CSharpGL(24)用ComputeShader实现一个简单的图像边缘检测功能
效果图
这是红宝书里的例子,在这个例子中,下述功能全部登场,因此这个例子可作为使用Compute Shader的典型示例。
★用imageLoad从纹理中读取数据。★
★用imageStore将数据写入纹理。★
★用vertex/fragment shader显示出compute shader的计算结果。★
下面是3个测试用例。
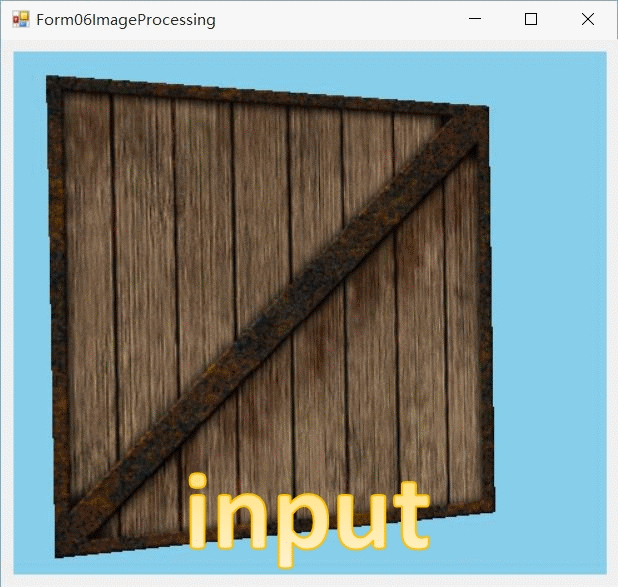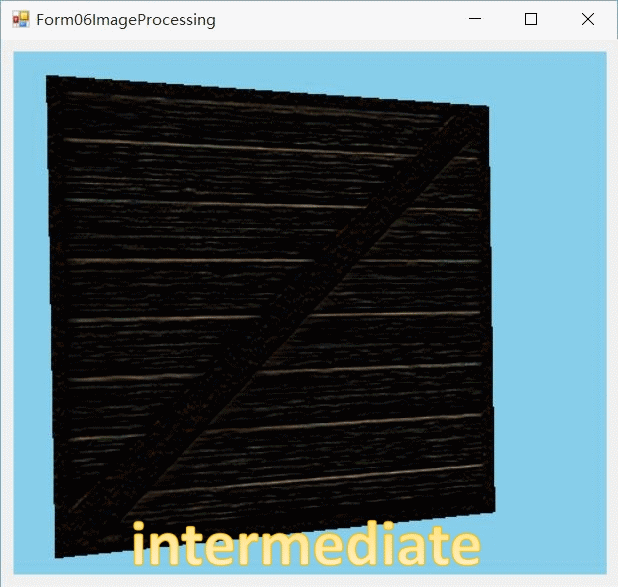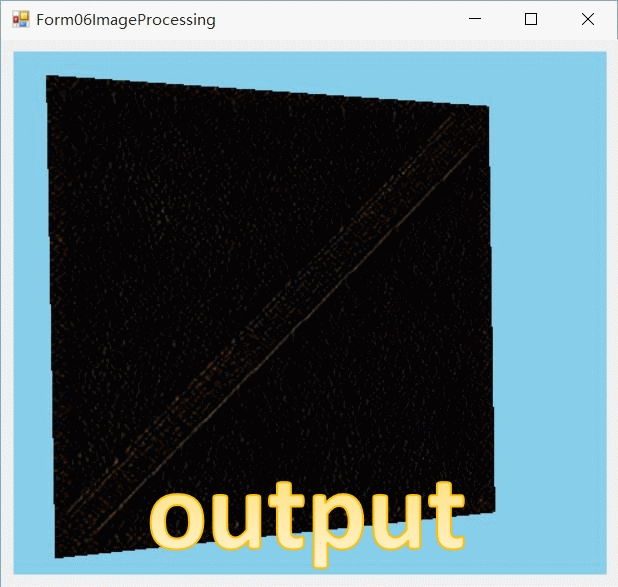
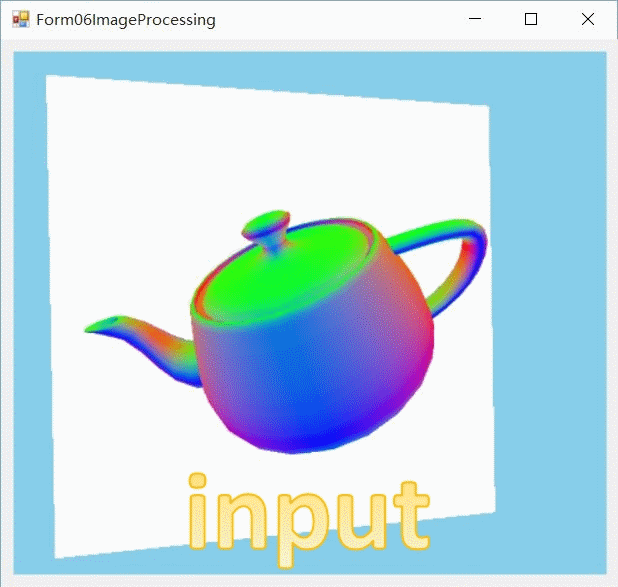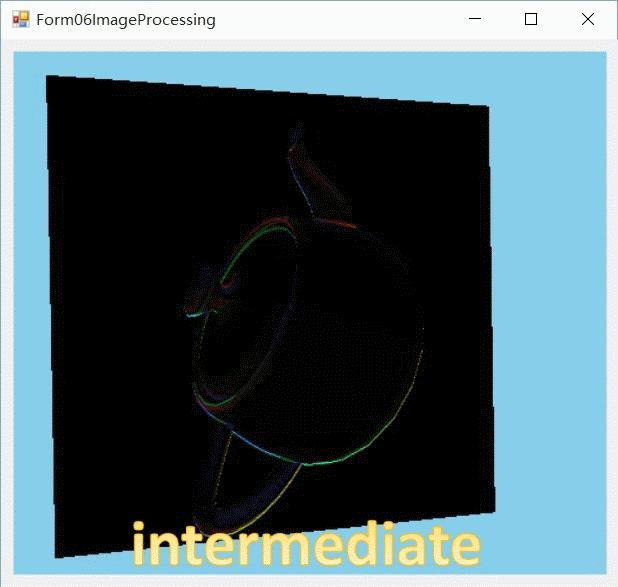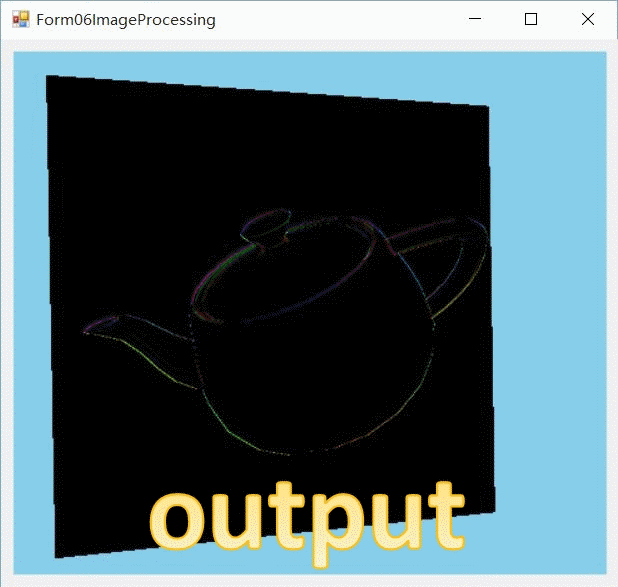
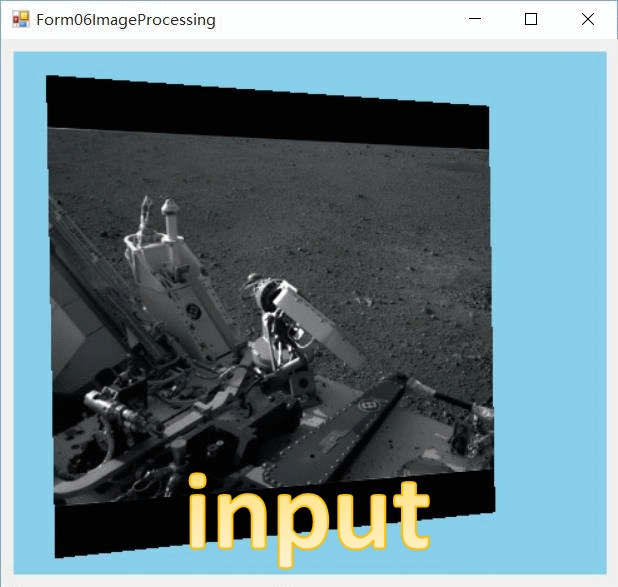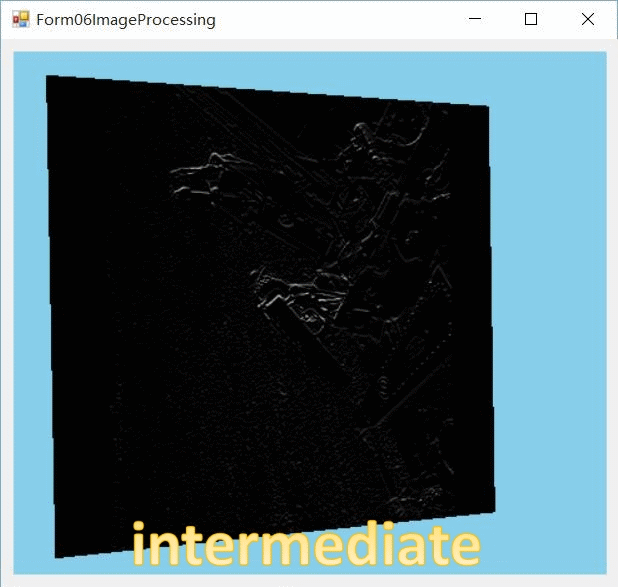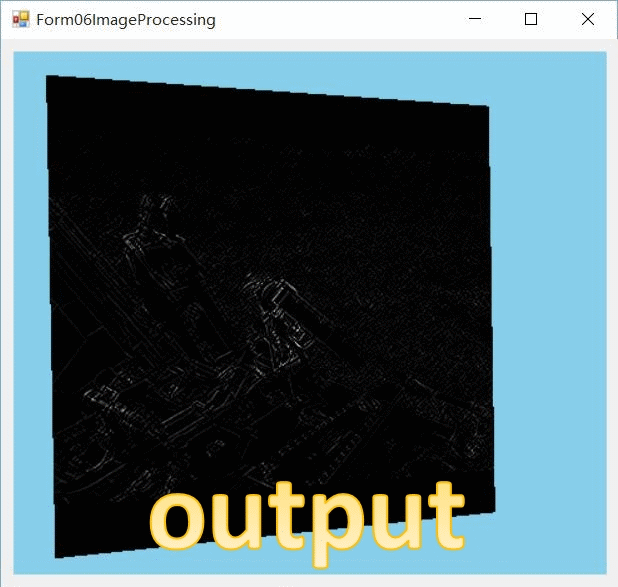
下载
CSharpGL已在GitHub开源,欢迎对OpenGL有兴趣的同学加入(https://github.com/bitzhuwei/CSharpGL)
Image Processing
渲染结果
先解决简单的问题:把compute shader计算后的结果(一个纹理)显示出来。这用到如下的vertex shader和fragment shader,非常简单。


1 #version 430 core 2 3 in vec3 vert; 4 in vec2 uv; 5 out vec2 passUV; 6 uniform mat4 mvp; 7 8 void main(void) 9 { 10 gl_Position = mvp * vec4(vert, 1.0f); 11 passUV = uv; 12 }
