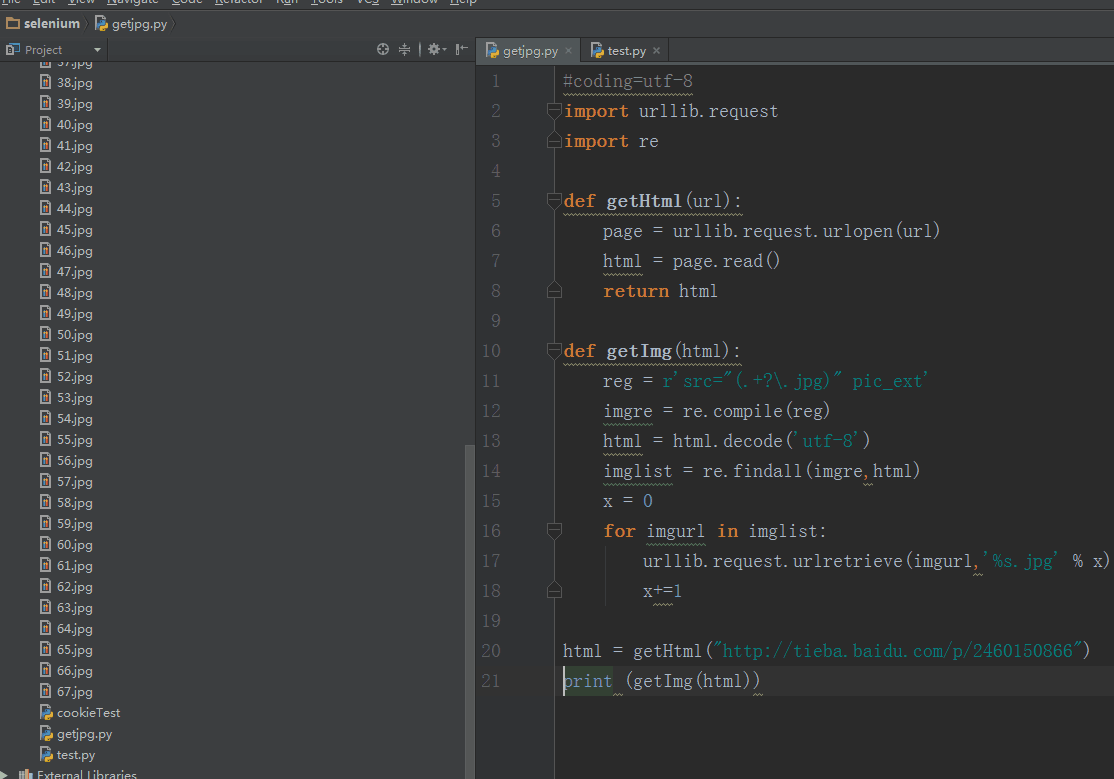
在网上查看大神的关于Python爬虫的文章,代码如下:
#coding=utf-8
import urllib
import re
def getHtml(url):
page = urllib.urlopen(url)
html = page.read()
return html
def getImg(html):
reg = r'src="(.+?.jpg)" pic_ext'
imgre = re.compile(reg)
imglist = re.findall(imgre,html)
x = 0
for imgurl in imglist:
urllib.urlretrieve(imgurl,'%s.jpg' % x)
x+=1
html = getHtml("http://tieba.baidu.com/p/2460150866")
print getImg(html)
以下则是在运行上述代码过程中遇到的相关问题,以及解决方式,虽然不怎么高级,但是也算是一种学习思路吧。
问题1:在Python3.2的环境下,未运行时,代码会报错:
解决1:将
print getImg(html)
修改为
print (getImg(html))
问题2:代码执行后,报如下错误:
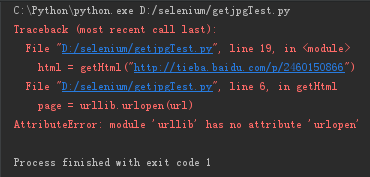
解决2:度娘进行搜索,才发现3.2不兼容2.0的,于是进入官方文档查找最新的调用方式,对这三行进行以下修改,修改前:
import urllib page = urllib.urlopen(url) urllib.urlretrieve(imgurl,'%s.jpg' % x)
修改后:
import urllib.request page = urllib.request.urlopen(url) urllib.request.urlretrieve(imgurl,'%s.jpg' % x)
问题3:运行代码,提示以下错误:
C:Pythonpython.exe D:/selenium/getjpgTest.py
Traceback (most recent call last):
File "D:/selenium/getjpgTest.py", line 20, in <module>
print (getImg(html))
File "D:/selenium/getjpgTest.py", line 13, in getImg
imglist = re.findall(imgre,html)
File "C:Pythonlib
e.py", line 213, in findall
return _compile(pattern, flags).findall(string)
TypeError: cannot use a string pattern on a bytes-like object
Process finished with exit code 1
解决3:百度之后,很容易得到答案,加上下面一句代码即可解决:
html=html.decode('utf-8')
最终得到以下代码:
#coding=utf-8
import urllib.request
import re
def getHtml(url):
page = urllib.request.urlopen(url)
html = page.read()
return html
def getImg(html):
reg = r'src="(.+?.jpg)" pic_ext'
imgre = re.compile(reg)
html = html.decode('utf-8')
imglist = re.findall(imgre,html)
x = 0
for imgurl in imglist:
urllib.request.urlretrieve(imgurl,'%s.jpg' % x)
x+=1
html = getHtml("http://tieba.baidu.com/p/2460150866")
print (getImg(html))
执行结果如下: