一、redis是用C语言开发的一个开源的高性能键值对内存数据库,可用作数据库、缓存、消息代理:
性能优秀,读写速度非常快;线程安全;丰富的数据类型;支持数据持久化;
高性能:执行耗时久且结果不经常变动的sql,将结果放进缓存,查询时间短。
经典场景是:电商平台,某个产品一天之内信息都不变,但每次查询耗时2S(放进缓存可能就是每次2ms),一天内100万次浏览;
高并发:redis缓存作为缓冲,支持高性能的主从复制的集群策略。MySQL并不好支持高并发,单机最多支撑到2000qps,而缓存单机支撑的并发量一秒几万十几万,是MySQL的几十倍并发量。;
可用作分布式锁,功能可用其他中间件替代(如zookeeper)
redis内部使用一个redisObject对象表示所有key和value。redisObject包含type(表示一个value对象具体是何种数据类型)、encoding(表示不同数据类型在redis内部的存储方式)
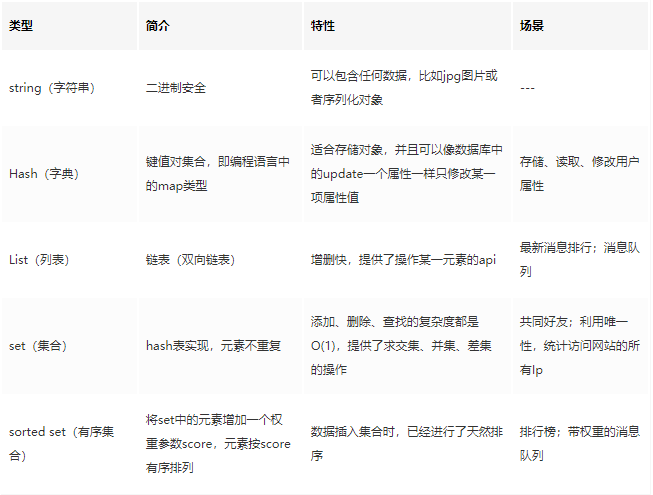
1、redis五种主要的数据类型:String、Hash、list、set、sortedSet有序集合
(1)String是redis最基本类型,二进制安全故redis的string类型可包含任何数据,例如jpg图或者序列化的对象,简单的set/get;
(2)Hash是一个键值(key-value)集合,redis的hash是一个string的key和value的映射表,适合存储对象,常用命令hget、hset、hgetall;
(3)list列表是简单的字符串列表,按照插入顺序排序(有序且可重复)。
1 可做粉丝列表:key=某大V,value=[张三、李四、王五]
2可做文章的评论列表
3通过lrange命令,从某个元素开始读取多少个元素,可基于list实现分页查询。基于redis实现简单的高性能分页,做类似微博下拉不断分页的东西,性能高
4 做简单的消息对列,从list头放进去,从list尾巴拿出来
常用命令:lpush、lpop、rpush、rpop、lrange(获取部分列表)。redis的list的实现是双向链表
(4)set是string的无序集合,通过hashtable实现。set中元素无序且不重复。
做交集、并集、差集操作,比如交集可以是两个人的共同微博粉丝
常用命令sadd、spop、smembers、sunion
(5)sortedSet与set的区别就是有序,常用命令zadd、zrange、zrem、zcard。
sortedSet关联了一个double类型权重的参数score,redis就是通过score来为集合中的成员进行从小到大排序。
sortedSet内部使用hashmap和跳跃表skipList来保证数据的存储和有序,hashmap放的是成员到score的映射,跳跃表放的是所有成员,排序依据是hashmap里存的score,跳跃表查询效率高,实现简单:
做排行榜:zadd board 命令,是给score的
zadd board 85 张三
zadd board 90 王五
zadd board 80 李四
zrevrange board 0 99 获取排名前100的用户
zrank board 李四 可看到用户在排行榜里的排名
2、redis的架构模式:
(1)单机版:多个客户端对应一个redis服务器,特点是简单,但是内存容量有限,处理能力有限,无法高可用,不支持高并发;
(2)主从复制:多个从redis服务器从一个主redis服务器拷贝数据,多个客户端从从redis服务器get数据(也可从主redis服务器get),从服务器仅提供读操作,主服务器提供写操作。
优点:用户从主redis服务器复制多个从redis服务器,两者数据相同,主服务器更新数据到从服务器,降低了主服务器的读压力,再转交从库
缺点:未解决主服务器的写压力
注:关于主从架构的,文章后面有详细的说明,请直接移步文章末尾
(3)哨兵:监听主节点的存活状态,如果主节点挂掉,从节点能继续提供缓存功能(主从节点结合哨兵模式能解决单点故障问题,提高redis可用性)
(4)集群(proxy型)
3、redis怎么用
结合springboot使用,一种是通过RedisTemplate使用,另一种是使用spring cache集成Redis(注解的方式)
redis注解:
@cacheable根据方法的请求参数对其结果进行缓存 @cacheable(value = "",key = "")
@cacheable(value=“user”,key="#id")
public User getUser(int id){
return xxxmap.get(id);
}
@cachePut,与@cacheable作用一样,不同的是它每次都会出发真实方法的调用@cachePut(value=“”,key="")
@cachePut(value=“user”,key="#user.id")
public User saveUser(User user){
return user;
}
@cacheEvict 根据条件对缓存进行清空@cacheEvict(value=“”,key="")
@cacheEvict(value=“user”,key="#id")
public void deleteUser(int id){
removeUser( id );
}
二、使用redis有什么缺点?
1、缓存与DB双写一致性问题:分布式环境下非常容易出现缓存与数据库间数据一致性问题
我们只能采取合适的策略去降低缓存与数据库间数据不一致的概率,而无法保证两者间的强一致性
(1)有强一致性要求的数据,不要用缓存
(2)采取正确更新策略,更新数据库后及时更新缓存,或者先更新DB再删缓存,删缓存失败可提供补偿,用消息队列
2、缓存雪崩:即缓存在同一时间大面积失效,这时来了一拨请求,全怼到DB上导致DB连接异常
解决办法就是,方法1:在往redis存数据的时候,设置缓存的失效时间加一个随机值,避免集体失效
方法2 :若redis是集群部署,将热点数据均匀分布在不同redis库中,也能避免全部失效,或者设置热点数据永不过期,有更新操作就更新缓存就好了
方法3: 建立备份缓存,缓存A和缓存B,A设置超时时间B不设置,先从A读缓存,A没有读B并且更新A,B
雪崩实际出现的场景:电商,定时午夜12点刷新缓存(即设置的缓存失效时间是午夜12点),但是12点有个秒杀活动,活动开始时大量用户涌入但缓存失效了,所有请求全怼到数据库上了,DB挂了
3、缓存穿透:即请求数据库和缓存中不存在的数据,导致所有请求到DB上,从而DB连接异常
解决办法1:接口层增加校验,比如用户鉴权,参数做校验,不合法的直接return,比如id<=0的直接拦截
解决办法2:redis里的布隆过滤器,利用高校的数据结构和算法快速断定你这个key是否在数据库中,不存在则return,存在就去查DB刷新KV再return
4、缓存击穿:与雪崩有点像,某个key是热点,大量请求同时访问它,在这个key失效的瞬间,持续的大并发直接落到数据库上,在key这个点上击穿了缓存
解决办法:设置热点数据永不过期,或者加上互斥锁
使用互斥锁(mutex key)
业界比较常用的做法,是使用mutex。简单地来说,就是在缓存失效的时候(判断拿出来的值为空),不是立即去load db,而是先使用缓存工具的某些带成功操作返回值的操作(比如Redis的SETNX或者Memcache的ADD)去set一个mutex key,当操作返回成功时,再进行load db的操作并回设缓存;否则,就重试整个get缓存的方法。
SETNX,是「SET if Not eXists」的缩写,也就是只有不存在的时候才设置,可以利用它来实现锁的效果。
public String get(key) {
String value = redis.get(key);
if (value == null) { //代表缓存值过期
//设置3min的超时,防止del操作失败的时候,下次缓存过期一直不能load db
if (redis.setnx(key_mutex, 1, 3 * 60) == 1) { //代表设置成功
value = db.get(key);
redis.set(key, value, expire_secs);
redis.del(key_mutex);
} else { //这个时候代表同时候的其他线程已经load db并回设到缓存了,这时候重试获取缓存值即可
sleep(50);
get(key); //重试
}
} else {
return value;
}
}三、单线程redis为什么这么快?
