time
time模块 内置的 import直接导入,不需要自己安装的就是内置模块
import time
时间模块分三种
时间戳 给计算机看的
print(time.time()) 浮点型(小数) 给计算机看 可用于简单计算
结构化时间 用来修改
print(time.localtime()) 结构化时间 输出结果为命名元组
字符串时间 给人看的
print(time.strftime(‘%Y-%m-%d %X’)
年 月 日 当前时间
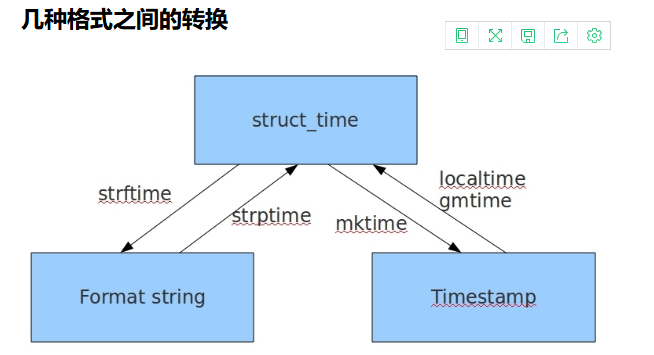
时间戳想转换成字符串时间
先转换成结构化时间
f = time.localtime(time.time()-86400) 减去86400秒,获得一天前的时间
再将结构化时间转换成字符串时间
print(time.strftime('%Y-%m-%d %H:%M:%S',f))
t = '2019-03-20 10:40:00' 这个时间向后退一个月 # 1.转成结构化 f = time.strptime(t,'%Y-%m-%d %X') # 2.结构化时间转成时间戳 ts = time.mktime(f) # 3.将时间戳向大变 new_ts = ts + 86400 * 30 # 4.将最新的时间戳转成结构化时间 new_f = time.localtime(new_ts) # 5.将结构化时间转成字符串时间 print(time.strftime('%Y-%m-%d %X',new_f)) 获取当前时间求前一月的现在时间 1.获取时间戳进行减法计算 new_ts = time.time() - 30*86400 # 2.最新的时间戳转成结构化时间 new_f = time.localtime(new_ts) # 3.将结构化时间转成字符串时间 print(time.strftime('%Y-%m-%d %X',new_f)) time.strftime()
strftime 结构化时间转换成字符串时间使用 ('格式',' 结构化时间') 格式可以少写
strptime 字符串时间专程结构化时间使用 ('字符串时间','格式') 格式必须一一对应
datetime
from datetime import datetime from:从xx导入
print(datetime.now()) 结果精确到毫秒 拿到的是时间对象
与时间戳之间的转换
f = datetime.timestamp(datetime.now()) # 将时间对象转换成时间戳 print(datetime.fromtimestamp(f)) # 将时间戳转成时间对象
与字符串时间之间的转换
print(datetime.strptime('2018-11-30','%Y-%m-%d')) # 将字符串转成时间对象 f = datetime.now() print(datetime.strftime(f,'%Y-%m-%d')) 将时间对象转成字符串
精华: from datetime import datetime,timedelta print(datetime.now() - timedelta())
collections 数据类型的补充
from collections import xxx <---- 导入什么模块就进行什么操作
Counter 计算
c = Counter('adfasdfasdfasdfasdfasdf') print(c) print(dict(c)) # from collections import namedtuple 命名元组 tu = namedtuple('juge',['name','age','sex','hobby']) 类 t = tu('腚哥',19,'待定','抽烟,喝酒,烫头') 实例一个对象 明确的标明每个元素是什么意思 print(t[0]) 对象找属性
deque 双端队列
双端队列 d = deque([1,2,3,4]) d.append(5) #右边添加 print(d) d.appendleft(10) # 左边添加 print(d) d.insert(2,99) print(d) d.remove(3) print(d) print(d.pop()) print(d) print(d.popleft()) print(d)
队列 栈
队列 FIFO 先进先出
应用场景 火车票购票服务等
import queue q = queue.Queue(3) 括号内不写内容默认无限制,可加int,作用为限制put的个数 print(q.qsize()) 看队列还有多少值 print(q.empty()) 看队列是否是空的 print(q.full()) 看队列是否是满的 q.put(1) 向队列加入内容 q.put('ancdf') q.put([1,2,3]) print('已经放了3个') q.put([1,2,3]) print('已经放了4个') print(q) print(q.get()) 谁先put就取出谁 按put的顺序取出 print(q.get()) print(q.get()) print(q.get()) 如果队列里的数据已经全部取出,但还要get取出,程序不会报错,但已经取不出值,get在等队列里的值取出,程序不会继续向下运行,始终在运行本行的get,这种情况叫做 阻塞
栈 后进先出 LIFO 先进后出 FILO
import queue lifoq = queue.LifoQueue() lifoq.put(1) lifoq.put(2) lifoq.put(3) lifoq.put(4) lifoq.put(5) print(lifoq.get()) ----> 5 print(lifoq.get()) ----> 4 后进入的先被取出来
def func2(): print('345') def func1(): func2() print('234') def main(): func1() print('123') main() 栈 在底层的数据结构 再很多算法中 解决问题的时候必须用到这种数据结构
defaultdict 默认字典
li = [ {'name':'alex','hobby':'抽烟'}, {'name':'alex','hobby':'喝酒'}, {'name':'alex','hobby':'烫头'}, {'name':'alex','hobby':'撩妹'}, {'name':'wusir','hobby':'小宝剑'}, {'name':'wusir','hobby':'游泳'}, {'name':'wusir','hobby':'打牌'}, {'name':'太白','hobby':'烫头'}, {'name':'太白','hobby':'洗脚'}, {'name':'太白','hobby':'开车'}, ] for i in li: d[i['name']].append(i['hobby']) print([dict(d)]) li = [('红色',1),('黄色',1),('绿色',1),('蓝色',1),('红色',5),('绿色',1),('绿色',1),('绿色',1)] d = defaultdict(list) for i in li: d[i[0]].append(i[1]) dd = dict(d) for em in dd: dd[em] = sum(dd[em]) print(dd) dic = {"1":2,'2':2,'3':5,'alex':1,'wusir':2,'eva_j':3,'renjia':4} while 1: time.sleep(0.5) print(dic) print dic