什么是索引
索引在MySQL中也叫是一种“键”,是存储引擎用于快速找到记录的一种数据结构。索引对于良好的性能非常关键,尤其是当表中的数据量越来越大时,索引对于性能的影响愈发重要。
索引优化应该是对查询性能优化最有效的手段了。索引能够轻易将查询性能提高好几个数量级。
索引相当于字典的音序表,如果要查某个字,如果不使用音序表,则需要从几百页中逐页去查。
索引的原理
索引的目的在于提高查询效率,与我们查阅图书所用的目录是一个道理:先定位到章,然后定位到该章下的一个小节,然后找到页数。相似的例子还有:查字典,查火车车次,飞机航班等
本质都是:通过不断地缩小想要获取数据的范围来筛选出最终想要的结果,同时把随机的事件变成顺序的事件,也就是说,有了这种索引机制,我们可以总是用同一种查找方式来锁定数据。
磁盘IO与预读


简单介绍一下磁盘IO和预读,磁盘读取数据靠的是机械运动,每次读取数据花费的时间可以分为寻道时间、旋转延迟、传输时间三个部分,寻道时间指的是磁臂移动到指定磁道所需要的时间,主流磁盘一般在5ms以下;旋转延迟就是我们经常听说的磁盘转速,比如一个磁盘7200转,表示每分钟能转7200次,也就是说1秒钟能转120次,旋转延迟就是1/120/2 = 4.17ms;传输时间指的是从磁盘读出或将数据写入磁盘的时间,一般在零点几毫秒,相对于前两个时间可以忽略不计。那么访问一次磁盘的时间,即一次磁盘IO的时间约等于5+4.17 = 9ms左右,听起来还挺不错的,但要知道一台500 -MIPS(Million Instructions Per Second)的机器每秒可以执行5亿条指令,因为指令依靠的是电的性质,换句话说执行一次IO的时间可以执行约450万条指令,数据库动辄十万百万乃至千万级数据,每次9毫秒的时间,显然是个灾难。