redis是单线程工作模型。快的原因是1 纯内存操作 2、单线程操作,避免经常的上下文切换 3、采用非阻塞I/O多路复用机制
1、纯内存操作:redis将所有数据放在内存中,是不需要从磁盘读取数据,0次IO。
2、单线程操作:(1)简化了算法实现 (2)避免了线程切换和加锁释放锁带来的消耗。(3)缺点是阻塞,若一个命令执行时间过长,会造成其他命令的阻塞。
3、非阻塞I/O多路复用机制:I/O多路复用实际上是指多个连接的管理可以在同一进程,多路是指多个网络连接,复用的是同一个线程。在网络服务中,I/O多路复用起的作用是一次性把多个连接的事件通知业务代码处理,处理方式由业务代码决定。
pS:I/O多路复用机制涉及到了redis的线程模型,这里扩展一下:
redis的线程模型
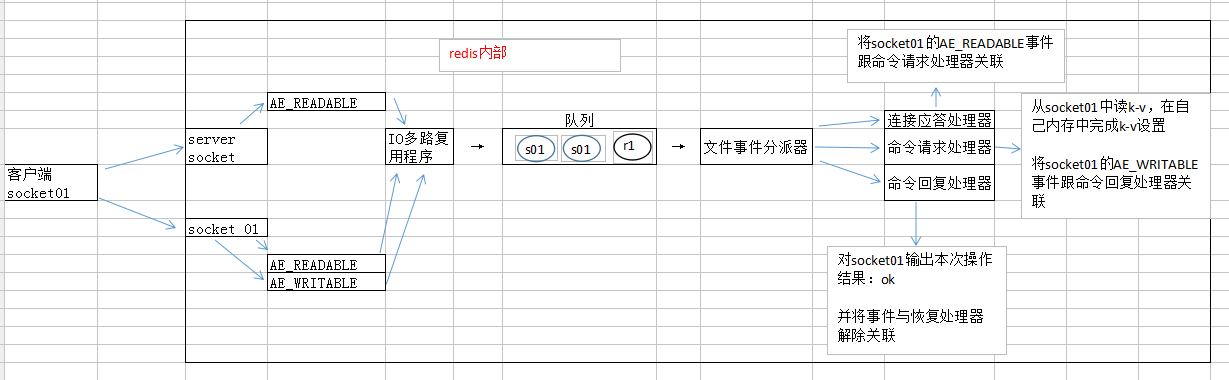
(1)文件事件处理器file event handler(单线程模式运行,redis基于reactor模式开发的网络事件处理器):
采用IO多路复用机制同时监听多个socket,并将socket放入一个队列中,每次从队列中取一个socket给事件分派器来处理(并行访问-->串行访问)
文件事件处理器包括:多个socket、IO多路复用程序、文件事件分派器、事件处理器
(2)文件事件:
1 当socket变得可读时,比如客户端对redis执行write操作或close操作,或者有新的可以应答的socket出现(客户端对redis执行connect操作),socket会产生一个AE_READABLE事件;
2 当socket变得可写时(客户端对redis执行read操作),socket会产生一个AE_WRITABLE事件;
3 IO多路复用程序同时监听AE_WRITABLE和AE_READABLE两种事件,若一个socket同时产生了这两种事件,文件事件分派器优先处理AE_READABLE事件
(3)文件事件处理器:若是客户端要连接redis,那么会为socket关联连接应答处理器;
若是客户端要写数据到redis,那么会为socket关联命令请求处理器;
若是客户端要从redis读数据,那么会为socket关联命令回复处理器;
四、redis的过期策略及内存淘汰机制(过期策略和内存淘汰机制是要结合使用的,才能保证过期的key全部删除干净)
设置了过期时间的数据,并不一定到时间了就立马会被删除,只是数据过期了,要根据redis的淘汰策略来看
1、redis采用定期删除+惰性删除策略:
定期删除是随机检查设了过期时间的key,来删除
惰性删除是,当你查询某个key时,redis检查一下,过期了就删除
2、redis的淘汰策略有7种(redis4加了一种访问频率最少,最不经常使用的KV淘汰),推荐allkeys-LRU最近最少使用淘汰策略:
已设置过期时间中有三种策略:1最近最少使用less recently use的数据淘汰、2剩余时间最短time to live的数据淘汰、3随机选择数据淘汰
4从所有KV 中对最近最少使用的数据淘汰、
5从所有KV中随机淘汰、
6不淘汰策略,若超过最大内存额返回错误信息、
7通过统计访问频率,将访问频率最少的也就是最不经常使用的KV淘汰
另:LRU算法的实现:继承LinkedHashMap,构造方法据给定初始化大小调用super方法,并重写删除最老entry数据方法
public class LRUCache<k,v> extends LinkedHashMap<k,v>{
private final int CACHE_SIZE;
public LRUCache( int cacheSize){
super( (int)Math.ceil( cacheSize / 0.75) + 1 , 0.75f, true);
//设置一个hashmap的初始大小,同时最后一个true指的是让LinkedHashMap按照访问顺序来进行排序,最近访问的放在头,最早访问的放在尾
CACHE_SIZE = cacheSize;
}
@override
protected boolean removeEldestEntry(){
return size() > CACHE_SIZE;
//当map中的数据量大于指定的缓存个数时,自动删除最老的数据
}
}
阿里云redis开发规范解读
-------开始-----
1、key命名设计:可读性、可管理性、简洁性
规范建议使用冒号进行分割拼接,因为很多redis客户端是根据冒号分类的: apps:app:1、apps:app:2、apps:app:3
2、value设计:拒绝bigkey
规范建议String类型的value控制在10kb范围内,因为redis随着value不断增长,在超过10kb后,性能明显下降
3、控制key的生命周期:设定过期时间
尽可能对每个Key都设置过期时间
4、时间复杂度为O(n)的命令需要注意N的数量
以list为例,元素数量越多,命令的性能越差,而redis 是单线程的,若出现一个慢命令,会导致之后的命令耗时增长。这也是jdk1.8对hashmap进行链条冲突优化:当entry数量不少于64时,如果冲突链表长度达到8,会将其转化为红黑树,因为链表长度越长,性能越差。
5、禁用命令:KEYS、FLUSHDB、FLUSHALL等
这些命令在搭建redis环境的时候就应该禁用掉(在config配置文件中通过rename-command禁用)。
FLUSHDB、FLUSHALL这两个命令是会删库数据的
6、推荐使用批量操作提升操作效率
批量命令包括原生命令(mget、mset、hmget、hmset、LPUSH key value)、非原生命令(Pipeline)
7、monitor命令控制使用时间
monitor命令一般是用来观察redis服务端都在执行哪些命令并实时输出。规范建议控制monitor命令的使用时间,是因为随着monitor命令的执行时间越长,越多数据积压在输出缓冲区,从而导致输出缓冲区占用内存越来越大
-----结束-----
一、redis与memcached的区别(为什么选择redis而不用memcached)/mem ca qu/
1、存储方式:memcache把数据全部存在内存中,断电就会挂掉,数据不能超过内存大小,而redis部分数据会存在磁盘上,能保证数据持久性
2、支持的数据类型:memcache只支持简单的key-value,redis支持五种数据类型
3、value大小:redis可以达到1GB,而memcache只有1MB
4、redis内存使用率比memcached高,由于其组合式的压缩,采用hash结构来做k-v存储;
5、性能上,redis只使用单核,每一个核上redis在存储小数据时比memcached性能更高,而memcached可使用多核,在大数据量时比redis性能高;
6、集群模式:memcached原生不支持集群模式,redis目前是支持原生cluster集群模式的;
二、redis的主从架构
1、redis不能支撑高并发的瓶颈是单机,qps大概上万到几万不等,所以要用集群的缓存架构
2、redis要支撑超过10万+的高并发要怎么做?
解决方案就是读写分离,一般来说,对缓存一般都是用来支撑读高并发的,写的请求是比较少的。
此处读写分离,就是用主从架构,一主多从,主负责写并同步数据到从节点(是异步同步数据的),从节点提供读操作
3、redis replication 以及master持久化对于主从架构的安全意义
redis replication --> 主从架构 --> 读写分离 --> 水平扩容支撑读高并发
(1)图解redis replication 基本原理
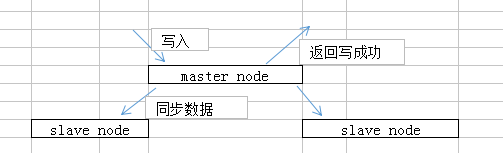
(2)redis replication核心机制:
1 redis 采用异步方式复制数据到slave节点,redis 2.8开始,slave节点会周期性地确认自己每次复制的数据量
2 一个master节点可配置多个slave节点
3 slave node 也可以连接其他slave node
4 slave node做复制时,是不会阻塞master node正常工作的
5 slave node复制时,也不会阻塞对自己的查询操作,它会用旧的数据集来提供服务。复制完成时,需要删除旧数据集,加载新数据集,这时就会暂停对外服务。
6 slave node 主要用来进行横向扩容,做读写分离,扩容的slave node可提高读的吞吐量
(3)master持久化对于主从架构的安全保障的意义
主从架构,必须建议开启master node的持久化
不建议用slave node作为master node的数据热备,因为如果关掉master的持久化,可能在master宕机重启时,数据是空的,然后一经复制,slave node的数据也丢了。
即使采用了高可用机制,slave node可自动接管master node,但是也可能哨兵sential还没检测到master失败了,master node就自动重启了,还是可能导致上面的所有slave node数据清空故障。
4、redis 主从架构
***redis高并发:主从架构,一主多从,主写从读,单机几万QpS,数据量很大就要用redis集群;
***redis高可用:主从架构部署,加上哨兵,就可实现任一实例宕机,自动进行主备切换。
(1)主从架构的核心原理
当启动一个slave node时,它会发送一个psync命令给master node。
如果这是slave node重新连接master node,那么master node仅仅会复制给slave node部分缺少的数据。
否则,会触发一次full resynchronization(全量复制),开始时master会启动一个后台线程,开始生成一份RDB快照文件,同时还会将从客户端收到的所有写命令缓存在内存中。RDB文件生成完毕后,master会将这个RDB文件发给slave,slave会先将RDB文件写入本地磁盘,然后再从本地磁盘加载到内存中。然后master会将内存中缓存的写命令发送给slave,slave也会同步这些数据。(整个过程涉及RDB文件和写命令两部分数据)
slave node如果跟master node有网络故障,断开了连接,会自动重连。master如果发现有多个slave node都来重新连接,仅仅会启动一个rdb save操作,用一份RDB数据服务所有slave node。
(2)主从复制的断点续传
redis2.8开始,就支持主从复制的断点续传,如果主从复制过程中,网络连接断了,那么可以接着上次复制的地方,继续复制,而不是从头重新复制。
master node会在内存中维护一个backlog,master和slave都会保存一个replica offset还有一个master id。
