前言:通常体质被分散存储在不同的设备上面,在庞大的服务器集群中,我们需要集中化的管理,日志的统计和检索,一般我们使用grep和awk,wc等linux命令虽然能够实现检索和统计,但是呢,对于要求更高的查询,排序等环境会有很大的压力和瓶颈;于是我们需要对于日志进行集中化的管理,将所有机器上面的日志信息进行收集,汇总到一起,完整的日志数据具有非常重要的作用;
1)信息查找 ,通过检索日志信息,定位相应的bug,及时找出解决方案
2)服务诊断(信息判断),通过检索日志信息,进行统计和分析,从而了解服务器的负载情况和运行状态,判断问题的所在点
3)数据分析,如果是格式化的log日志,可以做进一步的数据分析,统计和检索,汇总出最具价值的信息;

【ELK组成结构】
1)Elasticsearch:基于lucnne(卢斯)的开源分布式搜索引擎,同时是基于java开发的,其主要特点:分布式,零配置,自动发现 ,索引分片,索引副本机制,restful风格接口,多数据源,自动搜索负载等
Ps:关键词详解:
Lucene:是一款高性能,可扩展的信息检索工具库,信息检索是指文档搜索,文档内信息搜索或者文档相关的元数据搜索等操作
Restful:对于rest理解就是web服务的一种架构风格,面向资源的资源的架构,使用不同的协议实现轻量级,跨品台,跨语言的架构设计;同时是一种思想设计;
索引分片::在elasticsearch中索引是一个保存相关数据的地方,索引实际上是指向一个或多个物理分片的逻辑命名空间;在这里,需要知道,一个分片就是一个lucene实例,本身就是一个完整的搜索引擎,·我们的数据都存储和索引到分片内;ES就是利用分片将数据分发到集群各处,可以理解为分片是数据的容器,分片又被分配到集群各个节点,使得数据得以均衡;
2)Logstash:是一个完全开源的工具 ,可以对日志进行收集 ,过滤,并将其存储供以后使用(也就是搜索。工作 模式是C/S架构,Clinet端安装在需要收集日志的机器上,server负责将收集到的日志信息数据进行过滤,一并发给elasticsearch)
3)Kibana可以理解为基于浏览器页面的elasticsearch前端展示工具,也是开源免费的工具,为logstash和elasticsearch提供日志分析友好的web界面,可以实现汇总,分析和搜索重要的数据日志;
Ps:logstash和elasticsearch是用java语言编写的,而kibana是使用node.js框架,所以说在配置ELK环境要保证JDK开发库;
【ELK原理剖析】
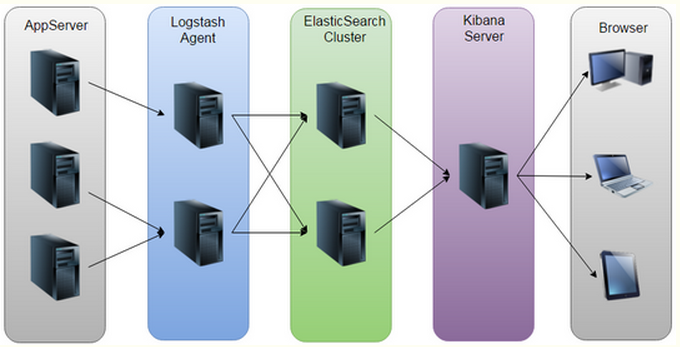
如上所示:LEK原理也就是工作流程,通过Logstash手机客户端app的日志信息数据,将所有的日志过滤出来,并存到Elasticsearch搜索引擎里,然后通过Kibana GUI在web前端展示给用户,用户需要可以进行查看指定的日志内容信息;
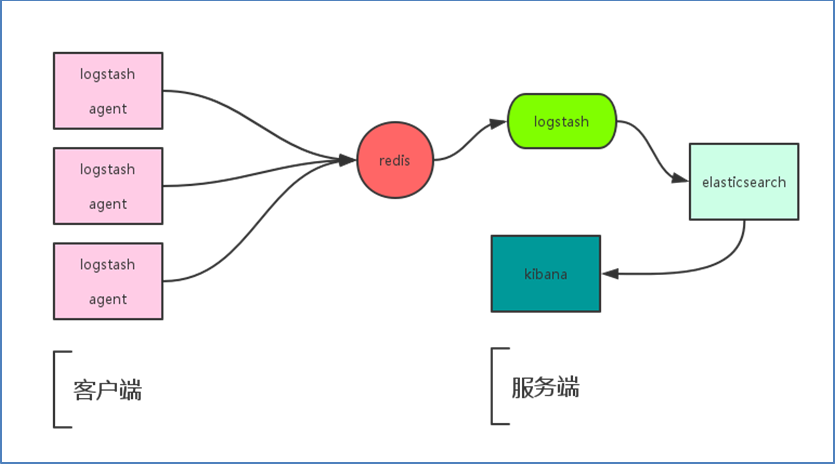
加入Redis之后的ELK的工作流程:
Logstash包含了indexer和Agent(shipper),Agent负责客户端监控和过滤日志,而index负责日志并将日志信息交给elasticsearch,随后 elasticsearch将日志存储到本地,并建立索引,提供搜索,Kibana可以从Elasticsearch中获取想要的日志信息,最后再展示给用户 ;
【集中式日志系统特点汇总】
1)收集:能够收集到各种来源的日志信息
2)传输;能够稳定且实时有效的将数据传输到中央系统
3)存储:如何有效的将日志 进行索引分片处理
4)分析:通过 Kibana CUI进行展示分析
5)告警:能够抓住关键性信息数据,进行告警处理
【ELK部署方案详解】
Logstash是一个ETL工具,负责从每个台机器上采集日志数据,对数据进行有效过滤和处理,传输到Elasticsearch中存储,Elasticsearch是一个分布式搜索分析引擎 ,主要用于存储数据 同时提供实时的数据查询,Kibana是一个数据可视化的web服务展示平台,根据用户选择性的要求从Elasticsearch中查询数据,形成相应的分析结果,以图形化的形式展示给用户
思路:
1)在每台需要收集日志的机器上面部署Logstach,作为Shipper的角色,监控抓取和过滤日志信息,并将其传输到Redis消息列队中,另一个角色Index,负责从Redis中获取数据。对数据进行格式化和相关操作后,输出到Elasticsearch中存储
