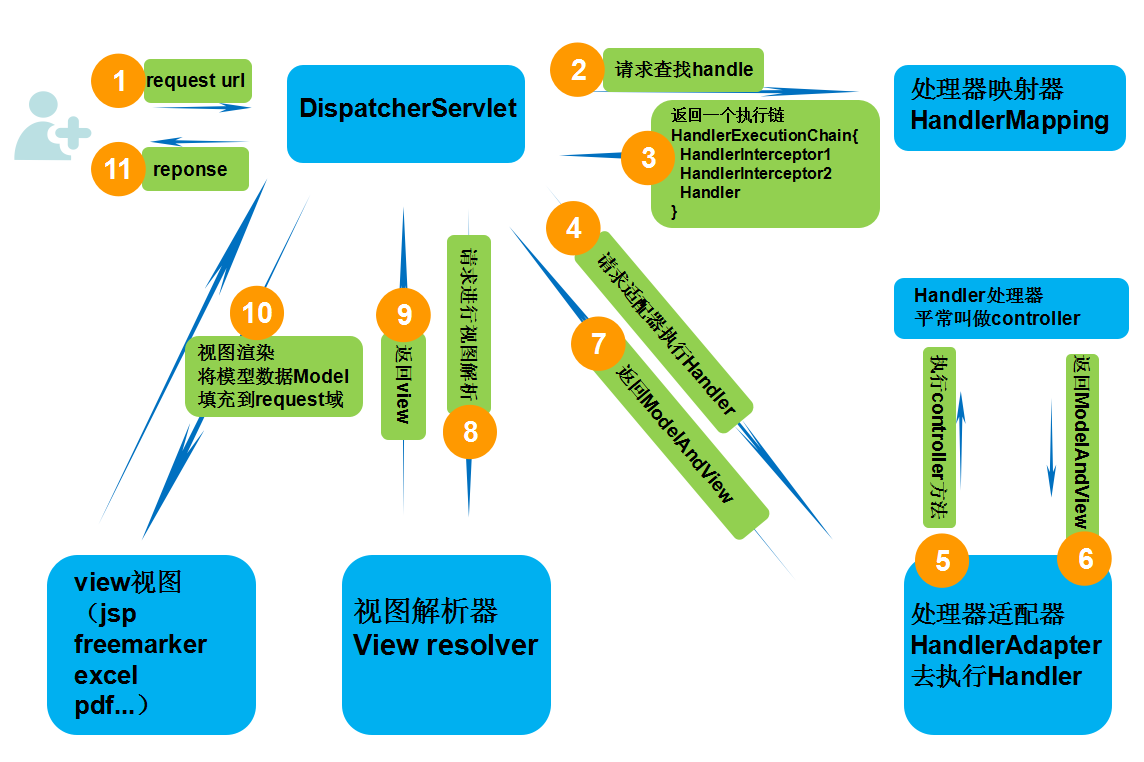
第一步:发起请求到前端控制器(DispatcherServlet)
第二步:前端控制器请求HandlerMapping查找 Handler (可以根据xml配置、注解进行查找)
第三步:处理器映射器HandlerMapping向前端控制器返回Handler,HandlerMapping会把请求映射为HandlerExecutionChain对象(包含一个Handler处理器(页面控制器)对象,多个HandlerInterceptor拦截器对象),通过这种策略模式,很容易添加新的映射策略
第四步:前端控制器调用处理器适配器去执行Handler
第五步:处理器适配器HandlerAdapter将会根据适配的结果去执行Handler
第六步:Handler执行完成给适配器返回ModelAndView
第七步:处理器适配器向前端控制器返回ModelAndView (ModelAndView是springmvc框架的一个底层对象,包括 Model和view)
第八步:前端控制器请求视图解析器去进行视图解析 (根据逻辑视图名解析成真正的视图(jsp)),通过这种策略很容易更换其他视图技术,只需要更改视图解析器即可
第九步:视图解析器向前端控制器返回View
第十步:前端控制器进行视图渲染 (视图渲染将模型数据(在ModelAndView对象中)填充到request域)
第十一步:前端控制器向用户响应结果
总结 核心开发步骤
()1、 DispatcherServlet 在 web.xml 中的部署描述,从而拦截请求到 Spring Web MVC
()2、 HandlerMapping 的配置,从而将请求映射到处理器
()3、 HandlerAdapter 的配置,从而支持多种类型的处理器
注:处理器映射求和适配器使用纾解的话包含在了注解驱动中,不需要在单独配置
()4、 ViewResolver 的配置,从而将逻辑视图名解析为具体视图技术
()5、 处理器(页面控制器)的配置,从而进行功能处理
View是一个接口,实现类支持不同的View类型(jsp、freemarker、pdf...)