offset就是保存在backlog中的,如果master和slave网络连接断了,slave会让master从上次的replica offset开始继续复制,但是如果在backlog中没有找到对应的offset,就会执行一次resynchronization
(3)无磁盘化复制:master在内存中直接创建RDB,发送给slave,不会在自己本地落地磁盘了。
repl-diskless-sync no ,默认是no的,默认不进行无磁盘化复制,修改为yes则会
repl-diskless-sync-delay 等待一定时长再开始复制,因为要等更多的slave重新连接过来
(4)过期key处理:
slave不会过期key,只会等待master过期key
如果master过期了一个key,通过LRU淘汰了一个key,会模拟一条del命令发送给slave。
主从复制:从节点仅提供读操作,主节点提供写操作,对于读多写少的状况,给主节点配置多个从节点可提高响应效率
主从复制的完整流程:
(1)、slave node执行slaveof[ masterIP ][ masterPort ]保存主节点信息:
slave node启动,仅保存master node的信息,包括master node的host和IP,但是复制还没开始。master的host和IP是redis.conf里面的slaveof配置的
(2)、slave node从节点的定时任务发现主节点信息,建立和主节点的socket连接:
slave node内部有个定时任务,每秒检查是否有新的master node要连接和复制,如果有,就建立socket连接
(3)、从节点发送Ping信号,主节点返回Pong,两边能相互通信
口令认证,如果master设置了requirePass,那么slave node必须发送masterauth的口令过去认证
(4)、连接建立后,主节点第一次执行全量复制,将所有数据发送给从节点(数据同步)
(5)、主节点把当前的数据同步给从节点后,便完成了复制的建立过程。接下来主节点会持续的把写命令异步发送给从节点,保证主从数据一致性;
对第(4)点的补充说明:
----开始----
数据同步相关的核心机制:第一次slave连接master时,执行全量复制的细节机制
- (1)master和slave都会维护一个offset:master会在自身不断累加offset,slave也会在自身不断累加offset。slave每秒都会上报自己的offset给master,同时master会保存每个slave的offset(不是特定用在全量复制的)
- (2)backlog:master node有一个backlog,默认1MB大小。master给slave复制数据时,会将数据同步一份在backlog中。backlog主要是用来做全量复制中断后的增量复制的(断点续传)
- (3)master run id:info server命令,可以看到master run id
- 如果根据host+IP定位master node是不可靠的。因为如果master node重启或数据出现了变化,那么slave应该根据不同的run id区分,run id不同就要做全量复制,如果需要不更改run id 重启redis,可用redis-cli debug reload
- (4)psync:从节点使用psync从master node进行复制,psync runid offset
- master会根据自身的情况返回响应信息,可能是FULLRESYNC runid offset促发全量复制,可能是CONTINUE触发增量复制。
全量复制:
- (1)master执行bgsave,会在本地生成一份RDB快照文件
- (2)master node将RDB快照文件发送给slave node,若RDB复制时间超过60s(repl-timeout),那么slave就认为复制失败,可适当调大这个参数
- 对于千兆网卡的机器,一般每秒传输100MB,6G文件很可能超过60S
- (3)master在生成RDB时,会将所有新的写命令缓存在内存中,在slave保存了RDB后,再将新的命令复制给slave
- client-output-buffer-limit slave 256MB 64MB 60,如果在复制期间,内存缓冲区(就是前面缓存新的写命令的地方)持续消耗超过64MB或者一次性超过256MB,那么停止复制,复制失败
- (4)slave node 接收到RDB后,清空自己的旧数据,然后从磁盘中重新加载RDB到自己的内存中,同时基于旧的数据版本对外提供服务
- (5)如果slave开启了AOF,那么会立即执行BGREWRITEAOF,重写AOF文件
如果复制的数据量在4-6G之间,很可能全量复制时间消耗到1分半到2分钟
增量复制:
- (1)如果全量复制过程中,master-slave网络连接中断,那么slave重连master时,会触发增量复制
- (2)master直接从自身的backlog中获取部分丢失的数据,发送给slave,默认backlog就是1MB
- (3)master就是根据slave发送的psync中的offset来从backlog中获取数据的(可参考“数据同步相关的核心机制”的第(4)点)
heartbeat:
主从节点互相都会发送heartbeat信息