1 #version 430 core 2 3 layout (location = 0) out vec4 color; 4 in vec2 passUV; 5 layout (binding = 0) uniform sampler2D output_image; 6 7 void main(void) 8 { 9 color = texture(output_image, passUV); 10 }
其模型用一个四边形即可。

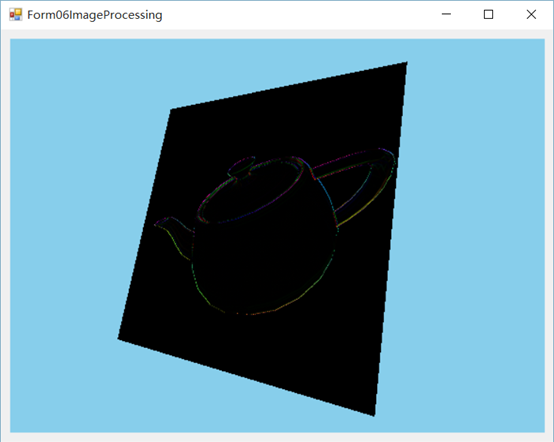
边缘检测算法
理论
在一个图像上,什么是边缘?如果相邻的两个像素颜色差别很大,就可以算是边缘。差别越大,就越能被视作边缘。
这个例子实现了一个简单的边缘检测算法,使用一个边缘检测滤波器对输入的图像(作为纹理)进行卷积操作。这个例子中的滤波器是可分离的(separable filter),就是说,可以对多维度空间的各个维度都单独处理。这里,我们将它应用到2维图像上,首先对水平维度进行处理,然后对垂直维度进行处理。
为了实现这个算法,compute shader的每个请求都要处理输入图像的一个像素。它需要读取输入图像的内容,然后减去该像素旁边的采样值。这意味着一个请求要从输入图像中读取2次。
为避免多于的内存访问,这里用一个shared数组来存储输入图形的一行。我们在每个请求中读取输入图像的目标像素,然后存储到shared数组。当所有请求都读取输入图像后,这个shared数组就含有输入图像当前行的所有像素值。之后每个请求都可以直接从此shared数组中读取像素值,这个读取速度是非常快的。
Compute Shader
实现边缘检测算法的compute shader如下。
1 #version 430 core 2 // 最大支持宽度为512的图像 3 layout (local_size_x = 512, local_size_y = 1, local_size_z = 1) in; 4 // 要进行检测的图像 5 layout (rgba32f, binding = 0) uniform image2D input_image; 6 // 检测结果 7 layout (rgba32f, binding = 1) uniform