简介
SequoiaDB 巨杉数据库是一款开源的金融级分布式关系型数据库,主要面对高并发联机交易型场景提供高性能、可靠稳定以及无限水平扩展的数据库服务。
用户可以在 SequoiaDB 巨杉数据库中创建多种类型的数据库实例,以满足上层不同应用程序各自的需求。
SequoiaDB 巨杉数据库支持 MySQL、PostgreSQL、SparkSQL 和 MariaDB 四种关系型数据库实例、类 MongoDB 的 JSON 文档类数据库实例、以及 S3 对象存储与 POSIX 文件系统的非结构化数据实例。
关键特性
SequoiaDB巨杉数据库可以为用户带来如下价值:
- 完全兼容传统关系型数据,数据分片对应用程序完全透明
- 高性能与无限水平弹性扩展能力
- 分布式事务与 ACID 能力
- 同时支持结构化、半结构化与非结构化数据
- 金融级安全特性,多数据中心间容灾做到 RPO = 0
- HTAP 混合负载,同时运行联机交易与批处理任务且互不干扰
- 多租户能力,云环境下支持多种级别的物理与逻辑隔离
业务场景
- 联机交易
- 分布式在线交易场景
- SequoiaDB 巨杉数据库采用计算层与存储层分离设计。
- 数据库底层存储采用 Raft 算法实现分布式环境下数据一致性技术,并且结合多分区、事务隔离等技术,为用户提供完整的分布式事务功能。
- 计算层是数据库的应用服务接入层,支持多种解析协议,包括:MySQL 协议、 PostgreSQL 协议、Spark SQL 协议、Hive SQL 协议、S3 协议、Posix 协议和 API 协议。用户可以根据不同场景,选择使用合适的计算层协议,完成应用服务开发
- 数据中台
- 主要提供全量数据的实时在线服务,同时提供对海量数据进行采集、计算、存储、 加工以及基于全量数据的数据价值发掘和数据科学工程等。
- 在企业中提供数据整合并对外提供联机服务的一组数据服务
- 数据中台主要面向外部的最终客户,提供高并发低延时的联机类业务支持。
- 数据中台体系可以分为四大部分,包括 ODS 区、贴源数据存储区、数据加工调度区、以及对外服务区。

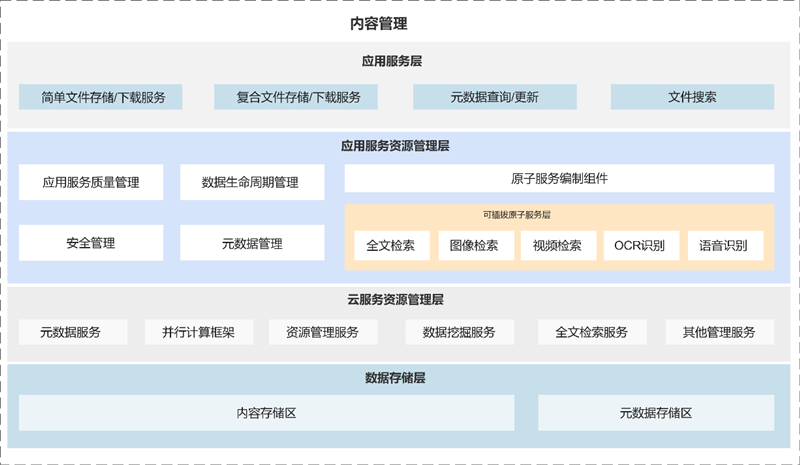
- 内容管理
- 提供了可弹性扩张的非结构化数据存储平台,以及包含批次管理、版本管理、生命周期管理、标签管理、模糊检索、断点续传等丰富的元数据管理机制。
框架
SequoiaDB 巨杉数据库作为分布式数据库,由 数据库存储引擎 与 数据库实例 两大模块构成。
-
数据库存储引擎模块是数据存储的核心,负责提供整个数据库的读写服务、数据的高可用与容灾、ACID与分布式事务等全部核心数据服务能力。
-
数据库实例模块则作为协议与语法的适配层,用户可根据需要创建包括 MySQL、MariaDB、PostgreSQL 与 SparkSQL 在内的结构化数据实例;支持 JSON 语法的 MongoDB 实例;以及完全兼容 S3 与 POSIX 文件系统的对象存储实例。

数据库实例
SequoiaDB 巨杉数据库支持多种类型的数据库实例。至当前版本为止,SequoiaDB 巨杉数据库支持七种不同的实例类型。
| 实例类型 | 实例分类 | 描述 |
|---|---|---|
| MySQL | 结构化数据 | 适用于纯联机交易场景,与 MySQL 保持 100% 兼容 |
| PostgreSQL | 结构化数据 | 适用于联机交易场景与中小量数据的分析类场景,与 PostgreSQL 基本保持兼容 |
| SparkSQL | 结构化数据 | 适用于海量数据的统计分析类场景,与 SparkSQL 保持 100% 兼容 |