考虑到磁盘IO是非常高昂的操作,计算机操作系统做了一些优化,当一次IO时,不光把当前磁盘地址的数据,而是把相邻的数据也都读取到内存缓冲区内,因为局部预读性原理告诉我们,当计算机访问一个地址的数据的时候,与其相邻的数据也会很快被访问到。每一次IO读取的数据我们称之为一页(page)。具体一页有多大数据跟操作系统有关,一般为4k或8k,也就是我们读取一页内的数据时候,实际上才发生了一次IO,这个理论对于索引的数据结构设计非常有帮助。
索引的数据结构
b树
balance tree

b+树
高度可控的多路搜索树
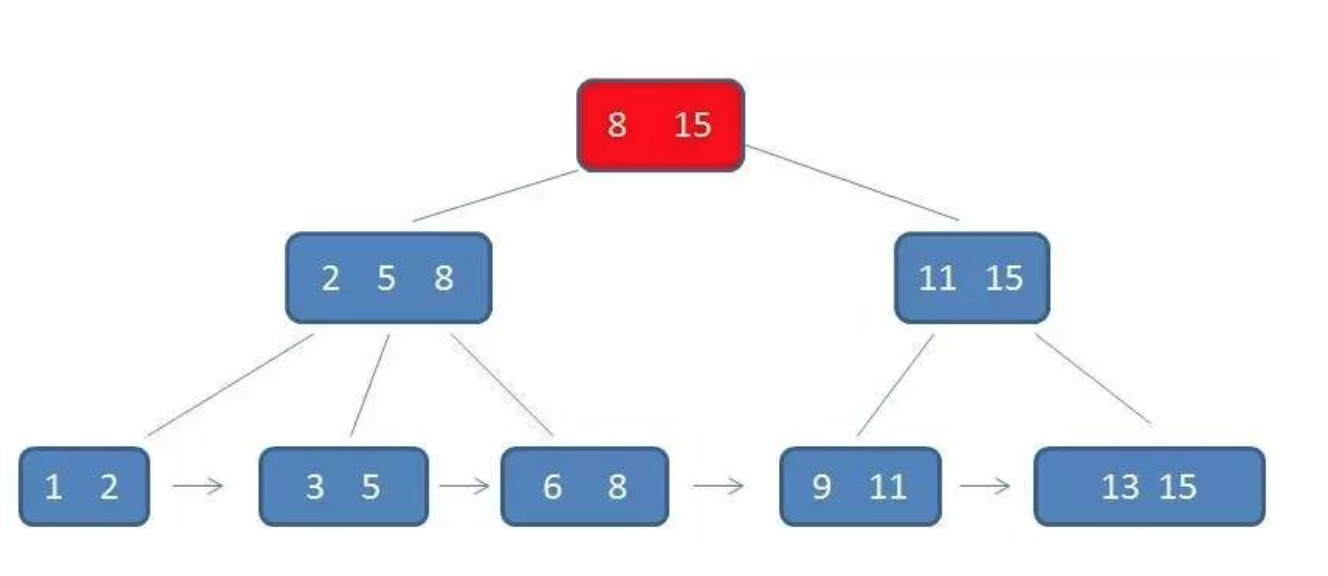
b+树是通过二叉查找树,再由平衡二叉树,b树演化而来
b+树特点
数据只储存在叶子节点
在子节点之间加入了双线连接,更方便的在子节点之间进行数据的读取
聚集索引和辅助索引
数据库中的B+树索引可以分为聚集索引(clustered index)和辅助索引(secondary index),
聚集索引与辅助索引相同的是:不管是聚集索引还是辅助索引,其内部都是B+树的形式,即高度是平衡的,叶子结点存放着所有的数据。
聚集索引与辅助索引不同的是:叶子结点存放的是否是一整行的信息
辅助索引
创建的索引列的数据储存在树形结构的叶子节点上
储存的内容:索引列 + id列
聚集索引
直接把整行数据写到叶子节点上
不同引擎的索引
innodb引擎
聚集索引 只有一个主键
辅助索引 除了主键之外的所有索引都是辅助索引 (回表:只查询一个索引不能解决查询的问题,还需要到具体的表中去获取整行数据)
myisam引擎
都是辅助索引
MySQL常用索引
primary key 主键的创建自带索引效果 非空 + 唯一 + 聚集索引
unique 唯一约束的创建自带索引效果 唯一 + 辅助索引
index 普通的索引 辅助索引
基本语法
创建索引
create index 索引名字 on 表(字段);
删除索引
drop index 索引名字 on 表;
索引的优缺点
优点
查找速度快,创建了索引之后查找的效率大幅度提高
缺点
浪费空间,文件所占的硬盘的资源大幅度提高,拖慢写的速度(不要在程序中创建无用的索引)
索引正确的使用方式(怎样命中索引?哪些情况会造成索引不命中?)
