什么是Mysql慢查询日志?
当SQL语句执行时间超过所设定的阈值时,便会记录到指定的日志文件中或者表中,所有记录内容称之为慢查询日志
为什么要收集Mysql慢查询日志?
数据库在运行期间,可能会存在这很多SQL语句标准性的问题,那么我们如何快速的去定位,分析哪些SQL语句需要优化处理,又是哪些SQL语句给业务系统造成影响呢?当我们进行统一的收集分析,这样开发和运维就不会产生矛盾,就不会相互的“撕咬”了;SQL语句执行的时间,对应的语句以及具体的写法一切尽收眼底~
如何收集Mysql慢查询日志或者是说具体思路是什么?
1.首先我们的数据采集者仍然是通过filebeat这个工具,对慢查询日志进行采集;
1.1:开启慢查询日志(永久生效,进入my.cnf配置文件进行修改,重启之后便会生效)
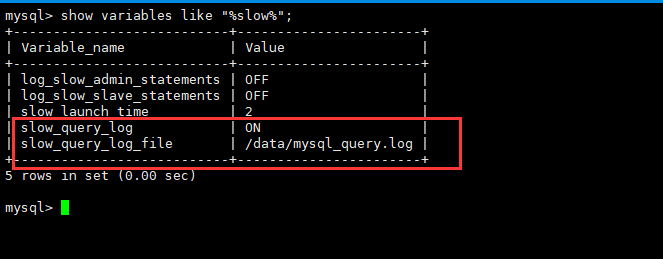
- slow_query_log=ON( log_slow_queries=ON ) #前者是Mysql5.6之后的开启方法;后者是Mysql5.6之前的开启方法;这里版本采用是5.5版本,故此都生效
- slow_query_log_file=/dada/mysql/the_slow_query.log #指定mysql慢查询日志的存储目录位置
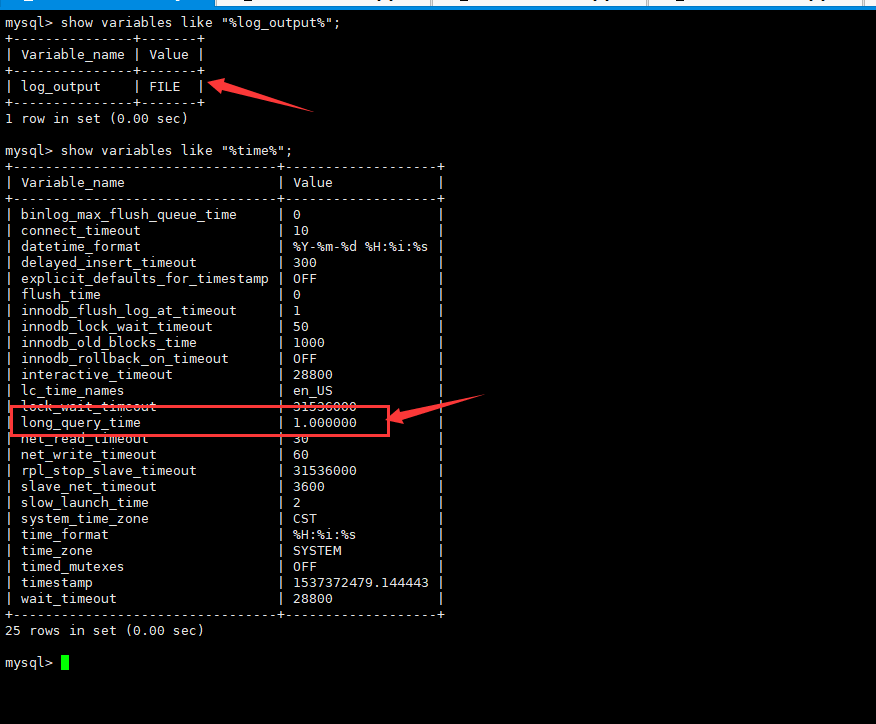
- long_query_time=1 #指定慢查询的时间阈值
- log_outpu=FILE #表示慢查询日志存放于指定的文件中
1.2:因为Mysql慢查询的格式多行格式,并且不同mysql版本的慢查询日志格式也不经相同,需要考虑将其“#Time”字段过滤掉并整合成为为一整条完整的日志输出,可以借助filebeat的muitline.negate选项,将慢日志查询日志多行合并到一起,输出为一条日志;
2.在logstash事件配置中,我们将拉取到的日志在此通过file过滤处理(通过grok的match插件将日志分为四种情况,当有多条匹配规则存在,就会依次匹配)根据不同情况(数据库版本不同,慢查询亦不同,有id有user,有id无user,无id有user,无id无user)四种情况进行判断匹配,
