前言:
在绝大部分情况下,特别是从一个大表中返回少量数据时,表扫描或者索引扫描并不是一种高效的方式。这些必须找出来并解决它们从而提高性能,因为扫描将遍历每一行,查找符合条件的数据,然后返回结果。这种处理是相当耗时耗资源的。在性能优化过程中,一般集中于:
1、 CPU
2、 Network
3、 磁盘IO
而扫描操作会增加这三种资源的开销。
准备工作:
下面将创建两个表来查看不同的物理关联操作的不同影响。创建脚本已经在本系列的第一篇中给出,这里不再显示。
步骤:
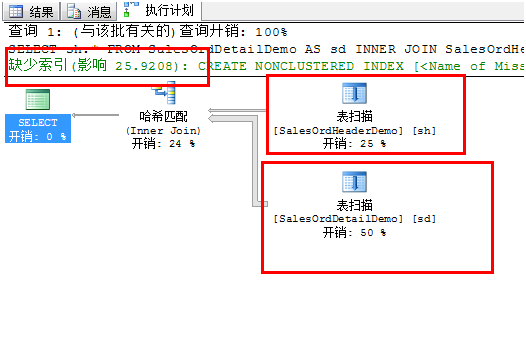
1、 打开执行计划并运行下面查询:
[sql] view plain copy
1. SELECT sh.*
2. FROM SalesOrdDetailDemo AS sd
- 3. INNER JOIN SalesOrdHeaderDemo AS sh ON sh.salesorderID = sd.salesorderid
4. WHERE sh.orderdate = '2004-07-31 00:00:00.000'
5. GO
从执行计划的截图可以看到两表均使用了表扫描,其中执行计划建议了丢失索引。此时应该考虑是否有必要创建:
2、 为了避免表扫描,创建一个聚集索引在表SalesOrdHeaderDemo中:
[sql] view plain copy
1. CREATE UNIQUE CLUSTERED INDEX idx_salesorderheaderdemo_SalesOrderID ON salesordheaderdemo(SalesOrderID)
2. GO
3、 再次运行步骤1中的查询,看看执行计划是否已经移除了表扫描:
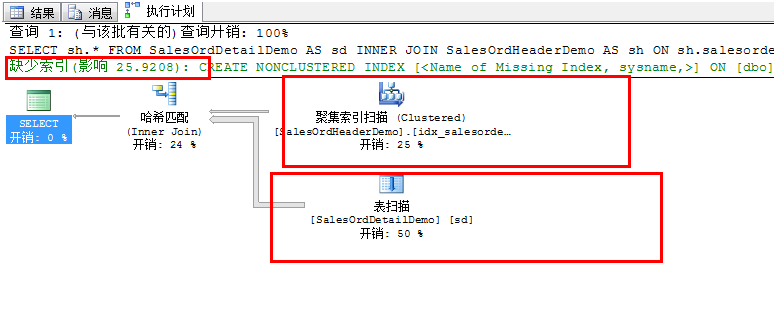
4、 上图中可以看到创建了聚集索引的表已经变成了聚集索引扫描,但是未创建的就还是表扫描,观察聚集索引扫描,它只是把表扫描换成了聚集索引扫描,所以没有很大的性能提升。
5、 现在继续把第二个表的表扫描去掉,通过创建在这个表上的唯一聚集索引:
[sql] view plain copy
1. CREATE UNIQUE CLUSTERED INDEX idx_SalesDetail_SalesOrderID ON SalesOrdDetailDemo(SalesOrderID,SalesOrderDetailID)
- 2.
3. GO
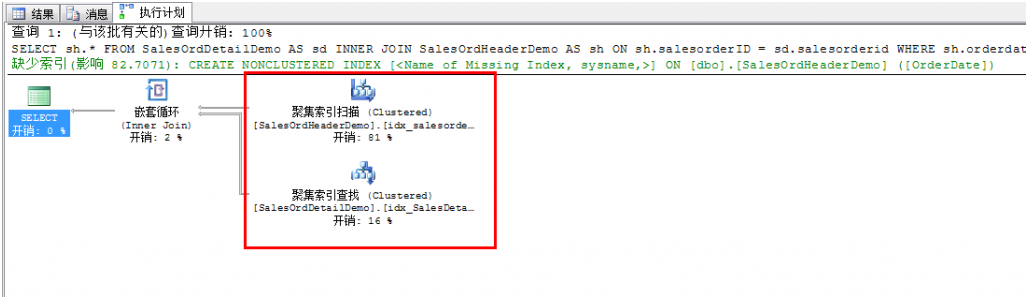
6、 再次执行查询。
7、 下面截图中可以看到表扫描已经彻底移除:
分析:
在深入讨论之前,首选需要澄清的是,扫描并不总是坏的,而查找并不总是好的,但是在绝大部分情况下,特别是在大表中返回少量数据时,查找会有更好的性能表现。同样,并不总是有方法在每个查询中移除扫描操作。如果查询的性能问题是因为扫描,那么移除扫描操作会更好,否则,看看是否有什么改变方式去提高性能。
在第一步中,因为两表均没有索引,所以优化器只能选择扫描来查找数据。
在第三步中,已经创建了一个聚集索引在SalesOrdHeaderDemo表上,表扫描变成了聚集索引扫描,聚集索引查找是我们希望得到的结果,但是因为我们没有什么谓词在第一个表上,所以只能扫描整个聚集索引来代替扫描整个表。
在第六步中,在第二个表也创建了聚集索引,且有一个谓词在这个表上,所以出现了聚集索引查找,而不是聚集索引扫描。