3、Spring事务什么时候会失效(spring事务失效的原因)
事务就是一系列指令的集合,服从ACID 原则
(1)使用了spring+springmvc,则在 <context:component-scan>重复扫描问题可能会引起事务失效
原因是:spring的context是父子容器,会产生冲突。
由servletContextListener产生的是父容器,springmvc产生的是子容器,子容器controller进行扫描装配时,装配了@service注解的实例,而该实例应由父容器进行初始化以保证事务的增强处理,故而此处得到的将是没有经过事务加强处理、没有事务处理能力的原样service
解决方法:
在主容器applicationContext.xml中将controller的注解排除掉:
<context:component-scan base-package="com">
<context:exclude-filter type="annotation" expression="org.springframework.stereotype.Controller" />
</context:component-scan>
在springMVC配置文件springmvc中将service注解给去掉:
<context:component-scan base-package="com">
<context:include-filter type="annotation" expression="org.springframework.stereotype.Controller" /> <context:exclude-filter type="annotation" expression="org.springframework.stereotype.Service" /> </context:component-scan>4、synchronized和volatile关键字
java中为了保证多线程读写数据时,保证数据的一致性,采用:
(1)同步:如synchronized关键字,或者锁对象
(2)使用volatile关键字:它能使变量在值发生改变时尽快让其他线程知道;
对volatile关键字的解释:volatile关键字只修饰变量。一般对变量的写操作会先在寄存器或者是CPU缓存上进行,最后才写入内存,这个过程中变量的新值对其他线程是不可见的(在多线程问题中这会引发严重问题)。修改volatile修饰的变量的值时,会将其他缓存中存储的修改前的变量清除,然后重新读取,即修改volatile修饰的变量的值时,会直接更新其他缓存中该变量的值(即达到了尽快通知其他线程该变量值改变的目的)。
volatile与synchronized的比较:
(1)volatile本质是告诉JVM当前变量在寄存器中的值是不确定的,需要从主存中读取;synchronized则是锁定当前变量,只有当前线程可以访问该变量,其他线程被阻塞;(volatile不会造成线程阻塞而synchronized会)
(2)volatile仅能修饰变量;synchronized能修饰变量和方法(如单例模式);
(3)volatile仅能实现变量的修改可见性;synchronized可以保证变量的修改可见性和原子性(操作步骤要么全部执行,要么都不执行);
volatile失效的情况:1 当一个域的值依赖于它之前的值(n+=1、n++) 2 当某个域的值受到其他域的值的限制(如Range类的lower和upper边界,需要lower<=upper)
使用volatile而不是synchronized唯一安全的情况是只有一个可变的域
5、画出JMM和JVM模型,并添加注释
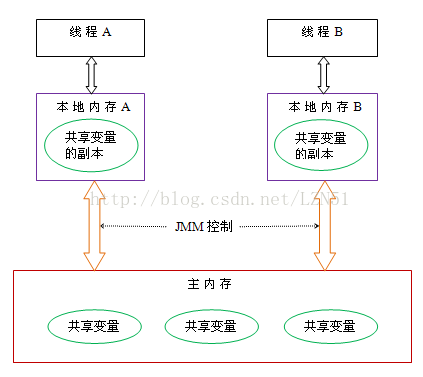
JMM:java内存模型,规定了线程和内存之间的关系(线程相关)。
系统存在一个主内存,java所有变量都储存在主存中,对所有线程共享。每条线程有自己的工作内存(即本地内存),其中保存的是主存中的变量的拷贝,线程对变量的操作都是在自己的工作内存中进行的,变量传递需要通过主存完成(涉及问题4)
JVM模型:
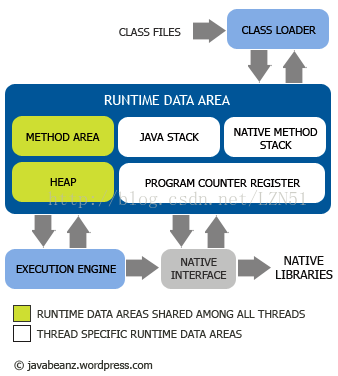