[mysql5.6版本my.conf配置]
slow_query_log=ON #开启慢查询日志
slow_query_log_file=/data/mysql_query.log #重新定义慢查询日志路径
long_query_time=1 #设定sql语句执行超时时间
[root@test ~]# systemctl restart mysqld
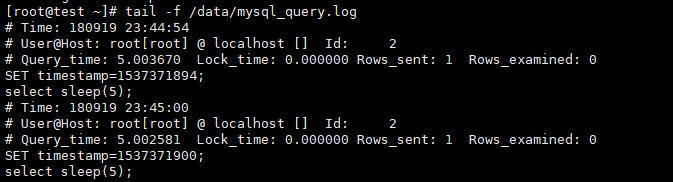
mysql> select sleep(5); #执行测试语句,验证慢日志输出,只要超过1秒设定的阀值即可
# tail -f /dada/mysql_query.log
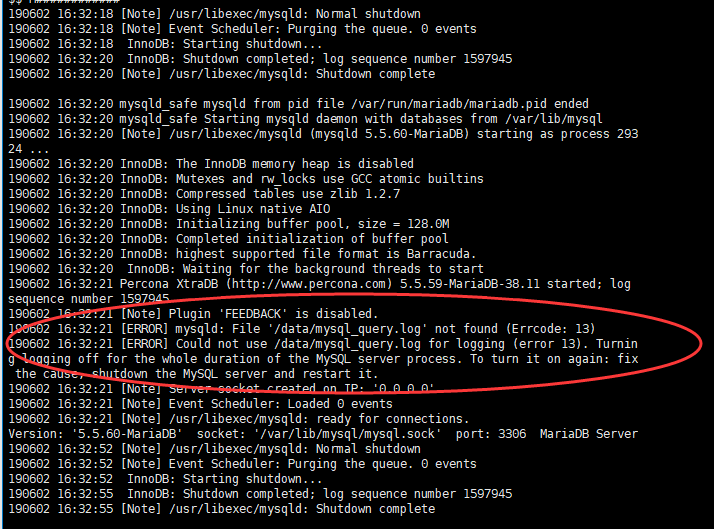
配置完慢查询日志路径时,切记不要忘记给予mysql属组属主权限,否则重启mysql服务之后,即使通过sql语句查询到慢查询日志位置,但是也没有生效,报错如下:
【拓展】
MariaDB [(none)]> show variables like "%log_output%"; #查看日志存放方式
MariaDB [(none)]> show global status like "%slow_queries%"; #mysql服务自启动到当前时间点的慢查询次数统计
【filebeat配置】
# vim /usr/local/filebeat/filebeat.yml
filebeat.inputs: #定义数据的原型 - type: log #定义的数据如如类型是log,为默认值。 