image2D output_image; 8 // 共享数组,存储当前行的像素 9 shared vec4 scanline[512]; 10 11 void main(void) 12 { 13 // 请求的位置 14 ivec2 pos = ivec2(gl_GlobalInvocationID.xy); 15 // 读取当前位置的像素 16 scanline[pos.x] = imageLoad(input_image, pos); 17 // 等待所有请求都走到这里 18 barrier(); 19 // 计算边缘值,存储到output_image 20 vec4 result = scanline[min(pos.x + 1, 511)] - scanline[max(pos.x - 1, 0)]; 21 // pos.yx:把输出图像翻转,这样就可以使用同一compute shader进行2维卷积。 22 imageStore(output_image, pos.yx, result); 23 }
执行
可以看到,上面的compute shader的一个local work group只能处理图像的一个维度上的一行。这一点由这一行代码决定:
layout (local_size_x = 512, local_size_y = 1, local_size_z = 1) in;
为了处理此维度上的全部行,在调用此compute shader时要这样:
GL.GetDelegateFor<GL.glDispatchCompute>()(1, 512, 1);
即指定在Y轴上执行512个local work group。这样就完成了在X轴维度上的计算。这时我们得到了一个中间图像intermediate_image。
★从这里可以看到设定local work group和global work group的理由:shader里的local_size_*大小有限,借助glDispatchCompute才能实现更大规模的计算,且更灵活。★
然后要对这个intermediate_image的Y轴维度执行算法。这时你注意到,在上面的compute shader里,我们用