master默认每隔10秒发送一次heartbeat,slave每隔1秒发送一个heartbeat
异步复制: master每次接收到写命令后,先在内部写入数据,然后异步发送给slave
----结束----
主从复制的问题:
(1)、一旦主节点宕机,从节点晋升为主节点,同时需要修改应用方的主节点地址,还要命令所有从节点去复制新的主节点,整个过程需要人工干预;
(2)、主节点的写能力、存储能力受到单机的限制
问题1 的解决方案是核心在于提高redis主从架构下的高可用性(主节点挂掉了,如何保证系统仍能接续使用?(slave节点挂掉是不会影响可用性的)):
使用 哨兵sentinal node:redis高可用架构,叫做故障转移,也可叫做主备切换。在master node故障时,自动检测,并将某个slave node自动切换为master node的过程叫做主备切换,实现redis主从架构下的高可用性。
(5)哨兵介绍
- 1 功能包括 主节点存活检测、主从运行情况检测、自动故障转移、主从切换(也叫主备切换)
集群监控:不断检查主、从服务器是否正常运行(监控master和slave进程是否正常工作)
消息通知:被监控的某个redis实例有故障,哨兵会通过API脚本向管理员或者其他应用程序发出通知
自动故障转移:当主节点不能正常工作时,哨兵会开始一次自动的故障转移操作,将与失效主节点是主从关系的其中一个从节点升级为新的主节点,并将其他从节点指向新的主节点,避免了人工干预
配置提供者:哨兵模式下,客户端应用在初始化时连接的是哨兵节点集合,从中获取主节点信息。故障转移发生后,通知client客户端新的master地址。
- 2 哨兵本身也是分布式的,作为一个哨兵集群去运行,协同工作:
故障转移时,判断一个master node是否宕机了,需要大部分哨兵都同意才行,涉及到了分布式选举的问题;
即使部分哨兵节点挂掉了,哨兵集群还是能正常工作的。
目前采用的sentinal 2 版本,主要是让故障转移的机制和算法变得更加健壮简单。
(6)哨兵核心
- 1 哨兵集群至少需要3个实例,来保证自己的健壮性;
- 2 哨兵+redis主从的部署架构,只能保证redis集群的高可用性,不能保证数据0丢失;
- 3 哨兵+redis主从的架构,尽量在测试环境和生产环境都进行充分的演练;
(7)为什么redis哨兵集群只有2个节点无法正常工作?
前提:哨兵集群必须部署2个以上节点。
若仅部署了2个哨兵实例,quorum = 1
configuration : quorum = 1
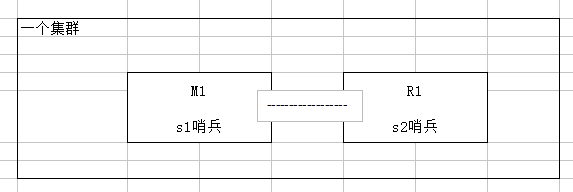
master宕机,s1和s2中只要有一个哨兵认为master宕机就可以进行切换(参数quorum决定在认为master宕机时需要几个哨兵认可,若quorum=2时,即要有2个哨兵认为master宕机才能进行切换),同时s1、s2中会选举出一个哨兵来执行故障转移
同时这个时候,需要majority大多数哨兵都是运行的,2个哨兵的majority就是2(3的majority=2,4的majority=2,5的majority=3),2个哨兵都运行着,就可以允许执行故障转移。但是如果整个m1和s1所在的机器宕机了,那么哨兵只有一个了,此时就没有majority来允许执行故障转移了,虽然还有一台机器还有一个R1,但是故障转移不会执行。
(8)经典的3节点哨兵集群
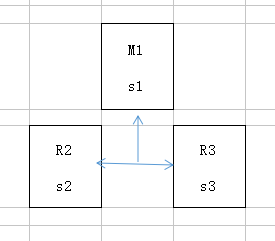
configuration: quorum = 2,majority=2
如果M1所在机器宕机了,那么还剩S2、S3两个哨兵,S2和S3一致认为master宕机,然后选举出一个来执行故障转移
同时3个哨兵的majority是2,所以还剩下的2个哨兵运行着,就可以允许执行故障转移。
(9)两个丢失数据的场景:
- 场景1:哨兵、主从架构下的异步复制数据丢失:master node接收写的请求并返回成功,此时数据还在master内存中。由于master复制数据到slave是异步的,可能还没复制数据,master就挂了,此时哨兵检测到master挂了,选举新的master供读写操作,那么旧的master还未复制的那部分数据就丢了
- 场景2:脑裂问题:master主节点,出现了异常性的有相同数据,相同工作的两个节点(集群脑裂导致的数据丢失)
- 图例:
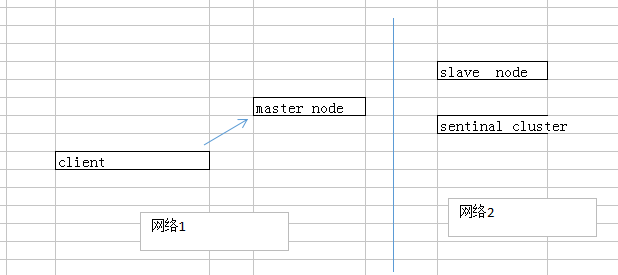
- 脑裂问题图描述:主节点与从节点哨兵集群所在的网络失去联系。哨兵以为原主节点出故障了。选举出新的master,而实际上原主节点依旧正常工作着,此时整个环境中存在两个master,客户端client可能与原master处于同一个网络,连接正常,继续写数据到原master。当管理员发现问题,原master再次恢复时会被作为一个slave挂到新的master上,自己的数据清空,重新从新的master复制数据,就出问题了(后client写入原master的那部分数据丢了)
- 解决方案:两个配置min-slaves-to-write 2, min-slaves-max-lag 10, 可减少异步复制数据和脑裂导致的数据丢失(这两个配置的意思是,要求至少有2个slave,数据复制和同步的延时不能超过10秒)
- 详解:
- 对场景1,min-slaves-max-lag可确保,一旦slave复制数据和ack延时太长,就认为可能master宕机后损失的数据太多了,那么旧拒绝写请求,这样可以把master宕机时由于部分数据未同步到slave导致的数据丢失降低到可控范围内。
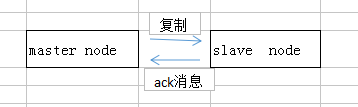
- 客户端client写数据到master的速度可能大于master复制数据到slave的速度,master可能已经缓存了2000条数据了,而slave才复制了1200条,此时master宕机的话就会丢失800条,而设置了min-slaves-to-write和min-slaves-max-lag就是限制了如果延时超过10S,master就先不接受写请求了,客户端自己在内存中暂时缓存,尝试写其他master或者停顿一段时间。一般这种情况会在客户端做降级,写到磁盘里,在client对外接收请求,再做降级,做限流,减慢请求涌入的速度,或者client会采取将数据临时灌入一个kafka中,每隔10分钟去队列里取一次,尝试重新发回master。
- 对场景2,如果一个master出现了脑裂,跟其他slave丢了连接,那么上面两个配置可确保说,如果不能继续给指定数量的slave发送数据,而且slave超过10秒没有给自己ack消息,那么就直接拒绝客户端的写请求。这样脑裂后的旧master就不会接受client的新数据,避免了数据丢失。上面的配置确保了,如果跟任何一个slave丢了连接,在10秒后发现没有slave给自己ack消息,就拒绝新的写请求,因此在脑裂场景下如此设置,最多丢失10秒的数据。
(10)redis哨兵的7个核心底层原理(包含slave选举算法)
- --1-- sdown和odown转换机制:sdown和odown是两种失败状态
- sdown是主观宕机,就是一个哨兵如果自己觉得一个master宕机了,那么就是主观宕机;
- odown是客观宕机,如果quorum数量的哨兵都觉得一个master宕机了,那么就是客观宕机;
- sdown达成的条件:如果一个哨兵去ping一个master,超过了is-master-down-after-milliseconds指定的毫秒数之后,就主观认为master宕机了;
- sdown到odown转换的条件:如果一个哨兵在指定时间内,收到了quorum指定数量的其他哨兵也认为那么master是sdown了,那么就认为是odown了,客观认为master宕机。
- --2-- 哨兵集群的自动发现机制: 哨兵之间的相互发现是通过redis的pub/sub系统实现的。
- 每个哨兵都会往_sentinal_ :hello 这个channel里发送一个消息,其他哨兵去这个channel订阅消息,这时候所有其他哨兵都可以消费到这个消息,并感知到其他哨兵的存在;
- 每隔两秒钟,每个哨兵都会往自己监控的某个master+slave对应的_sentinal_ :hello这个channel里发送一个消息,内容是自己的host、ip和runid,还有对这个master的监控配置;
- 每个哨兵也会去监听自己监控的每个master+slave对应的_sentinal_ :hello这个channel,然后去感知到同样在监听这个master+slave的其他哨兵的存在;
- 每个哨兵还会跟其他哨兵交换对master的监控配置,互相进行监控配置的同步。
- --3-- slave配置的自动纠正:
- 哨兵会负责自动纠正slave的一些配置,比如slave如果要成为潜在的master候选人,哨兵会确保slave在复制现有master的数据;
- 如果slave连接到了一个错误的master上,比如故障转移后,那么哨兵会确保他们连接到正确的master上(哨兵会确保其他slave修改配置)。
- --4-- slave-->master选举算法:
- 如果一个master被认为odown了,而且majority哨兵都允许了主备切换,那么某个哨兵就会执行主备切换操作,此时首先是要选举一个slave出来;
- 会考虑slave的一些信息:
- (1)跟master断开连接的时长:(先筛选掉不适合做master的)如果一个slave跟master断开连接已经超过了down-after-milliseconds的10倍,外加master宕机的时长,那么slave就被认为不适合选举为master(slave跟master的数据相差可能很多了):
- (down-after-milliseconds * 10)+ milliseconds_since_master_is_in_SDOWN_state ;
- 接下来会对slave进行排序
- (2)slave优先级:按照slave优先级进行排序,slave-priority越低,优先级越高(slave-priority默认100);
- (3)复制offset:如果slave priority相同,那么看replica offset,哪个slave复制了超多的数据,offset越靠后,优先级就越高;
- (4)run id:如果前两个条件都相同,那么选一个run id较小的那个slave。
- --5-- quorum 和 majority:
- 每次一个哨兵要做主备切换,首先要quorum数量的哨兵都认为sdown(即odown客观认为master宕机了),然后选举出一个哨兵来做切换,这个哨兵还得得到majority哨兵的授权才能正式执行切换;