2)部署Elasticsearch,取决于日志信息量了,如果 数据量大,则需要做集群,集群最好三个节点以上,同时还需要部署相关的监控软件
那么问题来了?为什么不在每台机器上面部署 Logstach直接获取数据,处理并存入Elasticsearch呢?
首先有三个优势:
第一:减轻日志所在机器的负载压力,本身每台机器上面都存在着应用服务所带来的压力,如果继续在这台机器上去搞事情,岂不是崩溃了?
第二:既然收集日志信息,那么收集对象数据量相当庞大,如果 所有机器持续向Elasticsearch中持续写入数据,必然造成Elasticsearch压力过大,导致Elasticsearch“撑死”,所以需要给Elasticsearch有个缓冲的机会,同样日志信息量不丢失;
第三:将日志信息格式化处理和传输的工作交给indexer去做,这样可以在修改同时,避免复杂度,Indexer 作为索引管理工具,提供了批量索引导入、清空索引、刷新索引队列、日志等各项功能
【拓展】
我们需要做的是将数据放入一个消息列队中进行缓冲,redis只是其中的一个选择,还有另外RabbitMQ和Kafka两种方式,其实在生产环境中,用的比较多 的是redis和kafka,但是由于Redis集群一般都是通过key来做分片,无法对list类型做集群,在数据量比较庞大的时候,就不合适了,而kafka天生就是分布式消息 队列系统
【Elasticsearch】
[root@elasticsearch ~]# yum install -y java

[root@elasticsearch ~]# rpm --import https://packages.elastic.co/GPG-KEY-elasticsearch
[root@elasticsearch ~]# vim /etc/yum.repos.d/elasticsearch.repo
[elasticsearch-5.x]
name=Elasticsearch repository for 5.x packages
baseurl=http://packages.elastic.co/elasticsearch/5.x/centos
gpgcheck=1
gpgkey=http://packages.elastic.co/GPG-KEY-elasticsearch
enabled=1
1)配置
[root@elasticsearch ~]# mkdir /data/elasticsearch-data -p
[root@elasticsearch ~]# grep -v "^#" /etc/elasticsearch/elasticsearch.yml #修改elasticsearch配置文件
1 cluster.name: bixiaoyu #组名(集群相同组必须要一致) 2 node.name: elasticsearch #节点名称,建议与主机名一致 3 path.data: /data/elasticsearch-data/ #数据存放位置(ps:数据存放位置是我们刚刚创建的目录路径) 4 path.logs: /var/log/elasticsearch/elasticsearch.log #日志存放位置 5 bootstrap.memory_lock: true 锁住内存,不被使用到交换分区中 6 network.host: 0.0.0.0 #网络设置 7 http.port: 9200 #elasticsearch默认端口
[root@elasticsearch ~]# chown -R elasticsearch:elasticsearch /data/
[root@elasticsearch ~]# systemctl start elasticsearch
[root@elasticsearch ~]# chkconfig elasticsearch on
注意:正在将请求转发到“systemctl enable elasticsearch.service”。
Created symlink from /etc/systemd/system/multi-user.target.wants/elasticsearch.service to /usr/lib/systemd/system/elasticsearch.service.
[root@elasticsearch ~]# systemctl status elasticsearch