classLoader:类加载器,将class文件加载到内存(做数据校验、转换解析、初始化数据)
Runtime data area: 运行时数据区,即JVM管理的内存
program counter register:程序计数器,线程私有,指向下一条要执行的指令,(区分“寄存器”,寄存器是执行指令的)
java stack: 栈,线程私有,生命周期与线程相同。每个方法被执行时都会创建一个栈,用于存储局部变量
heap: 堆,线程共享,存储实例对象及数组,是垃圾收集器管理的主要区域
method area:方法区,线程共享的内存区域,存储类信息、常量、静态变量
6、二分查找法的算法实现(java实现)
二分法要求数组是有序的,查找速度快,适用于不经常变动而查找频繁的有序列表
递归实现:
public static int binarySearch(int[] arr,int key,int low,int high){ //方法最后返回的是查找到的位置
if(key > arr[high] || key < arr[low] || low > high){ return -1;}
int mid = (low + high)/2;
if(key < arr[mid]){
return binarySearch(arr, key, low, mid-1);
}else if(key > arr[mid]){
return binarySearch(arr, key, mid+1, high)
}else{return mid;}
}
非递归实现(用while循环)
public static int commonBinarySearch(int[] arr, int key){
int low = 0; //低位
int high = arr.length-1; //高位
int mid = 0;
if(key > arr[high] || key < arr[low] || low > high){ return -1; }
while(low <= high){
mid = (low+high)/2;
if(arr[mid] > key){
high = mid - 1;
}else if(arr[mid] < key){
low = mid+1;
}else{ return mid; }
}
return -1; //最后没有找到,返回-1
}
7、有哪些垃圾收集器,及其使用的垃圾回收算法
一、(1)Serial串行垃圾收集器:采用复制算法、使用单线程进行垃圾回收(执行垃圾回收时,冻结所有应用程序线程),不适合服务器环境,适合简单的命令行程序
(2)Parallel并行垃圾收集器:JVM的默认垃圾收集器,采用复制算法、使用多线程进行垃圾回收(执行垃圾回收时,冻结所有的应用程序线程)
(3)CMS并发标记扫描垃圾收集器(concurrent mark sweep):采用“标记-清除”算法、使用多线程扫描堆内存,标记需要清理的实例并清理被标记过的实例。(会出现“碎片”问题)
当标记的引用对象在tenured区域(heap区下的一个区)或者当垃圾回收的时候堆内存的数据被并发的改变,CMS会持有应用程序所有线程。
相比并行垃圾收集器,CMS使用更多的CPU来确保程序的吞吐量;若为了更好的程序性能分配更多的CPU,那么CMS是第一选择。
(4)G1垃圾收集器(比较新,JDK1.7才正式引入):适用于堆内存很大的情况,将堆内存分割多区域,并且并发的对其进行垃圾回收,回收之后对剩余的堆内存空间进行压缩(G1会优先选择第一块垃圾最多的区域)
二、垃圾回收算法:(1)复制算法:把内存空间分成两等分,垃圾回收时,把当前区域中正在使用的对象复制到另一区域(缺点是需要两倍内存空间)
(2)标记-清除算法:从引用根节点开始标记所有被引用的对象,再遍历整个堆,将未标记的对象清除(缺点是要暂停整个应用,产生内存碎片)
(3)标记-整理算法:结合了(1)(2)的优点,从根节点标记所有被引用的对象,再遍历整个堆,清除未标记对象,并把存活的对象按顺序压缩到堆中一块。避免了碎片问题,也避免了两倍空间问题
8、三个线程:T1输出A,T2输出B,T3输出C,如何保证控制台顺序打印A,B,C?