- 如果quorum<majority,比如5个哨兵,majority就是3,quorum设为2,那么就要3个哨兵授权就可以执行切换;
- 如果quorum>=majority,那么必须quorum数量的哨兵都授权,比如5个哨兵,quorum设为5,那么必须5个哨兵都同意授权才能执行切换。
- --6-- configuration epoch:
- 执行切换的那个哨兵,会从要切换到的新master那里得到一个configuration epoch,这就是一个version号,每次切换的version都必须是唯一的;
- 如果第一个选举出的哨兵切换失败了,那么其他哨兵会等待一个failover-timeout时间,然后接替继续执行切换,此时会重新获取一个新的configuration epoch,作为新的version号。
- --7-- configuration传播:
- 哨兵完成切换后,会在自己本地更新生成最新的master配置,然后同步给其他哨兵,就是之前的pub/sub消息机制;
- 这里之前的version号就很重要了,因为各种消息都是通过一个channel去发布和监听的,所以一个哨兵完成一次新的切换后,新的master配置是跟着新的version的,其他哨兵都是根据版本号大小来更新自己的master配置的。
三、持久化
如果只把redis当作缓存服务器,那么完全不用考虑持久化,但是大多数服务器架构中,redis不单单只做缓存服务器,还可以作为数据库保存业务数据,就需要持久化。
Redis的两种数据持久化方式:RDB、AOF(append-only file追加)
1、RDB:快照存储数据持久化方式。将redis某一时刻的内存数据保存到硬盘的文件中,默认保存的文件名为dump.rdb,在redis服务器启动时,会重新加载dump.rdb文件中的数据到内存中恢复数据。
三种生成RDB文件的方式:
(1)save命令(占用主进程,阻塞其他客户端请求)、
(2)bgsave命令(新增子进程来同步数据,当forks子进程数据量大时也会阻塞)、
(3)服务器配置自动触发(redis.conf中配置 save 300 10 多少秒内至少达到多少次写操作就备份数据)
优点:(1)与AOF相比,通过rdb文件恢复数据比较快;(2)rdb文件非常紧凑,适合数据备份;(3)使用子进程进行数据备份,对redis服务器性能影响小;
缺点:(1)服务器宕机的话,而没有触发设置同步数据的条件,可能会丢失某段时间内的数据;
(2)save方式会造成服务器阻塞;
(3)bgsave方式在forks子进程时数据量大,也会发生阻塞;
(4)兼容性差:RDB文件需要满足特定格式,老版本redis不兼容新版本的RDB文件。
2、AOF:append-only file,记录客户端对服务器的每次写操作命令,并将这些写操作以Redis协议追加保存到以后缀aof文件末尾。在redis服务器重启时,会加载并运行aof文件的命令,恢复数据。
开启AOF持久化方式,redis默认不开启,可通过redis.conf文件配置:appendonly yes
写入.aof文件的三种策略:appendfsync always(每个写操作都保存到.aof文件) / everysec(默认,每秒写入一次.aof文件,最多会丢失1秒的数据) / no(不推荐)
优点:AOF只是追加日志文件,对服务器性能影响小,备份数据速度比RDB快,消耗内存少;兼容性好
缺点:生成的日志文件太大;恢复数据的速度比RDB慢;对性能影响大
3、当RDB和AOF两种方式都开启时,Redis会优先使用AOF日志文件来恢复数据,因为AOF保存的文件比RDB更完整。
四、redis的并发竞争问题如何解决?
单进程单线程模式,采用队列模式将并发访问变为串行访问
五、redis常用管理命令
# dbsize 返回当前数据库 key 的数量
# info 返回当前redis服务器状态和一些统计信息
# monitor 实时监听并返回redis服务器接收到的所有请求信息
# shutdown 把数据同步保存到磁盘上,并关闭redis服务
# flushdb 慎用,删除当前数据库中所有key,此方法不会失败
# flushall 慎用,删除全部数据库中所有key,此方法不会失败
另:查询key是否存在:exists key +key名字
删除key: del key key2 ...
六、redis客户端与服务端之间的通讯协议:RESP。实现简单、快速解析、可读性好;
七:redis设置过期时间的四种方式:
1、expire key seconds :设置key在n秒后过期
2、pexpire key milliseconds :设置key在n毫秒后过期
3、expireat key timestamp :设置key在某个时间戳(精确到秒)之后过期
4、pexpireat key millisecondsTimestamp: 设置key在某个时间戳(精确到毫秒)之后过期
八、redis三种删除策略
定时删除:设置键的过期时间并设置一个定时任务,当键达到过期时间,立即执行对键的删除操作。缺点是过期键多的话对应的删除任务也多,占CPU
惰性删除:从键空间获取键时,检查键是否过期,过期就删除否则返回该键。 缺点是过期键可能不会被删除(没查询这个键),占内存
定期删除:每隔一点时间,程序对数据库检查,删除过期键