imageStore(output_image, pos.yx, result);
而不是
imageStore(output_image, pos.xy, result);
这是把原图翻转了一下。因此,如果继续对intermediate_image执行上面的compute shader,实际上就实现了对原图在第二个维度上执行此算法。
因此总的计算过程如下。
1 computeProgram.Bind(); 2 glBindImageTexture(0, input_image[0], 0, false, 0, GL.GL_READ_WRITE, GL.GL_RGBA32F); 3 glBindImageTexture(1, intermediate_image[0], 0, false, 0, GL.GL_READ_WRITE, GL.GL_RGBA32F); 4 // 在X轴上执行边缘检测算法 5 glDispatchCompute(1, 512, 1); 6 // 确保所有compute shader请求都执行完成 7 glMemoryBarrier(GL.GL_SHADER_IMAGE_ACCESS_BARRIER_BIT); 8 9 glBindImageTexture(0, intermediate_image[0], 0, false, 0, GL.GL_READ_WRITE, GL.GL_RGBA32F); 10 glBindImageTexture(1, output_image[0], 0, false, 0, GL.GL_READ_WRITE, GL.GL_RGBA32F); 11 // 在Y轴上执行边缘检测算法 12 glDispatchCompute(1, 512, 1); 13 glMemoryBarrier(GL.GL_SHADER_IMAGE_ACCESS_BARRIER_BIT);
总结
经过这个例子,开始正视创建纹理过程中的各项参数。
原CSharpGL的其他功能(3ds解析器、TTF2Bmp、CSSL等),我将逐步加入新CSharpGL。
欢迎对OpenGL有兴趣的同学关注(https://github.com/bitzhuwei/CSharpGL)