| MariaDB | 结构化数据 | 适用于联机交易场景,与 MariaDB 的语法和协议保持完全兼容 |
| JSON API | 半结构化数据 | 适用于基于 JSON 数据类型的联机业务场景,与 MongoDB 保持部分兼容 |
| S3 对象存储 | 非结构化数据 | 适用于对象存储类的联机业务与归档类场景,与 S3 保持 100% 兼容 |
| POSIX 文件系统 | 非结构化数据 | 适用于使用传统文件系统向分布式环境迁移的业务场景,与标准 Ext3/XFS 等基本保持兼容 |
数据库存储引擎
SequoiaDB 巨杉数据库存储引擎采用分布式架构。集群中的每个节点为一个独立进程,节点之间采用 TCP/IP 协议进行通讯。
同一个操作系统可以部署多个节点,节点之间采用不同的端口进行区分。

节点角色
SequoiaDB 巨杉数据库存储引擎采用分布式架构。集群中的每个节点为一个独立进程,节点之间采用TCP/IP协议进行通讯。
SequoiaDB 巨杉数据库的节点分为三种不同的角色:协调节点、编目节点与数据节点。
协调节点
协调节点不存储任何用户数据。作为外部访问的接入与请求分发节点,协调节点将用户请求分发至相应的数据节点,最终合并数据节点的结果应答对外进行响应。
编目节点
编目节点主要存储系统的节点信息、用户信息、分区信息以及对象定义等元数据。在特定操作下,协调节点与数据节点均会向编目节点请求元数据信息,以感知数据的分布规律和校验请求的正确性。
数据节点
数据节点为用户数据的物理存储节点,海量数据通过分片切分的方式被分散至不同的数据节点。在关系型与 JSON 数据库实例中,每一条记录会被完整地存放在其中一个或多个数据节点中;而在对象存储实例中,每一个文件将会依据数据页大小被拆分成多个数据块,并被分散至不同的数据节点进行存放。
SQL节点
- SQL 实例是系统提供SQL访问能力的逻辑节点,可以直接配置 MySQL,PostgreSQL 和 SparkSQL 实例,实现不同 SQL 访问方式。
- SQL 实例将接收的外部请求进行SQL解析,生成内部的执行计划,将执行计划下发至协调节点,并汇总协调节点的应答进行外部响应。
- SQL 实例支持水平伸缩,实例互相独立,一次外部请求只能在一个 SQL 实例内完成。因此,可以根据外部应用的压力来规划SQL 实例的规模。
- SQL 实例需要进行一定的配置,才可以对接至指定的数据库存储引擎。
资源管理节点
资源管理节点(sdbcm)是一个守护进程,它是以服务的方式常驻系统后台。SequoiaDB 的所有集群管理操作都必须有 sdbcm 的参与,目前每一台物理机器上只能启动一个 sdbcm 进程,负责执行远程的集群管理命令和监控本地的 SequoiaDB 数据库。sdbcm 主要有两大功能:
- 远程启动,关闭,创建和修改节点:通过 SequoiaDB 客户端或者驱动连接数据库时,可以执行启动,关闭,创建和修改节点的操作,该操作向指定节点物理机器上的 sdbcm 发送远程命令,并得到 sdbcm 的执行结果。
- 本地监控:对于通过 sdbcm 启动的节点,都会维护一张节点列表,其中保存了所有本地节点的服务名和启动信息,如启动时间、运行状态等。如果某个节点是非正常终止的,如进程被强制终止,引擎异常退出等,sdbcm 会尝试重启该节点。
整体架构
SequoiaDB 巨杉数据库集群分为数据库存储引擎与数据库实例。
在当前版本中,SequoiaDB 巨杉数据库支持多达七种不同数据服务实例,包括针对结构化数据的 MySQL、MariaDB、PostgreSQL与 SparkSQL 实例;针对半结构化数据的 MongoDB 实例;以及针对非结构化数据的 S3 对象存储与 Posix 文件系统实例。