1. 所查询的列不是创建了索引的列
2. 在条件中不能带运算或者函数,必须是"字段 = 值"
3. 如果创建索引的列的重复率高(性别,部门),也不能有效利用索引(重复率不超过10%的列比较适合做索引)
4. 数据对应的范围如果太大的话,也不能有效利用索引(不能带 < , > , != , not in 等)
5. like如果把%放在最前面也不能命中索引
6. 多条件的情况
and 只要有一个条件列是索引列就可以命中索引
or 只有所有的条件列都是索引才能命中索引
7. 如果是联合索引,要遵循最左前缀规则
联合索引
对a和b都创建索引
create index ind_mix on (a,b);
在多个条件相连的情况下,使用联合索引的效率要高于使用单字段的索引
1. 创建索引的顺序是a,b,条件从哪一个字段开始出现了范围,索引就失效了
2. 联合索引在使用时遵循最左前缀原则(有a就能命中索引)
3. 联合索引中只有使用and能生效,使用or失效
MySQL收尾
执行计划
explain sql语句
查看sql语句的执行计划(是否命中索引,命中索引类型等)
覆盖索引
查的条件时索引列,并且显示的是查的条件相关的列
explain sql语句 如果看见 using index 表示覆盖索引
索引合并
创建的时候分开创建,用的时候临时合并到一起了
explain sql语句 如果看见 using union 表示索引合并
慢日志
MySQL日志管理 ======================================================== 错误日志: 记录 MySQL 服务器启动、关闭及运行错误等信息 二进制日志: 又称binlog日志,以二进制文件的方式记录数据库中除 SELECT 以外的操作 查询日志: 记录查询的信息 慢查询日志: 记录执行时间超过指定时间的操作 中继日志: 备库将主库的二进制日志复制到自己的中继日志中,从而在本地进行重放 通用日志: 审计哪个账号、在哪个时段、做了哪些事件 事务日志或称redo日志: 记录Innodb事务相关的如事务执行时间、检查点等 ======================================================== 一、bin-log 1. 启用 # vim /etc/my.cnf [mysqld] log-bin[=dir[filename]] # service mysqld restart 2. 暂停 //仅当前会话 SET SQL_LOG_BIN=0; SET SQL_LOG_BIN=1; 3. 查看 查看全部: # mysqlbinlog mysql.000002 按时间: # mysqlbinlog mysql.000002 --start-datetime="2012-12-05 10:02:56" # mysqlbinlog mysql.000002 --stop-datetime="2012-12-05 11:02:54" # mysqlbinlog mysql.000002 --start-datetime="2012-12-05 10:02:56" --stop-datetime="2012-12-05 11:02:54" 按字节数: # mysqlbinlog mysql.000002 --start-position=260 # mysqlbinlog mysql.000002 --stop-position=260 # mysqlbinlog mysql.000002 --start-position=260 --stop-position=930 4. 截断bin-log(产生新的bin-log文件) a. 重启mysql服务器 b. # mysql -uroot -p123 -e 'flush logs' 5. 删除bin-log文件 # mysql -uroot -p123 -e 'reset master' 二、查询日志 启用通用查询日志 # vim /etc/my.cnf [mysqld] log[=dir[filename]] # service mysqld restart 三、慢查询日志 启用慢查询日志 # vim /etc/my.cnf [mysqld] log-slow-queries[=dir[filename]] long_query_time=n # service mysqld restart MySQL 5.6: slow-query-log=1 slow-query-log-file=slow.log long_query_time=3 单位为秒 查看慢查询日志 测试:BENCHMARK(count,expr) SELECT BENCHMARK(50000000,2*3); 日志管理
慢日志通过配置文件开启
数据库/表的导入导出
备份表 :homwork库中的所有表和数据 mysqldump -uroot -p123 work > D:day42a.sql 备份单表 mysqldump -uroot -p123 work course > D:day42a.sql 备份库 : mysqldump -uroot -p123 --databases work > D:day42db.sql 恢复数据: 进入mysql 切换到要恢复数据的库下面 sourse D:day42a.sql
事务
开启事务,给数据加锁,防止数据被多个人同时修改
begin; select id from t1 where name = 'alex' for update; update t1 set id = 2 where name = 'alex'; commit;
多表联查速度慢怎么办
1. 从表结构的角度
尽量用固定长度的数据类型代替可变长数据类型
把固定长度的字段放前面
2. 从数据的角度
表中的数据越多,查询速度就越慢
列多:垂直分表 行多:水平分表
3. 从sql的角度
尽量把条件写的细致,where条件多做筛选
多表尽量用连表代替子查询
创建有效的索引,规避无效的索引
4. 从配置的角度
开启慢日志查询,确认具体的有问题的sql语句并修改
5. 从数据库的角度
读写分离(解决数据库读的瓶颈)