● elasticsearch.service - Elasticsearch Loaded: loaded (/usr/lib/systemd/system/elasticsearch.service; enabled; vendor preset: disabled) Active: active (running) since 三 2018-05-30 22:55:55 CST; 13min ago Docs: http://www.elastic.co Main PID: 2425 (java) CGroup: /system.slice/elasticsearch.service └─2425 /bin/java -Xms256m -Xmx1g -Djava.awt.headless=true -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:CMSInitiatingOccupancyFraction=75 -XX:+... 5月 30 22:55:58 elasticsearch elasticsearch[2425]: [2018-05-30 22:55:58,348][INFO ][env ] [Tessa] using [1] data paths, mou...[rootfs] 5月 30 22:55:58 elasticsearch elasticsearch[2425]: [2018-05-30 22:55:58,348][INFO ][env ] [Tessa] heap size [1015.6mb], com...s [true] 5月 30 22:56:00 elasticsearch elasticsearch[2425]: [2018-05-30 22:56:00,346][INFO ][node ] [Tessa] initialized 5月 30 22:56:00 elasticsearch elasticsearch[2425]: [2018-05-30 22:56:00,346][INFO ][node ] [Tessa] starting ... 5月 30 22:56:00 elasticsearch elasticsearch[2425]: [2018-05-30 22:56:00,415][INFO ][transport ] [Tessa] publish_address {127.0.0.....1:9300} 5月 30 22:56:00 elasticsearch elasticsearch[2425]: [2018-05-30 22:56:00,419][INFO ][discovery ] [Tessa] elasticsearch/4zbxGI80SvOJLFh7Y2slxg 5月 30 22:56:03 elasticsearch elasticsearch[2425]: [2018-05-30 22:56:03,472][INFO ][cluster.service ] [Tessa] new_master {Tessa}{4zbxGI...eceived) 5月 30 22:56:03 elasticsearch elasticsearch[2425]: [2018-05-30 22:56:03,502][INFO ][http ] [Tessa] publish_address {127.0.0.....1:9200} 5月 30 22:56:03 elasticsearch elasticsearch[2425]: [2018-05-30 22:56:03,502][INFO ][node ] [Tessa] started 5月 30 22:56:03 elasticsearch elasticsearch[2425]: [2018-05-30 22:56:03,504][INFO ][gateway ] [Tessa] recovered [0] indices int...er_state Hint: Some lines were ellipsized, use -l to show in full.
PS:通过状态可以看出elasticsearch设置的内存最小为256m,最大1G
[root@elasticsearch ~]# netstat -antlp | grep -E "9200|9300"