enabled: true #启动手工配置filebeat paths: - /data/mysql_query.log #这是指定mysql慢查询日志文件的路径 fields: log_topic: mysqlslowlogs #定义一个新字段log_topic,值为mysql_slowlogs;用于kifka的topic主题 exclude_lines: ['^# Time'] #支持正则,排除匹配的行,如果有多行,合并成整行过滤;这里过滤掉# Time开头的行 multiline.negate: true #匹配多行时指定正则表达式,这里匹配以# Time或者# User开头的行,Time行要先匹配再过滤 multiline.match: after #定义如何将匹配行组合成时间,在之前或者之后,有 "after"、 "before"两个值。multiline.pattern: '^# Time|^# User'
multiline.pattern: '^# Time|^# User'
processors: #filebeat对应的消息类型 - drop_fields: #删除无用的字段 fields: ["beat", "input", "source", "offset", "prospector"] filebeat.config.modules: #模块配置,默认情况下会加载modules.d目录中启用的模块 path: ${path.config}/modules.d/*.yml reload.enabled: false #重新加载,为关闭状态 name: 192.168.37.134 #host主机名称,指定本地日志收集的服务器IP即可 output.kafka: #filebeat支持多种输出,如kafka,logstash,elasticsearch等 enabled: true #表示启动该模块 hosts: ["192.168.37.134:9092", "192.168.37.135:9092", "192.168.37.136:9092"] #指定输出数据到kafka集群地址中,加上端口号 version: "0.10" topic: '%{[fields.log_topic]}' #自动获取日志分类,此处格式为filebeat6.x版本专配 partition.round_robin: #分区 reachable_only: true worker: 2 required_acks: 1 compression: gzip #压缩格式 max_message_bytes: 10000000 #最大消息字节 logging.level: debug #debug日志级别 filebeat的配置,重点是multiline.negate选项,通过此选项,将mysql慢查询日志多行合并到了一起,输出为一条日志。
[root@test filebeat]# nohup ./filebeat -e -c filebeat.yml &
【Logstash事件配置】
# vim /usr/local/logstash/config/etc/mysql_logs_query.conf
input { kafka { bootstrap_servers => "192.168.37.134:9092,192.168.37.135:9092,192.168.37.136:9092" topics => ["mysqlslowlogs"] } } filter { json { source => "message" } grok { # 有ID有use match => [ "message", "^#s+User@Host:s+%{USER:user}[[^]]+]s+@s+(?:(?<clienthost>S*) )?[(?:%{IP:clientip})?]s+Id:s+%{NUMBER:id} # Query_time: %{NUMBER:query_time}s+Lock_time: %{NUMBER:lock_time}s+Rows_sent: %{NUMBER:rows_sent}s+Rows_examined: %{NUMBER:rows_examined} uses(?<dbname>w+); SETs+timestamp=%{NUMBER:timestamp_mysql}; (?<query>[sS]*)" ] # 有ID无use match => [ "message", "^#s+User@Host:s+%{USER:user}[[^]]+]s+@s+(?:(?<clienthost>S*) )?[(?:%{IP:clientip})?]s+Id:s+%{NUMBER:id} # Query_time: %{NUMBER:query_time}s+Lock_time: %{NUMBER:lock_time}s+Rows_sent: %{NUMBER:rows_sent}s+Rows_examined: %{NUMBER:rows_examined} SETs+timestamp=%{NUMBER:timestamp_mysql}; (?<query>[sS]*)" ] # 无ID有use match => [ "message", "^#s+User@Host:s+%{USER:user}[[^]]+]s+@s+(?:(?<clienthost>S*) )?[(?:%{IP:clientip})?] # Query_time: %{NUMBER:query_time}s+Lock_time: %{NUMBER:lock_time}s+Rows_sent: %{NUMBER:rows_sent}s+Rows_examined: %{NUMBER:rows_examined} uses(?<dbname>w+); SETs+timestamp=%{NUMBER:timestamp_mysql}; (?<query>[sS]*)" ] # 无ID无use match => [ "message", "^#s+User@Host:s+%{USER:user}[[^]]+]s+@s+(?:(?<clienthost>S*) )?[(?:%{IP:clientip})?] # Query_time: %{NUMBER:query_time}s+Lock_time: %{NUMBER:lock_time}s+Rows_sent: %{NUMBER:rows_sent}s+Rows_examined: %{NUMBER:rows_examined} SETs+timestamp=%{NUMBER:timestamp_mysql}; (?