SequoiaDB 巨杉数据库的数据库存储引擎则包括协调节点、编目节点与数据节点三种类型的服务。数据节点与编目节点各自以多副本的形式构成一个个复制组。
数据库存储引擎与数据库实例均支持水平弹性扩展,任何角色的节点均提供高可用冗余机制,不存在单点故障的可能。

组成
- SQL 实例:提供兼容 MySQL、MariaDB、PostgreSQL 以及 SparkSQL 的数据库访问方式,可以实现实例化的弹性扩展。
- 协调节点 :协调节点不存储用户的任何数据,其作为外部访问的接入和分发节点,将用户请求分发至相应的数据节点,以及合并数据节点的应答对外进行响应。协调节点之间不进行数据交互;支持水平伸缩。
- 编目节点:编目节点主要存储系统的节点信息、用户信息、分区信息以及集合和集合空间的定义等元数据信息。协调节点和数据节点都会向编目节点请求元数据信息以感知数据的分布规律和校验请求的正确性。编目节点归属于编目复制组,其具备复制组的所有能力。
- 数据节点:数据节点为用户数据的真实存储节点。数据节点归属于数据复制组(又称分区组),复制组内节点互为副本,一主多从,支持 1~7 个节点,具备高可靠和高可用能力。通过增加/删除复制组内的节点可以实现数据的垂直扩容/减容。复制组内节点之间采用最终一致性同步数据,不同的复制组保存的数据无重复
核心概念
复制组
由于采用 PC 服务器内置物理盘,当前大部分分布式数据库无法在硬件设备出现故障时保证单一设备中数据的可靠性与持久性。因此 SequoiaDB 巨杉数据库采用数据多副本存放的机制,将编目节点与数据节点所存放的数据以节点为单位进行复制,多个拥有相同数据拷贝的节点被称为数据复制组。一般来说,复制组、数据分片和数据分区均代表同样的含义。
副本
每个复制组内的多个节点被称为数据副本,在 SequoiaDB 巨杉数据库中每个复制组最多支持 7 个数据副本。
由于复制组内的逻辑节点互为备份,配置了多个数据副本的 SequoiaDB 巨杉数据库原生提供高可用与容灾机制。用户可以通过添加复制组或分区的数量实现整个存储引擎集群的水平弹性扩展,也可以通过添加复制组内副本的数量实现更高的安全性以及提升读写分离的并发性。
一致性
复制组内部的多个数据副本之间可以同时使用强一致或最终一致的数据同步方式,用户可以基于节点或表(集合)级别进行相应的配置。整个集群内部数据的 ACID 与分布式事务完全由数据库存储引擎支持。
集合
-
集合(Collection)是数据库中存放文档的逻辑对象,类似于关系型数据库中的表。任何一条文档必须属于且仅属于一个集合。
-
集合由
<集合空间名>.<集合名>作为唯一标示。其中集合名最大长度为 127 字节,且需为 UTF-8 编码。 -
集合的属性信息
-
属性名 描述 分区键(ShardingKey) 指定集合的分区键,集合中所有的记录将分区键中指定的字段作为分区信息,分别存放在所对应的分区中 分区类型(ShardingType) 指定集合的分区类型:范围分区("range")或散列分区("hash") 分区数(Partition) 仅当选择 hash 分区时填写,代表了 hash 分区的个数 写副本数(ReplSize) 指定该集合默认的写副本数 数据压缩(Compressed) 标示新集合是否开启数据压缩功能 压缩算法(CompressionType) 压缩算法类型 主子表(IsMainCL) 标示新集合是否为主分区集合 自动切分(AutoSplit) 