实现线程顺序输出的三种方式:1、使用join方法,等待线程结束在执行其他;2、使用同步synchronized方法;3、使用锁ReentrantLock
1、最简单的实现方式join方法,思路:线程T1打印A,线程T2等待T1结束,再打印B,线程T3等待T2结束,在打印C
主类 public class MainClass{
public static void main(String[] args){
ThreadT1 T1= new ThreadT1 ();
ThreadT2 T2= new ThreadT2(T1);
ThreadT3 T3= new ThreadT3(T2);
T1.start(); T2.start(); T3.start(); //此处三个线程启动的顺序可随意,最终都会顺序打印出ABC
}
}
线程类 class ThreadT1 extends Thread{
public void run(){ system.out.println("A") }
}
class ThreadT2 extends Thread{
private ThreadT1 t1;
public ThreadT2 (ThreadT1 t){ this.t1 = t; }
public void run(){
try{
t1.join();//等待t1线程结束
}catch(InterruptedExceptionb e){ e.printStackTrace(); }
system.out.println("B");
}
}
//线程T3同上实现
2、使用synchronized同步,思路:主类中一个状态变量、三个synchronized修饰的方法分别打印ABC,同步锁在唤醒的过程中,会将同一个锁上的线程都唤醒,故方法中的条件判断中使用while循环
主类 public class PrintABC{
private int status = 1;
public void printA(){
synchronized(this){
while(status!=1){
try{ this.wait(); }catch(interruptedException e){ e.printStackTrace(); }
}
system.out.println("A"); status = 2; this.notifyAll(); //打印A后,修改状态变量值,唤醒之前被wait的线程
}
}
public void printB(){
synchronized(this){
while(status!=2){
try{ this.wait(); }catch(interruptedException e){ e.printStackTrace(); }
}
system.out.println("B"); status = 3; this.notifyAll(); //打印B后,修改状态变量值,唤醒之前被wait的线程
}
}
public void printC(){
synchronized(this){
while(status!=3){
try{ this.wait(); }catch(interruptedException e){ e.printStackTrace(); }
}
system.out.println("C"); status = 1; this.notifyAll(); //打印C后,修改状态变量值,唤醒之前被wait的线程
}
}
public static void main(string[] args){
PrintABC pabc = new PrintABC();
Thread printA = new Thread(new RunnableA(pabc));
Thread printB = new Thread(new RunnableB(pabc));
Thread printC = new Thread(new RunnableC(pabc));
printA.start(); printB.start(); printC.start();
}
}
线程类 class RunnableA implements Runnable{
private PrintABC p;
public RunnableA (PrintABC pp){
super();
this.p = pp;
}
public void run(){
p.printA();
}
}
//RunnableB、RunnableC同上实现
3、使用jdk1.5并发包中引入的ReentrantLock,是在方式2的基础上,主类添加ReentrantLock锁,其他不变,比方式2更灵活,也提供了在获取锁时阻塞的办法
import java.util.concurrent.locks.Condition;
import java.util.concurrent.locks.ReentrantLock;
public class PrintABC{
private int status = 1;
private ReentrantLock lock = new ReentrantLock();
private Condition ca = lock.newCondition();
private Condition cb= lock.newCondition();
private Condition cc = lock.newCondition();
public void printA(){
lock.lock();
try{
if(status != 1){ ca.await(); }
system.out.println("A");
status = 2;
cb.signal();
}catch(){ e.printStackTrace();
}finally{ lock.unlock();
}
}
public void printB(){
lock.lock();
try{
if(status != 2){ cb.await(); }
system.out.println("B");
status = 3;
cc.signal();
}catch(){ e.printStackTrace();
}finally{ lock.unlock();
}
}
public void printC(){
lock.lock();
try{
if(status != 3){ cc.await(); }
system.out.println("C");
status = 1;
ca.signal();
}catch(){ e.printStackTrace();
}finally{ lock.unlock();
}
}
//主方法同方式2
}
//线程类同方式2