<query>[sS]*)" ] } date { match => ["timestamp_mysql","UNIX"] #这里我们需要对日志输出进行时间格式转换,默认将timestamp_mysql的unix时间格式之后直接赋值给timestamp target => "@timestamp" } mutate { remove_field => "@version" #版本字段,删除不需要的字段 remove_field => "message" #在上述,我们已经对mysql的慢日志输出分段了,所以message输出已经是多余的了,故此删除 } } output { elasticsearch { hosts => ["192.168.37.134:9200","192.168.37.135:9200","192.168.37.136:9200"] #将filebeat采集到的数据输出到ES中 index => "mysql-slowlog-%{+YYYY.MM.dd}" #索引文件名称 } #stdout{ #codec=> rubydebug #} }
[root@localhost etc]# nohup /usr/local/logstash/bin/logstash -f mysql_logs_query.conf & #后台运行
ps:可stdount终端输出验证正常
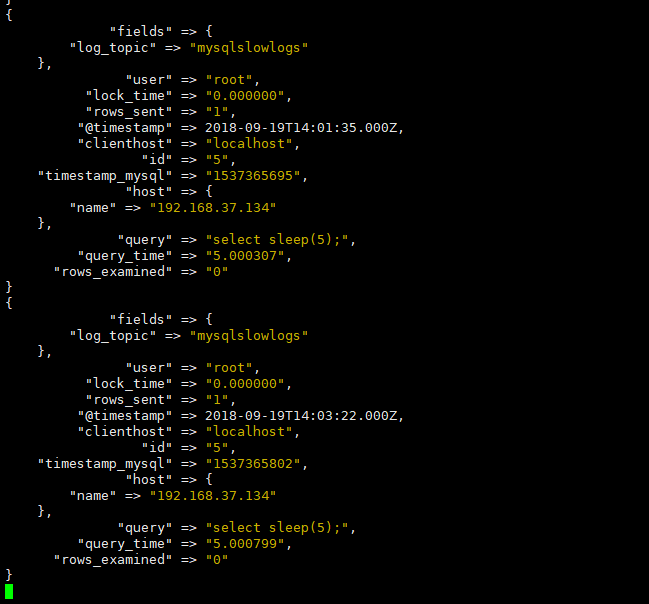
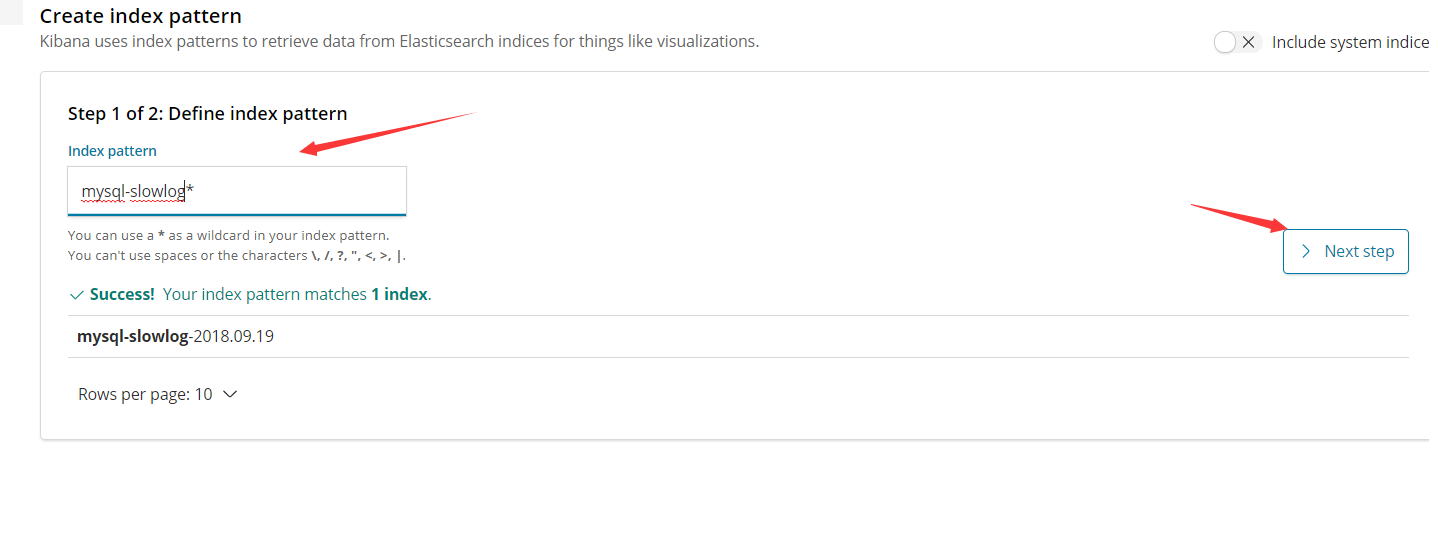
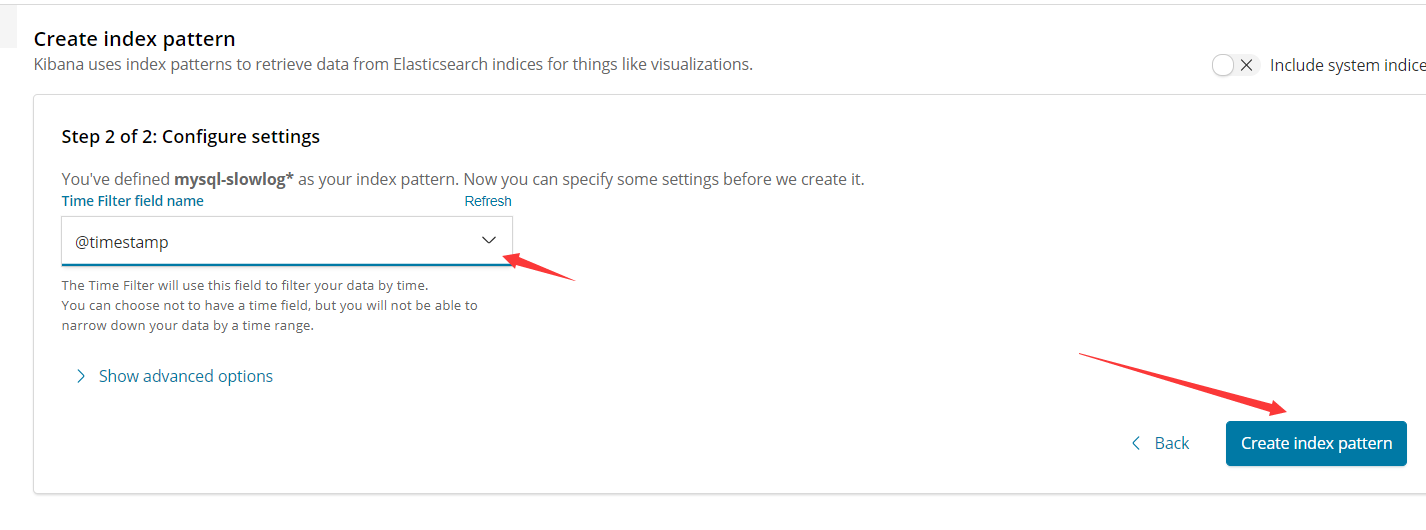
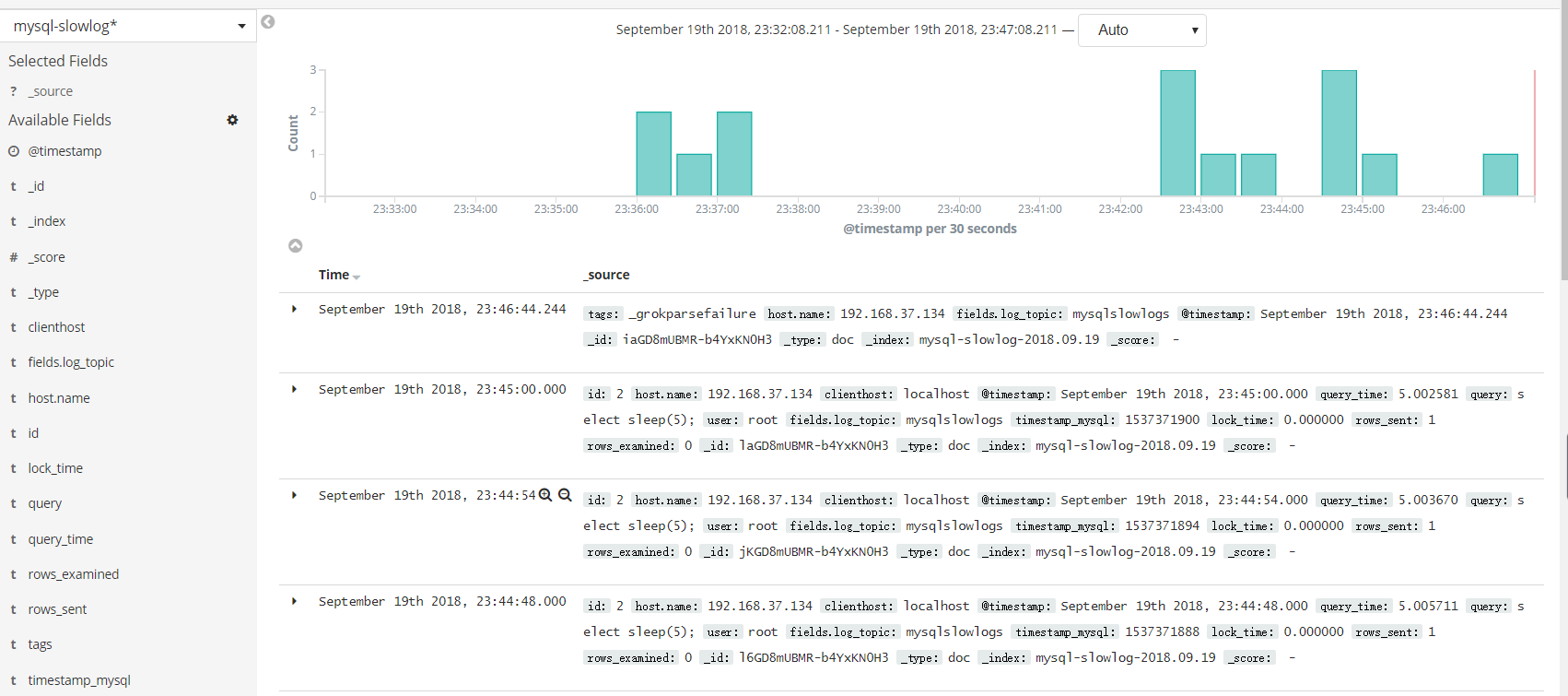
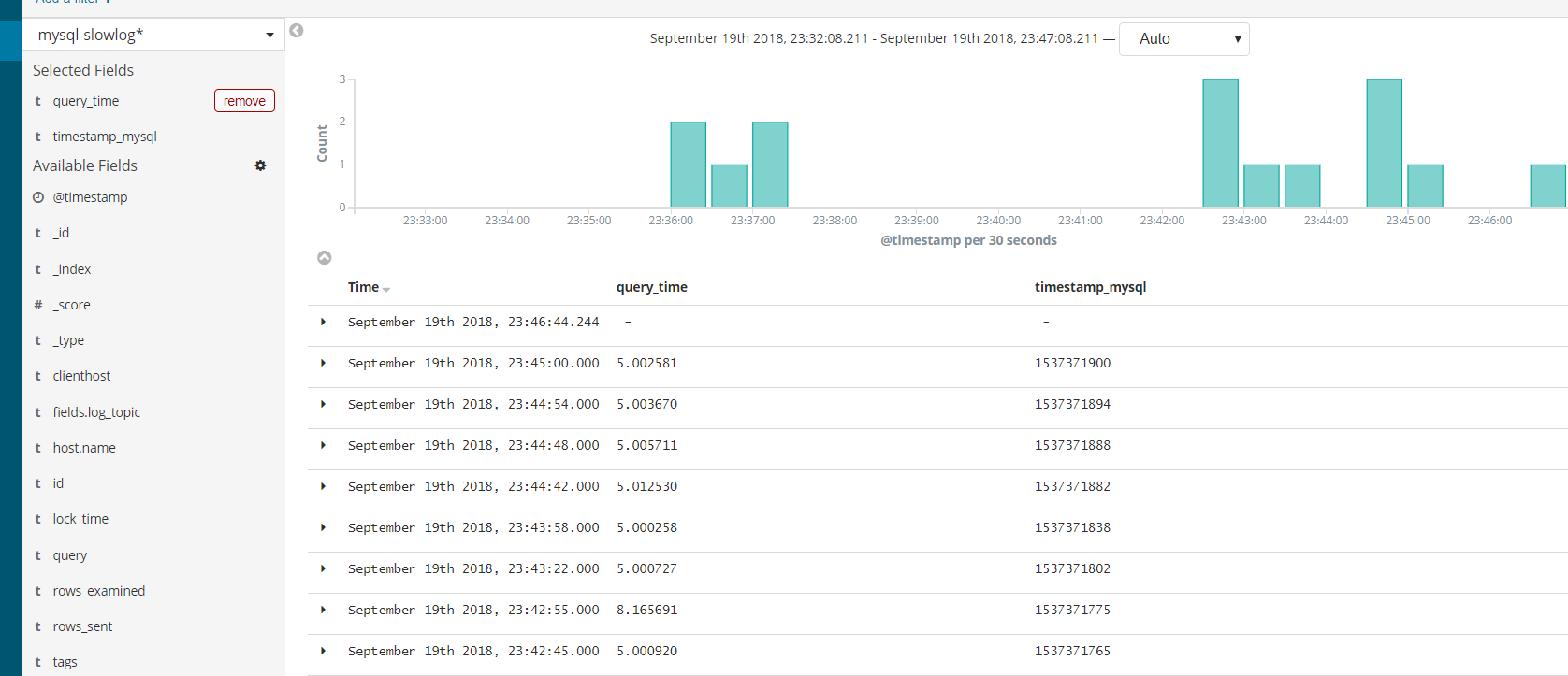
【Kibana登录验证】