标示新集合是否开启自动切分功能 集合属组(Group) 指定新集合将被创建到哪个复制组 $id 索引(AutoIndexId) 标示新集合是否自动使用 _id 字段创建名字为 "$id" 的唯一索引 $shard 索引(EnsureShardingIndex) 标示集合是否自动使用 ShardingKey 包含的字段创建名字为 "$shard" 的索引 严格数据模式(StrictDataMode) 标示对该集合的操作是否开启严格数据类型模式 自增字段(AutoIncrement) 自增字段 -
使用 SdbCS.createCL() 创建集合
-
-
集合空间
集合空间(Collection Space)是数据库中存放集合的物理对象,类似于关系型数据库中的表空间。
-
任何一个集合必须属于且仅属于一个集合空间。
-
集合空间名最大长度为 127 字节,且需为 UTF-8 编码
-
一个数据节点最多可以包含 16384 个集合空间,一个集合空间最多可以包含 4096 个集合。
-
集合空间由若干固定大小的数据页组成。在创建集合空间时,用户可以指定数据页大小。一旦数据页大小被指定后,它将不能被修改。
-
在一个数据节点中,一个集合空间最多可以访问 128M 个数据页。对应不同数据页大小,集合空间在该数据节点的容量上限为:
-
集合空间的数据页大小由创建集合空间时指定的属性 PageSize 决定。默认情况下,PageSize 的值为 64K
数据页大小(KB) 集合空间最大容量(GB) 4 512 8 1024 16 2048 32 4096 64 8192 -
-
集合空间的属性
-
属性名 描述 数据页大小(PageSize) 数据页/索引页大小 集合空间所属域(Domain) 所属域 Lob 数据页大小(LobPageSize) Lob 数据页大小
-
-
存储单元
- 数据文件和索引文件组成 SequoiaDB 巨杉数据库的存储单元 ( Storage Unit, 简称为:SU )。每一个集合空间在其相关的数据节点中都对应一个数据文件和一个索引文件。它们的名字分别为
<集合空间名>.1.data和<集合空间名>.1.idx。- 索引文件使用B树的结构来组织记录的索引
- 数据文件
- 元数据
- 数据文件的前 64KB 字节为文件头,其后为 16MB 的 SME 段 ( Space Management Extend )和 4MB 的 MME 段 ( Metadata Management Extend )。20MB+64K 字节是该数据文件的元数据。
- MME 段被切分成 4096 个 1KB 大小的元数据块 ( Meta Block, 简称为:MB )。每个元数据块分别对应一个存放在该数据文件中的集合,所以一个集合空间最多能存放 4096 个集合
- 实际数据存储空间
- 元数据之后的空间为实际存储数据的存储空间
- 元数据
- 数据文件和索引文件组成 SequoiaDB 巨杉数据库的存储单元 ( Storage Unit, 简称为:SU )。每一个集合空间在其相关的数据节点中都对应一个数据文件和一个索引文件。它们的名字分别为
-
创建集合空间
Sdb.createCS()
数据域
数据域(Domain)是由若干个复制组(ReplicaGroup)组成的逻辑单元。每个域都可以根据定义好的策略自动管理所属数据,如数据切片和数据隔离等。其主要作用是数据隔离。
- 一个复制组可以属于多个域。
- 复制组个数为0的域,称作空域。用户在空域中不能创建集合空间。
- SYSDOMAIN 为预定义的系统域。所有复制组均属于系统域,用户不能直接操作系统域