确定执行的优先级
列出可能的解决方案,然后权衡选择。而不是一开始只是关注去收集更多的数据。例如对于垃圾邮件可以有以下一些方案:

误差分析
一般先花一天时间,简单粗暴的实现一个算法,画出学习曲线,然后逐步改进。
- Start with a simple algorithm that you can implement quickly.
implement it and test it on your cross-validation data. - Plot learning curves to decide if more data, more feature, etc. are likely to help
- Error analysis: Manually examine the examples(in cross validation set) that your algorithm made erros.
See if you spot any systematic trend in what type of examples it is making errors on.
The importance of numerical evaluation
尝试不同的改进方式,并在交叉验证集上评价。
不对称性分类的误差评估
偏斜性问题:在分类问题中,正类与负类样本数量不平衡。
对于偏斜性问题可以用:Precision与Recall来评价模型
Precision(查准率):True positive / # predicted positive

Recall(召回率):True positive / # actual positive

精确度和找回率的权衡
提高精确度:将调整为

查准率与召回率
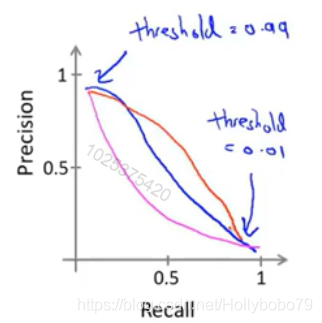
综合

机器学习数据
不要盲目搜集大量数据。但哪些条件下,大量数据有助于生成更好的模型。
- 特征数量足够
- 参数很多